TensorFlow官方教程学习 TensorFlow Mechanics 101
代码:tensorflow/examples/tutorials/mnist/
这个教程的目的在于展示如何使用TensorFlow来训练和评价一个简单的前向神经网络来使用经典的MNIST数据库识别手写数字。这个教程的适众为有经验并且对于使用TensorFlow有兴趣的用户。
这个教程目的并不在于概述地教授机器学习。
请确保你已经根据安装TensorFlow教程安装好了TensorFlow。
教程文件
这个教程参考了如下的文件:
| 文件 | 目的 |
|---|---|
| mnist.py | 建立全连接的MNIST模型的代码 |
| fully_connected_feed.py | 使用一个feed字典在下载的数据库上建立MNIST模型的主要代码 |
只需要简单地运行fully_connected_feed.py文件就可以直接开始训练
python fully_connected_feed.py准备数据
MNIST是一个机器学习的经典问题。这个问题查看手写数字的灰度28x28像素图像,决定图像表示的是哪个数字。所有数字在0到9之间。

如果想获取更多信息,查看Yann LeCun的MNIST网页 或者 Chris Olah的可视化MNIST
下载
在run_training()方法的最开始,input_data.read_data_sets()方法将会确保正确的数据被下载到你的本地训练文件夹然后解压数据,返回一个DataSet实例的字典。
data_sets = input_data.read_data_sets(FLAGS.train_dir, FLAGS.fake_data)注意:fake_data标识是为了单元测试的目的,可以被读者忽略。
| 数据库 | 目的 |
|---|---|
| data_sets.train | 55000图像和标签,主要为了训练 |
| data_sets.validation | 5000图像和标签,为了迭代验证训练的正确率 |
| data_sets.test | 10000图像和标签,为了最后测试训练的正确率 |
输入和Placeholders
placeholder_inputs()方法创建了两个tf.placeholder操作来定义输入的形状,包括batch_size,在接下来的图中使用并决定一个批的数据中装入多少实际训练例子。
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,
mnist.IMAGE_PIXELS))
labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size))再往下,在训练循环中,整个图像和标签的数据库被切分来适应每一步的batch_size,匹配这些placeholder操作,然后使用feed_dict参数传递给sess.run()。
建立图
在为data创建了placeholders之后,在mnist.py文件中根据3阶段模式创建图:inference(), loss)_和 training()
- inference() - 在网络需要向前运行进行预测的时候创建图。
- loss() - 将需要的计算损失的操作添加到Inference图中。
- training() - 将需要的计算和应用梯度的操作添加到loss图中。
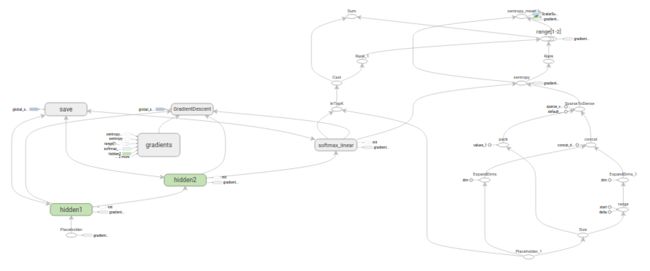
Inference
inference()函数根据需要创建图来返回包含输出预测的张量。
其将图像的placeholder作为输入,在此基础上建立完全连接的层。其采用ReLu激活,之后采用一个十个节点的线性层指定输出的logits。
(插入一下:什么是logits?在API文档中可以看到关于logits的说明是如 A Tensor of type float32 or float64. 或者 logits: Unscaled log probabilities.这样的,不过现在水平有限,没有深入理解之前不敢妄下定义。TensorFlow里面也有相关的问题)
每个层都是在一个唯一的tf.name_scope下创建,最为在该作用域内创建的元素的前缀。
with tf.name_scope('hidden1’):在定义的作用域内,这些层使用的权重和偏差都用tf.Variable的实例形式根据需要的形状生成。
weights = tf.Variable(
tf.truncated_normal([IMAGE_PIXELS, hidden1_units],
stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))),
name='weights')
biases = tf.Variable(tf.zeros([hidden1_units]),
name='biases')上面这些在hidden1作用域内创建的变量,例如权重变量的独特名字将会是’hidden1/weights’。
作为创建过程的一部分,每个变量都会有一个初始化的操作。
在最常见的情况下,权重使用tf.truncated_normal初始化并被赋予二维张量的形状,其中第一个维度表示该层中权重变量连接来源(connect from)的单元数量,第二个维度表示该层中权重连接到(connect to)的单元数量。对于第一层,也就是hidden1,维度是 [IMAGE_PIXELS, hidden1_units] 因为权重连接图像到hidden1中的输入。tf.truncated_normal初始化函数产生了给定均值和标准差的随机分布。
偏差由tf.zeros进行初始化,确保其开始时候值全部为0,它们的形状就是层中它们连接的单元的数量。
