爬虫中,爬取到的json如何转换成csv文件用作数据分析?
版本:python2.7
以爬取拉钩上深圳python的职位为例
# coding=utf-8
import requests
import json
from jsonpath import jsonpath
import urllib
class LagouSpider(object):
def __init__(self):
self.city = raw_input("请输入需要查找的城市: ")
self.position = raw_input("请输入需要查找的职位: ")
self.headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": "25",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Host": "www.lagou.com",
"Origin": "https://www.lagou.com",
"Referer": "https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36",
"X-Anit-Forge-Code": "0",
"X-Anit-Forge-Token": "None",
"X-Requested-With": "XMLHttpRequest",
}
self.base_url = "https://www.lagou.com/jobs/positionAjax.json?"
self.params = {
"city": self.city,
"needAddtionalResult": "false",
}
self.pn = 1
self.data = {
"first": "true" if self.pn == 1 else "false",
"pn": "1",
"kd": self.position,
}
self.headers["Content-Length"] = str(len(urllib.urlencode(self.data)))
self.item_list = []
def send_request(self):
python_dict = requests.post(self.base_url,params=self.params,data=self.data,headers=self.headers).json()
return python_dict
def send_parse_page(self,python_dict):
result_list = jsonpath(python_dict,"$..result")[0]
if len(result_list) == 0:
return True
for result in result_list:
item = {}
item["company-name"] = result["companyFullName"]
item["city"] = result["city"]
item["salary"] = result["salary"]
item["position-name"] = result["positionName"]
item["work-year"] = result["workYear"]
item["education"] = result["education"]
self.item_list.append(item)
self.save_content()
def save_content(self):
json.dump(self.item_list, open('lagou/'+'lagou.json', 'w'))
def main(self):
while self.pn < 5:
python_dict = self.send_request()
# print(python_dict)
result = self.send_parse_page(python_dict)
if result is True:
break
self.pn += 1
if __name__ == '__main__':
spider = LagouSpider()
spider.main()爬取到前5页的工作信息(如需爬取很多工作信息,修改while self.pn < 5:)
爬取到的结果如图:
思路:
1.现将json文件转换成python文件
2.取出key值作为表头
3.遍历取得字典中所有表头字段对应的value值
4.导入csv
5.用writerrow方法写入表头
6.用writerrows方法写入对应的value值
# coding=utf-8
import json
import csv
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def json_to_csv():
json_file = open('lagou/lagou.json', 'r')
csv_file = open('lagou/lagou.csv', 'w')
python_list = json.load(json_file)
head_data = python_list[0].keys()
value_data = [item.values() for item in python_list]
csv_writer = csv.writer(csv_file)
csv_writer.writerow(head_data)
csv_writer.writerows(value_data)
csv_file.close()
json_file.close()
if __name__ == '__main__':
json_to_csv()如果不修改Python2.7的默认解析器,会报这样的错误

也可以先decode('ascii').encoding('utf-8')
结果:

用Excel打开结果:
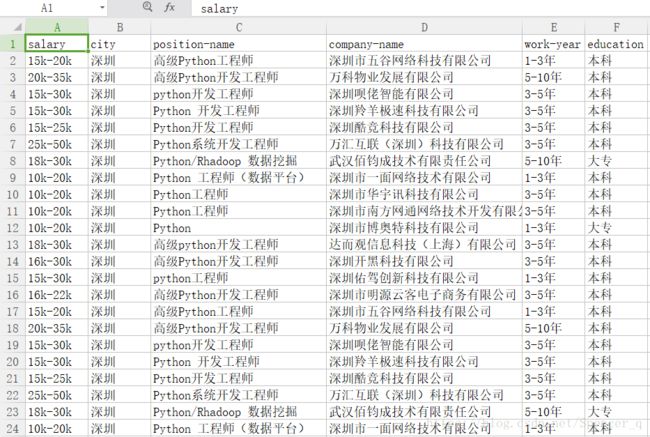 我是直接在WPS打开的,用正版的office打开可能会出现乱码,因为Windows是默认gbk编码的
我是直接在WPS打开的,用正版的office打开可能会出现乱码,因为Windows是默认gbk编码的
如果遇到乱码:
1.打开Excel,点击数据,从文本/csv导入需要打开的csv文件
2.在文本的原始格式选择utf-8,点击加载就可以了