【爬虫】秀才不出门,天下事尽知。你也能做到!Yhen手把手带你打造每日新闻资讯速达小工具。
以下内容为本人原创,欢迎大家观看学习,禁止用于商业用途,转载请说明出处,谢谢合作!
大噶好!我是python练习时长一个月的Yhen.很高兴能在这里和大家分享我的学习经验。作为小白,我在写代码的时候会遇到各种各样的BUG,今天我把我的一些经验分享给大家,希望对大家能有所帮助!
今天要给大家分享的是通过爬取”澎湃新闻网”的新闻资讯来打造自己的新闻资讯小工具!后面会提供源码给大家哦
文章目录
- 一. 前期准备
- 二.思路分析
- 三.代码实现
- 四.源码
- 五.【Yhen说】
- 六.【往期文章回顾】
一. 前期准备
首先先罗列一下今天主要会用到的一些库以在今天的用法:(大家可以先准备一下)
requests 爬虫库,用于对网页发送请求
pyquery 用于数据提取
os python自带,无需安装。用于创建文件夹
datetime 用于获取当前日期
time 用于设置请求延时
ok。准备好以后就正式开始今天的分享啦!
二.思路分析
我们今天的第一个目标是要把“澎湃新闻网“”里面的时事栏目里面的文章爬取下来
url:
https://www.thepaper.cn/channel_25951
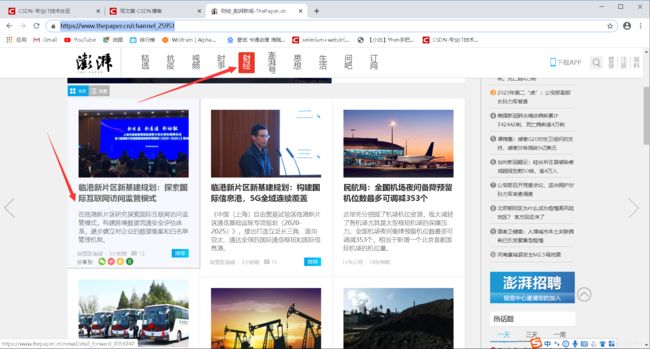
我们先来看看这个网站
这是新闻“财经栏目的详情页”
所以我们要先通过对这个网页进行请求
获取每一个新闻详情页的链接
然后对详情页进行请求
再提取出文章中的文字信息
保存到本地后,再打包成exe可执行文件
就完成我们的爬取任务啦!
好啦,思路分析完了
准备好了么
准备起飞了哦
三.代码实现
首先,还是老套路
按F12打开我们的检查工具
按左上角,然后定位到文章的标题(注意是标题,不要定位到新闻的图片了哦)
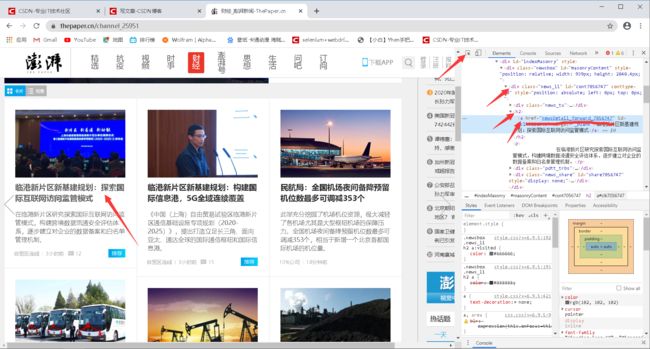
可以看到右边控制台是给我们定位到了h2,
而h2里面有个a标签,
a标签里面有个href,对应着有一条链接
我们点击看看
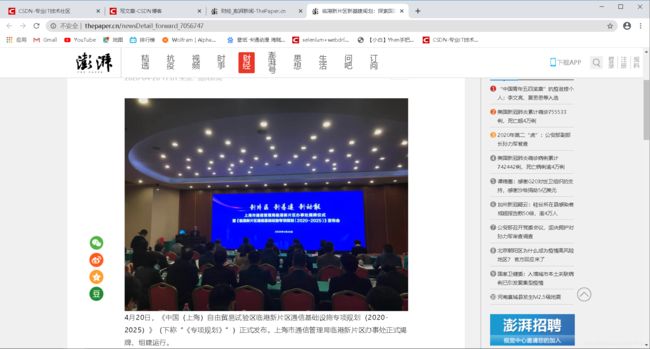
发现进入了新闻的详情页面啦
看来这个href对应的链接就是我们要找新闻详情页的链接啦
接下来我们用代码把这些链接全部提取出来
今天我们要用到的库比较多
我会分步讲解,用到哪个库我再演示导入哪个库
首先,我们要对网页发送请求,用到requests爬虫库,我们要延时请求,用到time 库
然后进行数据提取,用到pyquery库
# 导入爬虫库
import requests
# 导入pyquery(数据提取)
from pyquery import PyQuery as pq
# 用于延时请求
import time
首先是封装一个获取新闻内容网址和新闻标题的函数
然后带上请求头对网页发送请求,设置一秒的延时。
为什么要设置延时呢?
