Facebook Haystack图片存储架构
A- A+
2013-10-28 18:33|
分享到:
OSDI 10中有一篇Facebook图片存储系统Haystack的论文,名称为”Finding a needle in Haystack: Facebook’s photo storage”。从这篇论文可以看出,数据量大的应用有时也并不复杂。
我们先给Facebook图片存储系统算一笔账。Facebook目前存储了260 billion图片,总大小为20PB,通过计算可以得出每张图片的平均大小为20PB / 260GB,约为800KB。用户每周新增图片数为1 billion (总大小为60TB),平均每秒钟新增的图片数为10^9 / 7 / 40000 (按每天40000s计),约为每秒3500次写操作,读操作峰值可以达到每秒百万次。另外,图片应用的特点是写一次以后图片只读,图片可能被删除但不会修改。
图片应用系统有两个关键点:
1, Metadata信息存储。由于图片数量巨大,单机存放不了所有的Metadata信息,假设每个图片文件的Metadata占用100字节,260 billion图片Metadata占用的空间为260G * 100 = 26000GB。
2, 减少图片读取的IO次数。在普通的Linux文件系统中,读取一个文件包括三次磁盘IO:读取目录元数据到内存,把文件的inode节点装载到内存,最后读取实际的文件内容。由于文件数太多,无法将所有目录及文件的inode信息缓存到内存,因此磁盘IO次数很难达到每个图片读取只需要一次磁盘IO的理想状态。
3, 图片缓存。图片写入以后就不再修改,因此,需要对图片进行缓存并且将缓存放到离用户最近的位置,一般会使用CDN技术。
Facebook图片系统初期的架构如下:
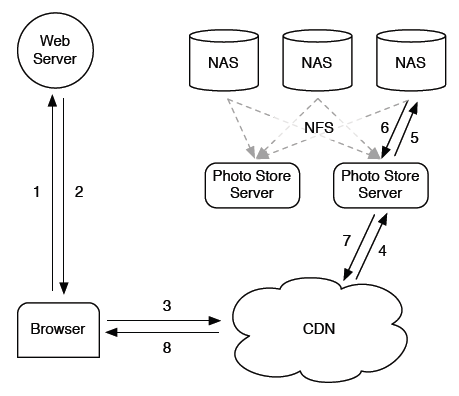
这个架构采用CDN作为图片缓存,底层使用基于NAS的存储,Photo Store Server 通过NFS挂载NAS中的图片文件提供服务。用户的图片请求首先调度到最近的CDN节点,如果CDN缓存命中,直接将图片内容返回用户;否则CDN请求后端的存储系统,缓存并将图片内容返回用户。Facebook的经验表明,SNS社交网站中CDN缓存的效果有限,存在大量的”长尾”请求。虽然user profile图片请求的CDN命中率高达99.8%,但是其它图片请求CDN命中率只有92%,大约1/10的请求最后落到了后端的存储系统。这个架构的问题如下:
1, 图片存储的IO次数过多。这个架构没有解决图片物理文件个数太多的问题,因此,无法将目录和文件的inode信息全部装载到内存中,且后端存储系统的访问比较分散,很难缓存,每次图片读取需要多次(一般为3次)IO操作。
2, 依赖于CDN提供商。Facebook使用Akamai & Limelight的CDN服务,不可控因素较多,成本也比较高。
Facebook Haystack新架构主要解决图片存取IO次数过多的文件,主要的思路是多个逻辑文件共享同一个物理文件。Haystack架构及读请求处理流程图如下:
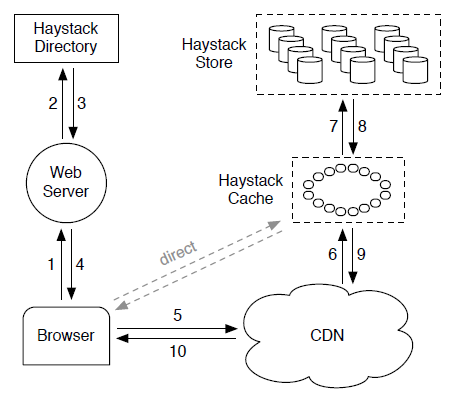
Haystack架构主要有三个部分:Haystack Directory,Haystack Store以及Haystack Cache。Haystack Store是物理存储节点,以物理卷轴(physical volume)的形式组织存储空间,每个物理卷轴一般很大,比如100GB,这样10TB的数据也只有100个物理卷轴。每个物理卷轴对应一个物理文件,因此,每个存储节点上的物理文件元信息都很小。多个物理存储节点上的物理卷轴组成一个逻辑卷轴(logical volume),用于备份。Haystack Directory存放逻辑卷轴和物理卷轴的对应关系,假设每个卷轴的大小为100GB,对应关系的条数为20PB / 100GB = 0.2MB,占用的内存可以忽略。Haystack cache主要用于解决对CDN提供商过于依赖的问题,提供最近增加的图片的缓存服务。
Haystack图片读取请求大致流程为:用户访问一个页面时,Web Server请求Haystack Directory构造一个URL:http:// / / / ,后续根据各个部分的信息依次访问CDN,Cache和后端的Haystack Store存储节点。Haystack Directory构造URL时可以省略 部分从而使得用户直接请求Haystack Cache而不必经过CDN。Haystack cache收到的请求包含两个部分:用户Browser的请求及CDN的请求,Haystack cache只缓存用户Browser发送的请求且要求请求的Haystack Store存储节点是可写的。一般来说,Haystack Store的存储节点写一段时间以后达到容量上限变为只读,因此,可写节点的图片为最近增加的图片,是热点数据。
