iOS性能优化系列篇之“列表流畅度优化”工具篇
这一篇文章是iOS性能优化系列文章的的第二篇,主要内容是关于列表流畅度的优化。在具体内容的阐述过程中会结合性能优化的总体原则进行分析,所以建议大家在阅读这篇文章前先阅读一下上一篇文章:iOS性能优化系列篇之“优化总体原则”。 希望后面有时间把这个系列更新下去,包括内存等其他方面的专项优化内容。希望这篇文章能够给大家在列表流畅度优化方面带来一点点启示。
和上一篇综述性质的文章不同,这一篇文章工程实用性更强一些,更多的是一些优化技术细节。文中讨论了许多可能影响列表流畅度的因素,由于2018 WWDC里面讲述了大量的关于性能优化相关的内容,因此本文也在相关的内容里面加入2018 WWDC的性能优化部分。
读者可将本体提及的优化手段或者原理应用到自己的项目中去。但是希望大家在优化过程中,要结合自己的项目具体问题具体分析,因为本文讨论的影响流畅度的因素,可能并不是你的应用流畅性不佳的瓶颈,根据我的经验,大部分流畅的问题都是业务逻辑导致的,反倒什么离屏渲染啊之类大家耳熟能详的流畅度的影响因素在实际项目中并没有想象的那么大。如果不经实地测量就盲目应用一些优化手段,可能会导致过度优化,事倍功半。
卡顿产生的原因
在总体原则篇中提到,五大原则中的其中一个就是要理解优化任务的底层运行机制,因为只有深入了解底层机制才能更好的有针对性的提出更优的解决方案,所以在进行列表流畅度优化前,我们一定要弄清楚一个view从创建到显示到屏幕上都经历了那些过程,在这些过程中那些方面可能会导致性能瓶颈,以及造成卡顿的底层原因是什么。
我们知道iOS设备大部分情况下,屏幕刷新频率是60hz(ProMotion下是120hz),也就是每隔16.67ms会进行一次屏幕刷新。每次刷新时,需要CPU和GPU配合完成一次图像显示。其主要流程如下:
应用内:
-
布局。CPU创建view,设置其属性(frame、background color等等)
-
创建backing images。setContents将一个image传給layer或者通过 drawRect:或 drawLayer:inContext绘制
-
准备。Core Animation将layer发送到render server前的一些准备工作,比如图片解码等。
-
提交。Core animation将layers打包通过 IPC (Inter-Process Communication) 发送到render server
应用外(render server):
-
设置用来渲染的OpenGL triangles(如果是有动画,还需计算动画layer的属性的中间值)。
-
渲染这些可见的triangles,将结果提交到视频缓冲区
-
视频控制器以60hz频率读取缓冲区内容显示到显示器,如果在16.67ms内没有完成提交,则会被丢弃。
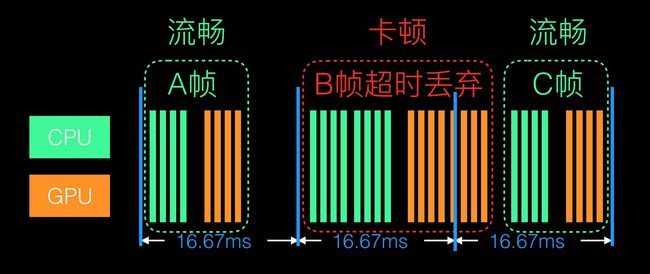
从上面的图中可以看到,在view显示的过程中,CPU和GPU都各自承担了不同的任务,CPU和GPU不论哪个阻碍了显示流程,都会造成掉帧现象。所以优化方法也需要分别对CPU和GPU压力进行评估和优化,在CPU和GPU压力之间找到性能最优的平衡点, 无论过度优化哪一方导致另一方压力过大都会造成整体FPS性能的下降。而寻找平衡点的过程则因项目特点不同而不同,并没有一套通用的方法,需要我们用instrument等性能评测工具,根据实际app的性能度量结果去做优化,不能凭空乱猜。
CPU优化
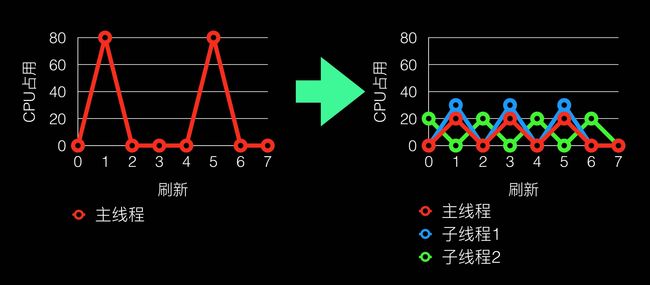
我们先看table view在滑动过程中CPU占用的情况。

从上图可以看出,在滑动过程中CPU占用特点是:
-
滑动时CPU占用率高、空闲时CPU占用率底
-
主线程CPU占用高、子线程CPU占底
根据上述特点我们可以做如下优化:
预加载,空间换时间
为什么要预加载:
-
滑动时CPU占用过高,16.67ms内无法完成内容提交—>导致卡顿
-
