在鱼眼和全向视图图像的深度学习方法
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者:黄浴
https://zhuanlan.zhihu.com/p/88675419
本文仅做学术分享,如有侵权,请联系删除。
普通摄像头的图像已经有很多论文讨论各种应用的深度学习方法,但对鱼眼镜头(fisheye)和全向(omnidirectional)摄像头的工作比较少。这里列出一些,另外也会讨论深度学习中对这类图像数据特别适合的模型,比如STN、SCNN和DCN等。
• “Graph-Based Classification of Omnidirectional Images”
2017, 3.
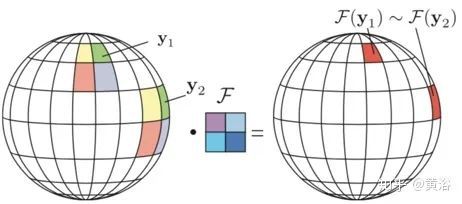
全向(Omnidirectional)摄像机提供了广阔的视野,广泛用于机器人技术和虚拟现实等领域。通常其图像用经典方法进行处理,会导致非最优解,因为是针对不同于全向几何(Omnidirectional geometry)特性的平面图像(planar images)而设计的。这里全向摄像机的特定几何形状下考虑基于图形(graph-based)表示形式的图像分类。特别是用于图数据的深度学习架构,该算法来自ICML‘17的论文“Graph-based Isometry Invariant Representation Learning”。这是一种图形构造(graph construction)的原则方式,使卷积滤波器在不同位置上相同图案的响应类似,与镜头畸变无关。
如图所示,图形构造使滤波器响应相似,与全向相机图像的模式与其位置无关。
它提出一个基于变换不变图网络(Transformation Invariant Graph-based Network, TIGraNet):
它以网格图上的图像信号作为输入,而分类标签作为输出。简而言之,该方法提出了一种频谱卷积层(spectral convolutional layers)和动态池层(dynamic pooling layers)交替堆叠的网络,该网络创建的特征与同测度变换(isometric transformation)相当。此外,其最后一层的输出由统计层(statistical layer)处理,这使数据的同变(equivariant)表示对同测度变换(isometric transformations)保持不变。
最后,将得到的特征向量馈送到多个全连接层和一个softmax层,后者输出信号类别的概率分布。将相机镜头几何(camera lens geometry)知识与图形结构结合,此变换不变(transformation-invariant)分类算法可扩展到全向(Omnidirectional)图像领域。
下图是借用的TIGraNet体系结构。该网络由频谱卷积层F1和动态池化层P1交替组成,随后是统计层H,多个全连接层(FC)和softmax算子(SM)。网络的输入是一个图像,该图像表示为拉普拉斯矩阵L的网格图信号y0。系统输出是与输入样本最可能类别的对应标签。

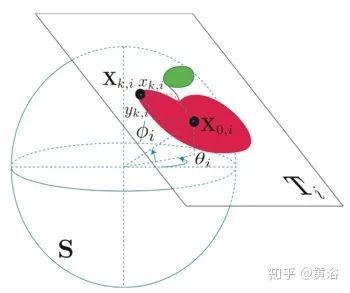
全向图像一般是表示为一个球面图像,如图所示,自由空间的3-D点投影到球面的2-D点,记作:

而切平面Ti的目标在切点X0,i投影到球体,该切点由球坐标(φi,θi)定义。点Xk,I由平面上的坐标(xk,i,yk,i)定义。该投影公式称为侏儒投影(gnomonic projection),即

其中c是角距离,定义为

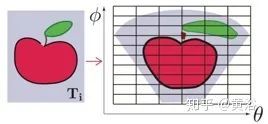
为处理球面定义的信号,通常将其投影到等矩形图像(equirectangular image)。如图所示,左侧是在切平面Ti上的原始图像,而右侧是投影到球面的点。为建立等矩形图像,通常离散规则网格的点从投影点通过插值来近似。
这里目标(goal)是开发一个变换不变系统,无需任何额外训练就可以识别在不同点(φi,θi)与球面S相切的不同平面Ti的同一目标(object)。建立这样一个系统的挑战是设计一个合适的图信号表示,补偿在球面S不同高度的失真(distortion)效应。
如图所示:a)从赤道正切平面Te的目标(φe= 0,θe= 0)(红点)选择模式p0,..,p4,然后b)通过移动切平面Ti至点(φi,θi)而移动球面目标。c)因此,位于切点(φi,θi)的滤波器用顶点(vertices)数值pi,1,pi,3(蓝点),这个可以通过内插获得。

