近来开发工作不忙,零零散散整理的Java基础
基本按照下图这个路子来搬运的
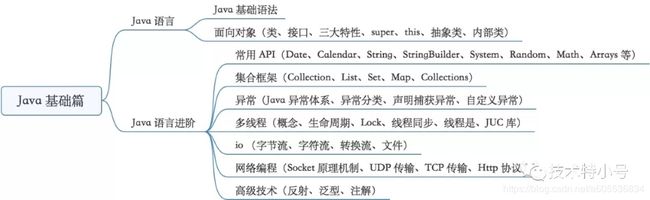
一. java基础
1.java 基础语法
1).标识符和关键字 主要是在命名的时候注意别用到了
2).Java基本数据类型、常量和变量
常量
变量:变量其实就是内存中的一块小区域
变量的分类:
按位置划分:局部变量 成员变量
按数据类型划分: 基本数据类型 引用数据类型
3).运算符 (++ – 三目运算:a? b:c 等)
4).流程控制
条件语句 if() else{} switch(){}
循环语句 for循环
while(判断的条件)
{
执行的语句
}
while循环 先判断 后执行 条件为true则执行 然后再次判断 一直到为false为止
do
{ 执行的语句
}
while (判断的条件);
先执行 在判断 先执行do 再判断 条件为true则继续执行 直到为false为止
break语句和continue语句
break 强行中断
continue 跳出当前条件 继续执行
方法
方法就是完成特定功能的代码片段
递归:内自我调用的方法
程序的执行过程 见图: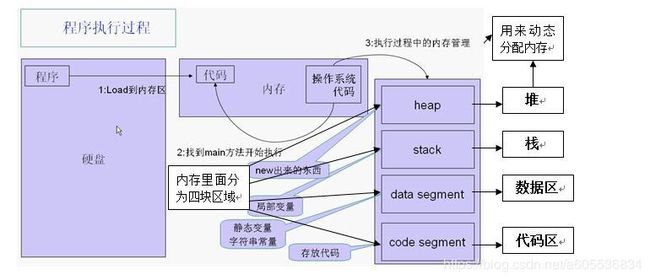
5). 注释和分隔符
2.面向对象思想
1).作为面向对象的思维来说,当你拿到一个问题时,你分析这个问题不再是第一步先做什么,第二步再做什么,
这是面向过程的思维,
你应该分析这个问题里面有哪些类和对象,这是第一点,
然后再分析这些类和对象应该具有哪些属性和方法。这是第二点。
最后分析类和类之间具体有什么关系,这是第三点。
面向对象有一个非常重要的设计思维:合适的方法应该出现在合适的类里面
2).类: 对某类事物的普遍一致性特征、功能的抽象、描述和封装,是构造对象的模版或蓝图,用 Java 编写的代码都会在某些类的内部。类之间主要有:依赖、聚合、继承等关系。
类的三大特性:封装、继承、多态
封装:
Java Bean的一般封装
private String obj;
public void set(String obj)
{
this.obj = obj;
}
poublic String get(){
return this.obj;
}
注意布尔值的get方法一般是isXXX()
继承: extends 多个不同类中抽取出共性的数据和逻辑,然后把这些抽取出来的内容封装成一个新的类,然后之前的类extends这个类java里继承是单继承,即一个子类只能有一个直接父类 PS:实在不行连续继承就是了
super关键字:子类可以使用super调用父类的成员变量和方法,前提是父类的该变量or方法能被调用 不是private修饰的
显式调用调用和隐式调用:
super和this super()用于该类显示调用父类构造器 this()用于该类显式调用本类中其他构造器 如果一个构造器中无super()调用 则会隐式调用父类的无参构造器,super和this不会出现在同一构造器中
子类创建时调用父类构造方法:子类需要使用父类的成员变量和方法,所以就要调用父类构造方法来初始化,之后再进行子类成员变量和方法的初始化。因此,构造方法是无法覆盖的。
当子类需要扩展父类的某个方法时,可以覆盖父类方法,但是子类方法访问权限必须大于或等于父类权限
在实际开发、程序设计过程中,并非先有的父类,而是先有了子类中通用的数据和逻辑,然后再抽取封装出来的父类。
类实例化的过程: 注意是类实例化对象!!
无论新实例化多少个对象,该类的所有 父类以及自身 的静态初始化块只执行一次,而且是最先执行的初始化,称作类的初始化。之后的初始化会依次执行父类的非静态初始化块、父类的构造器和子类的非静态初始化块、子类的构造器来完成初始化称为对象初始化;在子类的构造器中可以通过super来显式调用父类的构造器,可以通过this来调用该类重载的其他构造器,而具体调用哪个构造器决定于调用时的参数类型。
执行顺序 父类and本类的静态代码模块 > 父类and本类的非静态代码模块 > 父类and本类的构造器
多态:多态指的是对象的多种形态, 继承是多态的实现基础
java程序中定义的引用变量所指向的具体类型和通过该引用类型发出的方法在调用时不确定,该引用变量发出的方法到底调用哪个类的实现的方法,必须在程序运行期间才能决定,这就是多态。
简单说多态就是在编程时不知道变量的类型或者方法,运行时才知道
多态的三个前提
A.必须有子类和父类,具有继承或实现(继承)
B.子类必须重写父类的方法(重写)
C.父类的引用变量指向子类的对象(向上转型)
Demo:
public class Wine{
public void fun1(){
System.out.println("Wine 的Fun.....");
fun2();
}
public void fun2(){
System.out.prinltn("Wine 的Fun2");
}
}
public class JNC extends Wine{
/**
* @desc 子类重载父类方法
* 父类中不存在该方法,向上转型后,父类是不能引用该方法的
* @param a
* @return void
*/
public void fun1(String a){
System.out.println("JNC 的 Fun1...");
fun2();
}
/**
* 子类重写父类方法
* 指向子类的父类引用调用fun2时,必定是调用该方法
*/
public void fun2(){
System.out.println("JNC 的Fun2...");
}
}
public class Test {
public static void main(String[] args) {
Wine a = new JNC();
a.fun1();
}
}
Output:
Wine 的Fun…
JNC 的Fun2…
从程序的运行结果中我们发现,a.fun1()首先是运行父类Wine中的fun1().然后再运行子类JNC中的fun2()。
分析:在这个程序中子类JNC重载了父类Wine的方法fun1(),重写fun2(),而且重载后的fun1(String a)与 fun1()不是同一个方法,由于父类中没有该方法,向上转型后会丢失该方法,所以执行JNC的Wine类型引用是不能引用fun1(String a)方法。而子类JNC重写了fun2() ,那么指向JNC的Wine引用会调用JNC中fun2()方法。
Java实现多态有三个必要条件:继承、重写、向上转型。
继承:在多态中必须存在有继承关系的子类和父类。
重写:子类对父类中某些方法进行重新定义,在调用这些方法时就会调用子类的方法。
向上转型:在多态中需要将子类的引用赋给父类对象,只有这样该引用才能够具备技能调用父类的方法和子类的方法。
3).抽象类和接口
a.抽象类
抽象方法:它只有声明,而没有具体的实现。抽象方法的声明格式为:
abstract void fun();
如果一个类含有抽象方法,则称这个类为抽象类,抽象类必须在类前用abstract关键字修饰。因为抽象类中含有无具体实现的方法,所以不能用抽象类创建对象
public abstract class ClassName{
abstract void fun();
}
public class Test() extends ClassName{
@Override void fun() {
}
}
抽象类就是为了继承而存在的!! extends
对于一个父类,如果它的某个方法在父类中实现出来没有任何意义,必须根据子类的实际需求来进行不同的实现,那么就可以将这个方法声明为abstract方法,此时这个类也就成为abstract类了
抽象类里也可以存在成员变量和普通的方法
public abstract class Testabs {
abstract void fun();
public void fun1(){
System.out.println("Testabs 的fun....");
fun2();
}
public void fun2(){
System.out.println("Testabs 的fun2....");
}
}
//继承抽象类的子类必须实现抽象方法!
public class Test() extends ClassName{
@Override void fun() {
}
}
b.接口 interface
Java接口是一系列方法的声明,是一些方法特征的集合,一个接口只有方法的特征没有方法的实现,因此这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的行为(功能)。
接口无法被实例化,但是可以被实现。
一个实现接口的类,必须实现接口内所描述的所有方法。
如果不想全部实现,那么这个类必须是个抽象类,而且这抽象类的子类必须实现它未实现的方法。
public interface Testabs {
void fun();
void setType(boolean flag);
}
public abstract class Test implements Testabs {
@Override public void fun() {
System.out.println("Test fun....");
}
}
public class Wine extends Test{
@Override public void setType(boolean flag) {
}
public static void main(String[] args){
Testabs w = new Wine();
w.fun();
}
}
一个接口则无法实现其他的接口。
接口通常被用来做回调函数使用
c.抽象类和接口的区别和使用场景
<1>.语法层面上的区别
抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
一个类只能继承一个抽象类,而一个类却可以实现多个接口。
<2>.设计层面上的区别
抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。
抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。举个简单的例子,飞机和鸟是不同类的事物,但是它们都有一个共性,就是都会飞。那么在设计的时候,可以将飞机设计为一个类Airplane,将鸟设计为一个类Bird,但是不能将 飞行 这个特性也设计为类,因此它只是一个行为特性,并不是对一类事物的抽象描述。此时可以将 飞行 设计为一个接口Fly,包含方法fly( ),然后Airplane和Bird分别根据自己的需要实现Fly这个接口。然后至于有不同种类的飞机,比如战斗机、民用飞机等直接继承Airplane即可,对于鸟也是类似的,不同种类的鸟直接继承Bird类即可。从这里可以看出,继承是一个 "是不是"的关系,而 接口 实现则是 "有没有"的关系。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如鸟是否能飞(或者是否具备飞行这个特点),能飞行则可以实现这个接口,不能飞行就不实现这个接口。
设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。什么是模板式设计?最简单例子,大家都用过ppt里面的模板,如果用模板A设计了ppt B和ppt C,ppt B和ppt C公共的部分就是模板A了,如果它们的公共部分需要改动,则只需要改动模板A就可以了,不需要重新对ppt B和ppt C进行改动。而辐射式设计,比如某个电梯都装了某种报警器,一旦要更新报警器,就必须全部更新。也就是说对于抽象类,如果需要添加新的方法,可以直接在抽象类中添加具体的实现,子类可以不进行变更;而对于接口则不行,如果接口进行了变更,则所有实现这个接口的类都必须进行相应的改动。
下面看一个网上流传最广泛的例子:门和警报的例子:门都有open( )和close( )两个动作,此时我们可以定义通过抽象类和接口来定义这个抽象概念:
abstract class Door {
public abstract void open();
public abstract void close();
}
或者:
interface Door {
public abstract void open();
public abstract void close();
}
但是现在如果我们需要门具有报警alarm( )的功能,那么该如何实现?下面提供两种思路:
1)将这三个功能都放在抽象类里面,但是这样一来所有继承于这个抽象类的子类都具备了报警功能,但是有的门并不一定具备报警功能;
2)将这三个功能都放在接口里面,需要用到报警功能的类就需要实现这个接口中的open( )和close( ),也许这个类根本就不具备open( )和close( )这两个功能,比如火灾报警器。
从这里可以看出, Door的open() 、close()和alarm()根本就属于两个不同范畴内的行为,open()和close()属于门本身固有的行为特性,而alarm()属于延伸的附加行为。因此最好的解决办法是单独将报警设计为一个接口,包含alarm()行为,Door设计为单独的一个抽象类,包含open和close两种行为。再设计一个报警门继承Door类和实现Alarm接口。
interface Alram {
void alarm();
}
abstract class Door {
void open();
void close();
}
class AlarmDoor extends Door implements Alarm {
void oepn() {
//....
}
void close() {
//....
}
void alarm() {
//....
