【线性回归】面向新手的基础知识
文章目录
- 线性回归建模
- 线性回归损失函数、代价函数、目标函数
- 线性回归模型的求解方法
- 1. 梯度下降法
- 2. 最小二乘法
- 带有正则化项的回归模型
- 回归任务的评价指标
- 1. 平均绝对误差(MAE)
- 2. 均方误差(MSE)
- 3. 均方根误差(RMSE)
- 4. 决定系数( R 2 R^2 R2)
线性回归建模
首先考虑一个情景,假设我们希望用线性回归预测房屋的售价。一般网上公开的房价预测数据集都至少包含房屋的面积、厅室数量等特征以及房屋的售价:
| 面积( x 1 x_1 x1) | 厅室数量( x 2 x_2 x2) | 价格(万元)(y) |
|---|---|---|
| 64 | 3 | 225 |
| 59 | 3 | 185 |
| 65 | 3 | 208 |
| 116 | 4 | 508 |
| …… | …… | …… |
对此数据,我们可以建立售价和特征属性之间的关系:
f ( x ) = w 0 + w 1 x 1 + w 2 x 2 f(x)=w_0+w_1x_1+w_2x_2 f(x)=w0+w1x1+w2x2
更一般的,假如我们有数据集:
{ ( x ( 1 ) , y ( 1 ) , ( ( x ( 2 ) , y ( 2 ) ) , . . . , ( ( x ( n ) , y ( n ) ) } x i = ( x 1 ; x 2 ; x 3 ; . . . ; x d ) , y i ∈ R \{(x^{(1)},y^{(1)},((x^{(2)},y^{(2)}),...,((x^{(n)},y^{(n)})\} \\ x_i = (x_{1};x_{2};x_{3};...;x_{d}),y_i\in R {(x(1),y(1),((x(2),y(2)),...,((x(n),y(n))}xi=(x1;x2;x3;...;xd),yi∈R
其中,n 表示样本的个数,d表示特征的个数。则y与样本x的特征之间的关系为:
f ( x ) = w 0 + w 1 x 1 + w 2 x 2 + . . . + w d x d = ∑ i = 0 d w i x i \begin{aligned} f(x) &= w_0 + w_1x_1 + w_2x_2 + ... + w_dx_d \\ &= \sum_{i=0}^{d}w_ix_i \\ \end{aligned} f(x)=w0+w1x1+w2x2+...+wdxd=i=0∑dwixi
其中,我们假设 x 0 x_0 x0=1,下文都作此假设。
线性回归损失函数、代价函数、目标函数
- 损失函数:度量单个样本的错误程度。常用的损失函数有:0-1损失函数、平方损失函数、绝对损失函数、对数损失函数等。
- 代价函数:度量所有样本的平均错误程度,也就是所有样本损失函数的均值。常用的代价函数包括均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)等。
- 目标函数:代价函数与正则化函数的结合,也是最终要优化的函数。
我们的目标是找到一组合适的w,使得 f ( x ) ≈ y f(x)\approx y f(x)≈y 。对于回归问题,有许多性能度量方法,其中常用的一个是均方误差(MSE),即:
J ( w ) = 1 2 ∑ j = 1 n ( f w ( x ( j ) ) − y ( j ) ) 2 J(w)=\frac{1}{2}\sum_{j=1}^{n}(f_{w}(x^{(j)})-y^{(j)})^2 J(w)=21j=1∑n(fw(x(j))−y(j))2
我们称 J ( w ) J(w) J(w)为代价函数。注意到式子的系数不是1/n而是1/2,数是因为求导后的 J ′ ( w ) J'(w) J′(w) 系数为1,方便后续计算。为什么均方误差可以作为性能度量?可以从极大似然估计(概率角度)入手。
为了能够能精确的表达特征和目标值y的关系,引入了误差项ϵ,表示模型受到的未观测到的因素的影响。于是我们可以假设:
y ( i ) = w T x ( i ) + ϵ ( i ) y^{(i)} = w^T x^{(i)}+\epsilon^{(i)} y(i)=wTx(i)+ϵ(i)
使用回归模型需要满足许多前提假设,其中一个是要求ϵ独立同分布,且服从 N ( 0 , σ 2 ) N(0, σ^2) N(0,σ2)的高斯分布(正态分布):