滑动时CPU占用率高,但空闲时CPU占用率底—>CPU占用分布特点
-
利用CPU空闲时间预加载,降低滑动时CPU占用峰值—>解决卡顿
通过预加载我们希望达到的CPU理想占用效果如下:
预加载内容:
静态资源预加载
-
如何预加载:创建列表前找时机加载。如启动时、viewDidLoad、runloop空闲时等等
-
加载内容:缓存在磁盘的网络数据、图片、其他滑动时需要的耗时的资源
-
注意事项:在预加载带来的滑动性能提升和内存占用增加之间权衡
动态资源预加载
如何预加载:
在iOS10以后,UITableView和UICollectionView提供了预加载机制,iOS12开始prefeatching做了优化,不再与cell的加载同时并发进行,而是cell加载完成之后串行开始prefeatch,从而优化了流畅度
iOS10以前,也可以自己实现类似机制,主要利用的机制有:
-
UIScrollViewDelegate 提供滑动开始、结束、速度时机回调
-
indexPathsForRowsInRect 和layoutAttributesForElementsInRect 提供预加载的indexPath
-
可根据滑动速度动态调整加载的量
加载内容:
-
Cell的高度、subView的布局计算
-
拉取网络数据
-
网络图片
-
其他耗时的资源
注意事项:
-
在预加载带来的滑动性能提升和内存占用增加之间权衡
-
注意数据过期的问题
WWDC 2018中讲到了一个iOS12的底层优化点,苹果工程师在性能调优的时候发现一个导致丢帧的奇怪case,在没有其他后台线程运行、只有滑动的情况下,会比有少量的后台线程的情况更容易掉帧。通过调研CPU的调度算法发现,在仅有滑动的情况下,为了省电,CPU占用会保持比较底,但是这样CPU会花更多的时间来计算,就会导致可能错过这一帧。所以iOS12中,会把UIKit框架上所有的信息(滑动信息以及滑动frame的关键时间点)传递给底层CPU性能控制器,这样CPU可以更智能调度以在frame截止的时机内完成CPU计算。这部分属于系统底层的优化,对于应用开发者只要应用运行在iOS12就可以获得这部分优化。
多线程
为什么要多线程:
-
UIKit 大部分API只能在主线程调用, 特别是一些耗时的操作,如view的创建,布局和渲染默认都是在主线程上完成
-
主线程任务过多,16.67ms内无法完成,导致卡顿
-
将非主线程必须的任务,移到子线程中,减轻主线程负担
-
多核处理器,多线程可以发挥多核并发优势,提高性能
最终通过多线程,我们希望CPU占用达到如下效果:
使用多线程注意事项:
-
主线程最大程度上减少非主线程必须的任务
-
控制子线程数量在合理的范围内,防止线程爆炸,一定要根据项目实际CPU占用特点,有针对的使用多线程。
可在子线程中进行的任务
-
图片解码
-
文本渲染,UILabel和UITextview都是在主线程渲染的,当显示大量文本时,CPU的压力会非常大。特别是对于一些资讯类应用,这部分耗时相当大,对流畅度的影响也十分明显。对此可以自定义文本控件,用TextKit或最底层的CoreText对文本异步绘制。尽管这实现起来非常麻烦,但其带来的优势也非常大,CoreText对象创建好后,能直接获取文本的宽高等信息,避免了多次计算(调整 UILabel 大小时算一遍、UILabel 绘制时内部再算一遍);CoreText对象占用内存较少,可以缓存下来以备稍后多次渲染。用 [NSAttributedString boundingRectWithSize:options:context:] 来计算文本宽高,用 -[NSAttributedString drawWithRect:options:context:] 来绘制文本。尽管这两个方法性能不错,但仍旧需要放到后台线程进行以避免阻塞主线程。
-
UIView的drawRect, 由于 CoreGraphic 方法通常都是线程安全的,所以图像的绘制可以很容易的放到后台线程进行
-
耗时的业务逻辑
缓存
