python习题
代码判断
line2错 是因为too many values to unpack,这个错误。Python2可以改为a, b, c = raw_input(), raw_input(), raw_input(),这样不会有语法错误,但是a, b, c都还是字符串,用type()命令可以知道,之后可能还要int()回来,所以要么使用eval(raw_input()),要么就是用Python3。
line5错,应该是math.sqrt,或者上面1直接用from math import sqrt。


没看懂

读取文件
1.read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它范围为字符串对象。
2.readline()方法每次读出一行内容,所以,读取时占用内存小,比较适合大文件,该方法返回一个字符串对象。
3.readlines()方法读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存。

重用对象池
python中对于小整数对象有一个小整数对象池,范围在[-5,257)之间。对于在这个范围内的征数,不会新建对象,直接从小整数对象池中取就行。
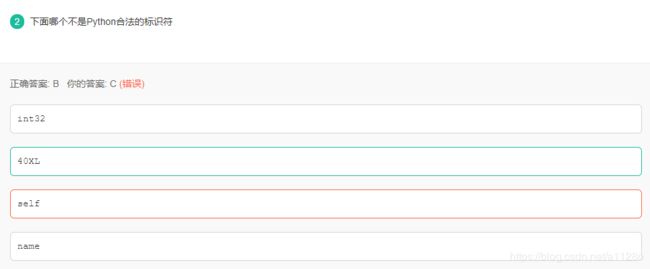
标识符
1)第一个字符必须是字母表中字母或下划线 _ 。
2)标识符的其他的部分由字母、数字和下划线组成。
3)标识符对大小写敏感。
4)不可以是python中的关键字,如False、True、None、class等。
注意:self不是python中的关键字。类中参数self也可以用其他名称命名,但是为了规范和便于读者理解,推荐使用self。
适配器
多个标志可以通过按位 OR(|) 来指定
re.M:多行匹配,影响 ^ 和 $
re.I:使匹配对大小写不敏感
分组:即用圆括号将要提取的数据包住,通过 .group()获取,一般和“|”结合使用
re.match( r’(.)on(.?) .*’, str1, re.M|re.I),将on左边和右边分组
>>print(str2.group(0))
Python's features
>>print(str2.group(1))
Pyth
>>print(str2.group(2))
's

return
return没有返回值时,函数自动返回None,Python没有Null

copy()与deepcopy()
 首先直接上结论:
首先直接上结论:
—–深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。
—–而等于赋值,并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。
—–而浅复制要分两种情况进行讨论:
1)当浅复制的值是**不可变对象(数值,字符串,元组)**时和“等于赋值”的情况一样,对象的id值与浅复制原来的值相同。
2)当浅复制的值是**可变对象(列表和元组)**时会产生一个“不是那么独立的对象”存在。有两种情况:
第一种情况:复制的 对象中无 复杂 子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
第二种情况:复制的对象中**有 复杂 子对象 **(例如列表中的一个子元素是一个列表),如果不改变其中复杂子对象,浅复制的值改变并不会影响原来的值。 但是改变原来的值 中的复杂子对象的值 会影响浅复制的值。
对于简单的 object,例如不可变对象(数值,字符串,元组),用 shallow copy 和 deep copy 没区别
复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的 子list,并未从原 object 真的「独立」出来。也就是说,如果你改变原 object 的子 list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不。
当浅复制的值是不可变对象(数值,字符串,元组)时,代码如下:
>>> a="1234567"
>>> b=a
>>> id(a)
4367619440
>>> id(b)
4367619440
>>> c=copy.copy(a)
>>> id(c)
4367619440
>>> d=copy.deepcopy(a)
>>> id(d)
4367619440
当浅复制的值是可变对象(列表,字典)时,改变的值不是 复杂子对象 代码如下:
>>> l1=[1,2,3]
>>> l2=l1
>>> l3=copy.copy(l1)
>>> id(l1)
4367654664
>>> id(l2)
4367654664
>>> id(l3)
4367628616
>>> l1.append(55)
>>> print(l1)
[1, 2, 3, 55]
>>> print(l3)
[1, 2, 3]
当浅复制的值是可变对象(列表,字典)时,改变的值是 复杂子对象 代码如下:
>>> import copy
>>> list1=[1,2,['a','b']]
>>> list2=list1
>>> list3=copy.copy(list2)
>>> list4=copy.deepcopy(list3)
>>> id(list1)
4338414656
>>> id(list2)
4338414656
>>> id(list3)
4338415016
>>> id(list4)
4338414368
>>> list1[2].append('a')
>>> id(list1)
4338414656
>>> print list1
[1, 2, ['a', 'b', 'a']]
>>> print list3
[1, 2, ['a', 'b', 'a']]
>>> print list4
[1, 2, ['a', 'b']]
>>> list1.append(33)
>>> id(list1)
4338414656
>>> id(list3)
4338415016
>>> print list1
[1, 2, ['a', 'b', 'a'], 33]
>>> print list3
python的数据存储方式
Python 存储变量的方法跟其他 OOP 语言不同。它与其说是把值赋给变量,不如说是给变量建立了一个到具体值的 reference。
当在 Python 中 a = something 应该理解为给 something 贴上了一个标签 a。当再赋值给 a 的时候,就好象把 a 这个标签从原来的 something 上拿下来,贴到其他对象上,建立新的 reference。 这就解释了一些 Python 中可能遇到的诡异情况:
>> a = [1, 2, 3]
>>> b = a
>>> a = [4, 5, 6] //赋新的值给 a
>>> a
[4, 5, 6]
>>> b
[1, 2, 3]
# a 的值改变后,b 并没有随着 a 变
>>> a = [1, 2, 3]
>>> b = a
>>> a[0], a[1], a[2] = 4, 5, 6 //改变原来 list 中的元素
>>> a
[4, 5, 6]
>>> b
[4, 5, 6]
# a 的值改变后,b 随着 a 变了
__init__与__new__方法
面向对象:
1,首先用__new__创建并返回一个实例对象,此处__new__为静态方法
2,返回的实例对象调用__init__方法进行初始化,初始化不返回任何东西,此处__init__是实例方法
init 方法为初始化方法, __new__方法才是真正的构造函数。
new__方法默认返回实例对象供__init__方法、实例方法使用。
init 方法为初始化方法,为类的实例提供一些属性或完成一些动作。
new 方法创建实例对象供__init 方法使用,__init__方法定制实例对象。
__new__是一个静态方法,而__init__是一个实例方法。

