Python网络爬虫实战之Fiddler抓包今日头条app!附代码
一、Fiddler介绍
1.Fiddler简介
Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件)。Fiddler 要比其他的网络调试器要更加简单,因为它不仅仅暴露http通讯还提供了一个用户友好的格式。
通俗来讲,Fiddler 的工作原理相当于一个代理,配置好以后,我们从手机 App 发送的请求会由 Fiddler 发送出去,服务器返回的信息也会由 Fiddler 中转一次。所以通过 Fiddler 我们就可以看到 App 发给服务器的请求以及服务器的响应了。
2.FiddlerPC端配置
我们安装好 Fiddler 后,首先在菜单 Tool>Options>Https 下面的这两个地方选上。

然后在 Connections 标签页下面勾选上 Allow remote computers to connect,允许 Fiddler 接受其他设备的请求。

同时要记住这里的端口号,默认是 8888,到时候需要在手机端填。配置完毕,保存后,一定关掉 Fiddler 重新打开。
3.Fiddler手机端配置
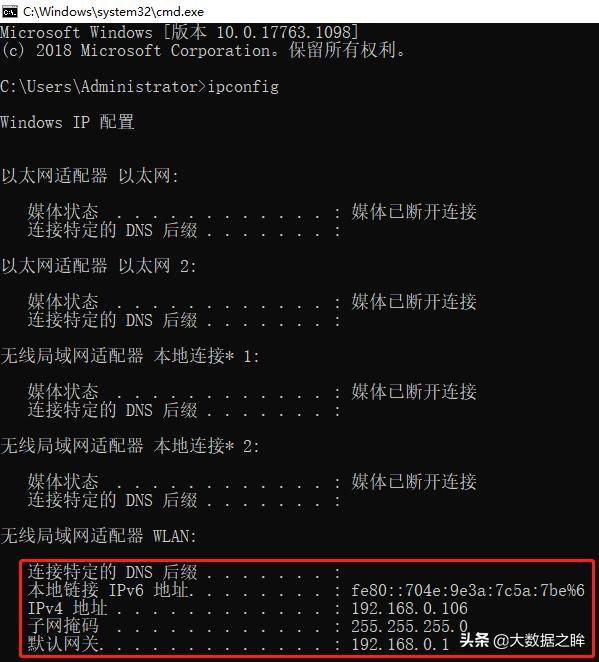
首先按win+R键输入cmd打开,输入命令ipconfig查看IP地址:
打开手机无线连接,选择要连接的热点。长按选择修改网络,在代理中填上我们电脑的 IP 地址和 Fiddler 代理的端口。如下图所示:


保存后,在手机默认浏览器(即手机自带浏览器)中打开上文查询到的ip地址http://192.168.0.106:8888(视自身情况而定)。
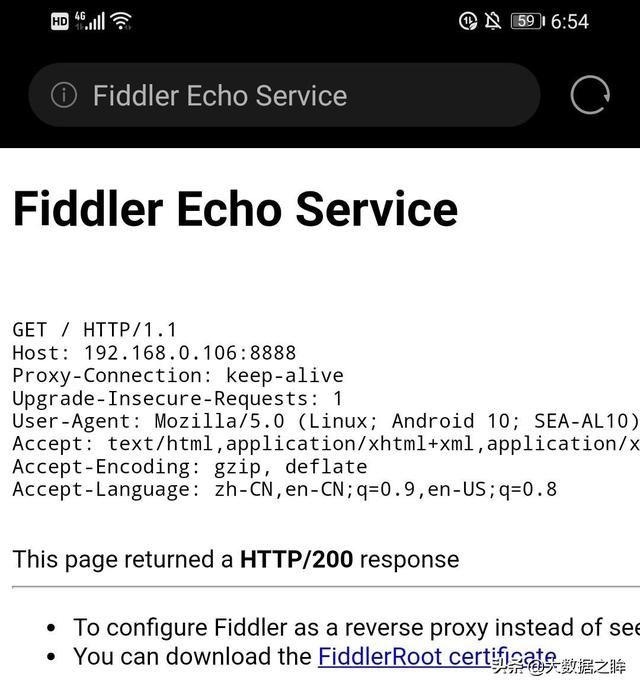
之后点击上述蓝色链接并安装到手机就可以进一步的使用电脑代理监控了。

二、今日头条app抓包实战
1.源代码获取
首先我们在上述配置环境下打开手机今日头条app,并搜索“疫情”:

之后可在Fildder中观察到弹出诸多条目,通过查看和经验筛选发现带有search的url即为我们所求,双击这条URL,可以进一步获取到requests url和client(即我们的客户端请求头)
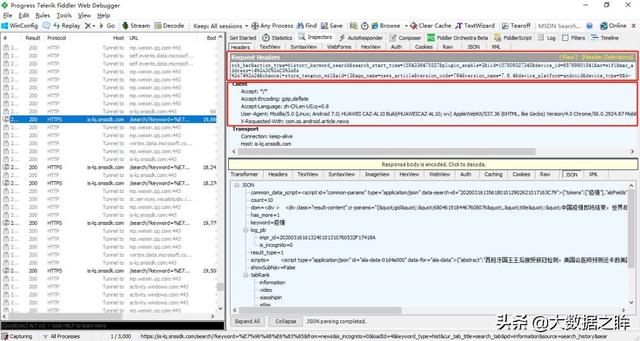
略微梳理一下就可以得到当前请求的代码:
import requests
import time
from bs4 import BeautifulSoup
import pandas as pd
import json
import random
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
head = {
'Accept': '*/*',
'Accept-Encoding': 'gzip,deflate',
'Accept-Language': 'zh-CN,en-US;q=0.8',
'User-Agent': 'Mozilla/5.0 (Linux; Android 7.0; HUAWEI CAZ-AL10 Build/HUAWEICAZ-AL10; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/56.0.2924.87 Mobile Safari/537.36 JsSdk/2 NewsArticle/7.0.1 NetType/wifi',
'X-Requested-With': 'com.ss.android.article.news'
}
url = "https://is-lq.snssdk.com/search/?keyword=..."
req = requests.get(url=url, headers=head,verify=False).json()2.json提取
接下来我们的任务就在于分析响应的json文件,通过req.keys()命令获取键信息,注意查找,发现在key为scripts的value中包含文章的所有信息,而值为Javascript代码字符串,因此通过Beautiful库进行解析:
soup = BeautifulSoup(req['scripts'],"lxml")
contents = soup.find_all('script',attrs={"type":"application/json"})
res = []
for content in contents:
js = json.loads(content.contents[0])
abstract = js['abstract']
article_url = js['article_url']
comment_count = js['comment_count']
raw_title = js['display']['emphasized']['title']
title = raw_title.replace("","").replace("","")
source = js['display']['emphasized']['source']
data = {
'title':title,
'article_url':article_url,
'abstract':abstract,
'comment_count':comment_count,
'source':source
}
res.append(data)3.信息存储
在相关文章信息提取完之后即可选择信息存储方式,我们通常采用json、csv、xlsx等格式进行存储:
def write2excel(result):
json_result = json.dumps(result)
with open('article.json','w') as f:
f.write(json_result)
with open('article.json','r') as f:
data = f.read()
data = json.loads(data)
df = pd.DataFrame(data,columns=['title','article_url','abstract','comment_count','source'])
df.to_excel('article.xlsx',index=False)4.自动化爬虫构建
最后一步,也就是找到翻页规律,完成自动化爬虫构建。我们在搜索出的结果页依次用手向下滑动,发现继续弹出search的url,观察下图:
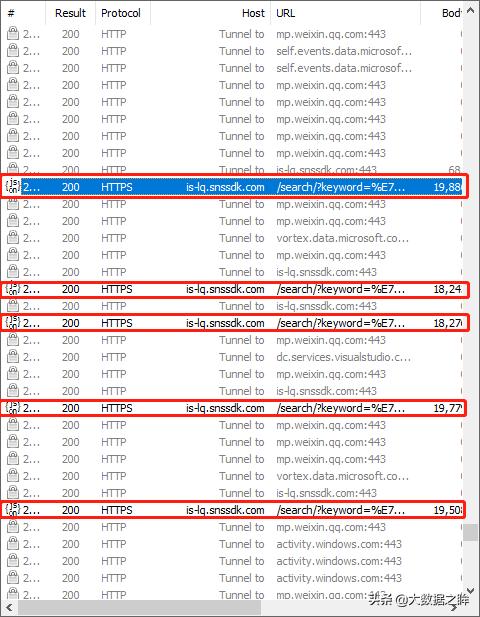
观察这些url,发现仅仅在offset这个参数有所区别,而且是10的倍数,因此我们的翻页循环代码为:
def get_pages(keyword,page_n):
res_n = []
for page_id in range(page_n):
page = get_one_page(keyword = keyword,offset = str(page_id*10))
res_n.extend(page)
time.sleep(random.randint(1,10))
return res_n三、爬虫总结
至此利用Fildder软件结合python程序很容易的构建了手机端app爬虫程序,再通过此爬虫总结一下:首先我们先安装好Fildder软件,并且同时配置好PC端和手机端代理,之后通过在手机上操作反馈到电脑端Fildder查看结果;进而通过Fildder抓包结果判断请求具体参数和数据格式,之后对响应的数据进行进一步的加工和存储就ok了。结果如下:
