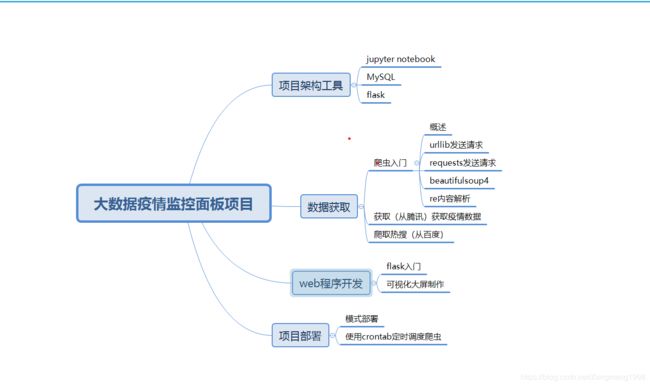
大数据疫情监控项目(Ⅰ)—爬虫入门
文章目录
- 使用urllib发送请求
- 使用requests发送请求
- 使用beautifulsoup4解析内容
- 使用re解析内容
近日在小破站看到的项目,觉得有趣,便尝试动手实操,实现脑图如下,仅以此项目向逆行者表以最崇高的敬意。
使用urllib发送请求
request.urlopen()
from urllib import request
url="http://www.baidu.com"
res=request.urlopen(url)#访问url并获得响应
print(res.geturl())#获取主机地址
print(res.getcode())#获取请求状态代码
print(res.info())#获取响应头
##html.decode("utf_8")#解码
#print(html)
http://www.baidu.com
200
Bdpagetype: 1
Bdqid: 0x9f5e52db00040d25
Cache-Control: private
Content-Type: text/html;charset=utf-8
Date: Wed, 06 May 2020 07:04:29 GMT
Expires: Wed, 06 May 2020 07:04:05 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Server: BWS/1.1
Set-Cookie: BAIDUID=9A5020C5FC0E7DC83ACD2300A0985750:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BIDUPSID=9A5020C5FC0E7DC83ACD2300A0985750; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: PSTM=1588748669; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BAIDUID=9A5020C5FC0E7DC897BF8BADA39D1B3F:FG=1; max-age=31536000; expires=Thu, 06-May-21 07:04:29 GMT; domain=.baidu.com; path=/; version=1; comment=bd
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=1435_31125_21083_31428_31341_31270_31463_31228_30824_31163_31474; path=/; domain=.baidu.com
Traceid: 1588748669021625601011483707200392924453
Vary: Accept-Encoding
Vary: Accept-Encoding
X-Ua-Compatible: IE=Edge,chrome=1
Connection: close
Transfer-Encoding: chunked
html=res.read()
#print(html)
html=html.decode('utf_8')
print(html)
……
使用requests发送请求
requests.get()
#引用与网络导入
import requests
url='http://www.baidu.com'
resp=requests.get(url)
print(resp.encoding)#查看编码
ISO-8859-1
print(resp.status_code)#查看状态码
200
html=resp.text
print(html)
ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é“  æ–°é—»
æ–°é—»
resp.encoding='utf_8'
html=resp.text
print(html)
百度一下,你就知道
print(resp.headers)#获取其稳定状态格式
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Wed, 06 May 2020 07:04:30 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:28:24 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
#尝试获取大众点评的信息
url='http://www.dianping.com'
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
res=requests.get(url,headers=header)
print(res.encoding)
print(res.status_code)
#注意网站的反爬机制,利用header可以解决,注意
UTF-8
200
使用beautifulsoup4解析内容
将复杂HTML文档转换成一个树形结构,每个节点都是python对象
- beautifulSoup(html)
- 获取节点find()、findall()/select()
- 获取属性 atrrs
- 获取文本 text
import requests
from bs4 import BeautifulSoup
url='http://wsjkw.sc.gov.cn/scwsjkw/gzbd/fyzt.shtml'
resp=requests.get(url)
print(resp.encoding)#查看编码
ISO-8859-1
resp.headers
{'Server': 'SCS', 'Date': 'Wed, 06 May 2020 06:59:18 GMT', 'Content-Type': 'text/html', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Expires': 'Wed, 06 May 2020 07:04:18 GMT', 'Cache-Control': 'max-age=300', 'Content-Encoding': 'gzip'}
resp.text#出现乱码要改变编码格式
'\r\n\r\n\r\n \r\n \r\n \r\n\r\n\r\n
使用re解析内容
- re是python自带的正则表达式模块,使用它需要一定的正则表达式基础;
- 使用方式一般为re.sea
