决策树使用与原理
目录
声明决策树
数据加载
训练
画图
深度为1,叶子节点不算深度
标准差:
gini
导包
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn import tree
from sklearn.model_selection import train_test_split声明决策树
clf = DecisionTreeClassifier(criterion='entropy')#参数使用熵
数据加载
iris = datasets.load_iris()#加载鸢尾花
X = iris['data']#特征值
y = iris['target']#目标值
feature_names = iris.feature_names
#固定random_state后,每次构建的模型是相同的、生成的数据集是相同的、每次的拆分结果也是相同的。
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state = 1024)训练
# 数据清洗,花时间
# 特征工程
# 使用模型进行训练
# 模型参数调优
# sklearn所有算法,封装好了
# 直接用,使用规则如下
clf.fit(X_train,y_train)
y_ = clf.predict(X_test)
from sklearn.metrics import accuracy_score #导包
accuracy_score(y_test,y_)#求准确率![]()
画图
plt.figure(figsize=(18,12))
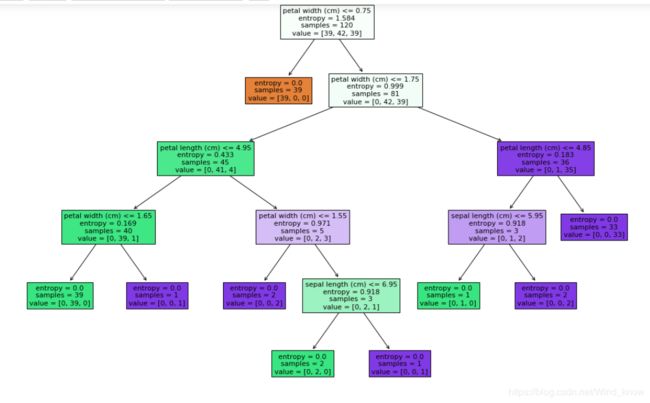
_=tree.plot_tree(clf,filled=True,feature_names=feature_names)样本0:39个,样本1: 42个 ,样本2: 39个。
plt.figure(figsize=(12,9))
_ = tree.plot_tree(clf,filled = True,feature_names=feature_names,max_depth=1深度为1,叶子节点不算深度

%%time
# 树的深度变浅了,树的裁剪
clf = DecisionTreeClassifier(criterion='entropy',max_depth=5)
clf.fit(X_train,y_train)
y_ = clf.predict(X_test)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,y_))
plt.figure(figsize=(18,12))
_ = tree.plot_tree(clf,filled=True,feature_names = feature_names)![]()
标准差:
标准差越大,波动越大,越能够分开。
# 连续的,continuous 属性 阈值 threshold
X_train
# 波动程度,越大,离散,越容易分开
X_train.std(axis = 0)![]()
列分

np.sort(X_train[:,2])
gini
%%time
# 树的深度变浅了,树的裁剪
clf = DecisionTreeClassifier(criterion='gini',max_depth=5)
clf.fit(X_train,y_train)
y_ = clf.predict(X_test)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,y_))
plt.figure(figsize=(18,12))
_ = tree.plot_tree(clf,filled=True,feature_names = feature_names)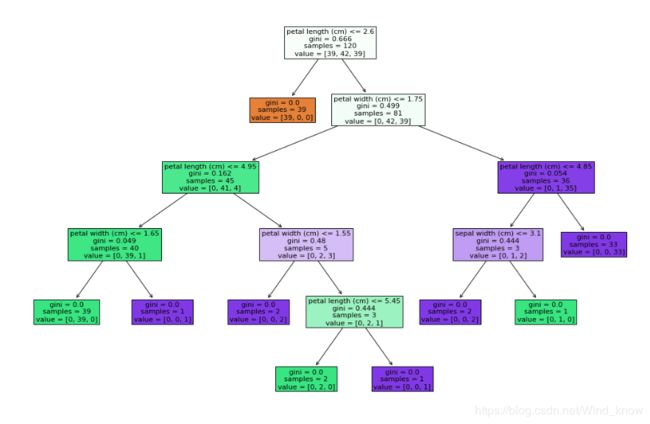
# 39 42 39
39/120*(1 - 39/120)*2 + 42/120*(1 - 42/120)=0.66625 系统越纯,基尼系数就越小。
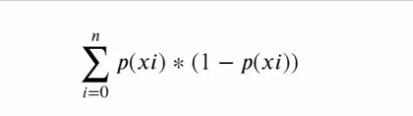
# 1.0 其余都是0
# 百分之百纯
gini = 1*(1-1)
gini
决策树模型,不需要对数据进行去量纲化,规划化,标准化。公司应用中,不用决策树,太简单
决策树升级版:集成算法(随机森林,(extrem)极限森林,梯度提升树,adaboost提升树)