图的三个主要操作 – 两个tf.nn.relu操作封装了隐藏层所需要的tf.matmul以及额外一个给logits的tf.matmul。这三个创建依次创建,由不同的tf.Variable实例连接到每个输入的placeholders或者前面层的输出的张量中。
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)
hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases)
logits = tf.matmul(hidden2, weights) + biases最后,logits张量将会包含返回的输出。
Loss
loss()函数通过添加所需要的计算损失的操作进一步构建图。
首先,来自labels_placeholders的值被装换为64bit的整数。然后添加一个tf.nn.sparse_softmax_cross_entropy_with_logits操作来自动从labels_placeholder产生one-hot标签并比较来自inference()函数的输出logits。
labels = tf.to_int64(labels)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits, labels, name='xentropy')之后使用tf.reduce_mean来计算批次维度(第一个维度)的交叉熵的均值来作为总的损失。
loss = tf.reduce_mean(cross_entropy, name='xentropy_mean')张量将会包含返回的损失值。
注意:交叉熵是一个来自于信息理论的概念,允许我们通过给定正确的结果来描述神经网络的预测结果有多糟糕。如果要获取更多相关信息,阅读可视化信息理论的博客。
Training
training()函数通过梯度下降添加所需操作来最小化损失。
首先,其获取来自loss()函数的损失张量,将其传递给tf.scalar_summary,后者是一个当使用SummaryWriter(见如下)的时候产生总结的值(summary values)给事件文件(even files)的操作。在这个例子中,其将会在每次总结的值被写出的时候传出损失值的快照。
tf.scalar_summary(loss.op.name, loss)接下来,我们实例化一个tf.train.GradientDescentOptimizer来负责根据需求的学习速率应用梯度下降方法。
optimizer = tf.train.GradientDescentOptimizer(learning_rate)然后我们产生一个单独的变量来包含一个全局训练过程步骤的计数器。minimize()操作被用于更新系统中可训练的权重值和增加全局步骤的次数。这个操作按照惯例命名为train_op,必须被TensorFlow会话运行来引发整个的训练过程(见如下)。
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)训练模型
一旦建立好了图,在fully_connected_feed.py中的代码就能够控制在循环中迭代训练和评价模型。
图(The Graph)
在run_training()函数的最开始是一个Python with命令指示所有的构建操作都是和默认的全局tf.Graph实例相关联。
with tf.Graph().as_default():一个tf.Graph是可以组合在一起运行的一系列操作的集合。大多数TensorFlow使用情况下仅仅需要依赖于一个默认图。
TensorFlow支持使用多个图的更加复杂的使用,但是这已经超出了该教程的范围。
会话(The Session)
一旦完成了所有的构建准备并且所有必须的操作都已经生成好了,tf.Session就可以被创建用来运行图。
sess = tf.Session()也可以用一个with语句块产生Session,使得其在块内起作用并且在结束时候自动关闭。
with tf.Session() as sess:不使用参数创建session意味着使用默认的本地session。
一旦创建了会话,所有的tf.Variable实例将会通过调用它们初始化操作中的sess.run()来进行初始化。
init = tf.initialize_all_variables()
sess.run(init)sess.run()方法将会根据图中作为参数传入的操作对应的完整子集。在最开始的调用中,init操作是一个仅仅包含变量的初始化函数的tf.group。图剩余的部分不会在这里运行,它们会在之后的训练循环中运行。
训练循环(Train Loop)
在会话中初始化了变量之后,就可以开始训练了。
用户的代码控制了训练的每一步,最简单的能够进行有效训练的循环是:
for step in xrange(FLAGS.max_steps):
sess.run(train_op)然而,这个教程比这个稍微复杂。必须把输入数据进行切分来匹配前面产生的placeholders。
图中Feed操作(Feed the Graph)
对于每一个步骤,代码必须生成一个包含这个步骤中用来训练的例子的feed字典。键是它们代表的placeholder操作。
在fill_feed_dict()函数中,给定的DataSet被请求下一个batch_size大小的图像和标签集合,placeholder对应的张量包含这些图像和标签。
images_feed, labels_feed = data_set.next_batch(FLAGS.batch_size,
FLAGS.fake_data)接着产生一个Python的字典对象,将这些placeholder作为键,其代表的feed张量作为值。
feed_dict = {
images_placeholder: images_feed,
labels_placeholder: labels_feed,
}这个字典被传递到sess.run()函数的feed_dict参数来提供这些训练步骤的输入例子。