}
}
总结起来:抽象类描述的是类的特性,而接口描述的是类的补充方法
4).内部类
广泛意义上的内部类一般来说包括这四种:成员内部类、静态内部类、匿名内部类和局部内部类。
成员内部类和静态内部类的区别:
Demo:
public class Test {
class Bean1 { //成员内部类
public int I = 0;
}
static class Bean2 {//静态内部类
public int J = 0;
}
public static void main(String[] args){
Test test = new Test();
Bean1 bean1 = test.new Bean1();
bean1.I++;
Bean2 bean2 = new Bean2();
bean2.J++;
Bean bean = new Test().new Bean();
Bean.Bean3 bean3 = bean.new Bean3();
bean3.K++;
}
class Bean {
class Bean3 {
public int K = 0;
}
}
}
创建静态内部类对象的一般形式为: 外部类类名.内部类类名 xxx = new 外部类类名.内部类类名()
创建成员内部类对象的一般形式为: 外部类类名.内部类类名 xxx = 外部类对象名.new 内部类类名()
匿名内部类:一般的按钮点击事件OnClickListener就是匿名内部类
局部内部类:局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内。
经典Demo:
public class Test {
public static void main(String[] args) {
Outter outter = new Outter();
outter.new Inner().print();
}
}
class Outter
{
private int a = 1;
class Inner {
private int a = 2;
public void print() {
int a = 3;
System.out.println("局部变量:" + a);
System.out.println("内部类变量:" + this.a);
System.out.println("外部类变量:" + Outter.this.a);
}
}
}
Output
3
2
1
3.java常用API
Object类是java语言中的根类,它所描述的所有方法子类都可以使用,所有类在创建对象的时候,最终找的父类就是Object。
在Objec类中,最常见的就是euqals方法和toString方法。equals方法用于比较两个对象是否相同,实质是比较两个对象的内存地址。在复写Object中的equals方法时,一定要注意public boolean equals(Object obj)的参数是Object类型。在调用对象的属性时,一定要进行类型转换,转换之前一定要进行类型判断。toString方法返回该对象的字符串表示。其实该字符串内容就是对象的类型+@+内存地址值。
1).String和StringBuilder、StringBuffer的区别:
主要是在运行速度和线程安全上区分:
a.运行速度的快慢上 StringBuilder > StringBuffer > String
String最慢的原因:String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,但后两者的对象是变量,是可以更改的
Java中对String对象进行的操作实际上是一个不断创建新的对象并且将旧的对象回收的一个过程。
而StringBuilder和StringBuffer的对象是变量,对变量进行操作就是直接对该对象进行更改,而不进行创建和回收的操作,所以速度要比String快很多。
字符串拼接时 String的"+" 和StringBuilder append 的比较
String s = “a” + “b” + “c” + “d”;
StringBuilder s = new StringBuilder();
s.append(“a”).append(“b”).append(“c”).append(“d”);
这两种方式其实效率一样, String在"+"的时候底层也是创建了个StringBuilder来append
String a = b + c + d 处理成a = new StringBuilder(b).append©.append(d)
只是说在循环里:
Demo:
public class Test {
public static void main(String[] args) {fun2();
fun1();
fun2();
}
public static void fun1() {
System.out.println("String时间: " + System.currentTimeMillis());
String str = "s";
for (int a = 0; a < 100000; a++) {
str += "a";
}
System.out.println("String时间: " + System.currentTimeMillis());
}
public static void fun2() {
System.out.println("StringBuilder时间: " + System.currentTimeMillis());
StringBuilder str = new StringBuilder("s");
for (int a = 0; a < 100000; a++) {
str.append("a");
}
System.out.println("StringBuilder时间: " + System.currentTimeMillis());
}
}
Output
StringBuilder时间: 1550656068839
StringBuilder时间: 1550656068845
String时间: 1550656068845
String时间: 1550656073184
结论:循环里String的效率确实比StringBuilder低
b.线程安全上
在线程安全上,StringBuilder是线程不安全的,而StringBuffer是线程安全的
如果一个StringBuffer对象在字符串缓冲区被多个线程使用时,StringBuffer中很多方法可以带有synchronized关键字,所以可以保证线程是安全的,但StringBuilder的方法则没有该关键字,所以不能保证线程安全,有可能会出现一些错误的操作。所以如果要进行的操作是多线程的,那么就要使用StringBuffer,但是在单线程的情况下,还是建议使用速度比较快的StringBuilder。
c. 总结一下
String:适用于少量的字符串操作的情况
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
2).Date、DateFormat
DateFormat是日期/时间格式化子类的抽象类,用来解析日期或时间。DateFormate是抽象类,一般需要使用子类SimpleDateFormat来创建对象
Date类表示特定的瞬间,精确到毫秒。
Demo
时间戳转一般的时间格式yyyy-MM-dd HH:mm:ss
public static void fun1() {
//创建日期格式化对象,在获取格式化对象时可以指定风格
DateFormat df= new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//对日期进行格式化
Date date = new Date(System.currentTimeMillis());// 当前时间的Date对象
String str_time = df.format(date);
System.out.println("当前时间: " + str_time);
}
一般时间格式yyyy-MM-dd HH:mm:ss转时间戳
private static void fun2(){
String strTime = "2019-02-21 09:56:44";
DateFormat df= new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//对日期进行格式化
try {
Date date = df.parse(strTime);
long longTime = date.getTime();
System.out.println("时间戳: " + longTime/ 1000);
} catch (ParseException e) {
e.printStackTrace();
}
}
3).Calendar
Calendar是日历类,替换了许多Date的方法。将所有可能用到的时间信息封装为静态成员变量,方便获取。另一方面,Calendar是抽象类,在创建对象时并非直接创建,而是通过静态方法创建,将语言敏感内容处理好,再返回子类对象
Demo:
private static void fun2(){
Calendar cal = Calendar.getInstance();
int day = cal.get(Calendar.DATE);//-----------------------当天 1-31
int day_if_month = cal.get(Calendar.DAY_OF_MONTH);//---------------当天 1-31
int day_of_week = cal.get(Calendar.DAY_OF_WEEK);//----------------从星期天开始计算,如果今天星期二,那么返回3
int day_of_year = cal.get(Calendar.DAY_OF_YEAR);//----------------本年的第几天
int hour = cal.get(Calendar.HOUR);//-----------------------12小时制
int hour_of_day = cal.get(Calendar.HOUR_OF_DAY);//----------------24小时制,一般使用这个属性赋值
int millisecond = cal.get(Calendar.MILLISECOND);//---------------- 当前毫秒
int minute = cal.get(Calendar.MINUTE);//---------------------当前分钟
int second = cal.get(Calendar.SECOND);//---------------------当前秒
int week_of_month = cal.get(Calendar.WEEK_OF_MONTH);//--------------本月的第几周
int week_of_year = cal.get(Calendar.WEEK_OF_YEAR);//---------------本年的第几周
int month = cal.get(Calendar.MONTH) + 1;//-----------------------月份获取需要 +1,那么,赋值时需要 -1
int year = cal.get(Calendar.YEAR); //-----------------年份
System.out.println("year:" + year + " month:"+ month + " day:" + day);
System.out.println("day_of_year: " + day_of_year + " day_if_month:" + day_if_month + " day_of_week:" + day_of_week);
System.out.println("week_of_year:" + week_of_year + " week_of_month:" + week_of_month);
System.out.println("hour_of_day:" + hour_of_day + " hour:" + hour + " minute:" + minute + " second:" + second + " millisecond:" + millisecond);
}
// 返回某月最后一天
public static void getLastDayOfMonth(int year, int month) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH, cal.getActualMaximum(Calendar.DATE));
String lastDay = new SimpleDateFormat("yyyy-MM-dd").format(cal.getTime());
System.out.println("该月最后一天 :" + lastDay);
}
4).Math
Math类是包含用于执行基本数学运算的方法的数学工具类,像初等函数、对数、平方根等。其所有方法均为静态方法,并且一般不会创建对象。比较常见的有:
abs方法,结果都为正数;ceil方法,结果为比参数值大的最小整数的double值;floor方法,结果为比参数值小的最大整数的double值;max方法,返回两个参数值中较大的值;min方法,返回两个参数值中较小的值;pow方法,返回第一个参数的第二个参数次幂的值;round方法,返回参数值四舍五入的结果;random方法,产生一个大于等于0.0且小于1.0的double小数。
5).System
System 类中提供了一些系统级的操作方法,常用的方法有 arraycopy()、currentTimeMillis()、exit()、gc() 和 getProperty()。
a. arraycopy() 方法
该方法的作用是数组复制,即从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。该方法的具体定义如下:
public static void arraycopy(Object src,int srcPos,Object dest,int destPos,int length)
其中,src 表示源数组,srcPos 表示从源数组中复制的起始位置,dest 表示目标数组,destPos 表示要复制到的目标数组的起始位置,length 表示复制的个数。
b.currentTimeMillis() 方法
该方法的作用是返回当前的计算机时间,时间的格式为当前计算机时间与 1970 年 1 月 1 日 0 时 0 分 0 秒所差的毫秒数
c.exit() 方法
该方法的作用是终止当前正在运行的 Java 虚拟机
public static void exit(int status)
其中,status 的值为 0 时表示正常退出,非零时表示异常退出。使用该方法可以在图形界面编程中实现程序的退出功能等
System.exit(0);
d.gc() 方法
该方法的作用是请求系统进行垃圾回收
System.gc();
e.getProperty() 方法。
该方法的作用是获得系统中属性名为 key 的属性对应的值
public static void fun1() {
String jversion=System.getProperty("java.version");
String oName=System.getProperty("os.name");
String user=System.getProperty("user.name");
System.out.println("Java 运行时环境版本:"+jversion);
System.out.println("当前操作系统是:"+oName);
System.out.println("当前用户是:"+user);
}
6).Arrays类
Arrays类一般用来操作数组(比如排序和搜索)的各种方法,比较常见的方法有:
a. Arrays.sort() //对数组元素进行排序(串行排序)
public static void fun1() {
String[] data = {"1", "4", "3", "2"};
System.out.println(Arrays.toString(data)); // [1, 4, 3, 2]
Arrays.sort(data);
System.out.println(Arrays.toString(data)); // [1, 2, 3, 4]
}
延伸出来Arrays.sort(Object[] array, int fromIndex, int toIndex)
对数组元素的指定范围进行排序(串行排序)
public static void fun1() {
String[] data = {"1", "4", "3", "2"};
System.out.println(Arrays.toString(data)); // [1, 4, 3, 2]
// 对下标[0, 3)的元素进行排序,即对1,4,3进行排序,2保持不变
Arrays.sort(data, 0, 3);
System.out.println(Arrays.toString(data)); // [1, 3, 4, 2]
}
b.Arrays.sort(T[] array, Comparator comparator)
使用自定义比较器,对数组元素进行排序(串行排序)array 目标数组
Interface Comparator 对任意类型集合对象进行整体排序,排序时将此接口的实现传递给Collections.sort方法或者Arrays.sort方法排序.
实现int compare(T o1, T o2);方法,返回正数,零,负数各代表大于,等于,小于
如果指定的数与参数相等返回0。
如果指定的数小于参数返回 -1。
如果指定的数大于参数返回 1。
Demo:
public static void fun1() {
// 排序
String demos[] = { "hello", "我擦嘞", "test", "CSDN" };
//
// static void
// sort(T[] a, Comparator c)
// 根据指定比较器产生的顺序对指定对象数组进行排序。
Arrays.sort(demos, new Comparator() {
@Override public int compare(String s, String t1) {
return s.compareTo(t1);
}
});
System.out.print(Arrays.toString(demos));
}
------------------------------
[CSDN, hello, test, 我擦嘞]
c.Arrays.asList(T… data) 转数组
public static void fun2(){
List list = Arrays.asList(1, 2, 3,18,11);
System.out.println(Arrays.toString(list.toArray()));
}
[1, 2, 3, 18, 11]
d.Arrays.fill(Object[] array, Object obj)
用指定元素填充整个数组(会替换掉数组中原来的元素)
Integer[] data = {1, 2, 3, 4};
Arrays.fill(data, 9);
System.out.println(Arrays.toString(data)); // [9, 9, 9, 9]
延伸出来Arrays.fill(Object[] array, int fromIndex, int toIndex, Object obj)
Integer[] data = {1, 2, 3, 4};
Arrays.fill(data, 0, 2, 9);
System.out.println(Arrays.toString(data)); // [9, 9, 3, 4]
e.Arrays.parallelSort(T[] array)
和Array.sort()一样,对数组元素进行排序(并行排序),当数据规模较大时,会有更好的性能
f.Arrays.binarySearch()
注意:在调用该方法之前,必须先调用sort()方法进行排序,如果数组没有排序,
那么结果是不确定的,此外如果数组中包含多个指定元素,则无法保证将找到哪个元素
Arrays.binarySearch(Object[] array, Object key)
使用 二分法 查找数组内指定元素的索引值
Integer[] data = {1, 3, 5, 7};
Arrays.sort(data);
System.out.println(Arrays.binarySearch(data, 1)); // 0
Arrays.binarySearch(Object[] array, int fromIndex, int toIndex, Object obj)
使用 二分法 查找数组内指定范围内的指定元素的索引值
Integer[] data = {1, 3, 5, 7};
Arrays.sort(data);
// {1, 3},3的索引值为1
System.out.println(Arrays.binarySearch(data, 0, 2, 3)); // 1
g. Arrays.hashCode(Object[] array)
返回数组的哈希值
Integer[] data = {1, 2, 3};
System.out.println(Arrays.hashCode(data)); // 30817
Arrays.deepHashCode(Object[] array)
返回多维数组的哈希值
Integer[][] data = {{1, 2, 3}, {1, 2, 3}};
System.out.println(Arrays.deepHashCode(data)); // 987105
h.Arrays.deepEquals(Object[] array1, Object[] array2)
判断两个多维数组是否相等,实际上比较的是两个数组的哈希值,
即 Arrays.hashCode(data1) == Arrays.hashCode(data2)
Integer[][] data1 = {{1,2,3}, {1,2,3}};
Integer[][] data2 = {{1,2,3}, {1,2,3}};
System.out.println(Arrays.deepEquals(data1, data2)); // true
二.集合框架
两大基类Collection与Map
1.Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作和属性。Collection包含了List和Set两大分支。
1).List是一个有序的队列,每一个元素都有它的索引。第一个元素的索引值是0。List的实现类有LinkedList, ArrayList, Vector, Stack。
a.ArrayList:ArrayList是基于数组实现的,是一个数组队列。可以动态的增加容量!
b.LinkedList:LinkedList是基于链表实现的,是一个双向循环列表。可以被当做堆栈使用!
c.Vector:Vector是基于数组实现的,是一个矢量队列,是线程安全的!
d.Stack:Stack是基于数组实现的,是栈,它继承与Vector,特性是FILO(先进后出)!
