Hadoop原理之_Azkaban任务调度
Azkaban是一个Hadoop workflow定时调度工具,它解决了多个Hadoop任务单元之间的前后依赖关系。它提供了十分友好的用户界面,使用简单,容易上手。在本博文中,你将学到,Azkaban的安装部署,Azkaban基础架构,Azkaban定时调度工作流程(包含Shell、MapReduce、Hive等)等重要知识
一、任务调度概述
1. 为什么需要工作流调度系统
1)一个完整的数据分析系统通常都是由大量任务单元组成:
shell 脚本程序,java 程序,mapreduce 程序、hive 脚本等。
2)各任务单元之间存在时间先后及前后依赖关系。
3)为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行。
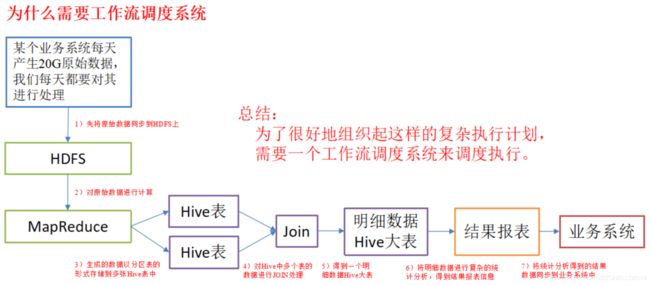
例如,我们可能有这样一个需求,某个业务系统每天产生 20G 原始数据,我们每天都要对其进行处理,处理步骤如下所示:
(1)通过 Hadoop 先将原始数据同步到 HDFS 上;
(2)借助 MapReduce 计算框架对原始数据进行计算,生成的数据以分区表的形式存储到多张 Hive 表中;
(3)需要对 Hive 中多个表的数据进行 JOIN处理,得到一个明细数据 Hive 大表;
(4)将明细数据进行复杂的统计分析,得到结果报表信息;
(5)需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
如下图所示:
2. 常见工作流调度工具
1)简单的任务调度:
直接使用 linux 的 crontab 来定义。
2)复杂的任务调度:
开发调度平台或使用现成的开源调度系统,比如 Ooize、Azkaban、Cascading、Hamake 等。
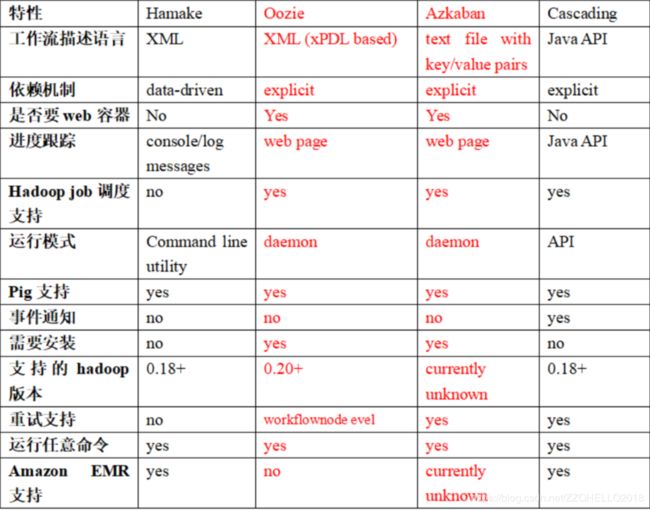
3.各种调度工具对比
下面的表格对上述四种 hadoop 工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在显著的区别,在做技术选型的时候,可以提供参考。
二、 Azkaban简介
Azkaban 是由 Linkedin 开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban 定义了一种 KV 文件格式来建立任务之间的依赖关系,并提供一个易于使用的 web 用户界面维护和跟踪你的工作流。
它有如下功能特点:
1)Web 用户界面
2)方便上传工作流
3)方便设置任务之间的关系
4)调度工作流
5)认证/授权(权限的工作)
6)能够杀死并重新启动工作流
7)模块化和可插拔的插件机制
8)项目工作区
9)工作流和任务的日志记录和审计
下载地址:http://azkaban.github.io/downloads.html
三、Azkaban 与 Oozie 对比
对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,Ooize 相比 Azkaban 是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器 Azkaban 是很不错的候选对象。
详情如下:
1)功能
两者均可以调度 mapreduce,pig,java,脚本工作流任务
两者均可以定时执行工作流任务
2)工作流定义
Azkaban 使用 Properties 文件定义工作流
Oozie 使用 XML 文件定义工作流
3)工作流传参
Azkaban 支持直接传参,例如·${input}
Oozie 支持参数和 EL 表达式,例如${fs:dirSize(myInputDir)}
4)定时执行
Azkaban 的定时执行任务是基于时间的
Oozie 的定时执行任务基于时间和输入数据
5)资源管理
Azkaban 有较严格的权限控制,如用户对工作流进行读/写/执行等操作
Oozie 暂无严格的权限控制
6)工作流执行
Azkaban 有两种运行模式,分别是 solo server mode(executor server 和 web server 部署在同一台节点)和multi server mode(executor server 和 web server 可以部署在不同节点)
Oozie作为工作流服务器运行,支持多用户和多工作流
