A Review on Deep Learning Techniques Applied to Semantic Segmentation
2018-02-22 10:38:12
1. Introduction:
语义分割是计算机视觉当中非常重要的一个课题,其广泛的应用于各种类型的数据,如:2D image,video,and even 3D or volumetric data。
最近基于 deep learning 的方法,取得了非常巨大的进展,在语义分割上也是遥遥领先于传统算法。
本文对于比较流行的深度风格技术进行了总结,其主要贡献在于:
- 提供了一个非常广泛的现有分割数据集的总结;
- 一个深入的关于深度分割方法的总结,起源及其贡献;
- 关于常用的分割评价标准的总结,包括 accuracy,execution time,以及 memory footprint;
- 关于上述结果的总结,以及一系列可能的未来工作。
2. Terminology and Background Concepts:
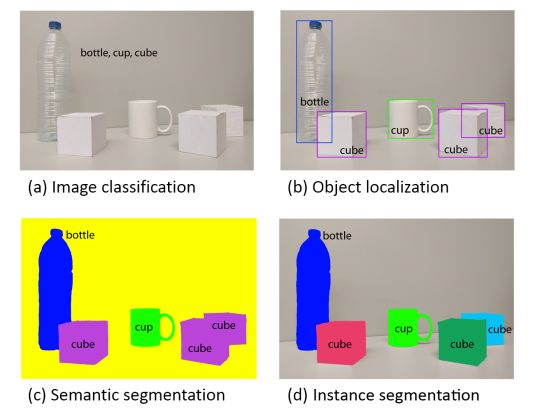
本文对视觉认知看成是一个 coarse to fine 的过程,即:由粗到细的过程。
最基本的就是 classification,然后是 localization or detection,然后更高级的是 semantic segmentation,其中,更加细致的是:instance segmentation 以及 part-based segmentation。
语义分割的目标是:make dense predictions inferring labels for every pixel,i.e. each pixel is labeled with the class of its enclosing object or region.
2.1. Common Deep Network Architecture
本节重点回顾了一些经典且重要的网络结构,正是这些网络结构的出现,才使得分割领域取得了突飞猛进的进展。常见的网络结构有:Alexnet,VGG-16,GoogLeNet,and ResNet。
AlexNet:7 layers,属于 deep learning 早期的网络结构。
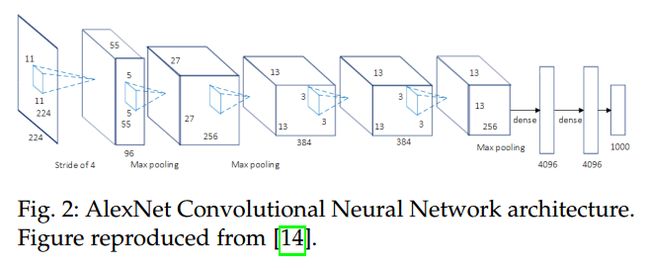
VGG:The main difference between VGG-16 and its predecessors is the use of a stack of convolution layers with small receptive fields in the first layers instead of few layers with big receptive fileds. This leads to less parameters and more non-linearities in between, thus making the decision function more discriminative and the model easier to train.

GoogLeNet:该网络进一步增加了 layer,并且引入了新的结构:Inception module。这种新的方法验证了 CNN layer 可用多种方式来堆叠,而不是传统的 sequential manner。实际上,这些模型由:a Network in Network (NiN) layer, a pooling operation, a large-size convolution layer, and small-sized convolution layer.
All of them are computed in parallel and followed by 1*1 convolution operations to reduce dimensionality.

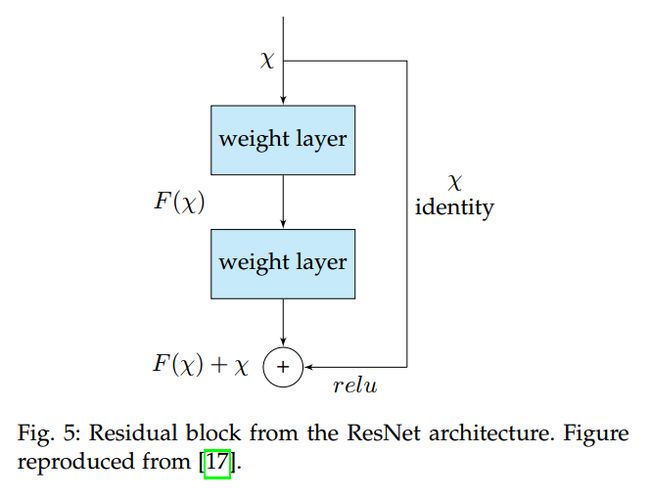
ResNet:残差网络,更是将 CNN 的深度加深到变态的级别(1k+ layer),带来了更好的性能。这是通过一种 identity skip connections 来实现的,即:将他们的输入拷贝给下一层。这种方法底层的直观的想法是:这确保了下一层学习到了新的不同的东西,至少不同于前一层的输出(different from what the input has already encoded, since it is provided with both the output of the previous layer and its unchanged input)。此外,这种连接在某种程度上,缓解了梯度消失的问题(help overcoming the vanishing gradients problem)。
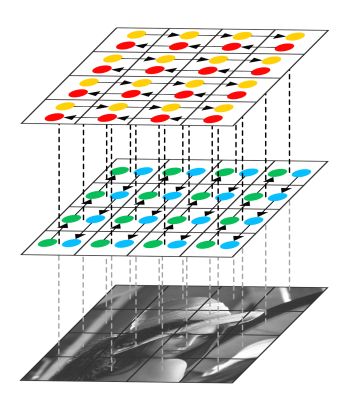
ReNet:Yoshua Bengio 等人提出 ReNet 网络结构,将 CNN 中的 Conv + Pooling 操作替换为 4 RNNs sweeping the image vertically and horizontally in both directions。
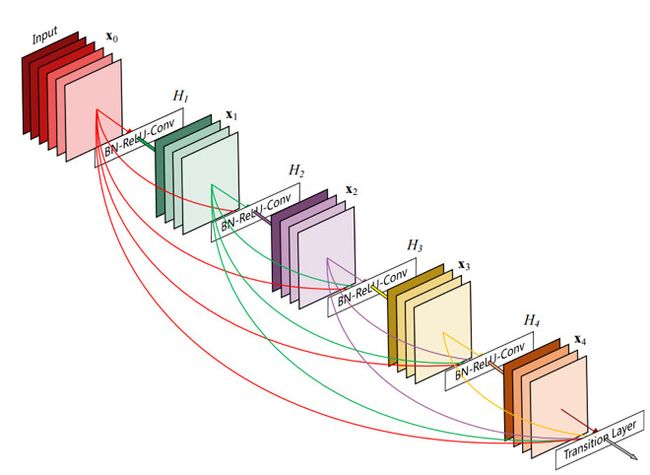
当然了,还有 CVPR 2017 年的 Dense Connected Network,这篇文章并没有回顾到,Dense Net 取得了更好的结果。
2.2 Transfer Learning:
从头开始训练一个网络是不可取的,因为这需要大量的数据,并且很难训练。现有的方法,基本都是在 pre-trained model 的基础上进一步微调出来的,而不是随机初始化一个网络参数。Yosinski et al. 已经证明,即使是 较远的 task 上迁移过来的 feature,都是比随机初始化要好的。
但是,直接将这种迁移技术应用过来也是不直观的:
一方面,想这么迁移特征,就要求那部分的网络结构要相同。这对于新提出的网络结构并不适用,因为迁移是需要利用现有网络结构的。
另一方面,当微调的时候,训练的方法和随机初始化那样的训练方法也是有很大区别的。选择哪一些层进行微调,也是非常重要的 --- 通常是网络的 high-level part of the network,因为底层的特征通常会包含一些通用的 feature --- 学习率的选择也是非常重要的,因为原本模型的参数已经很好了,这个时候,没有必要进行较大幅度的改变。
由于采集和处理分割的数据是比较困难的,导致数据量不是很大,特别是对于 RGB-D 或者 3D datasets,这些数据更是少的可怜。所以,迁移学习或者 微调技术,就显得更加重要了。所以,迁移学习已经称为分割领域一个大的趋势和一项非常重要且有效的技术了。
2.3 Data Preprocessing and Augmentation:
数据增广是一项已经被广泛应用的技术,可以增强模型的泛化能力,防止过拟合。通常是在图像或者特征空间进行一系列的转换。
常见的是在 data space 进行转换,可以产生更多的训练样本,常见的操作有:translation, rotation, warping, scaling, color space shifts, crops, etc.
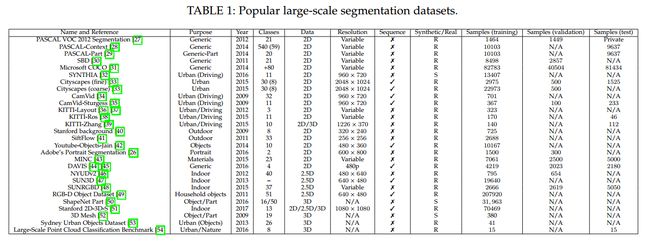
3. Datasets and Challengs
数据集这部分,感兴趣的可以参考原本,这里不一一介绍,只是列出其 dataset 名字。
3.1 2D datasets
- PASCAL Visual Object Classes (VOC)
- PASCAL Context
- PASCAL Part
- Semantic Boundaries Dataset (SBD)
- Microsoft Common Objects in Context (COCO)
- SYBTHetic Collection of Imagery and Annotations (SYNTHIA)
- Cityscapes
- Cam Vid
- KITTI
- Youtube-Objects
- Adobe's Portrait Segmentation
- Materials in Context (MINC)
- Densely-annotated VIdeo segmentation (DAVIS)
- Stanford background
- SiftFlow
3.2 2.5D Datasets
- BYUD v2
- SUN3D
- SUNRGBD
- The Object segmentation database (OSD)
- RGB-D object detection
3.3 3D datasets :
- ShapeNet Part
- Stanford 2D-3D-S
- A Benchmark for 3D Mesh Segmentation
- Sydney Urban Objects Dataset
- Large-Scale point cloud classification benchmark
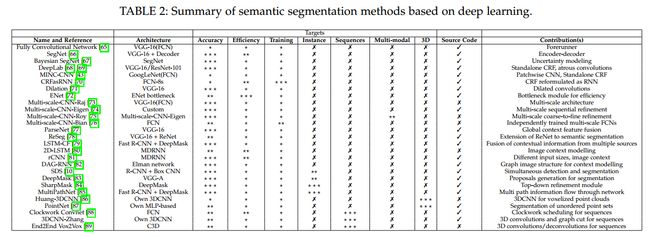
4. Methods

将深度学习应用到语义分割中的一个比较成功的方法是:FCN(fully convolutional network)。 这个工作被认为是 deep learning 在分割领域的一个里程碑。
4.1 Decoder Variants
后续的很多拓展工作,都是基于 encoder-decoder framework,encoder 用于编码输入图像,decoder 用于解码输出的feature map,表示分割的结果。
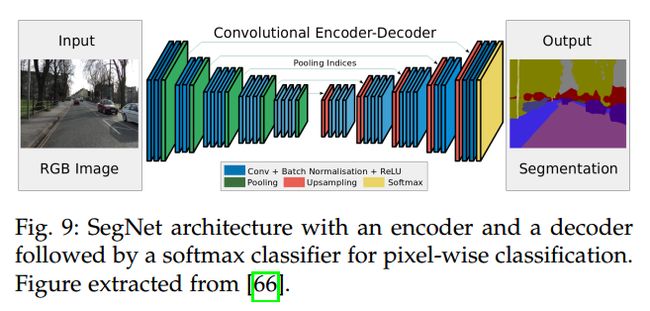
SegNet 这种网络的典型代表,其网络结构示意图如下所示:
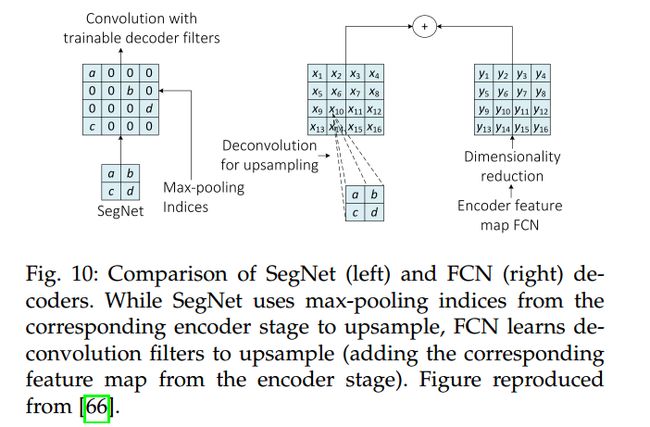
另一方面,FCN-based architecture 利用了可学习的反卷积滤波器(the learnable deconvolution filters to upsample feature maps)。在此之后,上采样的 feature maps 和 之前 卷积层的 feature map 进行相加。下图展示了这两种操作的具体细节:
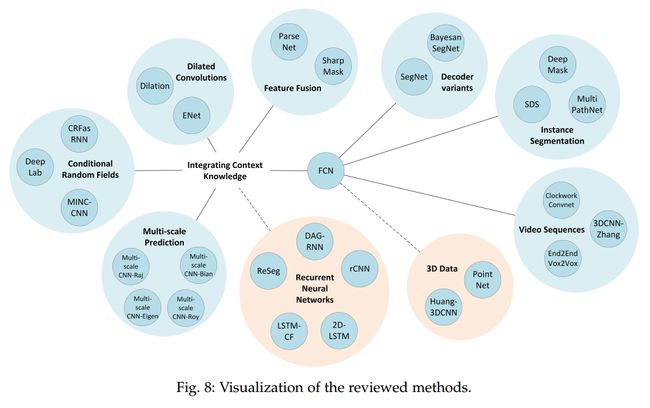
4.2 Integrating Context Knowledge
Local 和 Global 的信息对于分割来说,是非常重要的。It also implies balancing local and global information.
On the one hand, fine-grained or local information is crucial to achieve good pixel-level accuracy.
On the other hand, it is also important to integrate information from the global context of the image to be able to resolve local ambiguities.
但是,vanilla CNNs 没有很好的达到这两者之间的平衡,所以,有很多的方法被提出来处理这个问题,常见的有:refinement as a post-processing step with Conditional Random Fields (CRFs), dilated convolutions, multi-scale aggregation, or even defer the context modeling to another kind of deep networks such as RNNs.
4.2.1 Conditional Random Fields
CRF 将底层的图像信息 和 多类别的推理系统相结合 来产生最后的每一个像素的分类分数。这种结合,对于捕获长期的依赖,更加重要;但标准的 CNN 缺未能做到这一点。
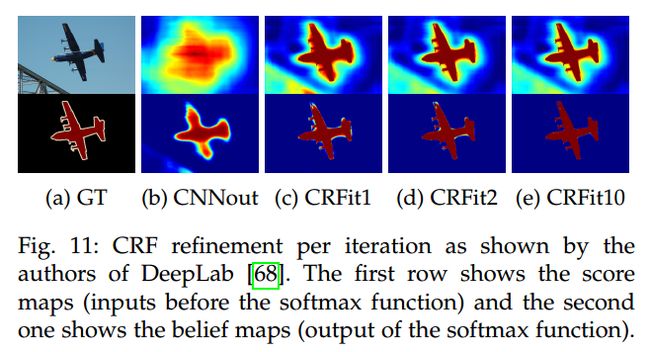
DeepLab models 将 fully connected pairwise CRF 模型作为独立的后处理步骤,来优化其分割结果。
It models each pixel as a node in the field and employs one pairwise term for each pair of pixels no matter how far they lie (this model is known as dense or fully connected factor graph). By using this model, both short and long-range interactions are taken into account, rendering the system able to recover detailed structures in the segmentation that were lost due to the spatial invariance of the CNN. Despite the fact that usually fully connected models are inefficient, this model can be efficiently approximated via probabilistic inference.
改善后的分割效果如下所示:
另一个比较突出的工作是将 CRF 结合到 网络中,做成了 end to end training 的方式。这个工作的主要贡献在于:the reformulation of the dense CRF with pairwise potentials as an intrgral part of the network。通过展开 the mean-field inference steps as RNNs,将 CRF 和 FCN 结合到一起,做到了端到端的训练。
4.2.2 Dilated Convolutions(扩张卷积)
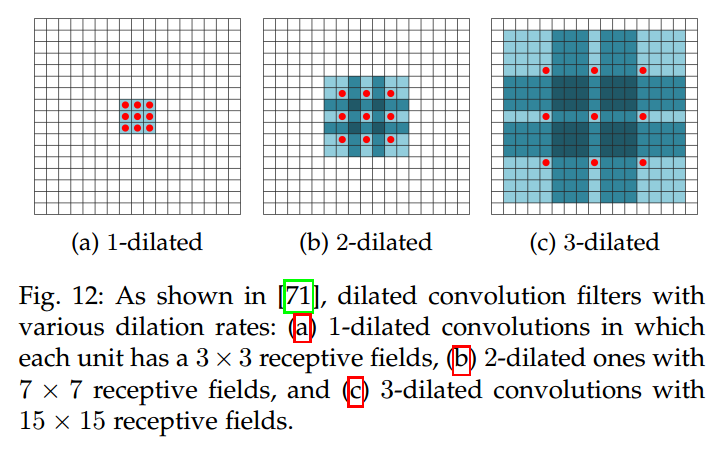
实际上,这个和在执行通常的卷积之前,扩张 filter 是一样的效果。这意味着,扩展其大小,根据 扩展率,然后将空的元素,用 0 填充。

这样做的好处在于:
1. 在没有额外损失 和 重叠的下采样 的情况下,可以得到更大的感受野。
2. 潜在的考虑了多尺度的技巧。
4.2.3 Multi-scale Prediction
将背景信息结合到网络设计中,是可能提升分割性能的方法之一,其中,多尺度处理,是常用的 trick 之一。
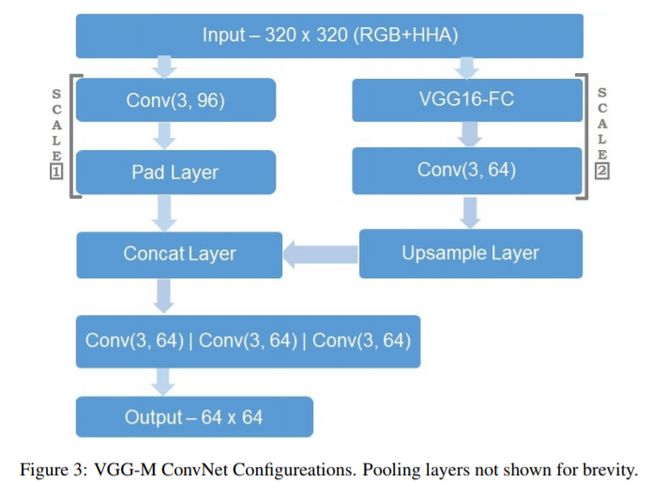

4.2.4 Feature Fusion(特征融合):
另一种将 context 信息添加到 FCN 结构中的方法是:feature fusion。一种常见的做法是:将底层的特征(global feature)和 更加局部的特征(more local feature maps)进行融合。
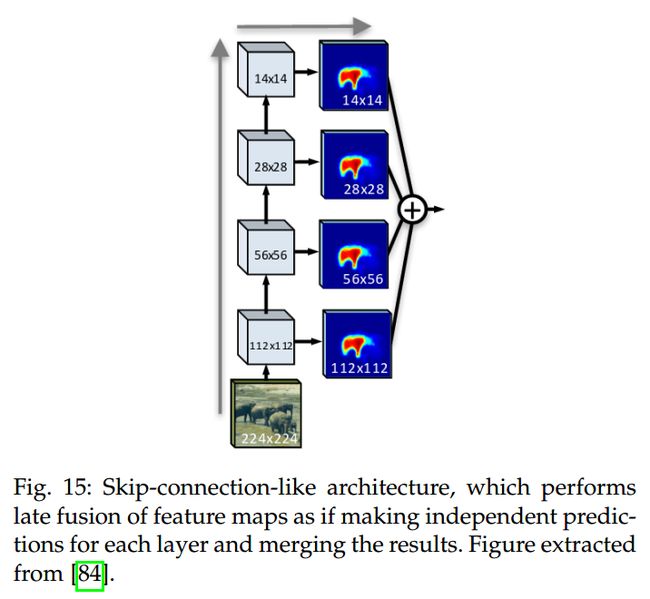
另一种方式是进行 early fusion(早期融合)。这种方法被 ParseNet 用起来了。The global feature is unpooling to the same spatial size as the local feature and then they are concatenated to generate a combined feature that is used in the next layer or to learn a classifier.

4.2.5 Recurrent Neural Network