args参数
当args与位置参数和默认参数混用的情况下:(注意三者的顺序)
示例一、(*三者顺序是:位置参数、默认参数、args)
def foo(x,y=1,*args):
pass
foo (1,2,3,4,5) // 其中的x为1,y=1的值被2替换,3,4,5都给args,即args=(3,4,5)
示例二、(*三者顺序是:位置参数、args、默认参数)
def foo(x,*args,y=1):
pass
foo (1,2,3,4,5) // 其中的x为1,2,3,4,5都给args,即args=(2,3,4,5),y始终为1
kwargs:(表示的就是形参中按照关键字传值把多余的传值以字典的方式呈现)
关于kwargs与位置参数、*args、默认参数混着用的问题:(注意顺序)
**位置参数、*args、**kwargs三者的顺序必须是位置参数、*args、kwargs,不然就会报错:

Python2
在Python2中,C选项是错的,因为a=1被当做了默认参数,而默认参数只能在可变参数之前
Python参数顺序:必选参数、默认参数、可变参数和关键字参数。
Python3
在python3中,C选项是对的,因为a=1被当做了命名关键字参数,而命名关键字参数需要在可变参数之后
Python3参数顺序:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
切片slice
切片操作不会引起下标越界异常
python3关于切片的说明
The slice of s from i to j is defined as the sequence of items with index k such that i <= k < j.
If i&nbs***bsp;j is greater than len(s), use len(s).
If i is omitted or None, use 0.
If j is omitted or None, use len(s).
If i is greater than or equal to j, the slice is empty.

_foo, __foo, __foo__
python中主要存在四种命名方式:
1、object #公用方法
2、_object #半保护
被看作是“protect”,意思是只有类对象和子类对象自己能访问到这些变量,
在模块或类外不可以使用,不能用’from module import* '导入。
__object 是为了避免与子类的方法名称冲突, 对于该标识符描述的方法,父类的方法不能轻易地被子类的方法覆盖,他们的名字实际上是_classname__methodname。
3、_ _ object 全私有,全保护
私有成员private,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据,不能用’from module import *’导入。
4、_ _ object_ _ 内建方法,用户不要这样定义
socket
装饰器
@dec 装饰器,先执行dec(), 并将 @dec 下面的 函数 作为dec()的参数。 (装饰器的作用:为已经存在的对象添加额外的功能)
foo(n) = n * 2 * 3

@修饰符
将被修饰的函数作为参数,运行修饰函数
1.先运行被修饰的函数
n=3
f * n
2.将被修饰的函数作为参数
f * 3
3.运行修饰函数
(2 * 3) * 2
复数

运算符优先级
