import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pylab
from pandas import DataFrame, Series
from keras import models, layers, optimizers, losses, metrics
from keras.utils.np_utils import to_categorical
import os
#遇到新问题时,最好首先为你选择的指标建立一个基于常识的基准。 如果没有需要打败的基准,那么就无法分辨是否取得了真正的进步
fname='F:/jena_climate_2009_2016.csv'#jena天气数据集(2009—2016 年的数据,每 10 分钟记录 14 个不同的量)
def fread(fname):
f=open(fname)
data=f.read()
f.close()
lines=data.split('\n')
header=lines[0].split(',')
lines=lines[1:]
return header,lines
#对于.csv数据格式等用pandas操作更加方便
df=pd.read_csv(fname,)
temperature=df['T (degC)']
# print(temperature)
pre_10=df.ix[:1440,2]
#绘制温度时间序列
# fig=plt.figure()
# ax1=fig.add_subplot(2,1,1)
# ax2=fig.add_subplot(2,1,2)
# temperature.plot(ax=ax1)
# pre_10.plot(ax=ax2)
# plt.show()
#一个时间步是 10 分钟,每 steps 个时间步采样一次数据,给定过去 lookback 个时间步之内的数据,能否预测 delay 个时间步之后的温度?
# lookback=720-----#过去5天内的观测数据
# steps=6---------#观测数据的采样频率是每小时一个数据点。
# delay=144---------#目标是未来 24 小时之后的数据
#准备数据
#数据类型不同,所以需要标准化
#预处理数据的方法是,将每个时间序列减去其平均值,然后除以其标准差
df=df.drop(['Date Time'],axis=1)
float_data=df.ix[:,:]
# print(train_data)
mean=float_data.mean(axis=0)
# print(mean)
float_data-=mean
std=float_data.std(axis=0)
float_data /=std
# print(float_data)
#生成时间序列样本及其目标的生成器
'''
data:浮点数数据组成的原始数组,标准化后的数据。
lookback:输入数据应该包括过去多少个时间步。一个时间步是 10 分钟
delay:目标应该在未来多少个时间步之后。
min_index 和 max_index:data 数组中的索引,用于界定需要抽取哪些时间步。这有助于保存一部分数据用于验证、另一部分用于测试。
shuffle:是否打乱样本。
batch_size:每个批量的样本数。
step:数据采样的周期(单位:时间步)。我们将其设为6,为的是每小时抽取一个数据点
'''
def generator(data,lookback,delay,min_index,max_index,shuffle=False,batch_size=128,step=6):
if max_index is None:
max_index=len(data)-delay-1
#[0--min_index--lookback--max_index--delay--len(data)]
# i
i=min_index+lookback
while 1:
if shuffle:
rows=np.random.randint(min_index+lookback,max_index,size=batch_size)
else:
if i+batch_size>=max_index:#表明取到最后一批(数量非学习基准方法
'''
事实证明,超越这个基准并不容易。我们的常识中包含了大量有价值的信息, 而机器学习模型并不知道这些信息.