检查状态
这个代码指定了两个值来通过run调用获取:[train_op, loss]
for step in xrange(FLAGS.max_steps):
feed_dict = fill_feed_dict(data_sets.train,
images_placeholder,
labels_placeholder)
_, loss_value = sess.run([train_op, loss],
feed_dict=feed_dict)因为这里有两个值要获取,sess.run()返回为包含两个值的元组。获取值列表中的每个张量对应着返回元组中的一个numpy数组。这些数组对应着这个训练步骤中的张量的值。由于train_op是一个没有输出值的操作(Operation),在返回的元组中对应的值为None,因此可以忽略。然而损失(loss)张量的值可能是NaN如果模型在训练中发散,所以我们需要捕获该值并打日志。
假设训练运行良好,没有NaN,训练循环也每隔100步输出一个简单的状态文本来让我们知道训练的状态。
if step % 100 == 0:
print 'Step %d: loss = %.2f (%.3f sec)' % (step, loss_value, duration)状态可视化
为了输出TensorBoard使用的事件文件,所有的摘要数据(在这个例子中只有一个)在图的构建阶段被收集到一个单独的张量中。
summary = tf.merge_all_summaries()在会话创建之后,一个tf.train.SummaryWriter可以被实例化来写事件文件。事件文件中包含了图自身和摘要数据的值。
summary_writer = tf.train.SummaryWriter(FLAGS.train_dir, sess.graph)最后,事件文件能够在每次summary被评估并且输出传递给写文件的add_summary()函数的时候被新的摘要数据更新。
summary_str = sess.run(summary, feed_dict=feed_dict)
summary_writer.add_summary(summary_str, step)当事件文件被写之后,TensorBoard能够打开训练文件来展示来自摘要的值。

注意:获取更多如何构建和运行TensorBoard的心里,请查看相关教程TensorBoard:可视化你的训练
保存检查点(Checkpoint)
为了产生一个检查点文件(checkpoint file)能够被用于之后恢复模型来进行进一步的训练和评价,我们实例化一个tf.train.Saver
saver = tf.train.Saver()在训练循环中,saver.save()方法能够周期性地被调用来写一个检查点文件到训练文件夹中,包含所有可训练变量的当前值。
saver.save(sess, FLAGS.train_dir, global_step=step)在未来的某个时间点,能够通过使用saver.restore()方法重载模型参数来回复训练。
saver.restore(sess, FLAGS.train_dir)评价模型
每一千步,代码将会尝试去通过训练和测试数据库来评价模型。do_eval()函数被调用三次,分别使用训练数据,验证数据,测试数据来评价模型
print 'Training Data Eval:'
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.train)
print 'Validation Data Eval:'
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.validation)
print 'Test Data Eval:'
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.test)注意在更加复杂的应用中,仅仅在有大量的优化参数之后才使用data_sets.test进行评价。对于项MNIST这样简单的小问题,我们评估所有的数据。
建立评估图(Eval Graph)
在进入训练循环之前,Eval操作应该通过调用evaluation()函数创建。其和loss()函数有着相同的logits/labels参数。
eval_correct = mnist.evaluation(logits, labels_placeholder)evaluation()函数仅仅创建一个tf.nn.in_top_k操作,能够自动给每个模型的输出评价是否正确,通过查看正确的标签能否前K个预测中找到。在这个例子中,我们设置K的值为1,仅仅预测最可能的为正确的标签才是对的。
eval_correct = tf.nn.in_top_k(logits, labels, 1)评价输出(Eval Output)
我们现在可以创建一个循环并填充一个feed_dict和调用sess.run()应用eval_correct操作来针对给定的数据库评价模型。
for step in xrange(steps_per_epoch):
feed_dict = fill_feed_dict(data_set,
images_placeholder,
labels_placeholder)
true_count += sess.run(eval_correct, feed_dict=feed_dict)true_count变量仅仅累加了in_top_k操作正确的预测。所以正确率可以通过简单得除以总的例子数量来获取。
precision = true_count / num_examples
print(' Num examples: %d Num correct: %d Precision @ 1: %0.04f' %
(num_examples, true_count, precision))