缓存的内容可以是
-
UIView。 view的创建代价很大,一些可以复用的view可以cache。例如UITableView为我们实现的了cell的复用。
-
图片。 图片涉及磁盘IO和解码,十分耗时,可以考虑缓存。
-
布局。其实不仅仅是cell的高度可以缓存,如果cell里面有大量的文字图片等复杂元素,cell的subView的布局也可以在第一次计算好,用Model的key来缓存。避免频繁多次的调整布局属性。在滑动列表(UITableView和UICollectionView)中强烈不建议使用Autolayout。随着视图数量的增长,Autolayout带来的 CPU 消耗会呈指数级上升。
-
数据, 网络拉取的数据或者db中的数据
-
其他创建耗时,可重复利用的资源。 如NSDateFormatter等
更优的实现方式
这里说的更优的实现方式,主要是指为了实现同一功能或者效果,CPU占用更小的实现方式。这部分包括的内容其实非常多,也很杂。受限于篇幅和水平有限,这里笔者仅罗列一些比较常见的点,并针对其中比较重要的drawRect优化和图片优化内容做进一步的讲解。
-
drawRect优化
-
图片优化
-
算法的时间复杂度优化。我们知道算法的时间复杂 O(1) < O(log n) < O (n) < O(n^2)... 大家可能觉得iOS开发过程中使用的算法并不多,算法对性能影响并不明显。其实不然,举iOS中的一个例子:IGListDiff采用空间换时间的方式,使得比较的算法复杂度从 O(n^2) 变成 O(n)。IGListKit-diff-实现简析 。还比如不同容器的选择,会带来不同的查找、插入、删除的时间复杂度,在大的数据量下也会带来不同的性能表现。
-
storyboard VS 代码创建view
-
frame VS autolayout autolayout性能度量,iOS12优化了autolayout的性能,耗时由指数变为线性耗时,
-
UIView VS CAlayer 后者更轻量,在不需要处理触摸事件的场景可以考虑使用CAlayer。UIView层级太多,会导致创建、布局等较耗时,可以尽量扁平化,甚至可以异步在子线程画到一个Image上。
-
UIImageView animationImages VS CAAnimation
-
NSDateFormatter dateFromString VS NSDate dateWithTimeIntervalSince1970:
-
更优的业务逻辑。大家平时在性能优化的时候,已经要优先去排查业务逻辑这块,仔细梳理。个人经验很多性能问题都是由不合理的业务逻辑导致的。使用Instruments的time profiler工具仔细观察耗时的业务逻辑,做好梳理和优化工作。
-
其他
下面详细讲下drawRect优化和图片优化
drawRect优化
首选使用CAShapeLayer替代drawRect,在大多数场景下,都可以使用CAShapeLayer替代drawRect。二者对比:
-
CAShapeLayer使用GPU硬件加速,更快。GPU对高度并行的浮点运算做了优化。而drawRect使用CPU绘图,相比之下会很慢,而且十分耗CPU
-
CAShapeLayer占用内存更少。因为不会创建寄宿图,因此无论多大都不会占用太多内存。而drawRect图层每次重绘的时候都需要重新抹掉内存然后重新分配,十分占用内存。详见内存恶鬼drawRect
-
CAShapeLayer不会被图层边界剪裁掉
-
CAShapeLayer不会出现像素化,通过矢量图绘制而不是bitmap
-
CAShapeLayer有很多属性可以方便的做动画,比如使用strokeStart和strokeEnd可以做出了很漂亮的动画
异步绘制。可以使用异步绘制的方式,在子线程绘制好获得image,然后交给主线程。
Dirty Rectangles: 可以使用setNeedsDisplayInRect标记Dirty Rectangles,仅重绘指定区域,也会极大提升性能。