7)工作流管理
Azkaban 支持浏览器以及 ajax 方式操作工作流
Oozie 支持命令行、HTTP REST、Java API、浏览器操作工作流
四、Azkaban安装部署
1.安装前准备
1)将 Azkaban Web 服务器、Azkaban 执行服务器和 MySQL 四个安装包上传到 hadoop102虚拟机的 /opt/software目录下,安装包如下
azkaban-web-server-2.5.0.tar.gz
azkaban-executor-server-2.5.0.tar.gz
azkaban-sql-script-2.5.0.tar.gz
mysql-libs.zip
2)目前 azkaban 只支持 mysql,需安装 mysql 服务器,这里默认已安装好 mysql 服务器,并建立了 root用户,密码 root。
2.安装 azkaban
1)在/opt/module/目录下创建 azkaban 目录
[atguigu@hadoop102 module]$ mkdir azkaban
2)解压 azkaban-web-server-2.5.0.tar.gz、
azkaban-executor-server-2.5.0.tar.gz、
azkaban-sql-script-2.5.0.tar.gz 到 /opt/module/azkaban 目录下
[atguigu@hadoop102 software]$ tar -zxvf azkaban-web-server-2.5.0.tar.gz
-C /opt/module/azkaban/
[atguigu@hadoop102 software]$ tar -zxvf azkaban-executor-server-2.5.0.tar.gz
-C /opt/module/azkaban/
[atguigu@hadoop102 software]$ tar -zxvf azkaban-sql-script-2.5.0.tar.gz
-C /opt/module/azkaban/
注:linux解压后-C代表解压到指定目录下
3)对解压后的文件重新命名
[atguigu@hadoop102 azkaban]$ mv azkaban-web-2.5.0/ server
[atguigu@hadoop102 azkaban]$ mv azkaban-executor-2.5.0/ executor
4)azkaban 脚本导入
进入 mysql,创建 azkaban 数据库,并将解压的脚本导入到 azkaban 数据库。
[atguigu@hadoop102 azkaban]$ mysql -uroot -p123456
-- mysql数据库中创建数据库
mysql> create database azkaban;
mysql> use azkaban;
-- 加载脚本
mysql> source /opt/module/azkaban/azkaban-2.5.0/create-all-sql-2.5.0.sql
3. 创建 SSL 配置
1)生成 keystore 的密码及相应信息
[atguigu@hadoop102 hadoop-2.7.2]$ keytool -keystore keystore -alias jetty -genkey -keyalg RSA
输入 keystore 密码:
再次输入新密码:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入<jetty>的主密码
(如果和 keystore 密码相同,按回车):
再次输入新密码:

2)将 keystore 拷贝到 azkaban web 服务器根目录中
[atguigu@hadoop102 hadoop-2.7.2]$ mv keystore /opt/module/azkaban/server/
4.时间同步配置
先配置好服务器节点上的时区,因为要保证和集群的时间一致。
1)如果在/usr/share/zoneinfo/ 这个目录下不存在时区配置文件 Asia/Shanghai,就要用 tzselect 生成。
[atguigu@hadoop102 Asia]$ tzselect
Please identify a location so that time zone rules can be set correctly.
Please select a continent or ocean.
1) Africa
2) Americas
3) Antarctica
4) Arctic Ocean
5) Asia
6) Atlantic Ocean
7) Australia
8) Europe
9) Indian Ocean
10) Pacific Ocean
11) none - I want to specify the time zone using the Posix TZ format.
#? 5
Please select a country.
1) Afghanistan 18) Israel 35) Palestine
2) Armenia 19) Japan 36) Philippines
3) Azerbaijan 20) Jordan 37) Qatar
4) Bahrain 21) Kazakhstan 38) Russia
5) Bangladesh 22) Korea (North) 39) Saudi Arabia
6) Bhutan 23) Korea (South) 40) Singapore
7) Brunei 24) Kuwait 41) Sri Lanka
8) Cambodia 25) Kyrgyzstan 42) Syria
9) China 26) Laos 43) Taiwan
10) Cyprus 27) Lebanon 44) Tajikistan
11) East Timor 28) Macau 45) Thailand
12) Georgia 29) Malaysia 46) Turkmenistan
13) Hong Kong 30) Mongolia 47) United Arab Emirates
14) India 31) Myanmar (Burma) 48) Uzbekistan
15) Indonesia 32) Nepal 49) Vietnam
16) Iran 33) Oman 50) Yemen
17) Iraq 34) Pakistan
#? 9
Please select one of the following time zone regions.
1) Beijing Time
2) Xinjiang Time
#? 1
The following information has been given:
China
Beijing Time
Therefore TZ='Asia/Shanghai' will be used.
Local time is now: Wed Jun 14 09:16:46 CST 2017.
Universal Time is now: Wed Jun 14 01:16:46 UTC 2017.
Is the above information OK?
1) Yes
2) No
#? 1
2)拷贝该时区文件,覆盖系统本地时区配置
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3)集群时间同步
sudo date -s ‘2017-06-14 09:23:45’
hwclock -w
5.配置文件
(1) Web 服务器配置
1)进入 azkaban web 服务器安装目录 conf目录,打开azkaban.properties 文件
[atguigu@hadoop102 conf]$ pwd
/opt/module/azkaban/server/conf
[atguigu@hadoop102 conf]$ vim azkaban.properties
2)按照如下配置修改 azkaban.properties 文件。
#Azkaban Personalization Settings
azkaban.name=Test #服务器UI名称,用于服务器上方显示的名字
azkaban.label=My Local Azkaban #描述
azkaban.color=#FF3601 #UI颜色
azkaban.default.servlet.path=/index #
web.resource.dir=web/ #默认根web目录
default.timezone.id=Asia/Shanghai #默认时区,已改为亚洲/上海 默认为美国
#Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类
user.manager.xml.file=conf/azkaban-users.xml #用户配置,具体配置参加下文
#Loader for projects
executor.global.properties=conf/global.properties #global配置文件所在位置
azkaban.project.dir=projects #
database.type=mysql #数据库类型
mysql.port=3306 #端口号
mysql.host=hadoop102 #数据库连接IP
mysql.database=azkaban #数据库实例名
mysql.user=root #数据库用户名
mysql.password=123456 #数据库密码
mysql.numconnections=100 #最大连接数
# Velocity dev mode
velocity.dev.mode=false
# Jetty服务器属性.
jetty.maxThreads=25 #最大线程数
jetty.ssl.port=8443 #Jetty SSL端口
jetty.port=8081 #Jetty端口
jetty.keystore=keystore #SSL文件名
jetty.password=000000 #SSL文件密码
jetty.keypassword=000000 #Jetty主密码 与 keystore文件相同
jetty.truststore=keystore #SSL文件名
jetty.trustpassword=000000 #SSL文件密码
# 执行服务器属性
executor.port=12321 #执行服务器端口
# 邮件设置
mail.sender=xxxxxxxx@163.com #发送邮箱
mail.host=smtp.163.com #发送邮箱smtp地址
mail.user=xxxxxxxx #发送邮件时显示的名称
mail.password=********** #邮箱密码
job.failure.email=xxxxxxxx@163.com #任务失败时发送邮件的地址
job.success.email=xxxxxxxx@163.com #任务成功时发送邮件的地址
lockdown.create.projects=false #
cache.directory=cache #缓存目录
2)web 服务器用户配置
在 azkaban web 服务器安装目录 conf 目录,按照如下配置修改 azkaban-users.xml 文件,增加管理员用户。
<user username="azkaban" password="azkaban" roles="admin" groups="azkaban" />
<user username="metrics" password="metrics" roles="metrics"/>
<user username="admin" password="admin" roles="admin,metrics" />
<role name="admin" permissions="ADMIN" />
<role name="metrics" permissions="METRICS"/>
</azkaban-users>
(2) 执行服务器配置
1)进入执行服务器安装目录 conf,打开 azkaban.properties
[atguigu@hadoop102 conf]$ pwd
/opt/module/azkaban/executor/conf
[atguigu@hadoop102 conf]$ vim azkaban.properties
2)按照如下配置修改 azkaban.properties 文件。
#Azkaban
default.timezone.id=Asia/Shanghai #时区
#Azkaban JobTypes 插件配置
azkaban.jobtype.plugin.dir=plugins/jobtypes #jobtype 插件所在位置
#Loader for projects
executor.global.properties=conf/global.properties
azkaban.project.dir=projects
#数据库设置
database.type=mysql #数据库类型(目前只支持mysql)
mysql.port=3306 #数据库端口号
mysql.host=192.168.25.102 #数据库IP地址
mysql.database=azkaban #数据库实例名
mysql.user=root #数据库用户名
mysql.password=123456 #数据库密码
mysql.numconnections=100 #最大连接数
#执行服务器配置
executor.maxThreads=50 #最大线程数
executor.port=12321 #端口号(如修改,请与web服务中一致)
executor.flow.threads=30 #线程数
6. 启动 web 服务器
在azkaban web服务器目录下执行启动命令
[atguigu@hadoop102 server]$ pwd
/opt/module/azkaban/server
[atguigu@hadoop102 server]$ bin/azkaban-web-start.sh
bin/azkaban-web-start.sh
7.启动执行服务器
在执行服务器目录下执行启动命令
[atguigu@hadoop102 executor]$ pwd
/opt/module/azkaban/executor
[atguigu@hadoop102 executor]$ bin/azkaban-executor-start.sh
启动完成后,在浏览器(建议使用谷歌浏览器)中输入:
https://服务器IP地址:8443,即可访问 azkaban 服务了。在登录中输入刚才新的户用名及密码,点击 login。
五、案例实战
Azkaba 内置的任务类型支持 command、java。
1. Command 类型之单 job 工作流案例
1)创建 job 描述文件
这里创建文件名为hello.job
#hello.job
type=command
command=echo 'this is hello job'
2)将 job 资源文件打包成zip文件
注意:azkaban目前只支持zip包
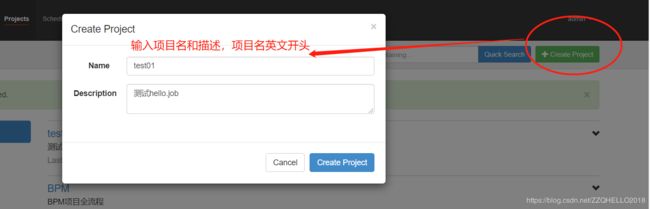
3)通过 azkaban 的 web 管理平台创建 project 并上传 job 压缩包
首先创建 project
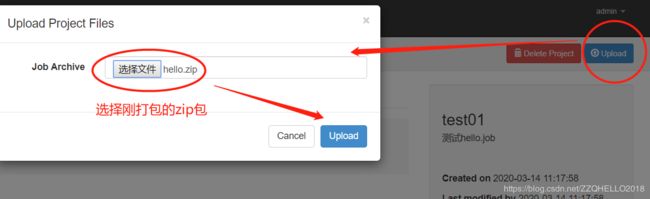
上传 zip 包
4)启动执行该 job
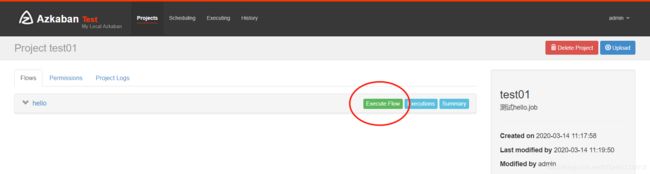
5)设置定时执行或者立即执行
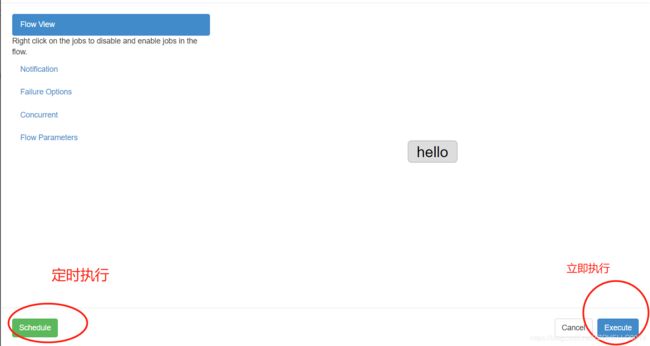
这里先演示立即执行
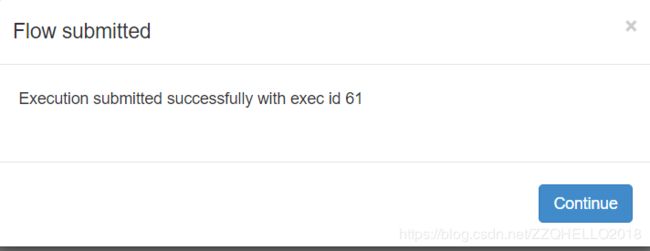
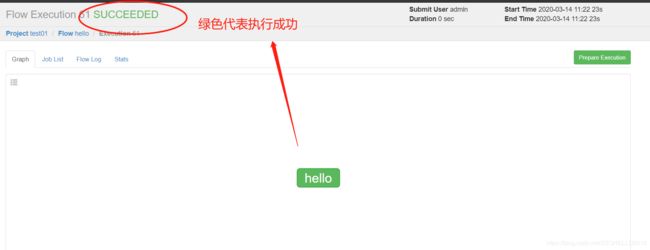
6)查看历史记录
在历史中可以查看运行记录

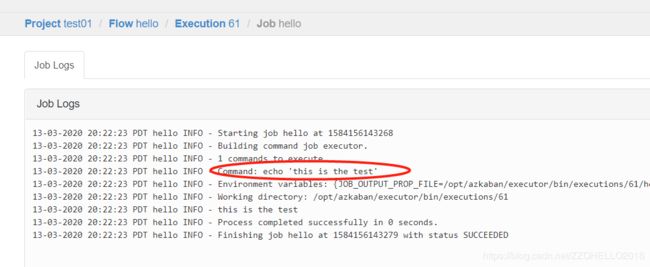
点击Flow的job可以查看细节

可以看到我们刚才脚本中的内容
补充:定时任务
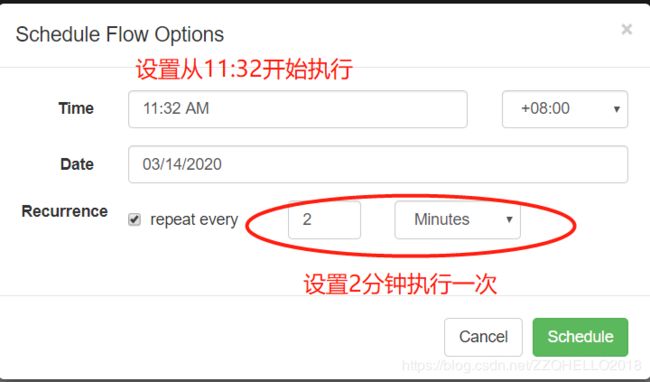
(1)刚才用的立即执行,这里用定时演示一下
点击上文的schedule按钮
(2)查看定时任务
![]()
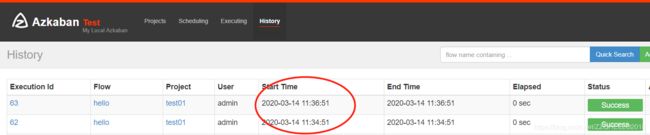
(3)查看执行历史
可以看到每两分钟执行一次
(4)删除定时任务,
点击scheduling中的Remove
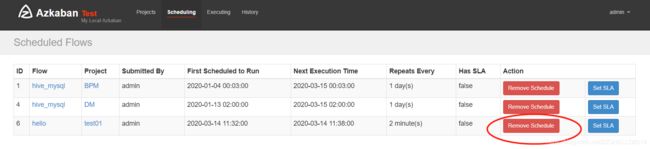
注意:定时job不能直接删除,要删除首先要用Remove Scheduling解除定时任务
2. Command 类型之多 job 工作流案例
1)创建有依赖关系的多个 job 描述
第一个 job:foo.job
# foo.job
type=command
command=echo foo
第二个job:bar.job 依赖 foo.job
# bar.job
type=command
dependencies=foo
command=echo bar
2)将所有 job 资源文件打到一个 zip 包中
3)创建工程
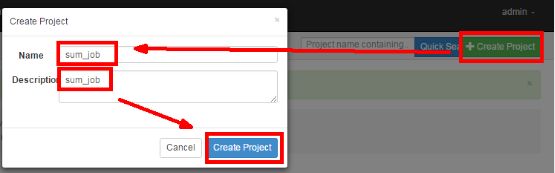
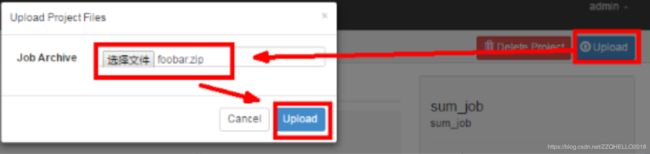
3)在 azkaban 的 web 管理界面创建工程并上传 zip 包
4)启动工作流 flow
a.步骤一

b.步骤二
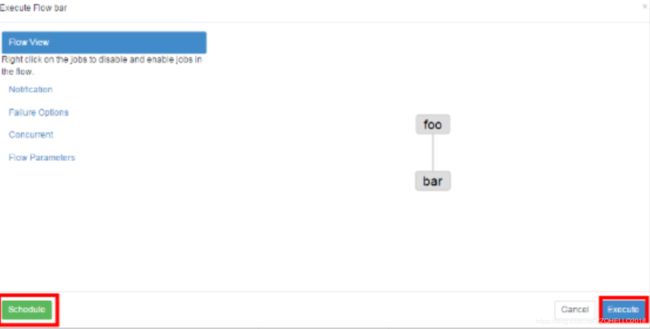
c.步骤三
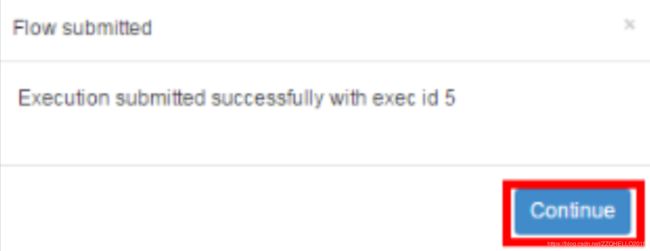
5)查看结果

3.HDFS 操作任务
1)创建 job 描述文件
# fs.job
type=command
command=/opt/module/hadoop-2.7.2/bin/hadoop fs -mkdir /azkaban
2)将 job 资源文件打包成 zip 文件
3)通过 azkaban 的 web 管理平台创建 project 并上传 job 压缩包
4)启动执行该 job
5)查看结果
4.MapReduce 任务
Mr 任务依然可以使用 command 的 job 类型来执行
1)创建 job 描述文件,及 mr 程序 jar 包(示例中直接使用 hadoop 自带的 example jar)
# mrwc.job
type=command
command=/opt/module/hadoop-2.7.2/bin/hadoop jar
hadoop-mapreduce-examples-2.7.2.jar wordcount /wordcount/input /wordcount/output
2)将所有 job 资源文件打到一个 zip 包中
3)在 azkaban 的 web 管理界面创建工程并上传 zip 包
4)启动 job
5.Hive脚本任务
1)创建 job 描述文件和 hive 脚本
(1)Hive脚本:test.sql
use default;
drop table aztest;
create table aztest(id int, name string)
row format delimited fields terminated by ',';
load data inpath '/aztest/hiveinput' into table aztest;
create table azres as select * from aztest;
insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest;
(2)Job描述文件:hivef.job
# hivef.job
type=command
command=/opt/module/hive/bin/hive -f 'test.sql'
【注:】hive -f 命令是指运行指定的sql文件
2)将所有 job 资源文件打到一个 zip 包中
3)在 azkaban 的 web 管理界面创建工程并上传 zip 包
4)启动 job
6.shell脚本任务(例如sqoop)
hadoop中的sqoop数据导入导出任务,可以用shell的形式进行任务调度。
(1)编写一个shell脚本
例如命名为oracle_hive.sh
#1、全量导入base_organization
sqoop import --hive-import --connect jdbc:oracle:thin:@172.31.13.27:1521/xtpdg --username=search --password=sea#rch#0911 --table MPLATFORM.BASE_ORGANIZATION --hive-database b2b_ods --hive-table ods_BASE_ORGANIZATION --hive-overwrite -m 1 --compression-codec org.apache.hadoop.io.compress.SnappyCodec --null-string '\\N' --null-non-string '\\N';
(2)编写job文件
命名为Oracle_hive.job
# Oracle_hive.job
type=command
command=bash Oracle_hive.sh
(3)其他job添加依赖
如果有其他job按照依赖顺序可以依次设置,例如下列load_b2b_dws_data.job依赖步骤2中job。
这里不是shell脚本了,而是一个sql文件
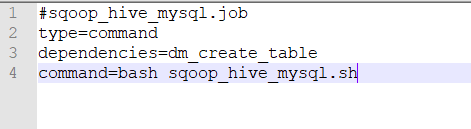
#sqoop_hive_mysql.job
type=command
dependencies=dm_create_table
command=bash sqoop_hive_mysql.sh
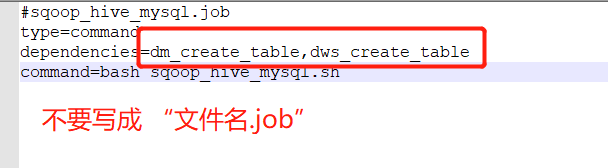
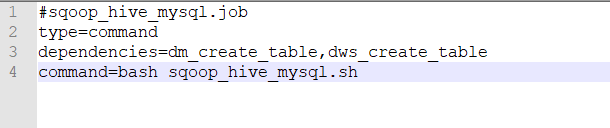
若有多个依赖,则用逗号隔开,例如
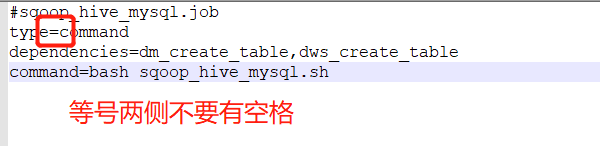
#sqoop_hive_mysql.job
type=command
dependencies=dm_create_table,dws_create_table
command=bash sqoop_hive_mysql.sh
(4)打包上传
六、注意事项(重要)
1.sqoop的sh脚本一定要用unix格式,否则上传报错$'\r': command not found
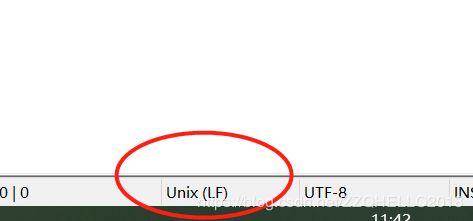
存现这种错误是因为 编写的 shell脚本是在win下编写的,每行结尾是\r\n 的Unix 结果行是\n 所以在Linux下运行脚本 会任务\r 是一个字符,所以运行错误,需要把文件转换下
2.job文件中的shell等号两边不要有空格
3.依赖后面不要带job后缀名,多个依赖用逗号隔开