训练神经网络中的基本概念之训练结果图分析---Top mAP rank Precision等
一、Top-1 Top-5
ImageNet 图像分类大赛评价标准采用 top-5 错误率,或者top-1错误率,即对一张图像预测5个类别,只要有一个和人工标注类别相同就算对,否则算错。
top1-----就是你预测的label取最后概率向量里面最大的那一个作为预测结果,如过你的预测结果中概率最大的那个分类正确,则预测正确。否则预测错误
top5-----就是最后概率向量最大的前五名中,只要出现了正确概率即为预测正确。否则预测错误
Top-1 = (正确标记 与 模型输出的最佳标记不同的样本数)/ 总样本数
Top-5 = (正确标记 不在 模型输出的前5个最佳标记中的样本数)/ 总样本数
二、matlab 训练结果图
![]()
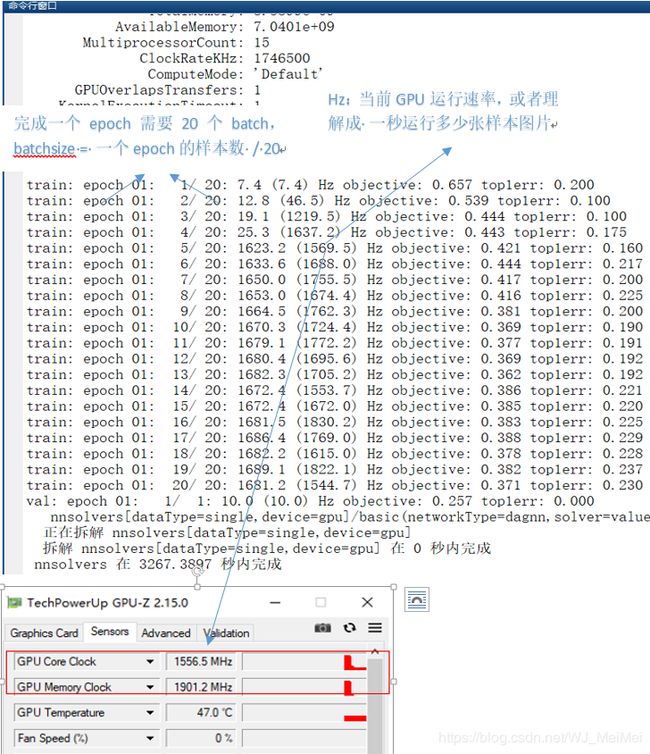
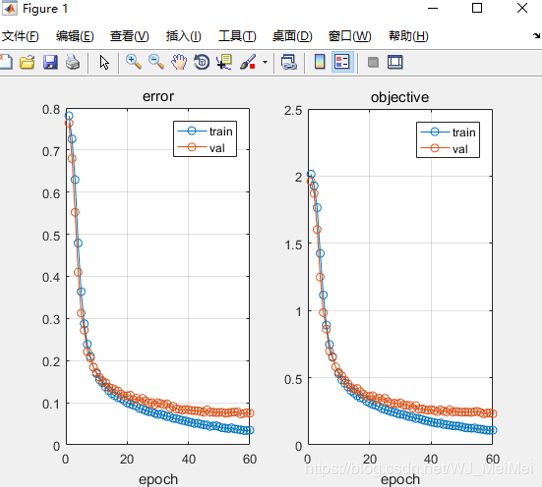
error:为一个batch里所有样本的loss
sample : 一次迭代的样本数目
三、MAP rank recall F-score CMC
mAP和rank1 是衡量算法搜索能力的指标,mAP的全称是mean average precision
rank1 是搜索结果中最靠前的一张图是正确结果的概率,一般通过实验多次来取平均值
rank-k:算法返回的排序列表中,前k位为存在检索目标则称为rank-k命中
Precision:= 提取出的正确信息条数 / 提取出的信息条数
Recall: = 提取出的正确信息条数 / 样本中的信息条数
故,Precision高,Recall就低,Recall高,Precision就低。一般在保证召回率的条件下,尽量提升精确率
F-score:![]() ,F-score是综合考虑Precision和Recall的调和值
,F-score是综合考虑Precision和Recall的调和值
mAP:以recall为横坐标,precision为纵坐标,绘制PR曲线,曲线下方面积即为AP,当需要检索的不止一个人时,此时取所有人的平均mAP
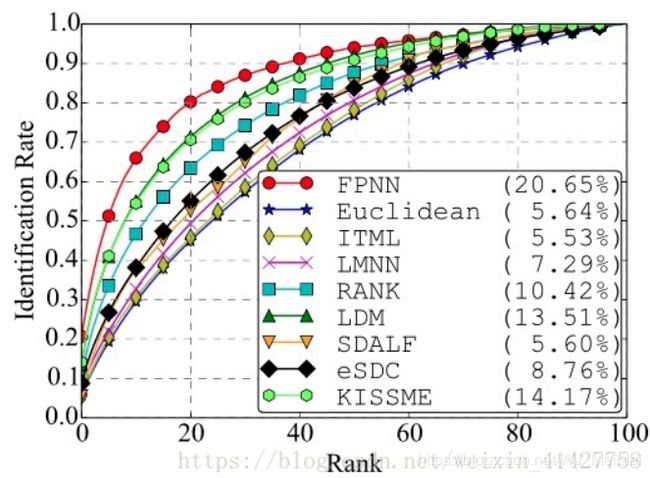
Cumulative Match Characteristic (CMC) curve: 计算rank-k的击中率,形成rank-acc的曲线,如下图:
四、例题
目标是识别 lable为m1,在100个样本中搜索
如果识别结果是m1、m2、m3、m4、m5……
则rank-1的正确率为100%;rank-2的正确率也为100%;rank-5的正确率也为100%
如果识别结果是m2、m1、m3、m4、m5……
则rank-1的正确率为0%;rank-2的正确率为100%;rank-5的正确率也为100%
如果识别结果是m2、m3、m4、m5、m1……
则此时rank-1的正确率为0%;rank-2的正确率为0%;rank-5的正确率为100%
待识别的有3个,1号(m1)、2号(m2) 、3号(m3),目的是识别 label为m1,m2,m3,在100个样本中搜索
如果1号识别结果是m1、m2、m3、m4、m5……
如果2号识别结果是m2、m1、m3、m4、m5……
如果3号识别结果是m3、m1、m2、m4、m5……
则rank-1的正确率为(1+1+1)/3=100%;rank-2的正确率也为(1+1+1)/3=100%;rank-5的正确率也为(1+1+1)/3=100%
rank-1 = (1号第一个位置的识别结果是否为m1,2号第一个位置的识别结果是否为m2....) / 待识别的label个数 = (有,有,有) / 3 = (1+1+1) / 3
如果1号识别结果是m4、m2、m3、m5、m6……
如果2号识别结果是m1、m2、m3、m4、m5……
如果3号识别结果是m3、m1、m2、m4、m5……
则rank-1的正确率为(0+0+1)/3=33.33%;rank-2的正确率为(0+1+1)/3=66.66%;rank-5的正确率也为(0+1+1)/3=66.66%
rank-2= (1号前2个位置的识别结果是否有m1,2号结果的前2个位置是否有m2....) / 待识别的label个数 = (没有,有,有) / 3 =(0 + 1 + 1)/ 3