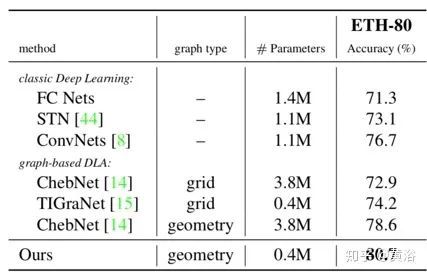
深度学习方法分为经典方法和基于图的方法:前者使用全连接网络(FCN),卷积网络(ConvNets)和空间变换网络(STN);STN在卷积网络基础上有一个附加层,学习输入图像的特定转换;后者选择ChebNet 和TIGraNet 进行实验,ChebNet是基于Chebyshev多项式滤波器设计的网络,TIGraNet是论文借用的基准方法。
下表是ETH-80数据集上最新方法的比较。选择不同方法的体系结构,但在全连接层具有相似数量的卷积滤波器和神经元。更准确地说,所有网络有2个卷积层,10个和20个滤波器,以及3个全连接层,分别具有300、200和100个神经元。在经典架构中,卷积层的滤波器大小为5×5。对ChebNet,尝试使用5和10阶多项式并最终选择后者。对于TIGraNet,使用5阶多项式滤波器。
• “Flat2Sphere: Learning Spherical Convolution for Fast Features from 360° Imagery”
2017, 8
尽管360°摄像机在视觉、图形和增强现实(AR)方面提供了巨大的可能性,但产生的球形图却使核心特征提取变得不容易。透视相机图像训练的卷积神经网络(CNN)产生“扁平”滤波器,但是在没有明显失真的情况下360°图像不能投影到单个平面。一种幼稚解决方案将视图球面重复投影到所有切平面,对实际问题而言,结果是准确的但计算量很大。
Flat2Sphere学习一个球形(spherical)卷积网络,该网络将平面(planar)CNN转换为直接在等矩形(equirectangular)投影中处理360°图像。这种方法学习在360°图像数据上重现扁平滤波器(flat filter)的输出,对视球面变化的畸变效应表现敏感。
这个模型的主要优点是:1)有效提取360°图像和视频的特征;2)充分利用针对透视图像精心磨练的强预训练网络(连同大量的带标签图像训练集)。
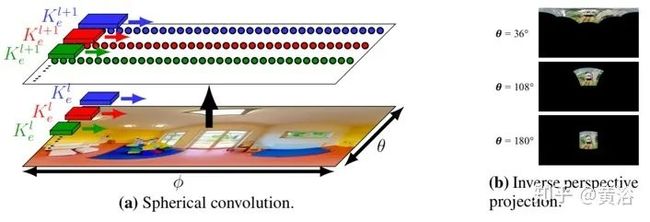
CNN应用于360°图像,有两个策略,如图所示。顶图是第一种策略,用全局投影(等矩形)将360°输入展开为单个平面图像,然后将CNN应用于变形的平面图像。底部是第二种策略,对多个切平面投影进行采样获得多个透视图像,将CNN独立应用于透视图像以获得原始360°图像的局部结果。策略1快速但不准确;策略2准确但缓慢。该方法学习在球面图像复制扁平滤波器,同时实现高速和高准确性。

球形卷积网络不同于普通的CNN,如图所示:(a)球形卷积的内核权重仅沿每行绑定,并且每个内核沿着行卷积生成1D输出;注意,内核大小在不同的行和层有所不同,并且在靠近图像顶部和底部的时候扩展;(b)是在不同极角(polar angles)θ球面反透视投影P-1至等矩投影。根据极角θ同样的方形图像变形为不同的大小和形状。
最后是实验结果例子:360°PASCAL测试图像上的目标检测。图片显示等矩投影顶部40%的区域;黑色区域是未定义的像素。文本给出了预测标签,多类别的概率和IoU。