一个Demo来看4中List的插入,查找,删除效率
private static final int COUNT = 100000; //十万
private static ArrayListOutput
…开始测试插入元素…
ArrayList : 插入 100000元素, 使用的时间是 1280 ms
LinkedList : 插入 100000元素, 使用的时间是 5 ms
Vector : 插入 100000元素, 使用的时间是 1099 ms
Stack : 插入 100000元素, 使用的时间是 1100 ms
…开始测试读取元素…
ArrayList : 随机读取 100000元素, 使用的时间是 3 ms
LinkedList : 随机读取 100000元素, 使用的时间是 4567 ms
Vector : 随机读取 100000元素, 使用的时间是 3 ms
Stack : 随机读取 100000元素, 使用的时间是 3 ms
…开始测试删除元素…
ArrayList : 删除 100000元素, 使用的时间是 1040 ms
LinkedList : 删除 100000元素, 使用的时间是 3 ms
Vector : 删除 100000元素, 使用的时间是 1040 ms
Stack : 删除 100000元素, 使用的时间是 1028 ms
由上Demo可得出结论 LinkedList的插入、删除效率最高10万个数据只需要3-5ms;
查找元素时ArrayList、Vector、Stack的效率差不多,均为1s左右
原因:
读取元素时:ArrayList随机读取的时候采用的是get(index),根据指定位置读取元素,而LinkedList则采用size/2 ,二分法去加速一次读取元素
而插入或者删除元素时:ArrayList插入时候要判断容量,删除时候要将数组移位,有一个复制操作!而LinkedList直接插入,不用判断容量,删除的时候也是直接删除跳转指针节点,没有复制的操作!
所以对于需要快速插入,删除元素,应该使用LinkedList。
对于需要快速随机访问元素,应该使用ArrayList。
2).Set是一种不包括重复元素的Collection。它维持它自己的内部排序,所以随机访问没有任何意义。与List一样,它同样允许null的存在但是仅有一个。由于Set接口的特殊性,所有传入Set集合中的元素都必须不同,同时要注意任何可变对象,如果在对集合中元素进行操作时,导致e1.equals(e2)==true,则必定会产生某些问题。Set接口有三个具体实现类,分别是散列集HashSet、链式散列集LinkedHashSet和树形集TreeSet。
需要注意的是:虽然Set中元素没有顺序,但是元素在set中的位置是由该元素的HashCode决定的,其具体位置其实是固定的。
此外需要说明一点,在set接口中的不重复是有特殊要求的。
举一个例子:对象A和对象B,本来是不同的两个对象,正常情况下它们是能够放入到Set里面的,但是如果对象A和B的都重写了hashcode和equals方法,并且重写后的hashcode和equals方法是相同的话。那么A和B是不能同时放入到Set集合中去的,也就是Set集合中的去重和hashcode与equals方法直接相关。
set底层数据结构是哈希表:
特点:存储取出都比较快
原理:具体省略,简单说就是链表数组结合体
a.HashSet
<1>.无序集合
<2>.可以存入空(null),但是有且只有一个
<3>.不可以存在重复元素
b.LinkedHashSet
LinkedHashSet继承自HashSet,其底层是基于LinkedHashMap来实现的,有序,非同步。LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
c.TreeSet
TreeSet是一个有序集合,其底层是基于TreeMap实现的,非线程安全。TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式。当我们构造TreeSet时,若使用不带参数的构造函数,则TreeSet的使用自然比较器;若用户需要使用自定义的比较器,则需要使用带比较器的参数。
注意:TreeSet集合不是通过hashcode和equals函数来比较元素的.它是通过compare或者comparaeTo函数来判断元素是否相等.compare函数通过判断两个对象的id,相同的id判断为重复元素,不会被加入到集合中。
2.Map是一个映射接口,即key—value键值对。Map中的每一个元素包含“一个key”和“key对应的value”。AbstractMap是个抽象类,它实现了Map接口中的大部分API。而HashMap,TreeMap,WeakHashMap都是继承于AbstractMap。Hashtable虽然继承于Dictionary,但它实现了Map接口。
在Map中它保证了key与value之间的一一对应关系。也就是说一个key对应一个value
1).HashMap
HashMap 底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组
HashMap是基于Hash表的Map实现,可操作null键和null值,是非线程安全的;LinkedHashMap是线程安全的
储存方式:HashMap其内部定义了一个hash表数组key所对应的value值链接成一个链表,而数组中储存的是链表的第一个节点的地址值,所以HashMap又叫做链表的数组。
HashMap的性能受两个因素的影响,初始容量和加载因子,如果Hash表中的条目数超过了初始容量和加载因子的乘积,那么hash表讲做出自我调整,把容量扩充为原来的两倍,并将原有的数据重新映射到表中,这个过程叫做rehash;容量扩充,重新映射,所以说rehash必然会造成时间和空间的开销,所以说初始容量和加载因子会影响HashMap的性能
2).LinkedHashMap
LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。
LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用get方法)的链表。默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。
注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
由于LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能,但在迭代访问Map里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
3).TreeMap
TreeMap是基于红黑树(二叉树)数据结构实现的,特点:会对元素的键进行排序存储。
TreeMap 要注意的事项:
a. 往TreeMap添加元素的时候,如果元素的键具备自然顺序,那么就会按照键的自然顺序特性进行排序存储。PS:比如按照英文字母顺序给请求参数排序等
b. 往TreeMap添加元素的时候,如果元素的键不具备自然顺序特性,那么键所属的类必须要实现Comparable接口。
4).value()方法与keySet()、entrySet()区别:
values():方法是获取集合中的所有的值----没有键,没有对应关系,
KeySet():将Map中所有的键存入到set集合中。因为set具备迭代器。所有可以迭代方式取出所有的键,再根据get方法。获取每一个键对应的值。keySet():迭代后只能通过get()取key
entrySet():Set
Demo:
public static void fun1(){
Map map = new HashMap();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
Set keySet = map.keySet();//先获取map集合的所有键的Set集合
Iterator it = keySet.iterator();//有了Set集合,就可以获取其迭代器。
while(it.hasNext()){
String key = it.next();
String value = map.get(key);//有了键可以通过map集合的get方法获取其对应的值。
System.out.println("key: "+key+"-->value: "+value);//获得key和value值
}
}
public static void fun2(){
Map map = new HashMap();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
//通过entrySet()方法将map集合中的映射关系取出(这个关系就是Map.Entry类型)
Set> entrySet = map.entrySet();
//将关系集合entrySet进行迭代,存放到迭代器中
Iterator> it2 = entrySet.iterator();
while(it2.hasNext()){
Map.Entry me = it2.next();//获取Map.Entry关系对象me
String key2 = me.getKey();//通过关系对象获取key
String value2 = me.getValue();//通过关系对象获取value
System.out.println("key: "+key2+"-->value: "+value2);
}
}
HashMap和TreeMap。keySet和entrySet在Map元素数较少时(小于10000)在查询速度上的区别不大,它们对于程序性能的影响可以忽略不计。但在元素较多时(大于100000)时entrySet的速度要明显快于keySet,尤其是TreeMap更明显。
So建议大家使用entrySet
3.接下来,再看Iterator。它是遍历集合的工具,即我们通常通过Iterator迭代器来遍历集合。
我们说Collection依赖于Iterator,是因为Collection的实现类都要实现iterator()函数,返回一个Iterator对象。ListIterator是专门为遍历List而存在的。
Java中的Iterator功能比较简单,并且只能单向移动:
1).使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
2).使用next()获得序列中的下一个元素。
3).使用hasNext()检查序列中是否还有元素。
4).使用remove()将迭代器新返回的元素删除。
Iterator的接口定义:
public interface Iterator {
boolean hasNext();
Object next();
void remove();
}
使用:
Object next():返回迭代器刚越过的元素的引用,返回值是Object,需要强制转换成自己需要的类型
boolean hasNext():判断容器内是否还有可供访问的元素
void remove():删除迭代器刚越过的元素
迭代使用方法:(迭代其实可以简单地理解为遍历,是一个标准化遍历各类容器里面的所有对象的方法类)
for(Iterator it = c.iterator(); it.hasNext(); ) {
Object o = it.next();
//do something
}
4.最后,看Arrays和Collections。它们是操作数组、集合的两个工具类。
1).Arrays见一-1-6)
2).Collections:
a.Java中Collection和Collections的区别:
Collection:java.util.Collection 是一个集合接口(集合类的一个顶级接口)。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式,其直接继承接口有List与Set。
Collections: Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
Collections提供以下方法对List进行排序操作
void reverse(List list):反转
void shuffle(List list),随机排序
void sort(List list),按自然排序的升序排序
void sort(List list, Comparator c);定制排序,由Comparator控制排序逻辑
void swap(List list, int i , int j),交换两个索引位置的元素
void rotate(List list, int distance),旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
Demo:
public static void fun1(){
List list = new ArrayList<>();
list.add(12);
list.add(-15);
list.add(7);
list.add(4);
list.add(35);
list.add(9);
System.out.println("源列表:" + list);
// 逆序
Collections.reverse(list);
System.out.println("逆序:" + list);
// 排序(自然顺序)
Collections.sort(list);
System.out.println("自然序:" + list);
// 随机排序
Collections.shuffle(list);
System.out.println("随机序:" + list);
// 定制排序的用法,将int类型转成string进行比较
Collections.sort(list, new Comparator Output:
源列表:[12, -15, 7, 4, 35, 9]
逆序:[9, 35, 4, 7, -15, 12]
自然序:[-15, 4, 7, 9, 12, 35]
随机序:[9, 12, 4, 7, -15, 35]
定制序:[-15, 12, 35, 4, 7, 9]
旋转3:[4, 7, 9, -15, 12, 35]
旋转-3:[-15, 12, 35, 4, 7, 9]
查找,替换操作
int binarySearch(List list, Object key), 对List进行二分查找,返回索引,注意List必须是有序的
int max(Collection coll),根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
int max(Collection coll, Comparator c),根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
void fill(List list, Object obj),用元素obj填充list中所有元素
int frequency(Collection c, Object o),统计元素出现次数
int indexOfSubList(List list, List target), 统计targe在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target).
boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替换旧元素。
public static void fun1(){
List list = new ArrayList<>();
list.add(12);
list.add(-15);
list.add(7);
list.add(4);
list.add(35);
list.add(9);
System.out.println("源列表:" + list);
System.out.println("最大的元素: " + Collections.max(list));
System.out.println("最小元素: " + Collections.min(list));
Collections.replaceAll(list,-15, 35);
System.out.println("用新元素替换旧元素: " + list);
System.out.println("统计元素出现次数: " + Collections.frequency(list, 35));
Collections.sort(list);
System.out.println("先sort排序,然后对List进行二分查找,得到的是索引: " + Collections.binarySearch(list, 35));
int index = Collections.binarySearch(list, 35, new Comparator() {
@Override public int compare(Integer int1, Integer int2) {
return int1.compareTo(int2);
}
});
System.out.println("先sort排序,然后对List进行二分查找,得到的是索引: " + index);
}
Collections同步控制
Collections中几乎对每个集合都定义了同步控制方法,例如 SynchronizedList(), SynchronizedSet()等方法,来将集合包装成线程安全的集合。下面是Collections将普通集合包装成线程安全集合的用法,
Collection c = Collections.synchronizedCollection(new ArrayList());
List list = Collections.synchronizedList(new ArrayList());
Set s = Collections.synchronizedSet(new HashSet());
Map m = Collections.synchronizedMap(new HashMap());
三.异常
1.java异常体系及分类
Thorwable类所有异常和错误的超类,有两个子类Error和Exception,分别表示错误和异常。 其中异常类Exception又分为运行时异常(RuntimeException)和非运行时异常,这两种异常有很大的区别,也称之为不检查异常(Unchecked Exception)
和检查异常(Checked Exception)。
1).Error和Exception
Error是程序无法处理的错误,比如OutOfMemoryError、ThreadDeath等。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
Exception是程序本身可以处理的异常,这种异常分两大类运行时异常和非运行时异常,程序中应当尽可能去处理这些异常。
2).运行时异常和非运行时异常
运行时异常都是RuntimeException类及其子类异常,如NullPointerException、IndexOutOfBoundsException等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
非运行时异常是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
2.异常的捕获和处理
Java异常的捕获和处理是一个不容易把握的事情,如果处理不当,不但会让程序代码的可读性大大降低,而且导致系统性能低下,甚至引发一些难以发现的错误。
Java异常处理涉及到五个关键字,分别是:try、catch、finally、throw、throws。下面将骤一介绍,通过认识这五个关键字,掌握基本异常处理知识。
1).异常处理的基本语法
try{
//(尝试运行的)程序代码
}catch(异常类型 异常的变量名){
//异常处理代码
}finally{
//异常发生,方法返回之前,总是要执行的代码
}
以上语法有三个代码块:
try语句块,表示要尝试运行代码,try语句块中代码受异常监控,其中代码发生异常时,会抛出异常对象。
catch语句块会捕获try代码块中发生的异常并在其代码块中做异常处理,catch语句带一个Throwable类型的参数,
表示可捕获异常类型。当try中出现异常时,catch会捕获到发生的异常,并和自己的异常类型匹配,
若匹配,则执行catch块中代码,并将catch块参数指向所抛的异常对象。catch语句可以有多个,
用来匹配多个中的一个异常,一旦匹配上后,就不再尝试匹配别的catch块了。
通过异常对象可以获取异常发生时完整的JVM堆栈信息,以及异常信息和异常发生的原因等。
finally语句块是紧跟catch语句后的语句块,这个语句块总是会在方法返回前执行,
而不管是否try语句块是否发生异常。并且这个语句块总是在方法返回前执行。
目的是给程序一个补救的机会。这样做也体现了Java语言的健壮性。
2).try、catch、finally三个语句块应注意的问题
第一、try、catch、finally三个语句块均不能单独使用,三者可以组成 try…catch…finally、try…catch、
try…finally三种结构,catch语句可以有一个或多个,finally语句最多一个。
第二、try、catch、finally三个代码块中变量的作用域为代码块内部,分别独立而不能相互访问。
如果要在三个块中都可以访问,则需要将变量定义到这些块的外面。
第三、多个catch块时候,只会匹配其中一个异常类并执行catch块代码,而不会再执行别的catch块,
并且匹配catch语句的顺序是由上到下。
3).throw、throws关键字
throw关键字是用于方法体内部,用来抛出一个Throwable类型的异常。如果抛出了检查异常,
则还应该在方法头部声明方法可能抛出的异常类型。该方法的调用者也必须检查处理抛出的异常。
如果所有方法都层层上抛获取的异常,最终JVM会进行处理,处理也很简单,就是打印异常消息和堆栈信息。
如果抛出的是Error或RuntimeException,则该方法的调用者可选择处理该异常。有关异常的转译会在下面说明。
throws关键字用于方法体外部的方法声明部分,用来声明方法可能会抛出某些异常。仅当抛出了检查异常,
该方法的调用者才必须处理或者重新抛出该异常。当方法的调用者无力处理该异常的时候,应该继续抛出,
而不是囫囵吞枣一般在catch块中打印一下堆栈信息做个勉强处理。
4).Throwable类中的常用方法
getCause():返回抛出异常的原因。如果 cause 不存在或未知,则返回 null。
getMessage():返回异常的消息信息。
printStackTrace():对象的堆栈跟踪输出至错误输出流,作为字段 System.err 的值。
3.自定义异常
在 Java 中你可以自定义异常。编写自己的异常类时需要记住下面的几点。
所有异常都必须是 Throwable 的子类。
如果希望写一个检查性异常类,则需要继承 Exception 类。
如果你想写一个运行时异常类,那么需要继承 RuntimeException 类。
class 自定义异常类 extends 异常类型(Exception){
// 因为父类已经把异常信息的操作都完成了,所在子类只要在构造时,将异常信息传递给父类通过super 语句即可。
// 重写 有参 和 无参 构造方法
}
Demo:
////或者继承RuntimeException(运行时异常)
public class MyException extends RuntimeException{
private static final long serialVersionUID = 1L;
// 提供无参数的构造方法
public MyException() {
}
// 提供一个有参数的构造方法,可自动生成
public MyException(String message) {
super(message);// 把参数传递给Throwable的带String参数的构造方法
}
}
public class CheckScore {
// 检查分数合法性的方法check() 如果定义的是运行时异常就不用抛异常了
public void check(int score) throws MyException {// 抛出自己的异常类
if (score > 120 || score < 0) {
// 分数不合法时抛出异常
throw new MyException("分数不合法,分数应该是0--120之间");// new一个自己的异常类
} else {
System.out.println("分数合法,你的分数是" + score);
}
}
}
public static void fun3(){
Scanner sc = new Scanner(System.in);
int score = sc.nextInt();
CheckScore check = new CheckScore();
try {
check.check(score);
} catch (MyException e) {// 用自己的异常类来捕获异常
e.printStackTrace();
}
}
Input:
200
Output:
com.kunzhuo.xuechelang.test.MyException: 分数不合法,分数应该是0–120之间
at com.kunzhuo.xuechelang.test.CheckScore.check(CheckScore.java:18)
at com.kunzhuo.xuechelang.test.Test.fun3(Test.java:101)
at com.kunzhuo.xuechelang.test.Test.main(Test.java:39)
四.多线程
1.多线程概念
1).操作系统中进程和线程的概念
进程是指一个内存中运行的应用程序,每个进程都有自己独立的一块内存空间,一个进程中可以启动多个线程。比如在Windows系统中,一个运行的exe就是一个进程
线程是指进程中的一个执行流程,一个进程中可以运行多个线程,比如java.exe进程中可以运行很多线程。线程总是属于某个进程,进程中的多个线程共享进程的内存。
2).多线程解决的是并发的问题,目的是使任务执行效率更高,实现前提是“阻塞”。它们看上去时同时在执行的,但实际上只是分时间片试用cpu而已
也就是说,“同时”执行是线程给人的感觉,在线程之间实际上是轮换执行。
3).Java中的多线程概述、定义任务
创建多线程的两种方式:继承Thread类和实现Runnable接口。
一个Thread类实例只是一个对象,像Java中的任何其他对象一样,具有变量和方法,生死于堆上。
Java中,每个线程都有一个调用栈,即使不在程序中创建任何新的线程,线程也在后台运行着。
一个Java应用总是从main()方法开始运行,mian()方法运行在一个线程内,它被称为主线程。
一旦创建一个新的线程,就产生一个新的调用栈。
线程总体分两类:用户线程和守候线程。
当所有用户线程执行完毕的时候,JVM自动关闭。但是守候线程却不独立于JVM,守候线程一般是由操作系统或者用户自己创建的。
a.定义任务(Task)
任务:简单来说,就是一序列工作的集合,这些工作之间有前后顺序,这一系列过程执行过后将实现一个结果或达到一个目的。
首先,思考一个问题,为什么要定义任务?作为java程序员,我们不关心底层的多线程机制是如何执行的,只关心我写个怎样的任务,java的底层的多线程机制才能认识,才能调用你的任务去执行。java是定义了Runnable接口让你去实现,意思就是:你实现Runnable接口类定义一个类,该类的对象就是我能识别的任务,其他方式定义的程序,我都不会将它认为是任务。
好,到这里要明确一点,我们此时只谈论任务,不说多线程。任务和你平时在一个类中编写的代码并无区别,只是按照java的要求实现了一个接口,并在该接口的run方法中编写了你的代码。也就是说,你平时想编写一个类,该类能够完成一些功能,这个类里的任何方法、变量由你自己来定义,而编写任务时,你需要实现Runnable接口,把你想让该任务实现的代码写到run方法中,当然,你可以在你定义的任务类中再定义其他变量、方法以在run中调用。
b.代码实现
Demo:
public class Task implements Runnable{
protected int countDown = 10;
private static int taskCount = 0 ;
private final int id = taskCount++;
public Task(){}
public Task(int countDown){
this.countDown = countDown;
}
public String status(){
return "#"+id+"("+(countDown>0?countDown:"Task!")+"). ";
}
@Override
public void run() {
while(countDown-->0){//变量countDown先减去1,在和0比较看是否大于0的意思。
System.out.print(status());
Thread.yield();
}
}
}
public static void fun1(){
Task task = new Task();
task.run();
}
-------------------- Output:
#0(9). #0(8). #0(7). #0(6). #0(5). #0(4). #0(3). #0(2). #0(1). #0(Task!).
c.任务和线程
任务只是一段代码。线程是用来驱动任务执行的,也就是说你要把任务挂载到某个线程上,这样线程才能驱动你定义的任务来执行。
显示的定义线程的过程就是将任务附着到线程的过程。线程Thread自身并不执行任何操作,它只是用来被多线程机制调用,并驱动赋予它的任务。
上面b的Demo
声明线程并将任务附着到该线程上:
Thread t = new Thread(new Task());
t.start();
Thread类的start方法就是触发了java的多线程机制,使得java的多线程能够调用该线程
2.生命周期
当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态。在线程的生命周期中,它要经过新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)和死亡(Dead)5种状态。尤其是当线程启动以后,它不可能一直"霸占"着CPU独自运行,所以CPU需要在多条线程之间切换,于是线程状态也会多次在运行、阻塞之间切换
// 开始线程
public void start( );
public void run( ); //
注意:启动线程使用start()方法,而不是run()方法。永远不要调用线程对象的run()方法。调用start0方法来启动线程,系统会把该run()方法当成线程执行体来处理;但如果直按调用线程对象的run()方法,则run()方法立即就会被执行,而且在run()方法返回之前其他线程无法并发执行。
也就是说,系统把线程对象当成一个普通对象,而run()方法也是一个普通方法,而不是线程执行体。需要指出的是,调用了线程的run()方法之后,该线程已经不再处于新建状态,不要再次调用线程对象的start()方法。只能对处于新建状态的线程调用start()方法,否则将引发IllegaIThreadStateExccption异常。
// 挂起和唤醒线程
public void resume( ); // 不建议使用
public void suspend( ); // 不建议使用
public static void sleep(long millis);
public static void sleep(long millis, int nanos);
public final native void wait() throws InterruptedException;
public final native void notify();
public final native void notifyAll();
// 终止线程
public void stop( ); // 不建议使用
public void interrupt( );
// 得到线程状态
public boolean isAlive( );
public boolean isInterrupted( );
public static boolean interrupted( );
// join方法
public void join( ) throws InterruptedException; //保证线程的run方法完成后程序才继续运行
1).新建和就绪状态
当程序使用new关键字创建了一个线程之后,该线程就处于新建状态,此时它和其他的Java对象一样,仅仅由Java虚拟机为其分配内存,并初始化其成员变量的值。此时的线程对象没有表现出任何线程的动态特征,程序也不会执行线程的线程执行体。
当线程对象调用了start()方法之后,该线程处于就绪状态。Java虚拟机会为其创建方法调用栈和程序计数器,处于这个状态中的线程并没有开始运行,只是表示该线程可以运行了。至于该线程何时开始运行,取决于JVM里线程调度器的调度。
调用线程对象的start()方法之后,该线程立即进入就绪状态——就绪状态相当于"等待执行",但该线程并未真正进入运行状态。如果希望调用子线程的start()方法后子线程立即开始执行,程序可以使用Thread.sleep(1) 来让当前运行的线程(主线程)睡眠1毫秒,1毫秒就够了,因为在这1毫秒内CPU不会空闲,它会去执行另一个处于就绪状态的线程,这样就可以让子线程立即开始执行。
2).运行和阻塞状态
如果处于就绪状态的线程获得了CPU,开始执行run()方法的线程执行体,则该线程处于运行状态。
如果计算机只有一个CPU,那么在任何时刻只有一个线程处于运行状态,当然在一个多处理器的机器上,将会有多个线程并行执行;
当线程数大于处理器数时,依然会存在多个线程在同一个CPU上轮换的现象。
3).线程阻塞
当发生如下情况时,线程会进入阻塞状态
a. 线程调用sleep()方法主动放弃所占用的处理器资源
b. 线程调用了一个阻塞式IO方法,在该方法返回之前,该线程被阻塞
c. 线程试图获得一个同步监视器,但该同步监视器正被其他线程所持有。关于同步监视器的知识、后面将存更深入的介绍
d. 线程在等待某个通知(notify)
e. 程序调用了线程的suspend()方法将该线程挂起。但这个方法容易导致死锁,所以应该尽量避免使用该方法
4).终止线程的三种方法
有三种方法可以使终止线程。
a. 使用退出标志,使线程正常退出,也就是当run方法完成后线程终止。
b. 使用stop方法强行终止线程(这个方法不推荐使用,因为stop和suspend、resume一样,也可能发生不可预料的结果)。
c. 使用interrupt方法中断线程。
3.Lock
1).Lock和synchronized概念和区别
a.synchronized
synchronized是Java中解决并发问题的一种最常用的方法,也是最简单的一种方法。Synchronized的作用主要有三个:
(1)确保线程互斥的访问同步代码