第一,是不为了给对方服务器带来太大的压力
第二,是避免请求过快被对方服务器识别出为非正常请求,对我们进行f反爬。万一对方封了我们的ip就GG啦!
if name == ‘main’:
index()
这串代码是调用函数的意思 ,如果不加函数里面的程序就不会被执行啦
# 请求头
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36',
'Cookie':'aliyungf_tc=AQAAACrtMHyGHA4ARxkbZ27Kgw3kCofh; route=ac205598b1fccbab08a64956374e0f11; JSESSIONID=5B42F8C6E712092B9A963E3F0532AD21; uuid=9065c880-0293-4758-86a8-0a228c6cfb2c; SERVERID=srv-omp-ali-portal10_80; Hm_lvt_94a1e06bbce219d29285cee2e37d1d26=1587280903; Hm_lpvt_94a1e06bbce219d29285cee2e37d1d26=1587280903; UM_distinctid=17191507d62338-03d1defec13f5f-721f3a40-144000-17191507d63400; CNZZDATA1261102524=262517629-1587279306-null%7C1587279306; __ads_session=6NY9VLMBdgmIzmsFHgA=',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Host':'www.thepaper.cn'}
# 封装一个获取新闻内容网址和新闻标题的函数
def index():
# 新闻网首页的链接
url = 'https://www.thepaper.cn/channel_25951'
# 对首页发送请求,并返回文本数据
respoonse = requests.get(url, headers=headers,).text
time.sleep(1)
if __name__ == '__main__':
index()
我们来打印下结果看看,能不能正常得到数据呢
ok,莫得问题,也没有文字的格式问题
那么接下来就要把链接和标题信息提取出来啦
我们再次来观察下控制台的数据
可以看到,我们的链接所在的便签是a
a便签上一级是h2便签
h2便签上一级是类选择器(class)为“news_li”的div便签
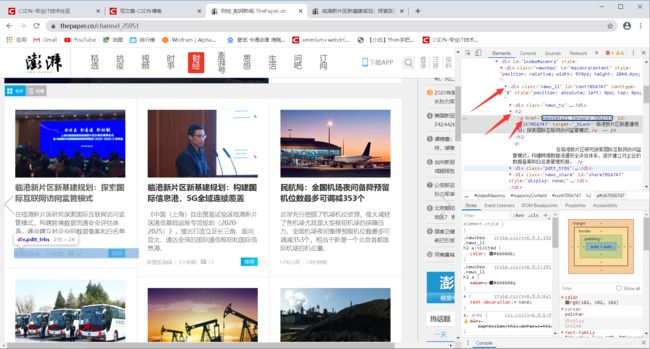
那么想要获取链接
只要用pyquery通过类选择器和它的下级标签定位,
然后通过属性“href”取值即可。
再通过取数据里的文本数据就可以获取标题信息啦
那我们来尝试一下
首先数据初始化
然后通过类选择器news_li 下级标签 h2 a 定位数据
