CaffeOnSpark安装和使用教程系列二:单节点使用CaffeOnSpark进行MNIST数据集的测试
说明:Yahoo在Github中给出了在Spark的单节点中CaffeOnSpark的简单安装和测试教程:
https://github.com/yahoo/CaffeOnSpark/wiki/GetStarted_standalone
但该教程只能作为参考,完全按照教程中的操作会出现一堆莫名其妙的问题。
1、确保CaffeOnSpark已经正确安装。
2、确保Hadoop和Spark集群已经正确部署。
3、下载MNIST数据集
进入CaffeOnSpark的主目录,执行如下指令:
sudo ./scripts/setup-mnist.sh
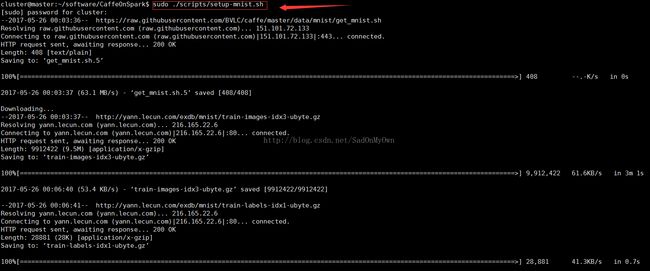
注:通过指令可以看到CaffeOnSpark的所有者为root,即普通的用户对CaffeOnSpark目录下的所有文件都没有写权限,这点非常重要。如果不注意这点,后续也会遇到权限问题的错误。使用“ls -l”指令可以查看CaffeOnSpark的详细权限信息。

4、修改CaffeOnSpark/data/lenet_memory_train_test.prototxt文件:
sudo vim lenet_memory_train_test.prototxt
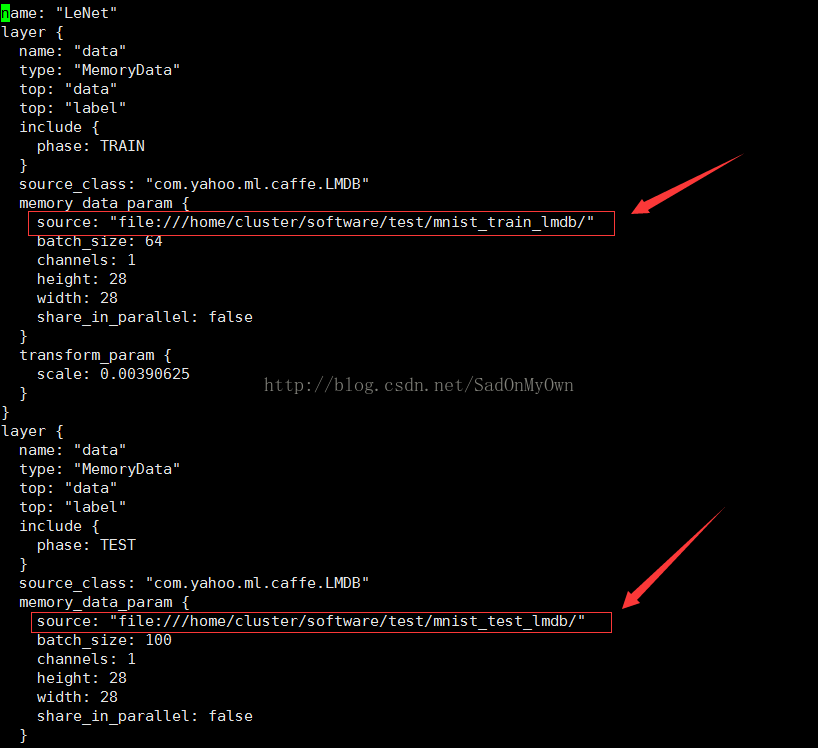
注:在该文件中主要是修改训练和测试数据的路径信息,教程中给出的资源路径为:

查看发现在CaffeOnSpark/data目录下确实有mnist_test_lmdb和mnist_train_lmdb两个资源文件:

但由于前文介绍的,只有root用户对CaffeOnSpark有操作权限,因此若在 lenet_memory_train_test.prototxt文件中传入CaffeOnSpark/data下的这两个资源文件,在执行过程中会出现“Permission Denied”的错误!
因此,在software新建一个所有者为普通用户的文件夹test,将mnist_test_lmdb和mnist_train_lmdb这两个资源文件拷贝到该文件夹下,在lenet_memory_train_test.prototxt中传入test下这两个资源文件的路径。