如果你在一个复杂模型的空间中寻找解决方案,那么可能无法学到简单且性能良好的基准方法
机器学习的一个非常重要的限制:
如果学习算法没有被硬编码要求去寻找特定类型的简单模型,那么有时候参数学习是无法找到简单问题的简单解决方案的
'''
#第一个循环网络基准
'''
门控循环单元(GRU,gated recurrent unit)层的工作原理与LSTM相同。但它做了一些简化,因此运 行的计算代价更低(虽然表示能力可能不如LSTM)。机器学习中到处可以见到这种计算代价与表示能力之间的折中。
'''
#训练并评估一个基于GRU的模型
def build_GRU():
model=Sequential()
model.add(layers.GRU(32,input_shape=(None,float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history1=model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps)
return history1
# acc_loss_plot(build_GRU())#0.28证明了循环网络与序列展平的密集网络相比在这种任务上的优势。但仍有改进的空间
#使用循环dropout来降低过拟合
'''
在循环层前面应用 dropout,这种正则化会 妨碍学习过程,而不是有所帮助
Yarin Gal 确定了在循环网络中使用 dropout 的正确方法:对每个时间步应该使用相同的 dropout 掩码(dropout mask,相同模式的舍弃单元),而不是让
dropout 掩码随着时间步的增加而随机变化。此外,为 了对 GRU、LSTM 等循环层得到的表示做正则化,应该将不随时间变化的 dropout 掩码应用于层
的内部循环激活(叫作循环 dropout 掩码)。对每个时间步使用相同的 dropout 掩码,可以让网络 沿着时间正确地传播其学习误差,而随时间随机变
化的 dropout 掩码则会破坏这个误差信号,并且不利于学习过程
#####循环注意(recurrent attention)和序列掩码 (sequence masking)。这两个概念通常对自然语言处理特别有用
'''
#Yarin Gal 使用 Keras 开展这项研究,并帮助将这种机制直接内置到 Keras 循环层中。因为使用 dropout 正则化的网络总是需要更长的时间才能完全收敛,所以网络训练轮次增加为原来的 2 倍
def build_GRU_with_dropout():
model = Sequential()
model.add(layers.GRU(32,
dropout=0.2,#指定该层输入单元的 dropout 比率
recurrent_dropout=0.2,#指定该层循环单元的 dropout 比率
input_shape=(None, float_data.shape[-1]),
))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history1 = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=40,
validation_data=val_gen,
validation_steps=val_steps)
return history1
# acc_loss_plot(build_GRU_with_dropout())#发现虽然过拟合速率有所缓解,但mae并没有降低很多
'''
增加网络容量通常是一个好主意,直到过拟合变成主要的障碍(假设 你已经采取基本步骤来降低过拟合,比如使用 dropout)。只要过拟合不是太严重,那么很可能是容量不足的问题
增加网络容量的通常做法是------增加每层单元数或增加层数
循环层堆叠(recurrent layer stacking)是构建更加强大的循环网络的经典方法,例如,目前谷歌翻译算法就是7个大型LSTM 层的堆叠
'''
def build_GRU_with_recurrent_layer_stacking():
model = Sequential()
model.add(layers.GRU(32,
dropout=0.1,#指定该层输入单元的 dropout 比率
recurrent_dropout=0.5,#指定该层循环单元的 dropout 比率
return_sequences=True,#所有中间层都应该返回完整的输出序列(一个3D张量)
input_shape=(None, float_data.shape[-1]),
))
model.add(layers.GRU(64, activation='relu', dropout=0.1,
recurrent_dropout=0.5))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history1 = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=40,
validation_data=val_gen,
validation_steps=val_steps)
return history1
# acc_loss_plot(build_GRU_with_recurrent_layer_stacking())#结果有所改进,但并不显著。
'''
因为过拟合仍然不是很严重,所以可以放心地增大每层的大小,以进一步改进验证损失。但这么做的计算成本很高。
添加一层后模型并没有显著改进,所以你可能发现,提高网络能力的回报在逐渐减小。
'''
#使用双向RNN。
'''
双向RNN利用了RNN的顺序敏感性:它包含两个普 通RNN,比如你已经学过的 GRU 层和 LSTM 层,每个RN分别沿一个方向对输入序列进行处理(时间正序和时间逆
序),然后将它们的表示合并在一起。通过沿这两个方向处理序列,双向RNN能够捕捉到可能被单向RNN忽略的模式。
'''
#将输入序列沿着时间维度反转(即将最后一行代码替换为 yield samples[:, ::-1, :], targets)
#执行后发现效果要比之前基于常识的基准方法差很多
'''
GRU 层通常更善于记住最近的数据,而不是久远的数据,与更早的数据点相比,更靠后的天气数据点对问题自然具有更高的预测能力(这也是基于常识的基准方法非常强大的原因)。因此,按时间正序的模型必然会优于时间逆序的模型.