注意: “.”代表用类选择器定位 再取下级标签直接空格即可
# 数据初始化
doc = pq(respoonse)
# 通过类选择器news_li 下级标签 h2 a 定位数据
a = doc(".news_li h2 a")
我们先来看看获取到的数据
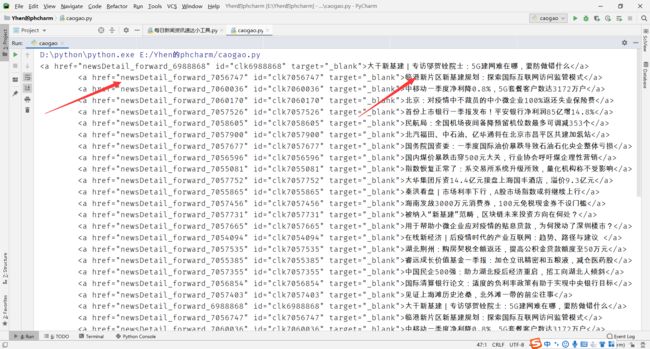
很好,我们的链接和标题都在这了
下面就可以通过他们的属性来提取出来啦
首先要先用.items把这些数据变成可遍历的数据
然后遍历数据
再通过属性href提取出新闻网址,
通过 提取数据中的文本 获取新闻标题
# 数据初始化
doc = pq(respoonse)
# 通过类选择器news_li 下级标签 h2 a 定位数据
# .itens把数据变成可遍历的数据
a = doc(".news_li h2 a").items()
# 遍历数据
for x in a:
# 通过属性href提取出新闻网址
href = "https://www.thepaper.cn/" + x.attr("href")
# 提取数据中的文本 获取新闻标题
title = x.text()
我们来打印下,看看能不能成功的得到标题和链接
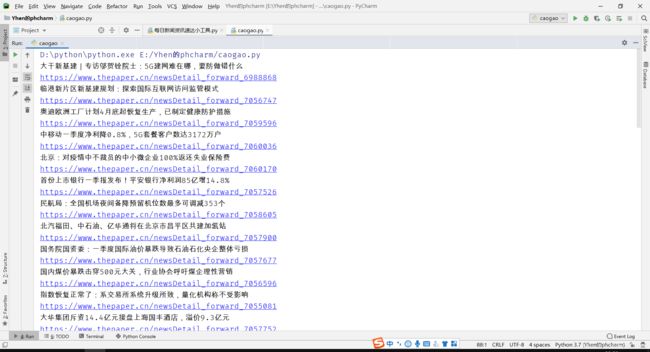
很好,都得到啦
因为我这份教程制作时的时间间隔比较长,而新闻的时效性是很高的,因此有些新闻更新了。
所以现在看到的标题和一开始在首页看到的标题会不太一样
但是对我们的教程是没有任何影响的哈
好了,得到了我们新闻页面的链接后,就要对他们发送请求,获取数据了
首先封装一个获取新闻内容的函数
传入参数href和title
记得在上一个函数要写上get_news(href, title)哦,不然就调用不了啦
# 将href,title参数传递到get_news函数
get_news(href, title)
# 封装一个获取新闻内容的函数
def get_news(href,title):
然后在这个函数里对刚刚获取的新闻网址发送请求
# 对新闻内容网址发送请求
response = requests.get(href,headers=headers).text
打印一下看看
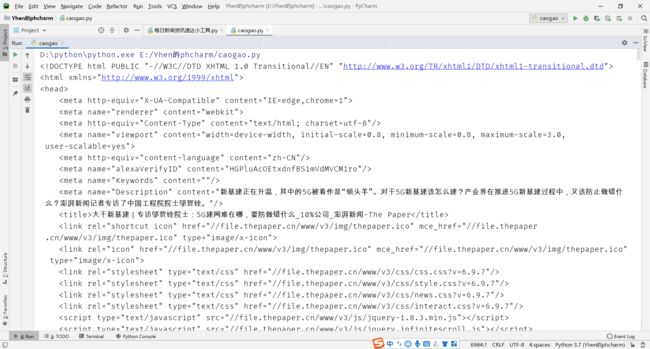
就可以成功得到新闻数据的
接下来再用一次pyquery把新闻内容提取出来吧
方法和上面是一样的
# 数据初始化
doc =pq(response)
# 通过类选择器news_txt提取新闻内容
news = doc(".news_txt").items()
# 遍历数据
for x in news:
# 取出数据中的文本数据,获取到新闻信息
new = x.text()
print(new)
打印看看
没有毛病
接下来就是我们今天的重头戏啦
既然我们要打造的是每日的新闻资讯工具
那么当然是要程序自动生成一个当前日期的文件夹啦
怎么实现呢?
