【Django 011】Django2.2视图函数详解(三):HttpResponse和JsonResponse以及重定向和反向解析详解
上一节我们了解了客户端的请求,这一节我们来看看服务器的返回,看看除了正常返回一个网页,我们还可以有哪些个性化的操作。
我是T型人小付,一位坚持终身学习的互联网从业者。喜欢我的博客欢迎在csdn上关注我,如果有问题欢迎在底下的评论区交流,谢谢。
文章目录
- 操作环境
- HttpResponse
- 构造函数
- 属性和方法
- 重定向与反向解析
- view函数中的反向解析
- 临时重定向
- 永久重定向
- 两种重定向对比
- 重定向加路径参数
- 重定向加查询参数
- 返回Json数据
- Json数据格式
- JsonResponse
- 源码分析
- 总结
操作环境
先总结下我的操作环境:
Centos 7
Python 3.7
Pycharm 2019.3
Django 2.2
因为Django长期支持版本2.2LTS和前一个长期支持版本1.11LTS有许多地方不一样,需要小心区分。
HttpResponse
前面了解的HttpRequest对象是Django帮我们自动创建的,但是返回的HttpResponse对象需要用户自己创建,用户需要确保每个view函数返回的都是一个HttpResponse对象。
经过前面几节,我们已经接触了两种服务端view函数返回HttpResponse对象的方法
- 直接利用HttpResponse方法
- 调用模板进行渲染,或者直接用render方法一步到位
render方法的三个参数如下
- request - 上一小节讲的HttpRequest对象
- template_name - templates下面的h5模板文件
- context - 传递到模板的数据,是一个字典
构造函数
先看看HttpResponse对象的构造函数,官方文档给出的定义如下
HttpResponse.__init__(content=b'', content_type=None, status=200, reason=None, charset=None)
- content
传递一个string进去做为返回的内容 - content_type
是一个MIME类型,浏览器通过这个类型选择打开文件的程序,同时还添加了一个编码类型,默认是text/html; charset=utf-8
MIME(Multipurpose Internet Mail Extensions)和文件的扩展名一样,只是便于选择默认打开程序的,并不会决定文件的内容
- status
状态码,状态码也和实际是否成功返回无关,例如成功返回网页也可以修改默认的200为404 - charset
编码类型,如果不指定就从前面的content_type提取
属性和方法
除了构造函数,还有很多的属性和方法可以用来做个性化。
常用的几个属性如下
- HttpResponse.content
- HttpResponse.charset
- HttpResponse.status_code
常用的几个方法如下
- HttpResponse.write()
- HttpResponse.flush()
- HttpResponse.set_cookie()
- HttpResponse.delete_cookie()
用一个简单实例来实际感受下。
新建一个叫Three的应用,然后创建路由规则和对应的view函数如下
urlpatterns = [
path('test/',views.test, name='test'),
]
def test(request):
response = HttpResponse()
response.content = 'This is a great world.
'
response.status_code = 404
return response
这时候如果访问http://127.0.0.1:8000/three/test/会正常返回网页,但是显示404错误码,如下所示

如果要分段往网页上添加内容可以用HttpResponse.write(),不过因为是写到缓存区里面,所以要记得及时flush。创建一个新的路由和view函数如下
path('writeflush/',views.writeflush),
def writeflush(request):
response = HttpResponse()
response.write('Life is beautiful.
')
response.write('Life is beautiful.
')
response.write('Life is beautiful.
')
response.flush()
return response
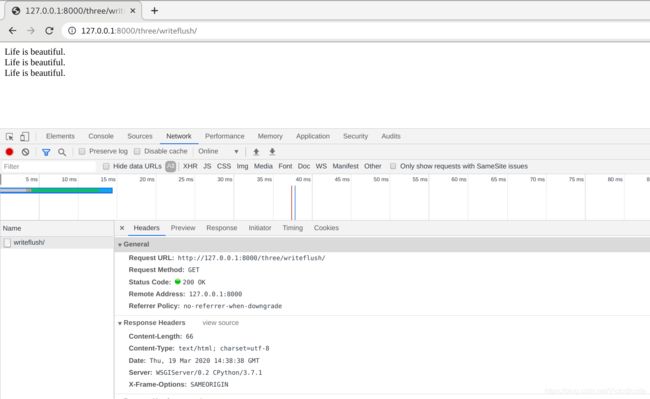
这时候如果访问http://127.0.0.1:8000/three/writeflush/就会看到下面的网页
重定向与反向解析
除了正常处理请求,还有一种比较常见的操作就是重定向到别的url来处理请求,也就是常说的301或者302返回码。当然既然涉及到跳转页面,又跟之前在《Django 009】Django2.2视图函数详解(一):正则表达式获取url中路径信息以及反向解析》中一样涉及到了反向解析,不过之前是在模板文件中,而这里是在view函数中,一会我们来看看如何实现。
view函数中的反向解析
在模板文件中,我们使用{% url 'namespace:name' %}的方式去做反向解析。而在view函数中,则是通过reverse方法来实现的。特别提醒是reverse而不是reversed,同时import的时候要看清楚,不能搞错了。
下面用实例来看看如何使用的。
临时重定向
临时重定向返回的是HttpResponseRedirect()对象。创建两个路由如下
urlpatterns = [
path('test/',views.test, name='test'),
path('testredirect/',views.testredirect),
]
两个view函数如下
def test(request):
response = HttpResponse()
response.content = 'This is a great world.
'
return response
def testredirect(request):
response = HttpResponseRedirect(reverse('three:test'))
return response
注意import的时候不要搞错了
from django.http import HttpResponse, HttpResponseRedirect
from django.urls import reverse
这里的反向解析使用的是reverse('three:test'),其中three是namespace名字,而test是上面路由中设定的name,用冒号连接和模板文件中一样。
这时候如果访问http://127.0.0.1:8000/three/testredirect/会看到下面的结果
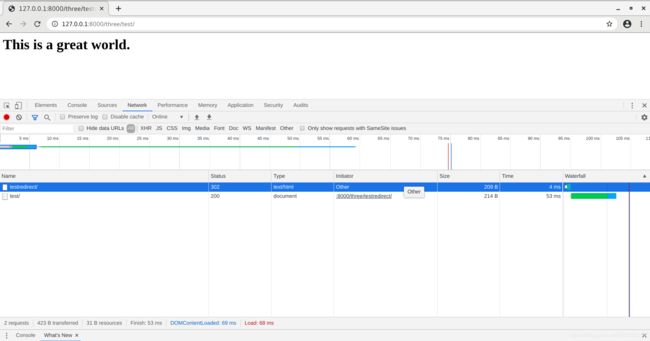
首先是做了一个302的重定向,然后直接跳到http://127.0.0.1:8000/three/test/来了。
当然这里是所有请求都被重定向了,也可以在这里做一些逻辑判断,将部分流量进行重定向。
永久重定向
永久重定向使用的是HttpResponsePermanentRedirect()对象。最常见的就是url后面不加/的情况。
例如我访问http://127.0.0.1:8000/three/test的结果如下

这也是为什么我们会发现浏览器自动帮我们加上/的原因。
两种重定向对比
表面上看301和302是两种重定向,但如果看源码就会发现,他俩都是继承自同一个父类,只是改了一个返回码
class HttpResponseRedirect(HttpResponseRedirectBase):
status_code = 302
class HttpResponsePermanentRedirect(HttpResponseRedirectBase):
status_code = 301
实际当中使用301或者302看具体业务的需求。
重定向加路径参数
在前面《Django 009】Django2.2视图函数详解(一):正则表达式获取url中路径信息以及反向解析》一样,遇到用正则表达式在url中提取路径参数的情况,反向解析时就要相应地传递参数进去,用例子来说明。
- 位置参数
修改一下上面路由和view函数如下
re_path(r'test/(.*?)/', views.test, name='test'),
path('testredirect/',views.testredirect),
def test(request,content):
response = HttpResponse()
response.content = content
return response
def testredirect(request):
response = HttpResponseRedirect(reverse('three:test', args=('this is awesome',)))
return response
位置参数用tuple来表示,传递给args,如果tuple只有一个元素记得加一个逗号。这时候访问http://127.0.0.1:8000/three/testredirect/就会如下所示

- 关键字参数
修改路由和view函数如下
re_path(r'test/(?P.*?)/', views.test, name='test'),
path('testredirect/',views.testredirect),
def test(request,shout):
response = HttpResponse()
response.content = shout
return response
def testredirect(request):
response = HttpResponseRedirect(reverse('three:test', kwargs={'shout':'what the hell?'})
return response
关键字参数由字典来表示,传递给kwargs,这时候访问http://127.0.0.1:8000/three/testredirect/就会如下所示

重定向加查询参数
如果是查询参数就比较简单,直接用字符串拼接的方式即可。
修改view函数如下
def test(request,shout):
result = request.GET.get('result')
response = HttpResponse()
response.content = shout + ' '+result
return response
def testredirect(request):
response = HttpResponseRedirect(reverse('three:test', kwargs={'shout': 'what the hell?'})+'?result=calm%20down')
return response
一个比较实用的应用场景就是用户登录后生成token然后带着token重定向到个人主页。这时候访问http://127.0.0.1:8000/three/testredirect/就会如下所示

返回Json数据
除了返回网页,还可以返回Json数据。在前后端分离或者是Ajax中使用的是很多的。这里先简单了解一下,后面我们再详细看看前后端分离和DRF(Django REST Framework)框架。
Json数据格式
Json包含JsonObject以及JsonArray,分别对应着python中的dict和list。这两种数据类型可以嵌套。
JsonResponse
区别于前面的HttpResponse,返回Json格式的时候是通过JsonResponse()对象来实现的。
创建路由和view函数如下
path('getinfo/', views.getinfo),
def getinfo(request):
data = {
'name': 'xiaofu',
'age': 99,
}
return JsonResponse(data=data)
这里的JsonResponse需要先import进来,主要是一个data参数,传递一个python的dict或者list进来。
之后访问http://127.0.0.1:8000/three/getinfo/的时候,结果如下

可以看到Content-Type是application/json。
如果觉的浏览器默认的Json显示比较不容易查看,可以安装Chrome插件

源码分析
如果查看JsonResponse的源码会发现它其实是HttpResponse的一个子类。将dict类型dumps成为string然后传入HttpResponse中,同时修改了content_type
def __init__(self, data, encoder=DjangoJSONEncoder, safe=True,
json_dumps_params=None, **kwargs):
if safe and not isinstance(data, dict):
raise TypeError(
'In order to allow non-dict objects to be serialized set the '
'safe parameter to False.'
)
if json_dumps_params is None:
json_dumps_params = {}
kwargs.setdefault('content_type', 'application/json')
data = json.dumps(data, cls=encoder, **json_dumps_params)
super().__init__(content=data, **kwargs)
总结
MTV模型中的V,也就是view函数,我们也了解的差不多了。现在问题又来了,从request到response这个过程是很短暂的,那么网站是如何实现长连接的呢?下次访问的时候服务器怎么知道我就是上次访问的我呢?这就涉及到cookie和会话技术了,我们下一节一起来看看。