'''
#将其应用于自然语言等问题,比如IMDB的LSTM实例[同样将序列反转]
# x_train = [x[::-1] for x in x_train]
# x_test = [x[::-1] for x in x_test]
'''
#得出模型性能与正序LSTM几乎相同,这证明了一个假设:
虽然单词顺序对理解语言很重要,但使用哪种顺序并不重要.
在机器学习中,如果一种数据表示不同但有用,那么总是值得加以利用,这 种表示与其他表示的差异越大越好,它们提供了查看数据的全新角度,抓住了数据中被其他方法忽略的内容,因此可以提高模型在某个任务上的性能。这是集成(ensembling)方法背后的直觉
'''
#双向RNN正是利用这个想法来提高正序RNN的性能。它从两个方向查看数据,从而得到更加丰富的表示,并捕捉到仅使用正序RNN时可能忽略的一些模式
#在 Keras 中将一个双向RNN实例化,我们需要使用 Bidirectional层,它的第一个参数 是一个循环层实例。Bidirectional 对这个循环层创建了第二个单独实例,然后使用一个实例 按正序处理输入序列,另一个实例按逆序处理输入序列
# model.add(layers.Bidirectional(layers.LSTM(32)))
#训练一个双向GRU
def build_bidirect_GRU():
model = Sequential()
model.add(layers.Bidirectional(layers.GRU(32,
dropout=0.2, # 指定该层输入单元的 dropout 比率
recurrent_dropout=0.2, # 指定该层循环单元的 dropout 比率
input_shape=(None, float_data.shape[-1]),
)))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history1 = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=40,
validation_data=val_gen,
validation_steps=val_steps)
return history1
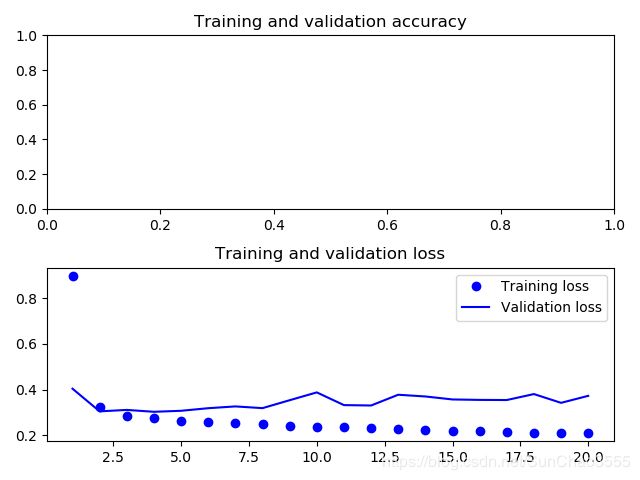
acc_loss_plot(build_bidirect_GRU())
'''
这个模型的表现与普通 GRU 层差不多一样好。其原因很容易理解:所有的预测能力肯定都 来自于正序的那一半网络,因为我们已经知道,逆序的那一半在这个任务上的表现非常糟糕(本例同样是因为,最近的数据比久远的数据更加重要)
#双向RNN 如果在序列数据中最近的数据比序列开头包含更多的信息,那么这种方法的效果就不明显
'''
基于常识的基准:
为了提高温度预测问题的性能,你还可以尝试下面这些方法
1)在堆叠循环层中调节每层的单元个数。当前取值在很大程度上是任意选择的,因此可能不是最优的。
2)调节 RMSprop 优化器的学习率。
3)尝试使用 LSTM 层代替 GRU 层。
4)在循环层上面尝试使用更大的密集连接回归器,即更大的 Dense 层或 Dense 层的堆叠。
5)不要忘记最后在测试集上运行性能最佳的模型(即验证MAE最小的模型)。否则,你开发的网络架构将会对验证集过拟合