首先,生成文件夹要用到os库,获取当前日期要用到datetime库
先导入吧
import os
# 用于获取当天日期
import datetime
然后通过下面一行代码设置我们要生成的日期文件路径
# 获取今日日期,并转换为字符串的形式。以此日期命名建立文件路径
date = datetime.datetime.now().strftime('%Y-%m-%d') + "新闻" + "//"
之前没有接触过这个模块的同学可能看不懂
没关系,我把他们拆开一步步给你们看
首先我们通过下面的代码获取当前的时间
# 获取今日日期,并转换为字符串的形式。以此日期命名建立文件路径
date = datetime.datetime.now()
print(date)
print(type(date))
打印下看看

成功得到了现在的年月日时分秒。数据类型是datetime类型的数据
但是我们建立的时间文件夹是不需要这么精准的
我们只要年月日
而且我们想把的格式变成字符串
我之前也和大家一样没接触过呢
怎么办呢?
不会就度娘呗哈哈哈
在一篇csdn博客中,成功找到了解决方法
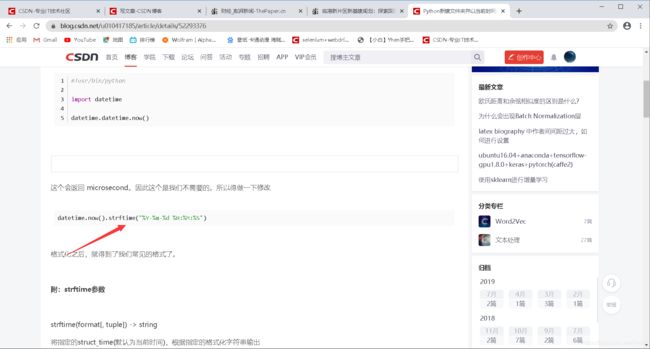
文中提到可以通过strftime格式化时间的方法
实现提取出日期中的年月日以及把时间格式化成字符串
一举两得

文中还附上了strftime的参数方法
大家有兴趣的可以自行去了解
原文链接
Python新建文件夹并以当前时间命名
date = datetime.datetime.now().strftime('%Y-%m-%d')
print(date)
print(type(date))
我们此时再来打印下时间和类型

此时已经成功提取到年月日
格式也变成字符串啦
我们要新建的是新闻文件夹,所以路径里当然当然要加个“新闻”啦。
并加上//表示文件夹
date = datetime.datetime.now().strftime('%Y-%m-%d') + "新闻" + "//"
接下来就是新建文件夹啦
首先判断是否存在日期文件夹
如果不存在就新建该文件夹
# 判断是否存在此文件夹
folder = os.path.exists(date)
# 如果不存在就新建该文件夹
if not folder:
os.makedirs(date)
好啦,接下来就是把打开新建的文件夹并把我们的新闻内容保存进去啦
首先打开日期date文件夹,以"a"追加的方式,编码为"utf-8"保存为txt文件.
然后 将获取到的新闻数据写入
最后关闭写入
就大功告成啦
# 打开date文件夹.以"a"追加的方式,编码为"utf-8"保存为txt文件.
with open(date + "{}.txt".format(title), "a", encoding="utf-8") as f:
# 将获取到的新闻数据写入
f.write(new)
# 关闭读写
f.close()
我们运行整个程序看看效果如何
首先成功给我们生成了一个当前日期的文件夹
新闻内容也成功写入进去了呢
成功保存为txt文件,也没有出现格式问题

我们已经成功90%啦
我们今天是要把他变成一个本地的新闻资讯获取工具
所以当然是要把他打包成exe啦
关于打包的具体操作我就不细说啦
我之前在这篇文章有详细介绍过
Yhen手把手教你把python文件打包成exe可执行程序
大家可以参考参考哦
OK,打包完成后
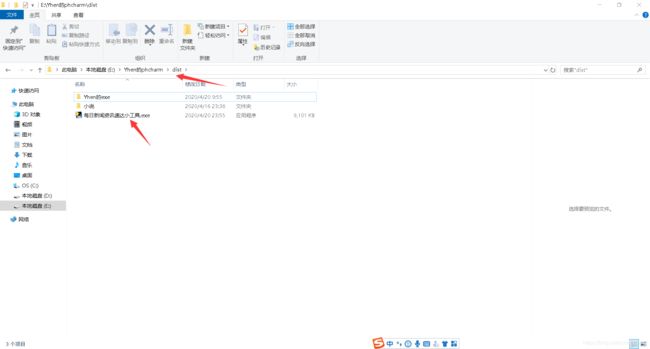
可以看到exe文件保存在了你pycharm路径下的dist文件夹
我们运行一下看看
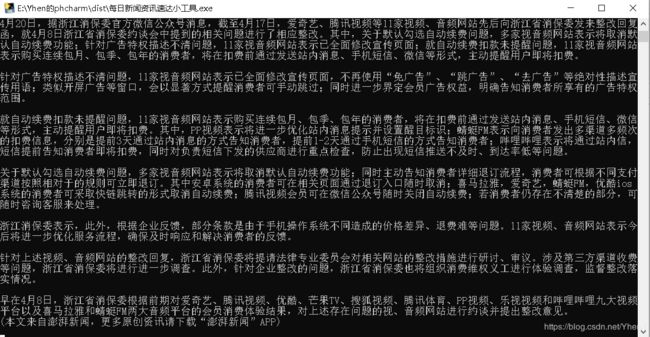
程序运行结束后,可以看到也是成功生成了当前日期的文件夹(晚一点点就变成21号的了哈哈哈)

打开后也是没有任何问题的呢
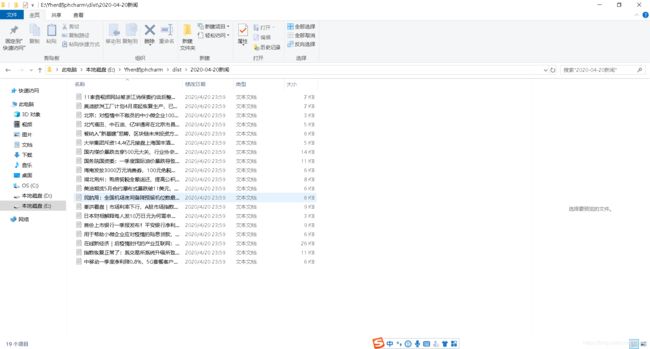

好啦!
成功啦
撒花完结!