(2)保证共享变量的修改能够及时可见
(3)有效解决重排序问题。
普通同步方法,锁死当前实例对象:
Demo:
public class SynchronizedTest {
int a = 0;
public synchronized void method1() {
a++;
System.out.println("Method 1 start" + a);
try {
a++;
System.out.println("Method 1 execute" + a);
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
a++;
System.out.println("Method 1 end" + a);
}
public synchronized void method2() {
a++;
System.out.println("Method 2 start" + a);
try {
a++;
System.out.println("Method 2 execute" + a);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
a++;
System.out.println("Method 2 end" + a);
}
public static void main(String[] args) {
final SynchronizedTest test = new SynchronizedTest();
new Thread(new Runnable() {
@Override public void run() {
test.method1();
}
}).start();
new Thread(new Runnable() {
@Override public void run() {
test.method2();
}
}).start();
}
}
----------------------------------- Output:
Method 1 start1
Method 1 execute2
Method 1 end3
Method 2 start4
Method 2 execute5
Method 2 end6
//静态同步方法,锁死当前类的class对象
public class SynchronizedTest {
public static synchronized void method1() {
System.out.println("Method 1 start");
try {
System.out.println("Method 1 execute");
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Method 1 end");
}
public static synchronized void method2() {
System.out.println("Method 2 start");
try {
System.out.println("Method 2 execute");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Method 2 end");
}
public static void main(String[] args) {
final SynchronizedTest test = new SynchronizedTest();
final SynchronizedTest test2 = new SynchronizedTest();
new Thread(new Runnable() {
@Override public void run() {
test.method1();
}
}).start();
new Thread(new Runnable() {
@Override public void run() {
test2.method2();
}
}).start();
}
}
Output:
Method 1 start
Method 1 execute
Method 1 end
Method 2 start
Method 2 execute
Method 2 end
//同步方法块,锁死括号里面的对象
public class SynchronizedTest {
public void method1() {
System.out.println("Method 1 start " + System.currentTimeMillis()/1000);
try {
synchronized (this) {
System.out.println("Method 1 execute"+ System.currentTimeMillis()/1000);
Thread.sleep(3000);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Method 1 end"+ System.currentTimeMillis()/1000);
}
public void method2() {
System.out.println("Method 2 start"+ System.currentTimeMillis()/1000);
try {
synchronized (this) {
System.out.println("Method 2 execute"+ System.currentTimeMillis()/1000);
Thread.sleep(1000);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Method 2 end"+ System.currentTimeMillis()/1000);
}
public static void main(String[] args) {
final SynchronizedTest test = new SynchronizedTest();
new Thread(new Runnable() {
@Override public void run() {
test.method1();
}
}).start();
new Thread(new Runnable() {
@Override public void run() {
test.method2();
}
}).start();
}
}
Output:
Method 1 start 1551320279
Method 1 execute1551320279
Method 2 start1551320279
Method 1 end1551320282
Method 2 execute1551320282
Method 2 end1551320283
synchronize的可重入性:
从互斥锁的设计上来说,当一个线程试图操作一个由其他线程持有的对象锁的临界资源时,将会处于阻塞状态,但当一个线程再次请求自己持有对象锁的临界资源时,这种情况属于重入锁,请求将会成功,在java中synchronized是基于原子性的内部锁机制,是可重入的,因此在一个线程调用synchronized方法的同时在其方法体内部调用该对象另一个synchronized方法,也就是说一个线程得到一个对象锁后再次请求该对象锁,是允许的,这就是synchronized的可重入性。
synchronized的缺陷
我们了解到如果一个代码块被synchronized修饰了,当一个线程获取了对应的锁,并执行该代码块时,其他线程便只能一直等待,等待获取锁的线程释放锁,而这里获取锁的线程释放锁只会有两种情况:
(1)获取锁的线程执行完了该代码块,然后线程释放对锁的占有;
(2)线程执行发生异常,此时JVM会让线程自动释放锁。
那么如果这个获取锁的线程由于要等待IO或者其他原因(比如调用sleep方法)被阻塞了,但是又没有释放锁,其他线程便只能干巴巴地等待,试想一下,这多么影响程序执行效率。
因此就需要有一种机制可以不让等待的线程一直无期限地等待下去(比如只等待一定的时间或者能够响应中断),通过Lock就可以办到。
2).Lock
(1)Lock不是Java语言内置的,synchronized是Java语言的关键字,因此是内置特性。Lock是一个类,通过这个类可以实现同步访问;
(2)Lock和synchronized有一点非常大的不同,采用synchronized不需要用户去手动释放锁,当synchronized方法或者synchronized代码块执行完之后,系统会自动让线程释放对锁的占用;而Lock则必须要用户去手动释放锁,如果没有主动释放锁,就有可能导致出现死锁现象。
Lock是一个接口:
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
lock()、tryLock()、tryLock(long time, TimeUnit unit)和lockInterruptibly()是用来获取锁的。unLock()方法是用来释放锁的。
lock()方法是平常使用得最多的一个方法,就是用来获取锁。如果锁已被其他线程获取,则进行等待。
由于在前面讲到如果采用Lock,必须主动去释放锁,并且在发生异常时,不会自动释放锁。因此一般来说,使用Lock必须在try{}catch{}块中进行,并且将释放锁的操作放在finally块中进行,以保证锁一定被被释放,防止死锁的发生。通常使用Lock来进行同步的话,是以下面这种形式去使用的:
public static void fun1(){
Lock lock = new ReentrantLock(true);
lock.lock();
try{
//处理任务
System.out.print("vgfsdzxc");
}catch(Exception ex){
}finally{
lock.unlock(); //释放锁
}
}
tryLock()方法是有返回值的,它表示用来尝试获取锁,如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返回false,也就说这个方法无论如何都会立即返回。在拿不到锁时不会一直在那等待。
tryLock(long time, TimeUnit unit)方法和tryLock()方法是类似的,只不过区别在于这个方法在拿不到锁时会等待一定的时间,在时间期限之内如果还拿不到锁,就返回false。如果如果一开始拿到锁或者在等待期间内拿到了锁,则返回true。
public static void fun1(){
Lock lock = new ReentrantLock(true);
if(lock.tryLock()) {
try{
//处理任务
System.out.print("fvsdxccvdsxzc");
}catch(Exception ex){
}finally{
lock.unlock(); //释放锁
}
}else {
//如果不能获取锁,则直接做其他事情
System.out.print("aaaaaaaaaaaaaaaaaaaaaaaac");
}
}
lockInterruptibly()方法比较特殊,当通过这个方法去获取锁时,如果线程正在等待获取锁,则这个线程能够响应中断,即中断线程的等待状态。也就使说,当两个线程同时通过lock.lockInterruptibly()想获取某个锁时,假若此时线程A获取到了锁,而线程B只有在等待,那么对线程B调用threadB.interrupt()方法能够中断线程B的等待过程。
由于lockInterruptibly()的声明中抛出了异常,所以lock.lockInterruptibly()必须放在try块中或者在调用lockInterruptibly()的方法外声明抛出InterruptedException。
public static void fun1() {
Lock lock = new ReentrantLock(true);
try {
lock.lockInterruptibly();
//处理任务
System.out.print("fvsdxccvdsxzc");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (Exception ex) {
} finally {
lock.unlock(); //释放锁
}
}
注意,当一个线程获取了锁之后,是不会被interrupt()方法中断的。因为本身在前面的文章中讲过单独调用interrupt()方法不能中断正在运行过程中的线程,只能中断阻塞过程中的线程。
因此当通过lockInterruptibly()方法获取某个锁时,如果不能获取到,只有进行等待的情况下,是可以响应中断的。
而用synchronized修饰的话,当一个线程处于等待某个锁的状态,是无法被中断的,只有一直等待下去。
3).ReentrantLock
ReentrantLock,意思是“可重入锁”.ReentrantLock是唯一实现了Lock接口的类,并且ReentrantLock提供了更多的方法。下面通过一些实例看具体看一下如何使用ReentrantLock。
public class Test{
private List arrayList = new ArrayList<>();
Lock lock = new ReentrantLock(); //注意这个地方
public static void main(String[] args) {
final Test test = new Test();
new Thread(){
public void run() {
test.insert(Thread.currentThread());
}
}.start();
new Thread(){
public void run() {
test.insert(Thread.currentThread());
}
}.start();
}
public void insert(Thread thread) {
//Lock lock = new ReentrantLock(); //如果放在这个地方,第二个线程会在第一个线程释放锁之前得到了锁?原因在于,在insert方法中的lock变量是局部变量,每个线程执行该方法时都会保存一个副本,那么理所当然每个线程执行到lock.lock()处获取的是不同的锁,所以就不会发生冲突。
lock.lock();
try {
System.out.println(thread.getName()+"得到了锁");
for(int i=0;i<5000;i++) {
arrayList.add(i);
}
} catch (Exception e) {
// TODO: handle exception
}finally {
System.out.println(thread.getName()+"释放了锁");
lock.unlock();
}
}
}
Output:
Thread-0得到了锁
Thread-0释放了锁
Thread-1得到了锁
Thread-1释放了锁
将lock声明为类的属性,这样就是正确地使用Lock的方法了。
tryLock()的使用方法
public class Test {
private ArrayList arrayList = new ArrayList();
private Lock lock = new ReentrantLock(); //注意这个地方
public static void main(String[] args) {
final Test test = new Test();
new Thread(){
public void run() {
test.insert(Thread.currentThread());
};
}.start();
new Thread(){
public void run() {
test.insert(Thread.currentThread());
};
}.start();
}
public void insert(Thread thread) {
if(lock.tryLock()) {
try {
System.out.println(thread.getName()+"得到了锁");
for(int i=0;i<5;i++) {
arrayList.add(i);
}
} catch (Exception e) {
// TODO: handle exception
}finally {
System.out.println(thread.getName()+"释放了锁");
lock.unlock();
}
} else {
System.out.println(thread.getName()+"获取锁失败");
}
}
}
lockInterruptibly()响应中断的使用方法:
public class Test {
private Lock lock = new ReentrantLock();
public static void main(String[] args) {
Test test = new Test();
MyThread thread1 = new MyThread(test);
MyThread thread2 = new MyThread(test);
thread1.start();
thread2.start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
thread2.interrupt();
}
public void insert(Thread thread) throws InterruptedException{
lock.lockInterruptibly(); //注意,如果需要正确中断等待锁的线程,必须将获取锁放在外面,然后将InterruptedException抛出
try {
System.out.println(thread.getName()+"得到了锁");
long startTime = System.currentTimeMillis();
for( ; ;) {
if(System.currentTimeMillis() - startTime >= Integer.MAX_VALUE)
break;
//插入数据
}
}
finally {
System.out.println(Thread.currentThread().getName()+"执行finally");
lock.unlock();
System.out.println(thread.getName()+"释放了锁");
}
}
}
class MyThread extends Thread {
private Test test = null;
public MyThread(Test test) {
this.test = test;
}
@Override
public void run() {
try {
test.insert(Thread.currentThread());
} catch (InterruptedException e) {
System.out.println(Thread.currentThread().getName()+"被中断");
}
}
}
Output:
Thread-0得到了锁
Thread-1被中断
运行之后,发现thread2能够被正确中断。
4).ReadWriteLock
ReadWriteLock也是一个接口,在它里面只定义了两个方法:
public interface ReadWriteLock {
/**
* Returns the lock used for reading.
*
* @return the lock used for reading.
*/
Lock readLock();
/**
* Returns the lock used for writing.
*
* @return the lock used for writing.
*/
Lock writeLock();
}
一个用来获取读锁,一个用来获取写锁。也就是说将文件的读写操作分开,分成2个锁来分配给线程,从而使得多个线程可以同时进行读操作。下面的ReentrantReadWriteLock实现了ReadWriteLock接口。
5).ReentrantReadWriteLock
读写锁将对一个资源(比如文件)的访问分成了2个锁,一个读锁和一个写锁。
ReentrantReadWriteLock里面提供了很多丰富的方法,不过最主要的有两个方法:readLock()和writeLock()用来获取读锁和写锁。
下面通过几个例子来看一下ReentrantReadWriteLock具体用法。
假如有多个线程要同时进行操作的话,先看一下synchronized达到的效果:
public class Test {
public static void main(String[] args) {
final Test test = new Test();
new Thread(){
public void run() {
test.get(Thread.currentThread());
};
}.start();
new Thread(){
public void run() {
test.get(Thread.currentThread());
};
}.start();
}
public synchronized void get(Thread thread) {
long start = System.currentTimeMillis();
while(System.currentTimeMillis() - start <= 1) {
System.out.println(thread.getName()+"正在进行读操作");
}
System.out.println(thread.getName()+"读操作完毕");
}
}
使用synchronized来修饰方法,并不能达到多个线程同时操作的目的,他是第一个线程操作进行完毕,然后再进行第二个线程的操作
使用读写锁:
public class Test {
private ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
public static void main(String[] args) {
final Test test = new Test();
new Thread(){
public void run() {
test.get(Thread.currentThread());
};
}.start();
new Thread(){
public void run() {
test.get(Thread.currentThread());
};
}.start();
}
public void get(Thread thread) {
rwl.readLock().lock();
try {
long start = System.currentTimeMillis();
while(System.currentTimeMillis() - start <= 1) {
System.out.println(thread.getName()+"正在进行读操作");
}
System.out.println(thread.getName()+"读操作完毕");
}finally {
rwl.readLock().unlock();
}
}
}
使用读写锁,能达到两个线程同时操作的目的
6).Lock和synchronized的选择
总结来说,Lock和synchronized有以下几点不同:
a.Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现;
b.synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;
c.Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断;
d.通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。
e.Lock可以提高多个线程进行读操作的效率。
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
4.线程同步
为何要使用线程同步:
java允许多线程并发控制,当多个线程同时操作一个可共享的资源变量时(如数据的增删改查),
将会导致数据不准确,相互之间产生冲突,因此加入同步锁以避免在该线程没有完成操作之前,被其他线程的调用,
从而保证了该变量的唯一性和准确性。
1).同步方法块
即有synchronized关键字修饰的方法。
由于java的每个对象都有一个内置锁,当用此关键字修饰方法时,
内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。
代码如:
public synchronized void save(){}
注: synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类
public static synchronized save(){}
2).同步代码块
即有synchronized关键字修饰的语句块。
被该关键字修饰的语句块会自动被加上内置锁,从而实现同步
代码如:
synchronized(object){
}
注:同步是一种高开销的操作,因此应该尽量减少同步的内容。
通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
3).使用特殊域变量(volatile)实现线程同步
a.volatile关键字为域变量的访问提供了一种免锁机制,
b.使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新,
c.因此每次使用该域就要重新计算,而不是使用寄存器中的值
d.volatile不会提供任何原子操作,它也不能用来修饰final类型的变量
意思就是哪个变量需要同步操作,这个字段就修饰他
Demo:
public class SynchronizedTest {
class Bank {
//需要同步的变量加上volatile
private volatile int account = 100;
public int getAccount() {
return account;
}
/**
* 用同步方法实现
*
* @param money
*/
public void save(int money) {
account += money;
}
}
class NewThread implements Runnable {
private Bank bank;
public NewThread(Bank bank) {
this.bank = bank;
}
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
//bank.save1(10);
bank.save(10);
System.out.println(i + "账户余额为:" + bank.getAccount() + " " + System.currentTimeMillis() / 1000);
}
}
}
/**
* 建立线程,调用内部类
*/
public void useThread() {
Bank bank = new Bank();
NewThread new_thread = new NewThread(bank);
System.out.println("线程1");
Thread thread1 = new Thread(new_thread);
thread1.start();
System.out.println("线程2");
Thread thread2 = new Thread(new_thread);
thread2.start();
}
public static void main(String[] args) {
SynchronizedTest st = new SynchronizedTest();
st.useThread();
}
}
注:多线程中的非同步问题主要出现在对域的读写上,如果让域自身避免这个问题,则就不需要修改操作该域的方法。
用final域,有锁保护的域和volatile域可以避免非同步的问题。
4).使用重入锁实现线程同步
ReentrantLock() : 创建一个ReentrantLock实例
lock() : 获得锁
unlock() : 释放锁
注:ReentrantLock()还有一个可以创建公平锁的构造方法,但由于能大幅度降低程序运行效率,不推荐使用
Demo见上Lock里的ReentrantLock
5).使用局部变量实现线程同步
如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,
副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
ThreadLocal 类的常用方法
ThreadLocal() : 创建一个线程本地变量
get() : 返回此线程局部变量的当前线程副本中的值
initialValue() : 返回此线程局部变量的当前线程的"初始值"
set(T value) : 将此线程局部变量的当前线程副本中的值设置为value
Demo:
public class SynchronizedTest {
public class Bank{
//使用ThreadLocal类管理共享变量account
private ThreadLocal account = new ThreadLocal(){
@Override
protected Integer initialValue(){
return 100;
}
};
public void save(int money){
account.set(account.get()+money);
}
public int getAccount(){
return account.get();
}
}
class NewThread implements Runnable {
private Bank bank;
public NewThread(Bank bank) {
this.bank = bank;
}
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
//bank.save1(10);
bank.save(10);
System.out.println(i + "账户余额为:" + bank.getAccount() + " " + System.currentTimeMillis() / 1000);
}
}
}
/**
* 建立线程,调用内部类
*/
public void useThread() {
Bank bank = new Bank();
NewThread new_thread = new NewThread(bank);
System.out.println("线程1");
Thread thread1 = new Thread(new_thread);
thread1.start();
System.out.println("线程2");
Thread thread2 = new Thread(new_thread);
thread2.start();
}
public static void main(String[] args) {
SynchronizedTest st = new SynchronizedTest();
st.useThread();
}
}
注:ThreadLocal与同步机制
a.ThreadLocal与同步机制都是为了解决多线程中相同变量的访问冲突问题。
b.前者采用以"空间换时间"的方法,后者采用以"时间换空间"的方式
6).使用阻塞队列实现线程同步
LinkedBlockingQueue来实现线程的同步
LinkedBlockingQueue是一个基于已连接节点的,范围任意的blocking queue。
队列是先进先出的顺序(FIFO),关于队列以后会详细讲解~
LinkedBlockingQueue 类常用方法
LinkedBlockingQueue() : 创建一个容量为Integer.MAX_VALUE的LinkedBlockingQueue
put(E e) : 在队尾添加一个元素,如果队列满则阻塞
size() : 返回队列中的元素个数
take() : 移除并返回队头元素,如果队列空则阻塞
代码实例:
实现商家生产商品和买卖商品的同步
Demo:
public class BlockingSynchronizedThread {
/**
* 定义一个阻塞队列用来存储生产出来的商品
*/
private LinkedBlockingQueue queue = new LinkedBlockingQueue();
/**
* 定义生产商品个数
*/
private static final int size = 10;
/**
* 定义启动线程的标志,为0时,启动生产商品的线程;为1时,启动消费商品的线程
*/
private int flag = 0;
private class LinkBlockThread implements Runnable {
@Override
public void run() {
int new_flag = flag++;
System.out.println("启动线程 " + new_flag);
if (new_flag == 0) {
for (int i = 0; i < size; i++) {
int b = new Random().nextInt(255);
System.out.println("生产商品:" + b + "号");
try {
queue.put(b);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("仓库中还有商品:" + queue.size() + "个");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} else {
for (int i = 0; i < size / 2; i++) {
try {
int n = queue.take();
System.out.println("消费者买去了" + n + "号商品");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("仓库中还有商品:" + queue.size() + "个");
try {
Thread.sleep(100);
} catch (Exception e) {
// TODO: handle exception
}
}
}
}
}
public static void main(String[] args) {
BlockingSynchronizedThread bst = new BlockingSynchronizedThread();
LinkBlockThread lbt = bst.new LinkBlockThread();
Thread thread1 = new Thread(lbt);
Thread thread2 = new Thread(lbt);
thread1.start();
thread2.start();
}
}
注:BlockingQueue定义了阻塞队列的常用方法,尤其是三种添加元素的方法,我们要多加注意,当队列满时:
add()方法会抛出异常
offer()方法返回false
put()方法会阻塞
7).使用原子变量实现线程同步
需要使用线程同步的根本原因在于对普通变量的操作不是原子的。
那么什么是原子操作呢?
原子操作就是指将读取变量值、修改变量值、保存变量值看成一个整体来操作
即-这几种行为要么同时完成,要么都不完成。
在java的util.concurrent.atomic包中提供了创建了原子类型变量的工具类,
使用该类可以简化线程同步。
其中AtomicInteger 表可以用原子方式更新int的值,可用在应用程序中(如以原子方式增加的计数器),
但不能用于替换Integer;可扩展Number,允许那些处理机遇数字类的工具和实用工具进行统一访问。
AtomicInteger类常用方法:
AtomicInteger(int initialValue) : 创建具有给定初始值的新的AtomicInteger
addAddGet(int dalta) : 以原子方式将给定值与当前值相加
get() : 获取当前值
上面的Demo替换一下Bank
class Bank {
private AtomicInteger account = new AtomicInteger(100);
public AtomicInteger getAccount() {
return account;
}
public void save(int money) {
account.addAndGet(money);
}
}
补充–原子操作主要有:
对于引用变量和大多数原始变量(long和double除外)的读写操作;
对于所有使用volatile修饰的变量(包括long和double)的读写操作。
5.线程池
ThreadPool
1).什么是线程池
为了避免系统频繁的创建和销毁线程带来的性能消耗,可以让线程得到很好的复用。
当需要使用线程时从线程池取(原来是创建),当用完时归还线程池(原来是销毁)。
2)JDK中的线程池
通过Executors类方法可以看出,
a.它的方法ExecutorService newFixedThreadPool(int nThreads)可以创建固定数量的线程池;
Demo:
public class FixThreadPoolDemo {
public static class MyTask implements Runnable{
@Override public void run() {
System.out.println(System.currentTimeMillis() + "Thread Name:" + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args){
MyTask myTask = new MyTask();
int size =5;
ExecutorService es = Executors.newFixedThreadPool(size);
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
}
}
b.方法ExecutorService newSingleThreadExecutor()可以创建只有一个线程的线程池;
public static void main(String[] args){
MyTask myTask = new MyTask();
ExecutorService es = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
}
c.方法ExecutorService newCachedThreadPool() 可以返回一个根据实际情况调整线程数量的线程池;
public static void main(String[] args){
MyTask myTask = new MyTask();
ExecutorService es = Executors.newCachedThreadPool();
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
}
d.方法ScheduledExecutorService newSingleThreadScheduledExecutor()可以返回一个可以执行定时任务线程的线程池;
OS可以拿来执行延迟定时任务
public static void main(String[] args){
MyTask myTask = new MyTask();
ExecutorService es = Executors.newSingleThreadScheduledExecutor();
try {
es.awaitTermination(5, TimeUnit.SECONDS);
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
e.方法ScheduledExecutorService newScheduledThreadPool(int corePoolSize)可以返回指定数量可以执行定时任务的线程池。
当然这些方法都有重载方法,例如参数中加入自定义的ThreadFacotry等。
public static void main(String[] args){
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(5);
/**
* 1,executorService.scheduleAtFixedRate:创建一个周期性任务,从上个任务开始,过period周期执行下一个(如果执行时间>period,则以执行时间为周期)
* 2,executorService.scheduleWithFixedDelay:创建一个周期上午,从上个任务结束,过period周期执行下一个。
*/
//如果前边任务没有完成则调度也不会启动
executorService.scheduleAtFixedRate(new Runnable() {
public void run() {
try {
Thread.sleep(1000);
System.out.println("当前时间:" + System.currentTimeMillis()/1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},0,2, TimeUnit.SECONDS);
}
3).线程池的实现原理
a.通过看JDK源码可以知道上边五种类型的线程池创建无论哪种最后都是ThreadPoolExecutor类的封装,我们来看下ThreadPoolExecutor最原始的构造函数,和调度execute源码:
/**
* 1,corePoolSize:指定线程池中活跃的线程数量
* 2,maximumPoolSize:指定线程池中最大线程数量
* 3,keepAliveTime:超过corePoolSize个多余线程的存活时间
* 4,unit:keepAliveTime的时间单位
* 5,workQueue:任务队列,被提交但尚未被执行的任务
* 6,threadFactory:线程工厂,用于创建线程
* 7,handler拒绝策略:当任务太多来不及处理时,如何拒绝任务
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
/**
* 三步:1,创建线程直到corePoolSize;2,加入任务队列;3,如果还是执行不过来,则执行拒绝策略
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
b.workQueue,当任务被提交但尚未被执行的任务队列,是一个BlockingQueue接口的对象,只存放Runnable对象
根据队列功能分类,看下JDK提供的几种BlockingQueue:
SynchronousQueue:直接提交队列:没有容量,每一个插入操作都要等待一个相应的删除操作。通常使用需要将maximumPoolSize的值设置很大,否则很容易触发拒绝策略。
ArrayBlockingQueue:有界的任务队列:任务大小通过入参 int capacity决定,当填满队列后才会创建大于corePoolSize的线程。
LinkedBlockingQueue:无界的任务队列:线程个数最大为corePoolSize,如果任务过多,则不断扩充队列,知道内存资源耗尽。
PriorityBlockingQueue:优先任务队列:是一个无界的特殊队列,可以控制任务执行的先后顺序,而上边几个都是先进先出的策略。
c.ThreadFactory是用来创建线程池中的线程工厂类
public class ThreadFactoryDemo {
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
@Override public Thread newThread(@NonNull Runnable runnable) {
Thread t = new Thread(group, runnable,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
public static class MyTask implements Runnable{
public void run() {
System.out.println(System.currentTimeMillis() + " Thread Name:" + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
MyTask myTask = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(), new DefaultThreadFactory() {//LinkedBlockingQueue 无界的任务队列:线程个数最大为corePoolSize,如果任务过多,则不断扩充队列,知道内存资源耗尽。
public Thread newThread(Runnable r) {
Thread t =new Thread(r);
t.setDaemon(true);
System.out.println(System.currentTimeMillis() + " create thread:" + t.getName());
return t;
}
});
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
}
}
Output:
1551749560466 create thread:Thread-0
1551749560466 create thread:Thread-1
1551749560466 create thread:Thread-2
1551749560466 create thread:Thread-3
1551749560485 create thread:Thread-4
1551749560486 Thread Name:Thread-0
1551749560486 Thread Name:Thread-2
1551749560487 Thread Name:Thread-1
1551749560488 Thread Name:Thread-4
d.拒绝策略:
在使用线程池并且使用有界队列的时候,如果队列满了,任务添加到线程池的时候就会有问题
如果线程池处理速度达不到任务的出现速度时,只能执行拒绝策略
中止策略(Abort Policy):默认的策略,队列满时,会抛出异常RejectedExecutionException,调用者在捕获异常之后自行判断如何处理该任务;
抛弃策略(Discard Policy):队列满时,进程池抛弃新任务,并不通知调用者;
抛弃最久策略(Discard-oldest Policy):队列满时,进程池将抛弃队列中被提交最久的任务;
调用者运行策略(Caller-Runs Policy):该策略不会抛弃任务,也不会抛出异常,而是将任务退还给调用者,也就是说当队列满时,新任务将在调用ThreadPoolExecutor的线程中执行。
AbortPolicy:该策略是线程池的默认策略。使用该策略时,如果线程池队列满了丢掉这个任务并且抛出RejectedExecutionException异常。
public static void main(String[] args) {
MyTask myTask = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue(2), new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread t =new Thread(r);
t.setDaemon(true);
System.out.println(System.currentTimeMillis() + " create thread:" + t.getName());
return t;
}
},new RejectedExecutionHandler() {
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("Task " + r.toString() +
" rejected from " +
executor.toString());
}
});
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
}
Output:
1551754686988 create thread:Thread-0
1551754686989 create thread:Thread-1
1551754686990 create thread:Thread-2
1551754686990 create thread:Thread-3
1551754686990 create thread:Thread-4
1551754686990 Thread Name:Thread-1
1551754686990 Thread Name:Thread-0
Task java.util.concurrent.FutureTask@3cd1a2f1 rejected from java.util.concurrent.ThreadPoolExecutor@2f0e140b[Running, pool size = 5, active threads = 5, queued tasks = 2, completed tasks = 0]
Task java.util.concurrent.FutureTask@7440e464 rejected from java.util.concurrent.ThreadPoolExecutor@2f0e140b[Running, pool size = 5, active threads = 5, queued tasks = 2, completed tasks = 0]
Task java.util.concurrent.FutureTask@49476842 rejected from java.util.concurrent.ThreadPoolExecutor@2f0e140b[Running, pool size = 5, active threads = 5, queued tasks = 2, completed tasks = 0]
1551754686991 Thread Name:Thread-4
DiscardPolicy:这个策略和AbortPolicy的slient版本,如果线程池队列满了,会直接丢掉这个任务并且不会有任何异常。
public static void main(String[] args) {
MyTask myTask = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue(2), new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread t =new Thread(r);
t.setDaemon(true);
System.out.println(System.currentTimeMillis() + " create thread:" + t.getName());
return t;
}
},new RejectedExecutionHandler() {
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
//就是一个空的方法
}
});
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
}
Output:
1551754800358 create thread:Thread-0
1551754800360 create thread:Thread-1
1551754800360 create thread:Thread-2
1551754800360 create thread:Thread-3
1551754800360 create thread:Thread-4
1551754800360 Thread Name:Thread-0
DiscardOldestPolicy:这个策略从字面上也很好理解,丢弃最老的。也就是说如果队列满了,会将最早进入队列的任务删掉腾出空间,再尝试加入队列。
因为队列是队尾进,队头出,所以队头元素是最老的,因此每次都是移除对头元素后再尝试入队。
public static void main(String[] args) {
MyTask myTask = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue(2), new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread t =new Thread(r);
t.setDaemon(true);
System.out.println(System.currentTimeMillis() + " create thread:" + t.getName());
return t;
}
},new RejectedExecutionHandler() {
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
if (!executor.isShutdown()) {
//移除队头元素
executor.getQueue().poll();
//再尝试入队
executor.execute(r);
}
}
});
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
}
Output:
1551754881512 create thread:Thread-0
1551754881513 create thread:Thread-1
1551754881513 create thread:Thread-2
1551754881513 create thread:Thread-3
1551754881514 Thread Name:Thread-0
1551754881514 create thread:Thread-4
1551754881514 Thread Name:Thread-1
1551754881514 Thread Name:Thread-2
1551754881515 Thread Name:Thread-4
CallerRunsPolicy:使用此策略,如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行。就像是个急脾气的人,我等不到别人来做这件事就干脆自己干。
public static void main(String[] args) {
MyTask myTask = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue(2), new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread t =new Thread(r);
t.setDaemon(true);
System.out.println(System.currentTimeMillis() + " create thread:" + t.getName());
return t;
}
},new RejectedExecutionHandler() {
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
if (!executor.isShutdown()) {
//直接执行run方法
r.run();
}
}
});
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
}
Output:
1551754985190 create thread:Thread-0
1551754985191 create thread:Thread-1
1551754985191 create thread:Thread-2
1551754985191 create thread:Thread-3
1551754985191 create thread:Thread-4
1551754985192 Thread Name:main
1551754985196 Thread Name:Thread-0
1551754985197 Thread Name:Thread-4
1551754985197 Thread Name:Thread-2
1551754985197 Thread Name:Thread-1
1551754985198 Thread Name:Thread-3
1551754986192 Thread Name:main
1551754986197 Thread Name:Thread-1
1551754986197 Thread Name:Thread-4
1551754987192 Thread Name:Thread-2
一个完整的阻塞or非阻塞线程池的Demo:
public class CustomThreadPoolExecutor {
private ThreadPoolExecutor pool = null;
/**
*
* 线程池初始化方法?
*corePoolSize?核心线程池大小----10?
* maximumPoolSize?最大线程池大小----30?
* keepAliveTime?线程池中超过corePoolSize数目的空闲线程最大存活时间----30+单位TimeUnit?
* TimeUnit?keepAliveTime时间单位----TimeUnit.MINUTES?
* workQueue?阻塞队列----new?ArrayBlockingQueue(10)====10容量的阻塞队列?
*threadFactory?新建线程工厂----new?CustomThreadFactory()====定制的线程工厂?
* rejectedExecutionHandler?饱和策略 当提交任务数超过maxmumPoolSize+workQueue之和时,?
* 即当提交第41个任务时(前面线程都没有执行完,此测试方法中用sleep(100)),?
* 任务会交给RejectedExecutionHandler来处理?
*
*/
public void init() {
pool = new ThreadPoolExecutor(
10,
30,
30,
TimeUnit.SECONDS,
new ArrayBlockingQueue(10),
new CustomThreadFactory(),
new CustomRejectedExecutionHandler()
);
}
public void onDestory() {
if(pool != null){
pool.shutdownNow();
}
}
public ExecutorService getCustomThreadPoolExecutor() {
return this.pool;
}
private class CustomThreadFactory implements ThreadFactory {
private AtomicInteger count = new AtomicInteger(0);
@Override public Thread newThread(@NonNull Runnable runnable) {
Thread t = new Thread(runnable);
String threadName = CustomThreadPoolExecutor.class.getSimpleName() + count.addAndGet(1);
System.out.println(threadName);
t.setName(threadName);
return t;
}
}
private class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable runnable, ThreadPoolExecutor threadPoolExecutor) {
// 这里来操作拒绝策略
//记录异常
//DiscardOldestPolicy策略: 线程队列不够就先进先出
// 简单来说 这里不处理就是非阻塞线程池,执行的任务数超过maxmumPoolSize+workQueu就不正常执行了;处理了就是阻塞线程池,如下所示:
if (!threadPoolExecutor.isShutdown()) {
////移除队头元素
//threadPoolExecutor.getQueue().poll();
////再尝试入队
//threadPoolExecutor.execute(runnable);
//System.out.println("error.............");
try {
threadPoolExecutor.getQueue().put(runnable);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
CustomThreadPoolExecutor executor = new CustomThreadPoolExecutor();
executor.init();
ExecutorService pool = executor.getCustomThreadPoolExecutor();
for (int i = 0; i < 100; i++) {
System.out.println("提交的第" + i + "个任务");
pool.execute(new Runnable() {
@Override public void run() {
try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
//1.销毁----此处不能销毁,因为任务没有提交执行完,如果销毁线程池,任务也就无法执行了
//executor.onDestory();
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
e.线程池的扩展:JDK已经对线程池做了非常好的编写,如果我们想扩展怎么办呢?
ThreadPoolExecutor提供了三个方法供我们使用:
beforeExecute()每个线程执行前,
afterExecute()每个线程执行后,
terminated()线程池退出时。
我们只要对这个三方法进行重写即可:
public static void main(String[] args) throws InterruptedException {
MyTask myTask = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue(10)){
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("准备执行线程:" + r.toString() +"===" + t.getName());
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("执行完成线程:" + r.toString());
}
@Override
protected void terminated() {
System.out.println("线程池退出" );
}
};
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
Thread.sleep(3000);
es.shutdown();
}
f.线程数量的优化:线程池的大小对系统性能有一定的影响,过大或者过小都无法发挥系统的最佳性能。但是也没有必要做的特别精确,只是不要太大,不要太小即可。我们可以根据此公式进行粗略计算:线程池个数=CPU的数量CPU的使用率(1+等待时间/计算时间)。当然了还需要根据实际情况,积累实际经验,来进行判断。
g.线程池中的堆栈信息:
Demo:
public class ExceptionThreadPoolDemo {
public static class MyTask implements Runnable {
int a, b;
public MyTask(int a, int b) {
this.a = a;
this.b = b;
}
public void run() {
double re = a / b;
System.out.println(re);
}
}
public static void main(String[] args) {
//ExecutorService es = new TraceThreadPoolExecutor(0,Integer.MAX_VALUE,0L, TimeUnit.SECONDS,new SynchronousQueue());
ExecutorService es = new ThreadPoolExecutor(0,Integer.MAX_VALUE,0L, TimeUnit.SECONDS,new SynchronousQueue());
for (int i = 0; i < 5; i++) {
//不进行日志打印
//es.submit(new MyTask(100,i));
//进行日志打印,只是打印了具体方法错误:Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zero
// at com.ljh.thread.thread_pool.ExceptionThreadPoolDemo$MyTask.run(ExceptionThreadPoolDemo.java:24)
// at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
// at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
// at java.lang.Thread.run(Thread.java:748)
//es.submit(new MyTask(100,i));
es.execute(new MyTask(100, i));
}
}
}
本来除数有一个是0会异常,使用execute还好,若使用submit,异常就被吃了
这就是我们常说的Runnable没有返回值,不能抛出受检查的异常。
但是这样的异常只告诉我们异常是哪里抛出的,看不到任务是在哪里提交的
所以扩展ThreadPoolExecutor,重写submit方法和execute方法
public class TraceThreadPoolExecutor extends ThreadPoolExecutor {
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,
BlockingQueue workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
public void execute(Runnable command) {
super.execute(wrap(command,clientTrace(),Thread.currentThread().getName()));
}
private Runnable wrap(final Runnable command, final Exception clientTrace, String Threadname) {
return new Runnable(){
@Override
public void run() {
try{
command.run();//执行原本任务捕获异常
}catch(Exception e){
clientTrace.printStackTrace();
throw e;// 抛出原本任务的异常
}
}
};
}
private Exception clientTrace() {
return new Exception("Client stack trace");
}
@Override
public Future submit(Runnable task) {
return super.submit(wrap(task,clientTrace(),Thread.currentThread().getName()));
}
}
main方法
public static void main(String[] args) {
ExecutorService es = new TraceThreadPoolExecutor(0,Integer.MAX_VALUE,0L, TimeUnit.SECONDS,new SynchronousQueue());
for (int i = 0; i < 5; i++) {
//es.submit(new MyTask(100,i));
es.execute(new MyTask(100, i));
}
}
h.分而治之:Fork/Join:大家都知道hadoop中的Map-Reduce分开处理,合并结果;当今流行的分布式,将用户的请求分散处理等等。分而治之是非常有用实用的。
JDK帮我们提供了ForkJoinPool线程池,供我们做这些处理.
ForkJoin主要提供了两个主要的执行任务的接口。RecurisiveAction与RecurisiveTask 。
RecurisiveAction :没有返回值的接口。
RecurisiveTask :带有返回值的接口。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态.而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行.那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程的等待时间,提高了性能.