p ( ϵ ( i ) ) = 1 2 π σ e x p ( − ( ϵ ( i ) ) 2 2 σ 2 ) p(\epsilon^{(i)}) = \frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(\epsilon^{(i)})^2}{2\sigma^2}\right) p(ϵ(i))=2πσ1exp(−2σ2(ϵ(i))2)
所以在给定w和x的前提下, y ( i ) y^{(i)} y(i) 服从 N ( w T x ( i ) , σ 2 ) N(w^T x^{(i)}, σ^2) N(wTx(i),σ2)的正态分布。
p ( y ( i ) ∣ x ( i ) ; w ) = 1 2 π σ e x p ( − ( y ( i ) − w T x ( i ) ) 2 2 σ 2 ) p(y^{(i)}|x^{(i)};w) = \frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-w^T x^{(i)})^2}{2\sigma^2}\right) p(y(i)∣x(i);w)=2πσ1exp(−2σ2(y(i)−wTx(i))2)
现在我们已经知道$y^{(i)} $的分布,但是我们不知道他的参数 w T x ( i ) , σ 2 w^T x^{(i)}, σ^2 wTx(i),σ2 ,极大似然估计法来正是用来解决此类问题的,假设样本独立同分布,最大化似然函数,来进行参数估计。最大化似然函数的原理说简单点就是在一次观测中,发生了的事件其概率应该大。概率大的事在观测中容易发生,所以我们希望让每一个 p ( y ( i ) ∣ x ( i ) ; w ) p(y^{(i)}|x^{(i)};w) p(y(i)∣x(i);w)都最大化,这等效于他们的乘积最大化。于是不难得到似然函数:
L ( w ) = ∏ i = 1 n 1 2 π σ e x p ( − ( y ( i ) − w T x ( i ) ) 2 2 σ 2 ) L(w) = \prod^n_{i=1}\frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-w^T x^{(i)})^2}{2\sigma^2}\right) L(w)=i=1∏n2πσ1exp(−2σ2(y(i)−wTx(i))2)
现在,目标转换为找到最佳的w,使得L(w)最大化,这就是极大似然估计的思想。我们通常对L(w)取对数,转换成加法的形式来方便计算:
L ( w ) = l o g L ( w ) = l o g ∏ i = 1 n 1 2 π σ e x p ( − ( y ( i ) − w T x ( i ) ) 2 2 σ 2 ) = ∑ i = 1 n l o g 1 2 π σ e x p ( − ( y ( i ) − w T x ( i ) ) 2 2 σ 2 ) = n l o g 1 2 π σ − 1 σ 2 ⋅ 1 2 ∑ i = 1 n ( ( y ( i ) − w T x ( i ) ) 2 \begin{aligned} L(w) &= log L(w) \\ &= log \prod^n_{i=1}\frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-w^T x^{(i)})^2} {2\sigma^2}\right) \\ & = \sum^n_{i=1}log\frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-w^T x^{(i)})^2}{2\sigma^2}\right) \\ & = nlog\frac{1}{{\sqrt{2\pi}\sigma}} - \frac{1}{\sigma^2} \cdot \frac{1}{2}\sum^n_{i=1}((y^{(i)}-w^T x^{(i)})^2 \end{aligned} L(w)=logL(w)=logi=1∏n2πσ1exp(−2σ2(y(i)−wTx(i))2)=i=1∑nlog2πσ1exp(−2σ2(y(i)−wTx(i))2)=nlog2πσ1−σ21⋅21i=1∑n((y(i)−wTx(i))2
因此,要最大化 L ( w ) L(w) L(w)只需要最小化:
1 2 ∑ i = 1 n ( ( y ( i ) − w T x ( i ) ) 2 \frac{1}{2}\sum^n_{i=1}((y^{(i)}-w^T x^{(i)})^2 21i=1∑n((y(i)−wTx(i))2
这一结果即为均方误差的形式,因此使用 J ( w ) J(w) J(w)作为代价函数是合理的。
线性回归模型的求解方法
1. 梯度下降法
随机初始化参数w,不端迭代,直到w达到收敛的状态,此时 J ( w ) J(w) J(w)达到了最小值(有时候是局部最小值) :
w j = w j − α ∂ J ( w ) ∂ w w_j=w_j-\alpha\frac{\partial{J(w)}}{\partial w} wj=wj−α∂w∂J(w)
上式中α为学习率,其中,
∂ J ( w ) ∂ w j = ∂ ∂ w j 1 2 ∑ i = 1 n ( f w ( x ) ( i ) − y ( i ) ) 2 = 2 ∗ 1 2 ∑ i = 1 n ( f w ( x ) ( i ) − y ( i ) ) ∗ ∂ ∂ w j ( f w ( x ) ( i ) − y ( i ) ) = ∑ i = 1 n ( f w ( x ) ( i ) − y ( i ) ) ∗ ∂ ∂ w j ( ∑ j = 0 d w j x j ( i ) − y ( i ) ) ) = ∑ i = 1 n ( f w ( x ) ( i ) − y ( i ) ) x j ( i ) \begin{aligned} \frac{\partial{J(w)}}{\partial w_j} &= \frac{\partial}{\partial w_j}\frac{1}{2}\sum_{i=1}^{n}(f_w(x)^{(i)}-y^{(i)})^2 \\ &= 2*\frac{1}{2}\sum_{i=1}^{n}(f_w(x)^{(i)}-y^{(i)})*\frac{\partial}{\partial w_j}(f_w(x)^{(i)}-y^{(i)}) \\ &= \sum_{i=1}^{n}(f_w(x)^{(i)}-y^{(i)})*\frac{\partial}{\partial w_j}(\sum_{j=0}^{d}w_jx_j^{(i)}-y^{(i)}))\\ &= \sum_{i=1}^{n}(f_w(x)^{(i)}-y^{(i)})x_j^{(i)} \\ \end{aligned} ∂wj∂J(w)=∂wj∂21i=1∑n(fw(x)(i)−y(i))2=2∗21i=1∑n(fw(x)(i)−y(i))∗∂wj∂(fw(x)(i)−y(i))=i=1∑n(fw(x)(i)−y(i))∗∂wj∂(j=0∑dwjxj(i)−y(i)))=i=1∑n(fw(x)(i)−y(i))xj(i)
于是有:
w j = w j + α ∑ i = 1 n ( y ( i ) − f w ( x ) ( i ) ) x j ( i ) w_j = w_j + \alpha\sum_{i=1}^{n}(y^{(i)}-f_w(x)^{(i)})x_j^{(i)} wj=wj+αi=1∑n(y(i)−fw(x)(i))xj(i)
将上式向量化后得到:
w = w + α ∑ i = 1 n ( y ( i ) − f w ( x ) ( i ) ) x ( i ) w = w + \alpha\sum_{i=1}^{n}(y^{(i)}-f_w(x)^{(i)})x^{(i)} w=w+αi=1∑n(y(i)−fw(x)(i))x(i)
可以看到上面的式子每次都迭代所有的样本,完成w的梯度下降,迭代过程如下图所示(越靠近内部,代价函数的值越小):

有时候我们不能将所有数据一次性加载到内存中,那么可以每次只用部分样本(例如16,32,64等)进行梯度下降,此时的梯度下降法又叫做批梯度下降法。
极端情况下,我们每次只对一个样本进行梯度下降,此时的梯度下降法又叫做随机梯度下降法(SGD)。好处是相对于使用多个样本的梯度下降法,SGD每次迭代计算量都比较小,因此迭代速度很快。缺点是容易受到噪声点的干扰,导致梯度下降的方向不稳定,如下图所示:
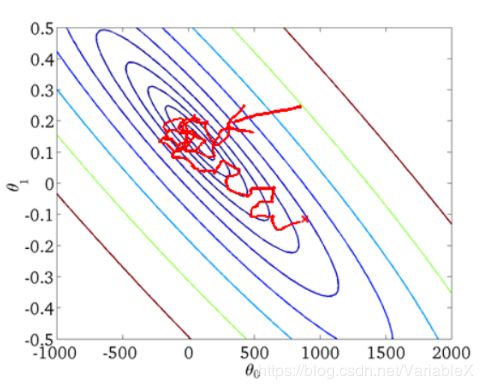
因此要结合实际场景选择合适的梯度下降算法。
2. 最小二乘法
令:
x ( i ) = [ x 0 ( i ) x 1 ( i ) x 2 ( i ) … x d ( i ) ] x^{(i)} = \left[ \begin{array} {cccc} x_0^{(i)}\\ x_1^{(i)}\\ x_2^{(i)}\\ \ldots \\ x_d^{(i)} \end{array} \right] x(i)=⎣⎢⎢⎢⎢⎢⎡x0(i)x1(i)x2(i)…xd(i)⎦⎥⎥⎥⎥⎥⎤
X = [ ( x ( 0 ) ) T ( x ( 1 ) ) T ( x ( 2 ) ) T … ( x ( n ) ) T ] X = \left[ \begin{array} {cccc} (x^{(0)})^T\\ (x^{(1)})^T\\ (x^{(2)})^T\\ \ldots \\ (x^{(n)})^T \end{array} \right] X=⎣⎢⎢⎢⎢⎡(x(0))T(x(1))T(x(2))T…(x(n))T⎦⎥⎥⎥⎥⎤
Y = [ y ( 1 ) y ( 2 ) … y ( n ) ] Y = \left[ \begin{array} {cccc} y^{(1)}\\ y^{(2)}\\ \ldots \\ y^{(n)} \end{array} \right] Y=⎣⎢⎢⎡y(1)y(2)…y(n)⎦⎥⎥⎤
则有:
f w ( x ) = X w f_w(x)=Xw fw(x)=Xw
且每个样本的误差组成的矩阵为:
X w − Y Xw -Y Xw−Y
进而有:
J ( w ) = 1 2 ( X w − Y ) T ( X w − Y ) J(w)=\frac{1}{2}(Xw-Y)^T(Xw-Y) J(w)=21(Xw−Y)T(Xw−Y)
由于这是个存在最小值的凸函数,故对w求导可得:
∂ J ( w ) ∂ w = ∂ ∂ w 1 2 ( X w − Y ) T ( X w − Y ) = 1 2 ∂ ∂ w ( w T X T X w − Y T X w − w T X T Y − Y T Y ) = 1 2 ( ∂ ( X w ) T ∂ w X w + ∂ ( X w ) T ∂ w X w − X T Y − X T Y − 0 ) = X T X w − X T Y \begin{aligned} \frac{\partial{J(w)}}{\partial w} &= \frac{\partial}{\partial w} \frac{1}{2}(Xw-Y)^T(Xw-Y) \\ &= \frac{1}{2}\frac{\partial}{\partial w} (w^TX^TXw - Y^TXw-w^T X^TY - Y^TY) \\ &= \frac{1}{2}(\frac{\partial (Xw)^T}{\partial w}Xw + \frac{\partial (Xw)^T}{\partial w}Xw-X^TY -X^TY - 0) \\ &= X^TXw - X^TY \end{aligned}\\ ∂w∂J(w)=∂w∂21(Xw−Y)T(Xw−Y)=21∂w∂(wTXTXw−YTXw−wTXTY−YTY)=21(∂w∂(Xw)TXw+∂w∂(Xw)TXw−XTY−XTY−0)=XTXw−XTY
可能用到的向量和矩阵求导公式:
∂ a T x ∂ x = ∂ x T a ∂ x = a ∂ x T A x ∂ x = ( A + A T ) x \cfrac{\partial\boldsymbol{a}^{\mathrm{T}}\boldsymbol{x}}{\partial\boldsymbol{x}}=\cfrac{\partial\boldsymbol{x}^{\mathrm{T}}\boldsymbol{a}}{\partial\boldsymbol{x}}=\boldsymbol{a} \\ \\ \cfrac{\partial\boldsymbol{x}^{\mathrm{T}}\mathbf{A}\boldsymbol{x}}{\partial\boldsymbol{x}}=(\mathbf{A}+\mathbf{A}^{\mathrm{T}})\boldsymbol{x} ∂x∂aTx=∂x∂xTa=a∂x∂xTAx=(A+AT)x
令导数等于0,得到:
w = ( X T X ) − 1 X T Y w = (X^TX)^{-1}X^TY w=(XTX)−1XTY
注意到上式存在矩阵的逆运算,一般样本数量大于维度的时候矩阵可逆,利用最小二乘法可以得到目标函数的闭式解。但是,当数据维度大于样本数时,X 非满秩,则 X T X X^TX XTX的结果根据:
r a n k ( A B ) ≤ min ( r a n k A , r a n k B ) rank(AB)\le \min{(rankA, rankB)} rank(AB)≤min(rankA,rankB)
可知 X T X X^TX XTX也不是满秩的,故不可逆,此时会有无穷多个解。
带有正则化项的回归模型
为了简化模型复杂程度,缓解过拟合,可以引入正则化项。根据使用的正则项,回归模型又可以细分为:lasso回归、岭回归(ridge回归)、ElasticNet回归。
Lasso回归使用 L 1 L_1 L1范数(向量中各个元素绝对值之和)来约束模型:
J ( w ) = 1 2 ∑ i = 1 n ( ( y ( i ) − w T x ( i ) ) 2 + λ ∥ w ∥ 1 (1) J(w) = \frac{1}{2}\sum^n_{i=1}((y^{(i)}-w^T x^{(i)})^2 + \lambda \|w\|_1 \tag 1 J(w)=21i=1∑n((y(i)−wTx(i))2+λ∥w∥1(1)
岭回归使用 L 2 L_2 L2范数(向量各元素平方和的平方根)的平方来约束模型:
J ( w ) = 1 2 ∑ i = 1 n ( ( y ( i ) − w T x ( i ) ) 2 + λ ∥ w ∥ 2 2 (2) J(w) = \frac{1}{2}\sum^n_{i=1}((y^{(i)}-w^T x^{(i)})^2 + \lambda \|w\|^2_2 \tag 2 J(w)=21i=1∑n((y(i)−wTx(i))2+λ∥w∥22(2)
L 1 L_1 L1, L 2 L_2 L2都有助于减缓过拟合,但是前者可以使得部分不重要的特征 x j x_j xj对应的权重 w j w_j wj变为0,可以起到特征选择的作用。
为了更好的理解,我们假设模型只有两个参数 x 1 , x 2 x_1, x_2 x1,x2, 对应的权重为 w 1 , w 2 w_1, w_2 w1,w2,将公式(1),(2)等号右边的两项分别绘制图像可以得到:
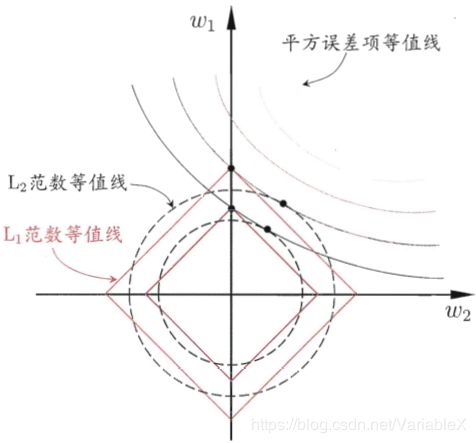
公式(1),(2)的最优解应该是均方误差项和正则化项的折中,即出现在均方误差项和正则化项的交点处。从上图可以看到,采用 L 1 L_1 L1范数时,交点出现在 w 2 w_2 w2等于0的坐标轴上,意味着对于此模型特征 x 2 x_2 x2并没有起到作用,可以舍去。而采用 L 2 L_2 L2范数的话,交点更容易落在某个象限中,即$w_1, w_2 不 等 于 0 。 总 的 来 说 , 就 是 不等于0。总的来说,就是 不等于0。总的来说,就是L_1 范 数 比 范数比 范数比L_2$范数更容易得到稀疏的解。
ElasticNet回归则是同时使用了 L 1 L_1 L1, L 2 L_2 L2来约束模型:
J ( w ) = 1 2 ∑ i = 1 n ( ( y ( i ) − w T x ( i ) ) 2 + λ 1 ∥ w ∥ 1 + λ 2 ∥ w ∥ 2 2 J(w) = \frac{1}{2}\sum^n_{i=1}((y^{(i)}-w^T x^{(i)})^2 + \lambda_1 \left \| {w} \right \|_1 + \lambda_2\left \| {w} \right \|_2^2 J(w)=21i=1∑n((y(i)−wTx(i))2+λ1∥w∥1+λ2∥w∥22
ElasticNet回归在具有多个特征,并且在特征之间具有一定关联的数据中比较有用。
回归任务的评价指标
1. 平均绝对误差(MAE)
平均绝对误差也叫 L 1 L_1 L1范数损失,公式为:
M A E = 1 n ∑ i = 1 n ∣ ( y ( i ) − y ^ ( i ) ∣ MAE = \frac{1}{n}\sum^{n}_{i=1} | (y^{(i)} - \hat y^{(i)} | MAE=n1i=1∑n∣(y(i)−y^(i)∣
其中n为样本的个数, y ^ ( i ) \hat y^{(i)} y^(i) 表示第i个样本的预测值。MAE能很好的刻画预测值和真实值的偏差,因为偏差有正有负,为了防止正负误差抵消,MAE计算的是误差绝对值的平均值。MAE 也可以作为损失函数,但是有些模型(如XGboost)必须要求损失函数有二阶导数,所以不能使用MAE进行优化。
加权平均绝对误差(WMAE)是MAE的变形,比如考虑时间因素,离当前时间越久的样本权重越低。公式为:
W M A E = 1 n ∑ i = 1 n w ( i ) ∣ ( y ( i ) − y ^ ( i ) ∣ WMAE = \frac{1}{n}\sum^{n}_{i=1} w^{(i)}| (y^{(i)} - \hat y^{(i)} | WMAE=n1i=1∑nw(i)∣(y(i)−y^(i)∣
其中, w ( i ) w^{(i)} w(i)为第i个样本的权重。
2. 均方误差(MSE)
MSE 计算的是误差平方和的均值,公式如下:
M S E = 1 n ∑ i = 1 n ( y ( i ) − y ^ ( i ) ) 2 MSE = \frac{1}{n}\sum^{n}_{i=1} (y^{(i)} - \hat y^{(i)} )^2 MSE=n1i=1∑n(y(i)−y^(i))2
MSE 它对误差有着更大的惩罚,但是他也对离群点敏感,健壮性可能不如MAE。
3. 均方根误差(RMSE)
MSE公式有一个问题是会改变量纲。因为公式平方了,比如说 y 值的单位是万元,MSE 计算出来的是万元的平方,对于这个值难以解释它的含义。RMSE 其实就是对MSE开平方根,公式如下:
R M S E = 1 n ∑ i = 1 n ( y ( i ) − y ^ ( i ) ) 2 RMSE=\sqrt{\frac{1}{n}\sum^{n}_{i=1} (y^{(i)} - \hat y^{(i)} )^2} RMSE=n1i=1∑n(y(i)−y^(i))2
可以看到 MSE 和 RMSE 二者是呈正相关的,MSE 值大,RMSE 值也大,所以在评价线性回归模型效果的时候,使用 RMSE 就可以了。
4. 决定系数( R 2 R^2 R2)
当数据集不同时,或者说数据集预测目标的量纲不同时,上面三种评估方式的结果就不好比较了。 R 2 R^2 R2把预测目标的均值作为参照,例如房价数据集的房价均值,学生成绩的成绩均值。现在我们把这个均值当成一个基准参照模型,也叫 baseline model。这个均值模型对任何数据的预测值都是一样的,可以想象该模型效果自然很差。基于此我们才会想从数据集中寻找规律,建立更好的模型。
R 2 R^2 R2公式如下:
R 2 = 1 − ∑ i = 1 n ( y ( i ) − y ^ ( i ) ) 2 ∑ i = 1 n ( y ˉ − y ^ ( i ) ) 2 = 1 − 1 n ∑ i = 1 n ( y ( i ) − y ^ ( i ) ) 2 1 n ∑ i = 1 n ( y ˉ − y ^ ( i ) ) 2 = 1 − M S E V A R R^2 = 1- \frac{\sum^{n}_{i=1} (y^{(i)} - \hat y^{(i)} )^2}{\sum^{n}_{i=1} (\bar y - \hat y^{(i)} )^2} = 1-\frac{\frac{1}{n}\sum^{n}_{i=1}(y^{(i)} - \hat y^{(i)})^2}{\frac{1}{n}\sum^{n}_{i=1}(\bar y - \hat y^{(i)})^2} = 1-\frac{MSE}{VAR} R2=1−∑i=1n(yˉ−y^(i))2∑i=1n(y(i)−y^(i))2=1−n1∑i=1n(yˉ−y^(i))2n1∑i=1n(y(i)−y^(i))2=1−VARMSE
R 2 R^2 R2= 1,达到最大值。即分子为 0 ,意味着样本中预测值和真实值完全相等,没有任何误差。也就是说我们建立的模型完美拟合了所有真实数据,是效果最好的模型, R 2 R^2 R2值也达到了最大。但通常模型不会这么完美,总会有误差存在,当误差很小的时候,分子小于分母,模型会趋近 1,仍然是好的模型,随着误差越来越大,$R^2 $也会离最大值 1 越来越远,直到出现下面的情况。
R 2 R^2 R2= 0,此时分子等于分母,样本的每项预测值都等于均值。也就是说我们辛苦训练出来的模型和前面说的均值模型完全一样,还不如不训练,直接让模型的预测值全去均值。当误差越来越大的时候就出现了第三种情况。
R 2 R^2 R2< 0 ,分子大于分母,训练模型产生的误差比使用均值产生的还要大,也就是训练模型反而不如直接去均值效果好。出现这种情况,通常是模型本身不是线性关系的,而我们误使用了线性模型,导致误差很大。
参考资料:
【机器学习12】线性回归算法评价指标:MSE、RMSE、R2_score
周志华 《机器学习》
李航 《统计学习方法 第二版》