图片优化
在大多数app中,图片绝对是使用最频繁的资源之一,我们知道磁盘和网络的加载速度和内存比要慢很多,而一般图片都比较大,I/O十分耗时。而且图片还涉及解码,也是一项十分消耗CPU的工作,因此图片的优化对app的性能有着十分关键的作用。
在之前将的优化总体原则的时候,我们说过需要理解优化对象的运行机制,我们先了解下图片显示原理:
-
从磁盘或者网络加载一张图片,此时图片未解码
-
图片赋值给UIImageView
-
在主线程中解码,非常耗时的 CPU 操作
-
CATransaction捕捉到layer tree的变化
-
在main run loop, 提交transaction:
如果图片数据没对齐,Core Animation会拷贝一份数据,进行字节对齐
GPU处理位图数据,进行渲染
针对上面的过程,我们的优化手段主要有:
-
异步下载/读取图片,这样可以防止这项十分耗时的操作阻塞主线程。
-
预处理图片大小。如果UIImage大小和UIImageview的size不同的话,CPU需要提前预处理,这是一项十分消耗CPU的工作,特别是在一些缩略图的场景下,如果使用了十分大的图片,不仅会带来很大的CPU性能问题,还会导致内存问题。我们可以用instruments Core Animation 的Misaligned Image debug选项来发现此问题。这里可以使用ImageIO中的CGImageSourceCreateThumbnailAtIndex等相关方法进行后台异步downsample,可以在CPU和内存上获得很好的性能。
-
UIImageView frame取整。视图或图片的点数(point),不能换算成整数的像素值(pixel),导致显示视图的时候需要对没对齐的边缘进行额外混合计算,影响性能。借助ceilf()、floorf()、CGRectIntegral()等将小数点后数据除去即可。我们可以用instruments Core Animation 的Misaligned Image debug选项来发现此问题
-
使用mmap,避免mmcpy。解码图片 iOS从磁盘加载一张图片,使用UIImageVIew显示在屏幕上,需要经过以下步骤:从磁盘拷贝数据到内核缓冲区、从内核缓冲区复制数据到用户空间。使用mmap内存映射,省去了上述第2步数据从内核空间拷贝到用户空间的操作,具体可以参考FastImageCache的实现
-
子线程解码。如果我们使用imgView.image = img; 如果图片没有解码,则会在主线程进行解码等操作,会极大影响滑动的流畅性。
-
字节对齐,如果数据没有字节对齐,Core Animation会再拷贝一份数据,进行字节对齐,也是十分消耗CPU。
-
iOS 12引入了Automatic Backing Store这项技术。通过在保证色彩不失真的基础上,使用更少的数据量,去表达一个像素的颜色。在UIView.draw()、UIGraphicsImageRenderer、UIGraphicsImageRenderer.Range中是默认开启的。其实我们自己可以针对图片的特点,采用更少的byte来标示一个像素占用的空间,FastImageCache就是使用这种优化手段,有兴趣的读者可以去了解一下。
-
我们日常开发中可以使用一些比较经典的图片缓存库,比如SDWebImage、 FastImageCache、YYImage等。这些第三方库替我们完成的大部分优化的工作,而且接口也十分友好。我们可也使用这些第三方库帮助我们获得更好的性能体验。
GPU优化
CPU和GPU之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。所以CPU擅长逻辑控制,串行的运算。和通用类型数据运算不同,GPU擅长的是大规模并发计算,这也正是密码破解等所需要的。所以GPU除了图像处理,也越来越多的参与到计算当中来。