Haystack的写请求(图片上传)处理流程为:Web Server首先请求Haystack Directory获取图片的id和可写的逻辑卷轴,接着将数据写入对应的每一个物理卷轴(备份数一般为3)。
Haystack Directory
Haystack Directory的功能如下:
1, 提供逻辑卷轴到物理卷轴的映射,为写请求分配图片id;
2, 提供负载均衡,为写操作选择逻辑卷轴,读操作选择物理卷轴;
3, 屏蔽CDN服务,可以选择某些图片请求直接走Haystack Cache;
4, 标记某些逻辑卷轴为read-only;
根据前面的计算结果,Facebook图片系统每秒的写操作大约为3500,每秒的读请求大约为100万。每个写请求都需要通过Haystack Directory分配图片id并获取可写的卷轴,每个读请求需要通过Haystack Directory查找图片所属的物理卷轴。这里需要注意,图片id到逻辑卷轴的映射的数据量太大,单机内存无法存放,可以推测存放在外部的Mysql Sharding集群中,图片系统的读取操作同时带有图片id和逻辑卷轴两个参数。
Haystack Directory的实现较为简单,采用Replicated Database做持久化存储,前面增加一个Memcache集群满足查询需求。
Haystack Store
Haystack Store存储物理卷轴,每个物理卷轴对应文件系统中的一个物理文件,每个物理文件的格式如下:
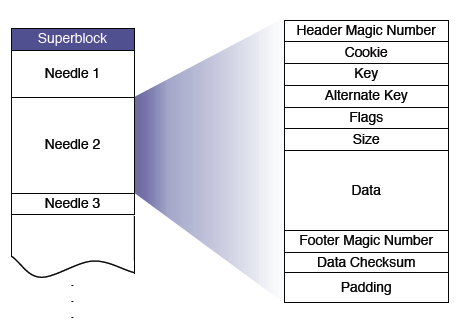
多个图片文件存放在一个物理卷轴中,每个图片文件是一个Needle,包含实际数据及逻辑图片的元数据。部分元数据需要装载到内存中用于图片查找,包括Key(图片id,8字节), Alternate Key(图片规格,包括Thumbnail, Small, Medium及Large,4字节),图片在物理卷轴的偏移Offset(4字节),图片的大小Size(4字节),每张图片占用8 + 8 + 4 = 20字节的空间,假设每台机器的可用磁盘为8TB,图片平均大小为800KB,单机存储的图片数为8TB / 800KB = 10MB,占用内存200MB。
存储节点宕机时,需要恢复内存中的图片查找元信息表,扫描整个物理卷轴耗时太长,因此,对每个物理卷轴维护了一个索引文件(Index File),保存每个Needle查找相关的元数据。写操作首先更新物理卷轴文件,然后异步更新索引文件。由于更新索引文件是异步的,可能出现索引文件和物理卷轴文件不一致的情况,不过由于对物理卷轴文件和索引文件的操作都是Append操作,只需要扫描物理卷轴文件最后写入的几个Needle补全索引文件即可。这种技术在Append-only的文件系统很常见。
Haystack Store存储节点采用延迟删除的回收策略,删除图片仅仅往卷轴中追加一个带有删除标记的Needle,定时执行Compaction任务回收已删除空间。
异常处理
可能出现的异常包括:
1, Haystack Store存储节点宕机:存储节点宕机时,存储节点上的未完成的写操作全部失败,客户端将重试;如果宕机的存储节点不可恢复,需要执行一个拷贝任务,从相应的备份机器上拷贝丢失的物理卷轴数据;由于物理卷轴一般很大,比如100GB,所以拷贝的过程会很长,一般为小时级别。
2, 写操作失败:客户端需要写逻辑卷轴对应的多个物理卷轴,所有备份全部写成功才算成功,否则不断重试。同一个物理卷轴可能多次写入同一个图片,类似GFS中的重复记录:对于每个成功的写操作,Haystack Store只需要保证每个物理卷轴至少写成功一次即可,Haystack Store存储节点对记录去重。
与其它系统的比较
Taobao TFS及CDN系统:Facebook Haystack和Taobao TFS都是解决大量的小图片文件的问题,因此架构很类似,不同点包括逻辑卷轴大小的选择,比如Haystack选择100GB的逻辑卷轴大小,TFS中block大小一般为64MB;Haystack使用RAID 6,且底层文件系统使用性能更好的XFS,淘宝后期摈除了RAID机制,文件系统使用Ext3;Haystack使用了Akamai & Limelight的CDN服务,而Taobao已经使用自建的CDN,当然,Facebook也在考虑自?DN。Facebook Haystack及Taobao TFS这样的文件系统一般称为Blob文件系统。
GFS系统:Haystack Store的每个存储节点相当于一个Chunk Server,物理卷轴相当于一个Chunk。Haystack Directory相当于GFS Master。GFS系统的难点在于Append流程及动态分配Chunk的写Lease,而在Haystack这样的Blob系统中可以回避这样的问题,后续将专门详细论述Blob文件系统和GFS的差别。