• “SalNet360: Saliency Maps for omnidirectional images with CNN”
2017, 9
随当前虚拟现实(VR)领域的趋势,让技术适应这种新型媒体的势头开始增强。VR头盔的应用程序之一是全向图像(Omni-directional Images,ODI)的显示。这些图像从静态角度描绘了整个场景,用VR头盔观看时,提供用户身临其境的体验。
存储ODI的最常用方法是应用等矩形、圆柱或立方体投影并保存为标准的二维图像。来自任何一种媒介的视觉注意(Visual Attention)数据预测对内容制造商来说都是有价值的,并且可以有效地驱动编码算法。本文是对CNN体系结构的扩展,以端到端方式将传统2D显著性(saliency)预测算法微调到ODI。要解决这些问题,需要做的是:1)将ODI细分为未失真的色块;2)为CNN提供补丁像素的球坐标。
如图所示,该方法将ODI作为输入,用预处理步骤将其分成六个补丁。六个补丁的每个都通过CNN发送。然后,用后处理技术将所有补丁的CNN输出合并。

通过指定每个补丁的视野及其分辨率,可以计算补丁像素的球坐标。然后,用以下方程在ODI查找相应的像素:


如图是球形坐标的定义和用于创建布丁的滑动视锥。

下图就是从ODI提取的布丁示意图。

如图是文章采用的网络架构。

如图是三种实验方案的结果比较。顶:左侧是输入ODI,右侧是与图像混合的真实显著图(saliency map)。下排:从左到右,这三个实验方案的结果:基础CNN、基础CNN +布丁块和基础CNN +布丁块+球面坐标。

• “Scene Understanding Networks for AD based on Around View Monitoring System”
2018, 5
现代驾驶辅助系统依靠各种传感器(雷达,激光雷达,超声和摄像头)进行场景理解和预测。这些传感器通常用于检测交通参与者和导航所需的场景元素。基于摄像头的系统,特别是环视监控(AVM)系统,在降低停车成本和停车模式方面都具有实现这些目标的巨大潜力。
本文提出一种端到端解决方案,用于通过识别驾驶车辆各个方向上最近的障碍物,为每帧划定安全的可驾驶区域;它计算最近障碍物的距离,并整合到统一的端到端架构中,该架构能够进行联合目标检测、路边(curb)检测和安全驾驶区域检测。一个架构增强版包括3D目标检测。
这种检测路边和自由驾驶区域方法的灵感来自于以前计算立体视觉障碍物的Stixel表示方法,其模型称为Bottom-Net。如图所示,最初网络将图像的每个垂直列作为输入,输入列的宽度为24,重叠23个像素。然后,每列通过卷积网络输出k种标签之一,其中k为高度。结果,它学会分类该列对应的障碍物底部像素位置。所有列的并集将构建路边或场景的自由驾驶区域。

在这种架构中,由于列之间的重叠,超过95%的计算是多余的。为此,逐列网络换成端到端体系结构。该网络用多个卷积层将图像编码为特征图,然后用多个上采样层生成与输入图像相同分辨率的特征图。裁剪与像素列相对应的图像硬编码区域,并附加相邻区域的23像素。
结果,用于裁剪上采样特征图的感兴趣区域(ROI)为23像素x720像素。在每个x坐标的图像水平滑动此窗口,然后在ROI池化层调整所得裁剪区域的大小(例如7x7),并判别为k个类之一(k是图像高度),最终预测底部点(bottom point)。
如图就是底部预测架构图:底部预测的分类层用单击(single shot)方法。而且,为了使网络更有效,用单个密集的水平上采样层替换多个上采样层相对应的网络的解码器部分。在跨度(stride)> 1的多个卷积计算后,编码器生成的最终特征图分辨率降低了16倍。

而整个Bottom-Net的架构如图所示。水平上采样层的顶部添加另一个全连接层,将每列输入做线性组合。Softmax层将每个列输出判别为k个类别之一,其中k是要预测图像的高度。每个列分类子任务都会自动考虑在被分类中心列附近的像素,并作为最终底部预测。

目标检测(OD)网络采用Faster R-CNN 和编码器如Inception-ResNet-V2相结合。Unified-Net 架构结合底部预测和目标检测网络,利用编码器的计算共享优势,实现更好的训练优化和运行性能,如图所示。

一个增强型架构3D-Net,最终是由两个分支组成,分别用于基于角度离散化的目标朝向估计和对象尺寸回归计算,如下图所示。

实验结果有一些例子,下图是侧视图检测。

这个图是检测显示的拷屏。

• “Eliminating the Blind Spot: Adapting 3D Object Detection and Mono Depth Estimation to 360◦ Panoramic Imagery ”
2018, 8
最近车辆视觉工作集中在前置摄像头。然而,如果没有像人类驾驶员那样的更全面的环绕感测,如360°全景摄像机所提供的,未来自动驾驶汽车不太可行。
本文调整常规直线型(rectilinear)图像开发的深度网络体系结构应用于等矩(equirectangular)360°全景图像。为了解决缺乏可用有注释全景车辆数据集问题,它通过风格(style)和投影转换对车辆数据集进行调整,这样对开发的全景图像算法可以跨域再训练。
按照这种方法,无需任何全景训练标注或标定参数,可以重新训练并调整现有架构,从单目全景图像中恢复车辆的场景深度和3D姿态。该方法在众包的全景图像上进行了定性评估,并用汽车环境模拟器进行了定量评估,为全景图像提供了第一个基准。
如图所示,全景图像通常使用等矩投影(图A)表示;相反,常规照相机使用直线型投影。在这种投影中,不像通常的焦点平面投影,图像空间坐标与观察点的纬度和经度成比例(图A)。调整以前的3D对象检测和深度估计,可以对全景影像做单目深度估计(图B),并从全景影像恢复车辆的完整3D姿态(图B)。

关于风格转换,采用CycleGAN模型实现。关于深度估计,采用CVPR‘17论文“Unsupervised Monocular Depth Estimation with Left-Right Consistency“的方法。
关于3D目标检测,基于faster RCNN算法,整个网络是多尺度 CNN (MS-CNN) 体系结构和扩展的3D姿态回归组成,通过6组异构网络输出的多任务损失函数,进行端到端训练微调:类和象限(quadrant)分类是基于交叉熵损失的学习过程,而边框的位置、目标中心、距离和朝向取决于均方损失。如果手动调整多任务损失权重,会很耗时,因此用CVPR’18论文“Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics”的方法,在训练过程中无需使用任何手动超参数,基于同调不确定性(homoscedastic uncertainty)动态调整多任务权重。
在网络调整中,使用填充法在水平图像边界无缝地计算卷积,如图所示:(a)将360°等矩图像折叠其自身,直到两端相遇。(b)一个3×3卷积内核,从另一侧复制的填充列添加在末端。

最后是单目深度恢复和3D目标检测的实验结果例子,如图所示,其中左图是真实世界的图像,右图是合成图像。

• “Distortion-Aware Convolutional Filters for Dense Prediction in Panoramic Images”
2018, 9
对360°全景图像和视频的3D数据需求正在变高,主要由于捕获(例如,全向摄像机)和可视化(例如,头戴式显示器)专用硬件市场的日益增长所推动。同时看到,捕获3D全景数据的传感器价格昂贵。为了填补这一空白,本文提出一种用于单个图像进行全景深度图估计的机器学习方法。
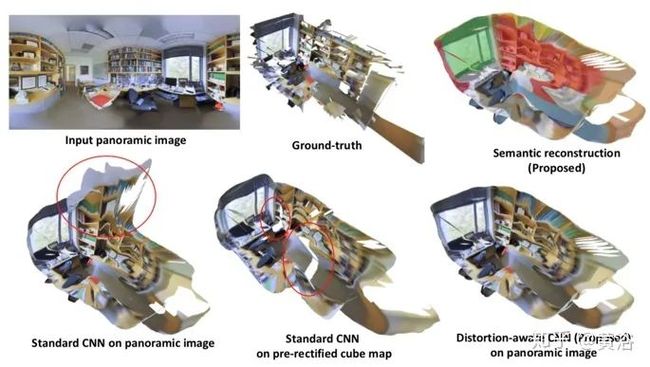
等矩形表示引起的变形问题主要是,当将球形像素投影到平面,图像会显着变形,尤其是沿y轴方向,这种失真导致深度预测的重大误差。校准(rectification)是解决此问题的一种简单方案。由于摄像机模型的视场限制,360°全景图像无法校正为单个透视图像,因此通常用6个透视图像组合进行校正,每个图像与不同方向相关联,即称为方体图投影(cube map projection)表示。然而,尽管全景图像在那些区域连续,这种表示在图像边界处都包括着不连续性。
得益于专门开发的失真-觉察(distortion-aware)可变形卷积滤波器,该方法可以用常规的透视图像进行训练,然后用于全景图像的深度回归,避开了创建带注释的全景训练数据集。文中给出一些应用,如全景单目SLAM、全景语义分割和全景风格转换。
如图所示:从单个输入等矩形图像(左上图)开始,利用失真-觉察卷积显著名减少了影响常规CNN(底行图)深度预测的失真。右上角图是语义标签预测,同样的想法用于从单个图像获得全景3D语义分割。
普通二维卷积执行两个步骤:通过在第l层的输入特征图fl上用规则网格R对特征进行采样,然后计算w加权的特征邻域之和。采样网格R定义感受野(receptive field)的大小和规模,即
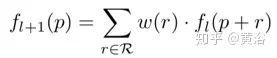
在失真-觉察卷积中,采样网格R借助函数δ(p,r)进行变换,该函数根据图像失真模型计算在像素位置失真的邻域(distorted neighborhood),即

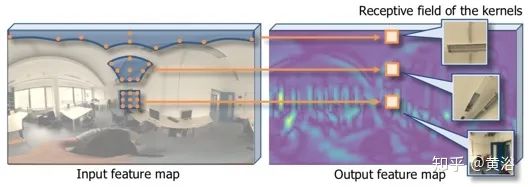
失真-觉察卷积的关键想法是,采样网格会根据图像失真模型变形,对感受野进行校正,如图所示。
首先,等矩形图像(x,y)的点p图像坐标转换为球坐标系ps =(θ,φ)的经度和纬度,即:
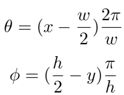
然后,将纬度和经度(θ,φ)按以下关系转换为单位球面坐标系pu =(xu,yu,zu):

随后,计算单位球坐标系中pu像素位置周围的切平面,即tu =(tx,ty)。在切平面的图像投影表示了原始等矩形图像在像素位置p周围的校准图像。可以将切平面tu邻域位置(neighboring location)在规则网格(regular grid)的采样反投影到等矩形图像坐标系(equirectangular image coordinate system)上,获得原始图像pˆ的一组变形像素位置。这个采样网格定义为
![]()
然后,与采样网格元素rsphere相关的切平面位置计算为
![]()
最后,通过使用上述坐标变换的逆函数,将每个元素pu,r =(xu,r,yu,r,zu,r)反向投影到等矩图像域,即


如图所示是等矩图像自适应采样网格的计算过程:等矩形图像的每个像素p转换为单位球坐标,然后在单位球坐标的切平面计算采样网格,最后将采样网格反投影到等矩形图像中,可确定失真采样网格的位置。

该方法的主要优点是可以将标准卷积体系结构与常见数据集一起用于透视图像训练权重。在测试时,通过失真-觉察的卷积滤波器权重在相同体系结构上传输处理等矩形图像,如图所示。尽管其报告了深度预测的情况,但语义分割任务也采用相同的策略。

最后,实验评估对方法的比较,如图所示:(a)等矩形图像的标准卷积;(b)方体图投影在6个校准图像的标准卷积;(c)等矩形图像采用的失真-觉察卷积。

注意该数据集图像在两极区(polar region)附近缺少颜色信息,需要填充为零。为避免在训练过程中网络偏离,应用修复(inpainting)算法。创建用于训练的透视图,首先,从原始360°全景图像提取沿不同方向的有限视野图像。垂直/水平轴分别以20°/15°间隔(偏航转)(俯仰转)采样方向。然后,校正为标准透视图。将等矩形投影的像素映射到透视投影,生成这些校正的透视图像。
带/不带修补和提取的校正透视图像的等矩形图像示例,如图所示。

如图是在斯坦福2D-3D-S数据集的深度预测结果:红色圆圈突出显示由于标准卷积模型(a)和方体图(Cube Map)表示形式(b)引起的失真而导致的伪影,这些失真由方法(c)解决。

如图是斯坦福2D-3D-S数据集的语义分割比较。红色圆圈突出显示了失真-觉察方法中没有方体图(Cube Map)模型两极区域和边界出现的错误。

最后一个实验例子图是失真-觉察卷积模型在全景风格转换的应用结果。

• “Restricted Deformable Convolution based Road Scene Semantic Segmentation Using Surround View Cameras”
2019, 9
正确理解车辆的周围环境仍然是自动驾驶的挑战之一。可以用环视相机进行360°道路场景语义分割,这种摄像头在现有量产汽车中已经广泛使用。首先,为解决鱼眼图像的大失真问题,本文提出了一种约束可变形卷积(Restricted Deformable Convolution,RDC)语义分割算法,该算法通过学习基于输入特征图的卷积滤波器形状对几何变换有效地建模。
其次,为获得周围环境图像的大规模训练集,它提出了一种称为缩放增强(zoom augmentation)方法,可将常规图像转换为鱼眼图像。最后,基于RDC的语义分割模型被建立。该模型将现实世界图像与变换后图像相结合,通过多任务学习架构对现实世界环视图像进行训练。注:采用ERFNet(IEEE T-ITS 2017年论文“ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation”)作为分割的基准模型。
以前大多直接将鱼眼图像转换成去失真图像(比如dewarp算法),如图是鱼眼镜头和去失真图像(undistorted/rectilinear image)例子:去失真图像中心清晰,但图像边界非常模糊。并且,原始鱼眼图像转换为去失真图像会丢失一些信息。


本文环视摄像机由安装在车辆两侧的四个鱼眼摄像机组成,如图所示,其中不同方向的相机会捕获具有不同图像组成(image composition)的图像。

RDC是受限可变形卷积,如图所示是3x3卷积的采样位置:(a)标准卷积;(b)具有扩张(dilation)2的扩张卷积;(c)可变形卷积;(d)受限可变形卷积。其中黑点是实际采样位置,(c)和(d)的空心圆是初始采样位置,(a)和(b)采用固定采样位置网格,(c)和(d)用学习的2D偏移量(红色箭头)放大采样位置;(c)和(d)的主要区别在于受限可变形卷积采用固定的中心采样位置;无需学习(d)的中央采样位置偏移。

下图所示是3×3受限可变形卷积示意图:该模块由具有扩展功能的3×3滤波器初始化。偏移域通过常规卷积层从输入特征图中学习。通道尺寸2(N-1)对应于(N-1 )2D偏移(红色箭头)。实际采样位置(黑点)将2D偏移量相加得到。新位置通过四个最近点双线性插值获得。黄色箭头表示梯度反向传播(BP)路径。
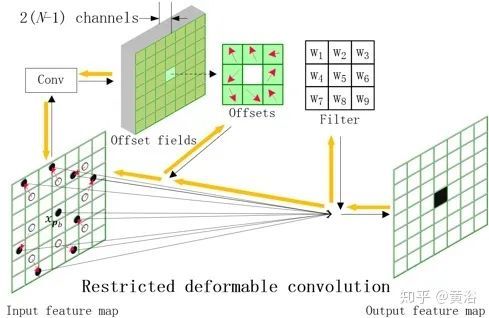
为了减少内存和计算成本,可以将2D滤波器近似为1D滤波器的组合。一个基本分解层由垂直内核和水平内核组成,然后在1D卷积之间插入非线性。对于2D RDC,每个学习的偏移都有两个分量:垂直和水平方向。将2D内核分解为垂直和水平内核,偏移也可以分解为同一方向的两个分量。
如图是分解RDC的直观解释:(a)3×3常规卷积;(b)分解卷积;(c)分解受限可变形卷积。在此省略(b)和(c)中的非线性。

深度CNN网络训练需要大量训练图像,但训练数据集总是有限的。所以一种方法是采用数据增强(Data argumentation)通过保留标签的变换来扩大训练数据。许多用于语义分割的数据增强形式,例如水平翻转、缩放、旋转、裁剪和颜色抖动(jittering)。
将常规图像变形为鱼眼图像通常称为缩放增强。缩放增强可以固定焦距或随机改变焦距。通过缩放增强方法,现有语义分割的常规图像数据集开源转换为鱼眼图像数据集。注:焦距越小,畸变程度越大。
如图是缩放增强例子:左侧是,原始彩色图像和注释,右侧是,焦距从200到800变化缩放增强变换的图像和注释。

如图所示用于道路场景语义分割的多任务学习(multi-task learning)架构:将数据馈入三个共享权重子网(蓝色块),总损失是主损失和辅助损失的加权和;γ是辅助损失权重,用于平衡辅助损失的贡献;α是主分支的任务权重,平衡不同任务的主损失;同样,β是辅助分支的任务权重,平衡不同任务的辅助损失。
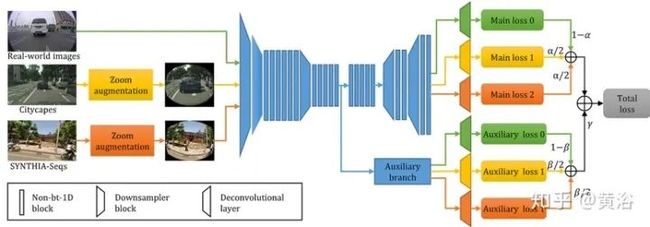
下图是实验中采取的模型ERFNet-RDC-λ架构:(a)ERFNet的Non-bt-1D块;(b)重建的Non-bt-1D块,前两个卷积层被RDC层替换;(c)ERFNet-RDC-λ的编码器。

而下图是ERFNet、ERFNet-DC-8、ERFNet-FRDC-8和ERFNet-RDC-8产生的分割结果示例:红色像素表示对其中公共汽车的错误识别,ERFNet-RDC-8在图像中几乎检测到整个公共汽车。

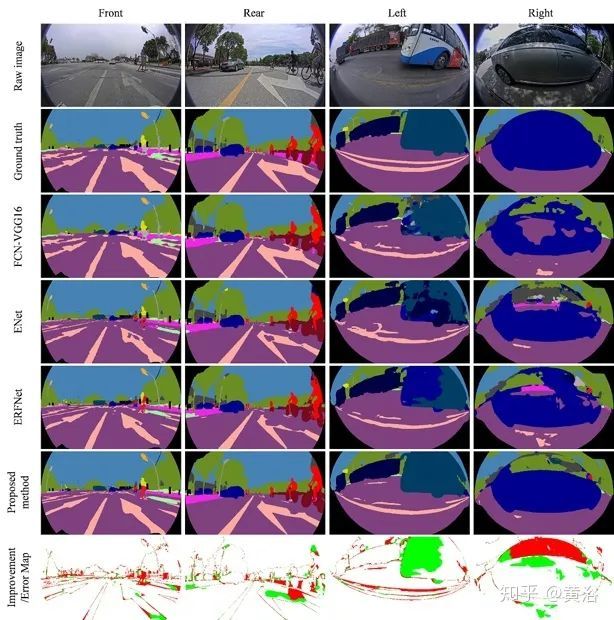
下图是SVScape测试集的结果示例。前视图、后视图、左视图和右视图的结果显示在图(a)中。前两行显示原始图像和真实值,后四行显示不同模型产生的结果。最后一行显示改进/误差图,RDC方法误分类的像素为红色,而被基本模型ERFNet误分类但RDC方法正确预测的像素为绿色。图(b)列出分割中对应目标的颜色代码。
(a)
![]()
(b)
最后,如图展示的实验结果示例,是原始环视图像的分割映射到鸟瞰平面做鸟瞰图像语义分割结果。

还有几篇放在下部分,以及附录的几个特殊设计的CNN模型。
推荐阅读:
专辑|相机标定
专辑|3D点云
专辑|SLAM
专辑|深度学习与自动驾驶
专辑|结构光
专辑|事件相机
专辑|OpenCV学习
专辑|学习资源汇总
专辑|招聘与项目对接
专辑|读书笔记
专辑|相机标定
专辑|3D点云
专辑|SLAM
专辑|深度学习与自动驾驶
专辑|结构光
专辑|事件相机
专辑|OpenCV学习
专辑|学习资源汇总
专辑|招聘与项目对接
专辑|读书笔记
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近1000+星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题