iOS中GPU在显示方面的工作主要是:接收提交的纹理(Texture)和顶点描述(三角形),进行变换(transform)、混合并渲染,然后输出到屏幕上。屏幕上的内容,主要也就是纹理(图片)和形状(三角模拟的矢量图形)两类。一般来说,CALayer的大多数属性都是使用GPU来绘制的。虽然GPU在处理图像等渲染是速度很快,但如果开发过程中使用不当,仍会导致GPU占用过高,渲染速度跟不上屏幕刷新导致卡顿。
对GPU消耗比较高的操作有:
纹理的渲染
所有的 Bitmap,包括图片、文本、栅格化的内容,最终都要由内存提交到显存,绑定为 GPU Texture。不论是提交到显存的过程,还是 GPU 调整和渲染 Texture 的过程,都要消耗不少 GPU 资源。当在较短时间显示大量图片时(比如 TableView 存在非常多的图片并且快速滑动时),CPU 占用率很低,GPU 占用非常高,界面仍然会掉帧。避免这种情况的方法只能是尽量减少在短时间内大量图片的显示,尽可能将多张图片合成为一张进行显示。
当图片过大,超过 GPU 的最大纹理尺寸时,图片需要先由 CPU 进行预处理,这对 CPU 和 GPU 都会带来额外的资源消耗。目前来说,iPhone 4S 以上机型,纹理尺寸上限都是 4096x4096,更详细的资料可以看这里:iosres.com。所以,尽量不要让图片和视图的大小超过这个值。
视图的混合 (Composing)
当多个视图(或者说 CALayer)重叠在一起显示时,GPU 会首先把他们混合到一起。如果视图结构过于复杂,混合的过程也会消耗很多 GPU 资源。为了减轻这种情况的 GPU 消耗,应用应当尽量减少视图数量和层次,并在不透明的视图里标明 opaque 属性以避免无用的 Alpha 通道合成。当然,这也可以用上面的方法,把多个视图预先渲染为一张图片来显示。
图形的生成
CALayer 的 border、圆角、阴影、遮罩(mask),CASharpLayer 的矢量图形显示,通常会触发离屏渲染(offscreen rendering),而离屏渲染通常发生在 GPU 中。当一个列表视图中出现大量圆角的 CALayer,并且快速滑动时,可以观察到 GPU 资源已经占满,而 CPU 资源消耗很少。这时界面仍然能正常滑动,但平均帧数会降到很低。为了避免这种情况,可以尝试开启 CALayer.shouldRasterize 属性,但这会把原本离屏渲染的操作转嫁到 CPU 上去。对于只需要圆角的某些场合,也可以用一张已经绘制好的圆角图片覆盖到原本视图上面来模拟相同的视觉效果。最彻底的解决办法,就是把需要显示的图形在后台线程绘制为图片,避免使用圆角、阴影、遮罩等属性。
常用优化手段
-
减少视图数量和层次,可把多个视图预先渲染为一张图片
-
不要让图片和视图超过GPU可渲染的最大尺寸
-
视图不透明
-
防止离屏渲染 OpenGL 中,GPU 屏幕渲染有以下两种方式:
On-Screen Rendering 意为当前屏幕渲染,指的是 GPU 的渲染操作是在当前用于显示的屏幕缓冲区中进行。
Off-Screen Rendering 意为离屏渲染,指的是 GPU 在当前屏幕缓冲区以外新开辟一个缓冲区进行渲染操作。
相比于当前屏幕渲染,离屏渲染的代价是很高的,主要体现在两个方面:
创建新缓冲区 要想进行离屏渲染,首先要创建一个新的缓冲区。
上下文切换 离屏渲染的整个过程,需要多次切换上下文环境:先是从当前屏幕(On-Screen)切换到离屏(Off-Screen);等到离屏渲染结束以后,将离屏缓冲区的渲染结果显示到屏幕上有需要将上下文环境从离屏切换到当前屏幕。而上下文环境的切换是要付出很大代价的。
所以在图形生成的步骤我们要尽可能的避免离屏渲染
优化工具
iOS开发中,在GPU优化上,我们一般使用instruments中的Core Animation工具来进行滑动流畅度优化,在Core Animation中我们可也看到列表滑动过程中的FPS,其中有一些很有用的debug选项,帮助我们找到代码中有性能问题的代码。下面是一些常用的选项:
Color Blended Layers