5、修改CaffeOnSpark/data/lenet_memory_solver.prototxt文件:
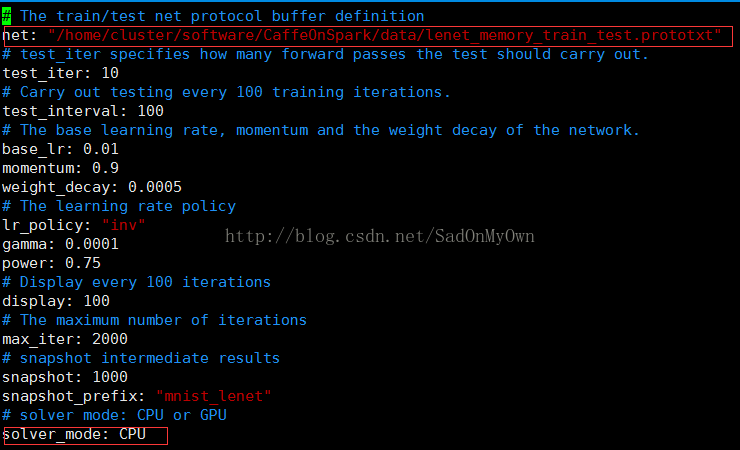
将“net”中lenet_memory_train_test.prototxt路径信息修改为绝对路径;
去掉“solver_mode:CPU”前边的“#”
6、导入临时环境变量
export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/lib
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda-7.0/lib64:/usr/local/mkl/lib/intel64/
export MASTER_URL=spark://master:7077
export SPARK_WORKER_INSTANCES=1
export CORES_PER_WORKER=1
export TOTAL_CORES=$((${CORES_PER_WORKER}*${SPARK_WORKER_INSTANCES}))
export CAFFE_ON_SPARK=/home/cluster/software/CaffeOnSpark
7、执行CaffeOnSpark示例程序
在Spark集群中输入如下指令:
spark-submit
--master spark://master:7077
--num-executors ${SPARK_WORKER_INSTANCES}
--files
${CAFFE_ON_SPARK}/data/lenet_memory_solver.prototxt,${CAFFE_ON_SPARK}/data/lenet_memory_train_test.prototxt
--conf spark.driver.extraLibraryPath="${LD_LIBRARY_PATH}"
--conf spark.executorEnv.LD_LIBRARY_PATH="${LD_LIBRARY_PATH}"
--class com.yahoo.ml.caffe.CaffeOnSpark
${CAFFE_ON_SPARK}/caffe-grid/target/caffe-grid-0.1-SNAPSHOT-jar-with-dependencies.jar
-train
-features accuracy,loss
-label label
-conf ${CAFFE_ON_SPARK}/data/lenet_memory_solver.prototxt
-conf ${CAFFE_ON_SPARK}/data/lenet_memory_train_test.prototxt
-devices 1
-connection ethernet
-model hdfs:///mnist.model
-output hdfs:///mnist_features_result
注:在程序执行过程中,可通过spark://master:8080查看正在执行任务的信息。
![]()
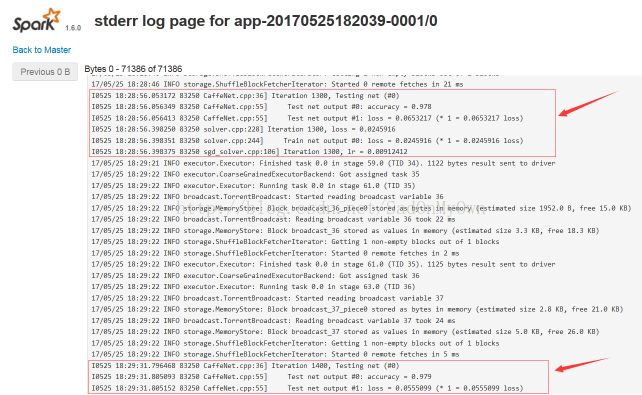
通过标准输出(stderr)日志信息,可以看到MNIST数据集的训练过程:
8、查看运行结果
由于设定训练的模型和特征结果保存在HDFS上,因此通过以下指令查看结果:
hadoop fs -ls /

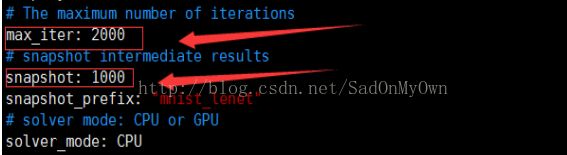
前两个为得到的最终结果,后边四个分别为迭代1000次和2000的快照信息。
通过以下指令可以查看最终得到的特征文件的具体内容信息:
hadoop fs -cat hdfs:///mnist_features_result/*
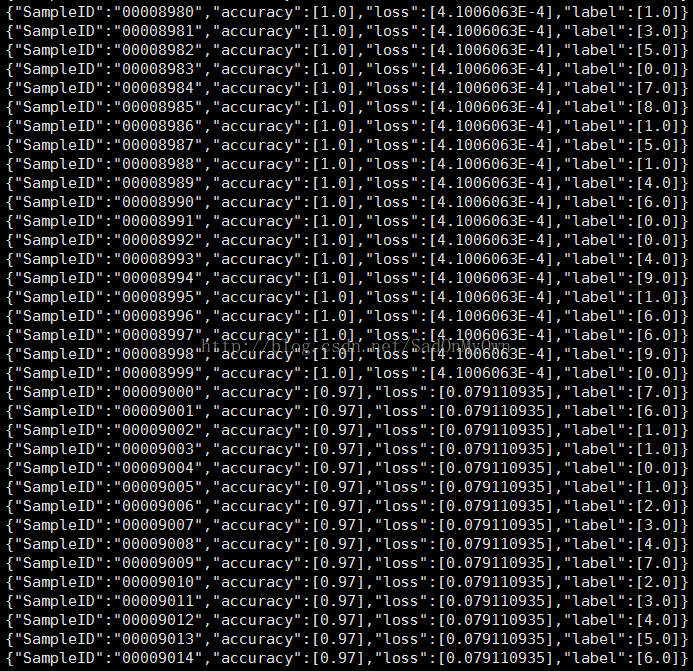
注:在lenet_memory_solver.prototxt中指定最大迭代次数为2000次,且每1000次打印一次快照,因此在结果文件中有1000和2000次迭代的信息: