Redis HBase Es HyperLogLog与BloomFilter笔记
什么是布隆过滤器?
它实际上是一个很长的二进制向量和一系列随机映射函数。把一个目标元素通过多个hash函数的计算,将多个随机计算出的结果映射到二进制向量的位中,依次来间接标记一个元素是否存在于一个集合中。
布隆过滤器可以做什么?
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器特点
如果布隆过滤器显示一个元素不存在于集合中,那么这个元素100%不存在与集合当中
如果布隆过滤器显示一个元素存在于集合中,那么很有可能存在,可能性取决于对布隆过滤器的定义(BF.RESERVE {key} {error_rate} {capacity})
布隆过滤器的原理图,这个就很容易理解了。
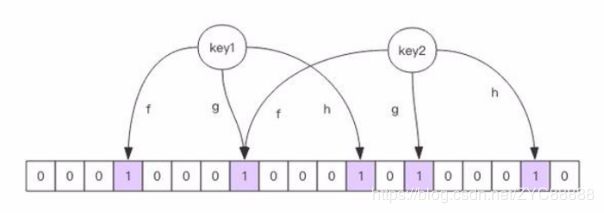
Bloom Filter实现
要实现一个布隆过滤器,我们需要预估要存储的数据量为n,期望的误判率为P,然后计算位图的大小m,哈希函数的个数k,并选择哈希函数。
求位图大小m公式:
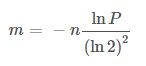
哈希函数数目k公式:

Python中已经有实现布隆过滤器的包:pybloom
安装
pip install pybloom
简单的看一下实现:
class BloomFilter(object):
FILE_FMT = b'>> b = BloomFilter(capacity=100000, error_rate=0.001)
>>> b.add("test")
False
>>> "test" in b
True
"""
if not (0 < error_rate < 1):
raise ValueError("Error_Rate must be between 0 and 1.")
if not capacity > 0:
raise ValueError("Capacity must be > 0")
# given M = num_bits, k = num_slices, P = error_rate, n = capacity
# k = log2(1/P)
# solving for m = bits_per_slice
# n ~= M * ((ln(2) ** 2) / abs(ln(P)))
# n ~= (k * m) * ((ln(2) ** 2) / abs(ln(P)))
# m ~= n * abs(ln(P)) / (k * (ln(2) ** 2))
num_slices = int(math.ceil(math.log(1.0 / error_rate, 2)))
bits_per_slice = int(math.ceil(
(capacity * abs(math.log(error_rate))) /
(num_slices * (math.log(2) ** 2))))
self._setup(error_rate, num_slices, bits_per_slice, capacity, 0)
self.bitarray = bitarray.bitarray(self.num_bits, endian='little')
self.bitarray.setall(False)
def _setup(self, error_rate, num_slices, bits_per_slice, capacity, count):
self.error_rate = error_rate
self.num_slices = num_slices
self.bits_per_slice = bits_per_slice
self.capacity = capacity
self.num_bits = num_slices * bits_per_slice
self.count = count
self.make_hashes = make_hashfuncs(self.num_slices, self.bits_per_slice)
def __contains__(self, key):
"""Tests a key's membership in this bloom filter.
>>> b = BloomFilter(capacity=100)
>>> b.add("hello")
False
>>> "hello" in b
True
"""
bits_per_slice = self.bits_per_slice
bitarray = self.bitarray
hashes = self.make_hashes(key)
offset = 0
for k in hashes:
if not bitarray[offset + k]:
return False
offset += bits_per_slice
return True 计算公式基本一致。
算法将位图分成了k段(代码中的num_slices,也就是哈希函数的数量k),每段长度为代码中的bits_per_slice,每个哈希函数只负责将对应的段中的bit置为1:
for k in hashes:
if not skip_check and found_all_bits and not bitarray[offset + k]:
found_all_bits = False
self.bitarray[offset + k] = True
offset += bits_per_slice
当期望误判率为0.001时,m与n的比率大概是14:
>>> import math >>> abs(math.log(0.001))/(math.log(2)**2) 14.37758756605116
当期望误判率为0.05时,m与n的比率大概是6:
>>> import math >>> abs(math.log(0.05))/(math.log(2)**2) 6.235224229572683
上述题目中,m最大为320亿,n为50亿,误判率大概为0.04,在可以接受的范围:
>>> math.e**-((320/50.0)*(math.log(2)**2)) 0.04619428041606246
应用
布隆过滤器一般用于在大数据量的集合中判定某元素是否存在:
1. 缓存穿透:
缓存穿透,是指查询一个数据库中不一定存在的数据。正常情况下,查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并将查询到的对象放进缓存。如果每次都查询一个数据库中不存在的key,由于缓存中没有数据,每次都会去查询数据库,很可能会对数据库造成影响。
缓存穿透的一种解决办法是为不存在的key缓存一个空值,直接在缓存层返回。这样做的弊端就是缓存太多空值占用了太多额外的空间,这点可以通过给缓存层空值设立一个较短的过期时间来解决。
另一种解决办法就是使用布隆过滤器,查询一个key时,先使用布隆过滤器进行过滤,如果判断请求查询key值存在,则继续查询数据库;如果判断请求查询不存在,直接丢弃。
2. 爬虫:
在网络爬虫中,用于URL去重策略。
3. 垃圾邮件地址过滤
由于垃圾邮件发送者可以不停地注册新地址,垃圾邮件的Email地址是一个巨量的集合。使用哈希表存贮几十亿个邮件地址可能需要上百GB的内存,而布隆过滤器只需要哈希表1/8到1/4的大小就能解决问题。布隆过滤器决不会漏掉任何一个在黑名单中的可疑地址。至于误判问题,常见的补救办法是在建立一个小的白名单,存储那些可能被误判的清白邮件地址。
4. Google的BigTable
Google的BigTable也使用了布隆过滤器,以减少不存在的行或列在磁盘上的I/O。
5. Summary Cache
Summary Cache是一种用于代理服务器Proxy之间共享Cache的协议。可以使用布隆过滤器构建Summary Cache,每一个Cache的网页由URL唯一标识,因此Proxy的Cache内容可以表示为一个URL列表。进而我们可以将URL列表这个集合用布隆过滤器表示。
扩展
要实现删除元素,可以采用Counting Bloom Filter。它将标准布隆过滤器位图的每一位扩展为一个小的计数器(Counter),插入元素时将对应的k个Counter的值分别加1,删除元素时则分别减1:
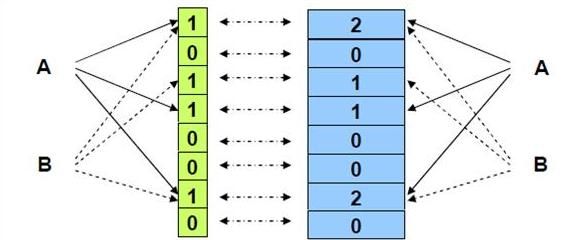
代价就是多了几倍的存储空间。
==============================================================================
HyperLogLog与布隆过滤器都是针对大数据统计存储应用场景下的知名算法。
HyperLogLog是在大数据的情况下关于数据基数的空间复杂度优化实现,布隆过滤器是在大数据情况下关于检索一个元素是否在一个集合中的空间复杂度优化后的实现。
在传统的数据量比较低的应用服务中,我们要实现数据基数和数据是否存在分析的功能,通常是简单的把所有数据存储下来,直接count一下就是基数了,而直接检索一个元素是否在一个集合中也很简单。
但随着数据量的急剧增大,传统的方式已经很难达到工程上的需求。过大的数据量无论是在存储还是在查询方面都存在巨大的挑战,无论我们是用位存储还是树结构存储等方式来优化,都没法达到大数据时代的要求或者是性价比太低。
HyperLogLog原理
最直白的解释是,给定一个集合 S,对集合中的每一个元素,我们做一个哈希,假设生成一个 16 位的比特串,从所有生成的比特串中挑选出前面连续 0 次数最多的比特串,假设为 0000000011010110,连续 0 的次数为 8,因此我们可以估计该集合 S 的基数为 2^9。当然单独用这样的单一估计偶然性较大,导致误差较大,因此在实际的 HyperLogLog 算法中,采取分桶平均原理了来消除误差。(这段话引用了 HyperLogLog 原理 中的描述,还有一些细节实现 感兴趣可阅读 https://blockchain.iethpay.com/hyperloglog-theory.html)
特点:实现牺牲了一定的准确度(在一些场景下是可以忽略的),但却实现了空间复杂度上的极大的压缩,可以说是性价比很高的。
虽然基数不完全准确,但是可以符合,随着数量的递增,基数也是递增的。
布隆过滤器原理
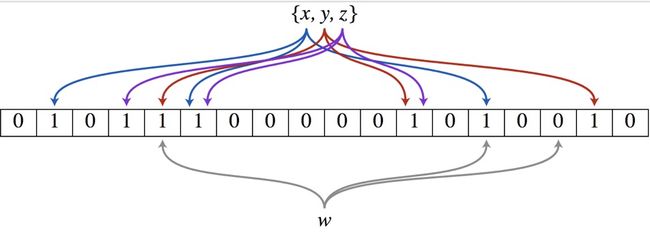
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k,以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置为0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。(这段话与图片引用于 布隆过滤器(Bloom Filter)的原理和实现 中的描述,还有一些细节实现 感兴趣可阅读 https://www.cnblogs.com/cpselvis/p/6265825.html)
特点:巧妙的使用hash算法和bitmap位存储的方式,极大的节约了空间。
由于主要用的是hash算法的特点,所有满足和hash算法相同的规则:当过滤器返回 true时(表示很有可能该值是存在的),有一定概率是误判的,即可能不存在;当过滤器返回false时(表示确定不存在),是可以完全相信的。
我们换个数据的角度来看规则:当数据添加到布隆过滤器中时,对该数据的查询一定会返回true;当数据没有插入过滤器时,对该数据的查询大部分情况返回false,但有小概率返回true,也就是误判。
我们知道它最终满足的规则和hash的规则是一致的,只是组合了多个hash,使用了bitmap来存储,大大优化了存储的空间和判断的效率。
redis中的HyperLogLog
在redis中对HyperLogLog 的支持早在2.8.9的时候就有了。它的操作非常简单
- PFADD 给HyperLogLog添加值
- PFCOUNT 获取基数
- PFMERGE 合并两个HyperLogLog数据(完美合并,分别添加和统一添加的结果是一致的)
redis中的布隆过滤器(rebloom模块扩展)
在redis中的布隆过滤器的支持是在redis4.0后支持插件的情况下,通过插件的方式实现的 ,redis的布隆过滤器插件地址:https://github.com/RedisLabsModules/rebloom
它的操作也很简单,以下为几个主要命令,其它命令请参考文档 https://github.com/RedisLabsModules/rebloom/blob/master/docs/Bloom_Commands.md
BF.RESERVE {key} {error_rate} {size} 创建一个布隆过滤器 key为redis存储键值,error_rate 为错误率(大于0,小于1),size为预计存储的数量(size是比较关键的,需要根据自己的需求情况合理估计,设置太小的话会增大错误率,设置太大会占用过多不必要的空间)BF.ADD {key} {item} 添加值到布隆过滤器中(当过滤器不存在的时候会,会以默认值自动创建一个,建议最好提前创建好) key为redis存储键值,item为值(如需要添加多个,请使用BF.MADD 可同时添加多个)
BF.EXISTS {key} {item} 判断值是否存在过滤器中 true(表示很可能存在) false (表示绝对不存在)
参考文章:
Redis中的布隆过滤器实现(rebloom模块扩展)
下载并编译
git clone git://github.com/RedisLabsModules/rebloom
cd rebloom
make
配置文件中加载rebloom
loadmodule /your_path/rebloom.so
重启Redis服务器即可
./bin/redis-cli -h 127.0.0.1 -p 6379 -a ****** shutdown
./bin/redis-server redis.conf
rebloom在Redis中的使用
bloom filter定义
BF.RESERVE {key} {error_rate} {capacity}
使用给定的期望错误率和初始容量创建空的Bloom过滤器(如果不存在的话)。如果打算向Bloom过滤器中添加许多项,则此命令非常有用,否则只能使用BF.ADD 添加项。
初始容量和错误率将决定过滤器的性能和内存使用情况。一般来说,错误率越小(即对误差的容忍度越低),每个过滤器条目的空间消耗就越大。
bloom filter基本操作
1,BF.ADD {key} {item}
单条添加元素
向Bloom filter添加一个元素,如果该key不存在,则创建该key(过滤器)。
如果项是新插入的,则为“1”;如果项以前可能存在,则为“0”。
2,BF.MADD {key} {item} [item...]
批量添加元素
布尔数(整数)的数组。返回值为0或1的范围的数据,这取决于是否将相应的输入元素新添加到过滤器中,或者是否已经存在。
3,BF.EXISTS {key} {item}
判断单个元素是否存在
如果存在,返回1,否则返回0
4,BF.MEXISTS {key} {item} [item...]
判断多个元素是否存在
布尔数(整数)的数组。返回值为0或1的范围的数据,这取决于是否将相应的元是否已经存在于key中。
127.0.0.1:8001> bf.reserve bloom_filter_test 0.0000001 1000000 OK 127.0.0.1:8001> bf.reserve bloom_filter_test 0.0000001 1000000 (error) ERR item exists 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.add bloom_filter_test key1 (integer) 1 127.0.0.1:8001> bf.add bloom_filter_test key2 (integer) 1 127.0.0.1:8001> 127.0.0.1:8001> bf.madd bloom_filter_test key2 key3 key4 key5 1) (integer) 0 2) (integer) 1 3) (integer) 1 4) (integer) 1 127.0.0.1:8001> bf.exists bloom_filter_test key2 (integer) 1 127.0.0.1:8001> bf.exists bloom_filter_test key3 (integer) 1 127.0.0.1:8001> bf.mexists bloom_filter_test key3 key4 key5 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:8001>
5,bf.insert
bf.insert{key} [CAPACITY {cap}] [ERROR {ERROR}] [NOCREATE] ITEMS {item…}
该命令将向bloom过滤器添加一个或多个项,如果它还不存在,则默认情况下创建它。有几个参数可用于修改此行为。
key:过滤器的名称
capacity:如果指定了,应该在后面加上要创建的过滤器的所需容量。如果过滤器已经存在,则忽略此参数。如果自动创建了过滤器,并且没有此参数,则使用默认容量(在模块级指定)。见bf.reserve。
error:如果指定了,后面应该跟随着新创建的过滤器的错误率(如果它还不存在)。如果自动创建过滤器而没有指定错误,则使用默认的模块级错误率。见bf.reserve。
nocreate:如果指定,表示如果过滤器不存在,就不应该创建它。如果过滤器还不存在,则返回一个错误,而不是自动创建它。如果需要在创建过滤器和添加过滤器之间进行严格的分离,可以使用这种方法。将NOCREATE与容量或错误一起指定是一个错误。
item:指示要添加到筛选器的项的开头。必须指定此参数。
127.0.0.1:8001> bf.insert bloom_filter_test2 items key1 key2 key3 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:8001> bf.insert bloom_filter_test2 items key1 key2 key3 1) (integer) 0 2) (integer) 0 3) (integer) 0 127.0.0.1:8001> bf.insert bloom_filter_test2 capacity 10000 error 0.00001 nocreate items key1 key2 key3 1) (integer) 0 2) (integer) 0 3) (integer) 0 127.0.0.1:8001> 127.0.0.1:8001> bf.insert bloom_filter_test2 capacity 10000 error 0.00001 nocreate items key4 key5 key6 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:8001>
bf持久化操作
BF.SCANDUMP {key} {iter}
对bloom过滤器进行增量保存。这对于不能适应常规save和restore模型的大型bloom filter非常有用。
第一次调用这个命令时,iter的值应该是0。这个命令将返回连续的(iter, data)对,直到(0,NULL),以表示完成
Python伪代码演示:
chunks = []
iter = 0
while True:
iter, data = BF.SCANDUMP(key, iter)
if iter == 0:
break
else:
chunks.append([iter, data])
# Load it back
for chunk in chunks:
iter, data = chunk
BF.LOADCHUNK(key, iter, data)
bf.scandump示例
127.0.0.1:8001> bf.scandump bloom_filter_test2 0
1) (integer) 1
2) "\x06\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x04\x00\x00\x00\x80\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x06\x00\x00\x00\x00\x00\x00\x00{\x14\xaeG\xe1z\x84?\x88\x16\x8a\xc5\x8c+#@\a\x00\x00\x00j\x00\x00\x00\n"
127.0.0.1:8001> bf.scandump bloom_filter_test2 1
1) (integer) 129
2) "\x00\x00\x00\x00\xa2\x00\x00\x00\x00\x00\x00B\x01\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00 \x00\x00\b\x00\x00\x00\x00\b\x00\x00@\x00\x01\x04\x18\x02\x00\x00\x00\x82\x00\x00\x80@\x00\b\x00\x00\x00\x00 \x00\x00@\x00\x00\x00\x00\x18\b\x00\b\x00\b\x00\x80B\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00\x00\x00 (\x00\x00\x00\x00@\x00\x00\x00\x00@\x00\x00\x04\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00\x00\x80\x00\x00@\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\b"
127.0.0.1:8001> bf.scandump bloom_filter_test2 129
1) (integer) 0
2) ""
127.0.0.1:8001>
blool filter数据类型的属性
bf.debug
这里可以看到,随着bloom filter元素的增加,其空间容量也在不断地增加
127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:5" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:5 ratio:1e-07" 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:128955" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:128955 ratio:1e-07" 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:380507" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:380507 ratio:1e-07" 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:569166" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:569166 ratio:1e-07" 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:852316" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:852316 ratio:1e-07" 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:1000005" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:1000005 ratio:1e-07" 127.0.0.1:8001>
关于布隆过滤器数据类型的空间分析
redis的bigkeys选项可以分析整个实例中的big keys信息,但是无法分析出MBbloom--类型的key值得大小
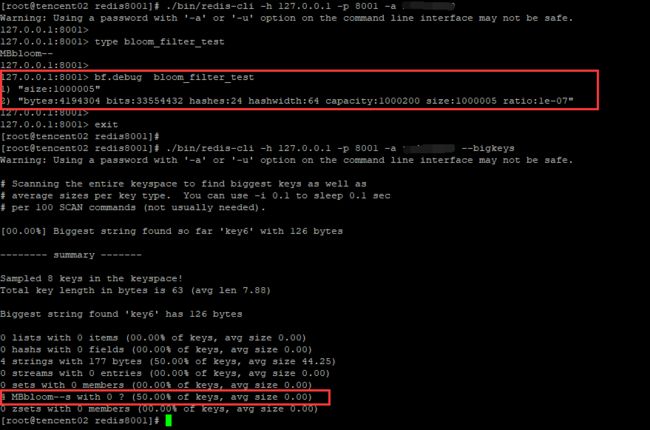
这里基于Redis的debug object功能,实现对MBbloom--类型的key的统计(没有找到怎么用Python执行bf.debug原生命令的执行方式)。
import redis
import sys
import time
import random
def get_bf_bigkeys():
try:
redis_conn = redis.StrictRedis(host='127.0.0.1', port=8001, db=0, password='******')
except:
print("connect redis error")
sys.exit(1)
dict_key = {}
cursor = 1
while cursor != 0:
if cursor == 1:
key = redis_conn.scan(cursor=0, match='*', count=5000)
else:
key = redis_conn.scan(cursor=cursor,match='*', count=5000)
cursor = key[0]
if len(key[1]) > 0:
for var in key[1]:
if str(redis_conn.type(var), encoding = "utf-8") == 'MBbloom--':
info = redis_conn.debug_object(var)
dict_key[var] = float(info['serializedlength']) / 1024 / 1024 # byte ---> mb
res = sorted(dict_key.items(), key=lambda dict_key: dict_key[1], reverse=True)
for i in range(10 if len(res) > 10 else len(res)):
print(res[i])
if __name__ == "__main__":
get_bf_bigkeys()
统计结果示例如下
[root@tencent02 redis8001]# python3 static_big_bf_keys.py (b'bloom_filter_test', 4.000059127807617) (b'my_bf2', 0.04577445983886719) (b'bloom_filter_test2', 0.00014019012451171875) (b'my_bf1', 0.0001220703125) [root@tencent02 redis8001]#
===================================================================
1、主要功能
提高随机读的性能
介绍一下HBase的块索引机制。块索引是HBase固有的一个特性,因为HBase的底层数据是存储在HFile中的,而每个HFile中存储的是有序的
但实际应用中,仅仅只有块索引满足不了需求,这是因为,块索引能帮助我们更快地在一个文件中找到想要的数据,但是我们可能依然需要扫描很多文件。而布隆过滤器就是为解决这个问题而生。因为布隆过滤器的作用是,用户可以立即判断一个文件是否包含特定的行键,从而帮我们过滤掉一些不需要扫描的文件。如下图所示,块索引显示每个文件中都可能包含对应的行键,而布隆过滤器能帮我们跳过一些明显不包含对应行键的文件。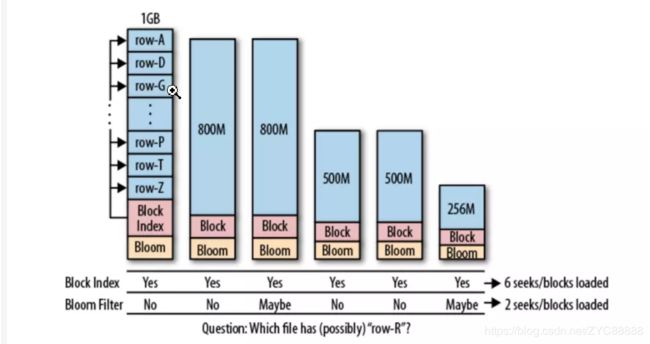
2、存储开销
bloom filter的数据存在StoreFile的meta中,一旦写入无法更新,因为StoreFile是不可变的。Bloomfilter是一个列族(cf)级别的配置属性,如果你在表中设置了Bloomfilter,那么HBase会在生成StoreFile时包含一份bloomfilter结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。所以,开启bloomfilter会有一定的存储及内存cache开销。
3、控制粒度
a)ROW
根据KeyValue中的row来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r3 cf:q1 v)、kv4(r4 cf:q1 v)
如果设置了CF属性中的bloomfilter为ROW,那么get(r1)时就会过滤sf2,get(r3)就会过滤sf1
b)ROWCOL
根据KeyValue中的row+qualifier来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r1 cf:q2 v)、kv4(r2 cf:q2 v)
如果设置了CF属性中的bloomfilter为ROW,无论get(r1,q1)还是get(r1,q2),都会读取sf1+sf2;而如果设置了CF属性中的bloomfilter为ROWCOL,那么get(r1,q1)就会过滤sf2,get(r1,q2)就会过滤sf1
4、常用场景
1、根据key随机读时,在StoreFile级别进行过滤
2、读数据时,会查询到大量不存在的key,也可用于高效判断key是否存在
5、举例说明
假设x、y、z三个key存在于table中,W不存在
使用Bloom Filter可以帮助我们减少为了判断key是否存在而去做Scan操作的次数
step1)分别对x、y、z运算hash函数取得bit mask,写到Bloom Filter结构中
step2)对W运算hash函数,从Bloom Filter查找bit mask
如果不存在:三个Bit位至少有一个为0,W肯定不存在该(Bloom Filter不会漏判)
如果存在 :三个Bit位全部全部等于1,路由到负责W的Region执行scan,确认是否真的存在(Bloom Filter有极小的概率误判)
6、源码解析
1.get操作会enable bloomfilter帮助剔除掉不会用到的Storefile
在scan初始化时(get会包装为scan)对于每个storefile会做shouldSeek的检查,如果返回false,则表明该storefile里没有要找的内容,直接跳过
if (memOnly == false
&& ((StoreFileScanner) kvs).shouldSeek(scan, columns)) {
scanners.add(kvs);
}shouldSeek方法:如果是scan直接返回true表明不能跳过,然后根据bloomfilter类型检查。
if (!scan.isGetScan()) {
return true;
}
byte[] row = scan.getStartRow();
switch (this.bloomFilterType) {
case ROW:
return passesBloomFilter(row, 0, row.length, null, 0, 0);
case ROWCOL:
if (columns != null && columns.size() == 1) {
byte[] column = columns.first();
return passesBloomFilter(row, 0, row.length, column, 0, column.length);
}
// For multi-column queries the Bloom filter is checked from the
// seekExact operation.
return true;
default:
return true;
}2.指明qualified的scan在配了rowcol的情况下会剔除不会用掉的StoreFile。
对指明了qualify的scan或者get进行检查:seekExactly
// Seek all scanners to the start of the Row (or if the exact matching row
// key does not exist, then to the start of the next matching Row).
if (matcher.isExactColumnQuery()) {
for (KeyValueScanner scanner : scanners)
scanner.seekExactly(matcher.getStartKey(), false);
} else {
for (KeyValueScanner scanner : scanners)
scanner.seek(matcher.getStartKey());
}如果bloomfilter没命中,则创建一个很大的假的keyvalue,表明该storefile不需要实际的scan
public boolean seekExactly(KeyValue kv, boolean forward)
throws IOException {
if (reader.getBloomFilterType() != StoreFile.BloomType.ROWCOL ||
kv.getRowLength() == 0 || kv.getQualifierLength() == 0) {
return forward ? reseek(kv) : seek(kv);
}
boolean isInBloom = reader.passesBloomFilter(kv.getBuffer(),
kv.getRowOffset(), kv.getRowLength(), kv.getBuffer(),
kv.getQualifierOffset(), kv.getQualifierLength());
if (isInBloom) {
// This row/column might be in this store file. Do a normal seek.
return forward ? reseek(kv) : seek(kv);
}
// Create a fake key/value, so that this scanner only bubbles up to the top
// of the KeyValueHeap in StoreScanner after we scanned this row/column in
// all other store files. The query matcher will then just skip this fake
// key/value and the store scanner will progress to the next column.
cur = kv.createLastOnRowCol();
return true;
}这边为什么是rowcol才能剔除storefile纳,很简单,scan是一个范围,如果是row的bloomfilter不命中只能说明该rowkey不在此storefile中,但next rowkey可能在。而rowcol的bloomfilter就不一样了,如果rowcol的bloomfilter没有命中表明该qualifiy不在这个storefile中,因此这次scan就不需要scan此storefile了!
7、总结
1.任何类型的get(基于rowkey或row+col)Bloom Filter的优化都能生效,关键是get的类型要匹配Bloom Filter的类型
2.基于row的scan是没办法走Bloom Filter的。因为Bloom Filter是需要事先知道过滤项的。对于顺序scan是没有事先办法知道rowkey的。而get是指明了rowkey所以可以用Bloom Filter,scan指明column同理。
3.row+col+qualify的scan可以去掉不存在此qualify的storefile,也算是不错的优化了,而且指明qualify也能减少流量,因此scan尽量指明qualify
======================================
ES的聚合是其一大特色。然而出于性能的考虑, ES的聚合是以分片Shard为单位,而非Index为单位, 所以
有些聚合的准确性是需要注意的。 比如: TermAggregations.
es的基数聚合使用到了hyperloglog算法。 出于好奇,了解了一下。
在海量数据场景下, 我们通常会遇到这样的两个问题:
-
数据排重。比如在推送消息场景,消息重复对用户是打扰, 用户发券场景, 重复发券就是损失了。
- pv/uv统计。这类场景下, 对精确度要求没必要锱铢必较。
如何高效解决这两类问题呢?
对于数据排重, 我们可以使用布隆过滤器。java 样列代码如下:
BloomFilter bloomFilter = BloomFilter.create(new Funnel() {
private static final long serialVersionUID = 1L;
@Override
public void funnel(String arg0, PrimitiveSink arg1) {
arg1.putString(arg0, Charsets.UTF_8);
}
}, 1024*1024*32);
bloomFilter.put("asdf");
bloomFilter.mightContain("asdf"); 对于计数, 我们可以使用HyperLogLog算法,ES中已经有相关的实现。
其实封装一下,布隆过滤器也是能直接实现HyperLogLog算法的功能的。
https://blockchain.iethpay.com/hyperloglog-theory.html hyperloglog原理
https://www.cnblogs.com/cpselvis/p/6265825.html 布隆过滤器原理
http://redisdoc.com/hyperloglog/index.html redis的hyperloglog的使用
https://github.com/RedisLabsModules/rebloom/blob/master/docs/Bloom_Commands.md redis的布隆过滤器的使用