就像我们看到的,CNN 已经被广泛的应用于多维度的数据,如 image。但是,这些网络依赖于手动设计的 kernels,使得网络仅仅作用于 local context。利用拓扑结构,RNN 已经被广泛的应用于建模 short- and long-termporal sequences. 用这种方法,将 pixel-level and local information 连接起来,RNN 可以成功的应用于建模 global contexts,然后改善语义分割的效果。但是,一个很重要的约束在于:the lack of a natural sequential structure in images and the focus of standard vanilla RNNs architecture on one-dimensional inputs。
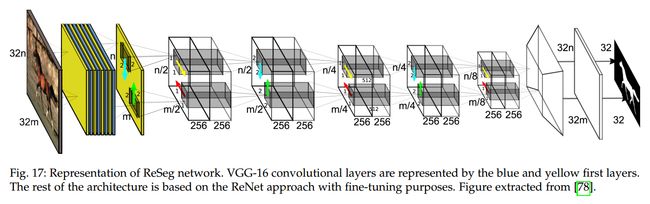
基于 ReNet model,Visin et al. 提出一种新的网络结构用于语义分割,称为:ReSeg。这种方法,首先用 VGG 提取图像的特征,然后用 ReNet layers 进行微调。最终,对 feature maps 用 transpose convolutions 进行 resize,这篇文章中,用到了 GRU(Gated Recurrent Units)替换掉了 RNNs,因为这种网络结构有较好的 memory usage 以及 computational power。
LSTM-CF(LSTM Context Fusion)是中山大学 甘宇康同学做的(哈哈哈,简称:康康),该网络考虑到了图像中特征之间的关系,用双向 LSTM 进行建模,在 RGBD 数据集上取得了不错的效果。
建模图像的全局信息,是跟 2D recurrent 方法有关的,通过在输入图像上展开水平和竖直方向的网络(by unfolding vertically and horizontally the network over the input images)。
另一种捕获全局信息的方法依赖于:利用更大的输入窗口(using bigger input windows),为了建模更大的 context information。
还有一种是利用 UCGs(Undirected cyclic graphs)来建模图像的 context 信息,进行语义分割。但是,RNNs 并不能直接用于 UCGs,可以通过 将其分解为 多个有向图(several directed graphs DAGs)。用这种方法,图像可以通过三个不同的 layers 来处理:用 CNN 来处理图像的特征图;用 DAG-RNNs 来建模图像的 contextual dependencies,用 deconvolutional layers 进行上采样特征图。
4.3 Instance Segmentation :