四.源码
下面把源码给大家
# 导入爬虫库
import requests
# 导入pyquery(数据提取)
from pyquery import PyQuery as pq
# 用于创建文件夹
import os
# 用于获取当天日期
import datetime
# 用于延时请求
import time
# 请求头
headers ={
# 浏览器类型
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36',
# 用户信息
'Cookie':'aliyungf_tc=AQAAACrtMHyGHA4ARxkbZ27Kgw3kCofh; route=ac205598b1fccbab08a64956374e0f11; JSESSIONID=5B42F8C6E712092B9A963E3F0532AD21; uuid=9065c880-0293-4758-86a8-0a228c6cfb2c; SERVERID=srv-omp-ali-portal10_80; Hm_lvt_94a1e06bbce219d29285cee2e37d1d26=1587280903; Hm_lpvt_94a1e06bbce219d29285cee2e37d1d26=1587280903; UM_distinctid=17191507d62338-03d1defec13f5f-721f3a40-144000-17191507d63400; CNZZDATA1261102524=262517629-1587279306-null%7C1587279306; __ads_session=6NY9VLMBdgmIzmsFHgA=',
# 请求数据类型
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
}
# 封装一个获取新闻内容网址和新闻名称的函数
def index():
# 新闻网首页的链接
url = 'https://www.thepaper.cn/channel_25951'
# 对首页发送请求,并返回文本数据
respoonse = requests.get(url, headers=headers,).text
time.sleep(1)
# 数据初始化
doc = pq(respoonse)
# 通过类选择器news_li 下级标签 h2 a 定位数据
# .itens把数据变成可遍历的数据
a = doc(".news_li h2 a").items()
# 遍历数据
for x in a:
# 通过属性href提取出新闻网址
href = "https://www.thepaper.cn/" + x.attr("href")
# 提取数据中的文本 获取新闻标题
title = x.text()
# 将href,name参数传递到get_news函数
get_news(href, title)
# 封装一个获取新闻内容的函数
def get_news(href,title):
# 对新闻内容网址发送请求
response = requests.get(href,headers=headers).text
# 数据初始化
doc =pq(response)
# 通过类选择器news_txt提取新闻内容
news = doc(".news_txt").items()
# 遍历数据
for x in news:
# 取出数据中的文本数据,获取到新闻信息
new = x.text()
print(new)
#
# 获取今日日期,并转换为字符串的形式。以此日期命名建立文件路径
date = datetime.datetime.now().strftime('%Y-%m-%d') + "新闻" + "//"
# 判断是否存在此文件夹
folder = os.path.exists(date)
# 如果不存在就新建该文件夹
if not folder:
os.makedirs(date)
# 打开date文件夹.以"a"追加的方式,编码为"utf-8"保存为txt文件.
with open(date + "{}.txt".format(title), "a", encoding="utf-8") as f:
# 将获取到的新闻数据写入
f.write(new)
# 关闭读写
f.close()
if __name__ == '__main__':
index()
下面到我的吹水环节啦
五.【Yhen说】
今天这个项目算是我独立做的第二个项目吧。第一个是用selenium来爬海贼王图片的。说到这篇用selenium的文章,我觉得挺神奇的,前天我看着那篇文章的访问量蹭蹭的往上涨,我隔十几分进去看一下,发现访问量都是每次几十几十的涨的。他的访问量很快就超过了我写的第一篇教程爬千千小说的,现在已经达到七百多的访问量了,因为这篇文章,我的总访问量很快就破千了,我还是很开心的。这点访问量对于大佬们来说是洒洒水的事,但是对于我这个无名小辈来说。我还是挺满意的啦。破了第一次千!也多了一些同学关注我。谢谢大家的支持。大家的支持是我创作的动力。以后也会分享更多的经验给大家。
很开心能在这里给大家分享我的经验。有什么疑惑或者对我有什么建议的欢迎在评论区提出。
如果觉得我写的还可以的,可以给个小赞嘛,点个关注就更好啦!
也算是对我的一个支持啦!
我是Yhen,我们下期见!
六.【往期文章回顾】
【爬虫】Yhen手把手带你用python爬小说网站,全网打尽,想看就看!
(这可能会是你看过最详细的教程)
【爬虫】Yhen手把手带你用python爬取知乎大佬热门文章
【爬虫】Yhen手把手教你爬取表情包,让你成为斗图界最靓的仔
【爬虫】Yhen手把手带你爬取去哪儿网热门旅游信息(并打包成旅游信息查询小工具
【selenium爬虫】Yhen手把手带你用selenium自动化爬虫爬取海贼王动漫图片