Color Blended Layers是用来检测个半透明图层的混合区,渲染程度对屏幕中的混合区域进行绿到红的高亮。因为计算混合区的颜色时,导致overdraw,消耗一定的GPU资源,是导致滑动性能的一个因素。所以尽量要尽量避免
在开发过程中,避免Blended Layers的手段有
-
设置opaque属性YES
-
View背景颜色不透明
-
Image不含有透明通道
-
需要特别注意的是,在iOS8之后,UILabel使用的是CALayer作为底图层,而在iOS8开始,UILabel的底图层变成了_UILabelLayer,绘制文本也有所改变。UILabel显示中文时,还需masksToBounds = YES。
Color Hits Green and Misses Red Color Hits Green and Misses Red用来检测是否正确使用shouldRasterize,当缓存需要重新生成时,红色高亮rasterized layers,当设置shouldRasterize=YES,会将layer预先渲染成位图,并缓存。以提高性能。但是如果cache频繁重复地生成,表示shouldRasterize可能带来的是负面的性能影响。因此shouldRasterize适用于渲染耗时、图像内容不变的情况,在列表中由于内容要频繁变化,因此不推荐使用此属性
Color Copied Images
大多数时,Core Animation只需要提交原始图片的指针到render server,不涉及内存copy。但是一些情况下,Core Animation不得不copy一份图片发送到render server。苹果的GPU只解析32bit的颜色格式,如果图片颜色格式不对,CPU会预先格式转换。copy images是非常耗CPU的操作,一定要避免。
Color Misaligned Images 被拉伸缩放的图片、无法正确对齐到像素的图片(可能有不是整数的的坐标)。是耗CPU的操作
Color Offscreen-Rendered Yellow
GPU在当前屏幕缓冲区外开辟新的缓冲区进行渲染, 屏幕外缓冲区和当前屏幕缓冲区上下文切换是十分耗时的操作
引起Offscreen-Rendered的操作有:
-
- 圆角 cornerRadius masksToBounds同时设置
-
- 设置shadow
-
- 开启光栅化 shouldRasterize=YES.CALayer 有一个 shouldRasterize 属性,将这个属性设置成 true 后就开启了光栅化。开启光栅化后会将图层绘制到一个屏幕外的图像,然后这个图像将会被缓存起来并绘制到实际图层的 contents 和子图层,对于有很多的子图层或者有复杂的效果应用,这样做就会比重绘所有事务的所有帧来更加高效。但是光栅化原始图像需要时间,而且会消耗额外的内存。光栅化也会带来一定的性能损耗,是否要开启就要根据实际的使用场景了,图层内容频繁变化时不建议使用。最好还是用 Instruments 比对开启前后的 FPS 来看是否起到了优化效果。
-
- 图层蒙板
避免Offscreen-Rendered的方式可以其他方式实现圆角、shadow + shadowPath等。
总结
本文的讲了一些造成卡顿的原因,以及CPU和GPU优化的常用技巧和工具,大家在优化的时候可以作为参考。但不要把优化手段局限在这些方面,不同的应用有各自不同的特点,一定要具体问题具体分析。甚至可以跳出技术范畴,在交互方面做一些文章,比如在减少列表每次从服务器获取的数据数量、采用用户手动点击触发获取更多数据而不是滑动过程中自动获取、使用交互动画等都可以极大改善用户的滑动体验。
最后还是要强调一下我上一篇文章讲的优化时候需要注意的几大原则,这样才能在优化过程中有更好的全局观,尽量少走弯路,希望大家能够在优化过程中时刻牢记。
作者:Hello_Vincent
链接:https://juejin.im/post/5b72aaf46fb9a009764bbb6a