Demo1:
@RequiresApi(api = Build.VERSION_CODES.LOLLIPOP)
public class ForkJoinPoolDemo {
class SendMsgTask extends RecursiveAction {
private final int THRESHOLD = 100;
private int start;
private int end;
private List list;
public SendMsgTask(int start, int end, List list) {
this.start = start;
this.end = end;
this.list = list;
}
@Override
protected void compute() {
if ((end - start) <= THRESHOLD) {
for (int i = start; i < end; i++) {
System.out.println(Thread.currentThread().getName() + ": " + list.get(i));
}
}else {
int middle = (start + end) / 2;
invokeAll(new SendMsgTask(start, middle, list), new SendMsgTask(middle, end, list));
}
}
}
public static void main(String[] args) throws InterruptedException {
List list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
list.add(String.valueOf(i+1));
}
ForkJoinPool pool = new ForkJoinPool();
pool.submit(new ForkJoinPoolDemo().new SendMsgTask(0, list.size(), list));
pool.awaitTermination(10, TimeUnit.SECONDS);
pool.shutdown();
}
}
Demo2:
@RequiresApi(api = Build.VERSION_CODES.LOLLIPOP)
public class ForkJoinPoolDemo {
private class SumTask extends RecursiveTask {
private static final int THRESHOLD = 20;
private int arr[];
private int start;
private int end;
public SumTask(int[] arr, int start, int end) {
this.arr = arr;
this.start = start;
this.end = end;
}
/**
* 小计
*/
private Integer subtotal() {
Integer sum = 0;
for (int i = start; i < end; i++) {
sum += arr[i];
}
System.out.println(Thread.currentThread().getName() + ": ∑(" + start + "~" + end + ")=" + sum);
return sum;
}
@Override
protected Integer compute() {
if ((end - start) <= THRESHOLD) {
return subtotal();
}else {
int middle = (start + end) / 2;
SumTask left = new SumTask(arr, start, middle);
SumTask right = new SumTask(arr, middle, end);
left.fork();
right.fork();
return left.join() + right.join();
}
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
int[] arr = new int[1000];
for (int i = 0; i < 1000; i++) {
arr[i] = i + 1;
}
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask result = pool.submit(new ForkJoinPoolDemo().new SumTask(arr, 0, arr.length));
System.out.println("最终计算结果: " + result.invoke());
pool.shutdown();
}
}
6.JUC库
1).JUC简介:在 Java 5.0 提供了 java.util.concurrent (简称JUC )包,在此包中增加了在并发编程中很常用的实用工具类,用于定义类似于线程的自定义子系统,包括线程池、异步 IO 和轻量级任务框架。提供可调的、灵活的线程池。还提供了设计用于多线程上下文中的 Collection 实现等。
2).volatile关键字:当多个线程进行操作共享数据时,可以保证内存中的数据是可见的;相较于 synchronized 是一种较为轻量级的同步策略;
在多个线程共享单个变量时可以使用
3).原子量 变量 CAS 算法
a.原子变量
类 AtomicBoolean、AtomicInteger、AtomicLong 和 AtomicReference 的实例各自提供对相应类型单个变量的访问和更新。每个类也为该类型提供适当的实用工具方法。AtomicIntegerArray、AtomicLongArray 和 AtomicReferenceArray 类进一步扩展了原子操作,对这些类型的数组提供了支持。这些类在为其数组元素提供 volatile 访问语义方面也引人注目,这对于普通数组来说是不受支持的。核心方法:boolean compareAndSet(expectedValue, updateValue)
public class TestAtomicDemo {
public static void main(String[] args){
AtomicDemo ad = new AtomicDemo();
for(int i=0; i < 10; i++){
new Thread(ad).start();
}
}
}
class AtomicDemo implements Runnable{
private AtomicInteger atomicInteger = new AtomicInteger(0);
public void run(){
try{
Thread.sleep(200);
}catch(InterruptedException e){
}
System.out.println(Thread.currentThread().getName() + ":" + getSerialNumber());
}
public int getSerialNumber(){
return atomicInteger.getAndIncrement();//原子变量的自增运算
}
}
b.CAS算法:Compare and Swap比较并交换。总共由三个操作数,一个内存值v,一个线程本地内存旧值a(期望操作前的值)和一个新值b,在操作期间先拿旧值a和内存值v比较有没有发生变化,如果没有发生变化,才能内存值v更新成新值b,发生了变化则不交换。
CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题:ABA问题、循环时间长开销大、只能保证一个共享变量的原子操作。
4).并发容器
a.ConcurrentHashMap
ConcurrentHashMap它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中
ConcurrentHashMap和HashMap的比较:Hashmap是哈希表的map实现,可操作null键和null值,是非线程安全的,ConcurrentHashMap 是线程安全的;储存方式是:key所对应的value值链接成一个链表,而数组中储存的是链表第一个节点的地址值,所以hashmap又叫链表的数组。hashmap的性能受两个因素的影响,初始容量和加载因子,若hash表中的条目数超过初始值和加载因子的乘积,那么hash表将做出自我调整,将容量扩充为原来的两倍,并将原有的数据重新映射到表中,这个操作叫做rehash,容量扩充,重新映射,所以说rehash必将会造成时间和空间的开销,所以说初始容量和加载因子会影响hashmap的性能。
b.CountDownLatch(闭锁)是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待;
public class TestCountDownLatch {
// 主线程等待子线程执行完,然后执行计时操作
public static void main(String[] args) {
final CountDownLatch latch = new CountDownLatch(10);//10就是实际上就是闭锁需要等待的线程数量
LatchDemo ld = new LatchDemo(latch);
long start = System.currentTimeMillis();
// 创建10个线程
for (int i = 0; i < 10; i++) {
new Thread(ld).start();
}
try {
latch.await();//与CountDownLatch的第一次交互是主线程等待其他线程。主线程必须在启动其他线程后立即调用CountDownLatch.await()方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。 这样就达到计时的效果
} catch (InterruptedException e) {
}
long end = System.currentTimeMillis();
System.out.println("耗费时间为:" + (end - start));
}
}
class LatchDemo implements Runnable {
private CountDownLatch latch;
// 有参构造器
public LatchDemo(CountDownLatch latch) {
this.latch = latch;
}
public void run() {
synchronized (this) {
try {
// 打印50000以内的偶数
for (int i = 0; i < 50000; i++) {
if (i % 2 == 0) {
System.out.println(i + " " + Thread.currentThread().getName());
}
}
} finally {
// 线程数量递减
latch.countDown();
}
}
}
}
CountDownLatch的3个使用场景:
实现最大的并行性:有时我们想同时启动多个线程,实现最大程度的并行性。例如,我们想测试一个单例类。如果我们创建一个初始计数为1的CountDownLatch,并让所有线程都在这个锁上等待,那么我们可以很轻松地完成测试。我们只需调用 一次countDown()方法就可以让所有的等待线程同时恢复执行。
开始执行前等待n个线程完成各自任务:例如应用程序启动类要确保在处理用户请求前,所有N个外部系统已经启动和运行了。
死锁检测:一个非常方便的使用场景是,你可以使用n个线程访问共享资源,在每次测试阶段的线程数目是不同的,并尝试产生死锁。
五.IO(字节流、字符流、转换流、文件)
1.字节流
1).InputStream/OutPutStream - - -字节流基类
你把你自己想象为是一个程序,InputStream对你来说是输入,也就是你要从某个地方读到自己这来,而OutputStream对你来说就是输出,也就是说你需要写到某个地方
a.InputStream 此抽象类是表示字节输入流的所有类的超类。需要定义 InputStream 的子类的应用程序必须始终提供返回下一个输入字节的方法
int available()
返回此输入流方法的下一个调用方可以不受阻塞地从此输入流读取(或跳过)的字节数。
void close()
关闭此输入流并释放与该流关联的所有系统资源。
void mark(int readlimit)
在此输入流中标记当前的位置。
boolean markSupported()
测试此输入流是否支持 mark 和 reset 方法。
abstract int read()
从输入流读取下一个数据字节。
int read(byte[] b)
从输入流中读取一定数量的字节并将其存储在缓冲区数组 b 中。
int read(byte[] b, int off, int len)
将输入流中最多 len 个数据字节读入字节数组。
void reset()
将此流重新定位到对此输入流最后调用 mark 方法时的位置。
long skip(long n)
跳过和放弃此输入流中的 n 个数据字节。
b.OutputStream 此抽象类是表示输出字节流的所有类的超类。输出流接受输出字节并将这些字节发送到某个接收器。需要定义OutputStream 子类的应用程序必须始终提供至少一种可写入一个输出字节的方法。
void close()
关闭此输出流并释放与此流有关的所有系统资源。
void flush()
刷新此输出流并强制写出所有缓冲的输出字节。
void write(byte[] b)
将 b.length 个字节从指定的字节数组写入此输出流。
void write(byte[] b, int off, int len)
将指定字节数组中从偏移量 off 开始的 len 个字节写入此输出流。
abstract void write(int b)
将指定的字节写入此输出流。
进行I/O操作时可能会产生I/O例外,属于非运行时例外,应该在程序中处理。如:FileNotFoundException, EOFException, IOException等等,下面具体说明操作JAVA字节流的方法。
2).FileInputStream/FileOutputStream - - - - -处理文件类型
本例以FileInputStream的read(buffer)方法,每次从源程序文件TestFile.txt中读取1024个字节,存储在缓冲区buffer中,再将以buffer中的值构造的字符串new String(buffer)显示在屏幕上。程序如下(请在根目录下建立TestFile.txt文件,以便正常运行):
public class ReadFile {
public static void main(String[] args) {
try {
// 创建文件输入流对象
FileInputStream is = new FileInputStream("TestFile.txt");
// 设定读取的字节数
int n = 1024;
byte buffer[] = new byte[n];
// 读取输入流
while ((is.read(buffer, 0, n) != -1) && (n > 0)) {
System.out.print(new String(buffer));
}
System.out.println();
// 关闭输入流
is.close();
} catch (IOException ioe) {
System.out.println(ioe);
} catch (Exception e) {
System.out.println(e);
}
}
}
本例用System.in.read(buffer)从键盘输入一行字符,存储在缓冲区buffer中,再以FileOutStream的write(buffer)方法,将buffer中内容写入文件WriteFile.txt中,程序如下(运行后会在根目录下建立WriteFile.txt文件):
public class WriteFile {
public static void main(String[] args) {
try {
System.out.print("输入要保存文件的内容:");
int count, n = 1024;
byte buffer[] = new byte[n];
// 读取标准输入流
count = System.in.read(buffer);
// 创建文件输出流对象
FileOutputStream os = new FileOutputStream("WriteFile.txt");
//ileOutputStream os = new FileOutputStream("WriteFile.txt",true);//如果第二个参数为 true,则将字节写入文件末尾处,而不是写入文件开始处。如果有间隔 则和长度有关系
// 写入输出流
os.write(buffer, 0, count);
// 关闭输出流
os.close();
System.out.println("已保存到WriteFile.txt!");
} catch (IOException ioe) {
System.out.println(ioe);
} catch (Exception e) {
System.out.println(e);
}
}
}
3).ByteArrayInputStream/ByteArrayOutputStream - - - -字节数组类型
ByteArrayOutputStream把内存中的数据读到字节数组中,而ByteArrayInputStream又把字节数组中的字节以流的形式读出,实现了对同一个字节数组的操作.
ByteArrayInputStream相对于ByteArrayOutputStream的(可以将程序中的数据读到自己内置的大小任意的缓冲区中,再写到一个Byte数组中)功能,显得比较鸡肋,在JDK介绍文档中介绍的都比较少(将字节数组中的数据,读到流中的缓冲区中,再反馈给程序)该缓冲区中包含从流中读取的字节。内部计数器跟踪read方法要提供的下一个字节。关闭ByteArrayInputStream无效(ByteArrayOutputStream相同)此类中的方法,在关闭此流之后,仍可以被调用,而不会产生IOException。
Demo:
public class ByteArrayInputStreamDemo {
public static void main(String[] args)throws Exception{
Data data = new Data();
byte[] temp = data.getData();
InputStream inputStream = new ByteArrayInputStream(temp);
byte[] arr =new byte[temp.length];
inputStream.read(arr);
System.out.println(new String(arr));
}
}
class Data{
byte[] data = "abc".getBytes();
public byte[] getData() {
returndata;
}
}
ByteArrayOutputStream是用来缓存数据的(数据写入的目标(output stream原义)),向它的内部缓冲区写入数据,缓冲区自动增长,当写入完成时可以从中提取数据。由于这个原因,ByteArrayOutputStream常用于存储数据以用于一次写入。
关闭 ByteArrayOutputStream 无效。此类中的方法在关闭此流后仍可被调用,而不会产生任何IOException
Demo:从文件中读取二进制数据,全部存储到ByteArrayOutputStream中。
public static void main(String[] args) throws Exception {
FileInputStream fis = new FileInputStream("TestFile.txt");
BufferedInputStream bis = new BufferedInputStream(fis);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int c = bis.read();//读取bis流中的下一个字节
while (c != -1) {
baos.write(c);
c = bis.read();
}
bis.close();
byte retArr[] = baos.toByteArray();
System.out.println(new String(retArr));
}
4).BufferedInputStream/BufferedOutputStream - - - -缓冲流
BufferedInputStream是带缓冲区的输入流,默认缓冲区大小是8M,能够减少访问磁盘的次数,提高文件读取性能;
BufferedOutputStream是带缓冲区的输出流,能够提高文件的写入效率。
BufferedInputStream与BufferedOutputStream分别是FilterInputStream类和FilterOutputStream类的子类,实现了装饰设计模式。
BufferedInputStream:
Demo:
public class ReadFile {
public static void main(String[] args) {
try {
// 创建文件输入流对象
FileInputStream is = new FileInputStream("TestFile.txt");
BufferedInputStream bis = new BufferedInputStream(is);
// 设定读取的字节数
int n = 1024;
byte buffer[] = new byte[n];
// 读取输入流
while ((bis.read(buffer, 0, n) != -1) && (n > 0)) {//int read(byte[] b, int off, int len 将输入流中最多 len 个数据字节读入字节数组。
System.out.print(new String(buffer));
}
System.out.println();
// 关闭输入流
bis.close();
} catch (IOException ioe) {
System.out.println(ioe);
} catch (Exception e) {
System.out.println(e);
}
}
}
BufferedOutputStream:
Demo:
public class WriteFile {
public static void main(String[] args) {
try {
System.out.print("输入要保存文件的内容:");
int count, n = 512;
byte buffer[] = new byte[n];
// 读取标准输入流
count = System.in.read(buffer);
// 创建文件输出流对象
FileOutputStream os = new FileOutputStream("WriteFile.txt",true);//如果第二个参数为 true,则将字节写入文件末尾处,而不是写入文件开始处。
// 写入输出流
BufferedOutputStream outputStream = new BufferedOutputStream(os);
outputStream.write(buffer, 0, count);//将指定字节数组中从偏移量 off 开始的 len 个字节写入此输出流。
outputStream.flush();//刷新缓冲区,一定要写,否则写入不到文件中去
// 关闭输出流
outputStream.close();
System.out.println("已保存到WriteFile.txt!");
} catch (IOException ioe) {
System.out.println(ioe);
} catch (Exception e) {
System.out.println(e);
}
}
}
5).DataInputStream/DataOutputStream - - - -装饰类
DataOutputStream数据输出流允许应用程序将基本Java数据类型写到基础输出流中;
DataInputStream数据输入流允许应用程序以机器无关的方式从底层输入流中读取基本的Java类型.
DataOutputStream dos = new DataOutputStream(new FileOutputStream(“文件名”));
几种写入数据方法的区别:
dos.writeBytes(String):writeBytes(String) 依次写入字符串中的每一个字符,并且只写入字符的低8位,高字节被抛弃。比如,writeBytes(“ABC”), "ABC"中每个字符对应的java字符编码(java中每个字符都是2字节16位的):
'A’字符编码:00000000_01000001
'B’字符编码:00000000_01000010
'C’字符编码:00000000_01000011
writeBytes(“ABC”),实际写入了三个字节: 01000001_01000010_01000011
dos.writeChars(String):writeChars(String) 依次写入字符串中的每一个字符,字符的2个字节全部写入。dos.writeChars(“中国人”)会写入6个字节。 dos.writeChars(“ABC”)同样写入6个字节。
dos.write(String.getBytes()):同样对应上面的2个字符串 “ABC” 和 “中国人”,可以这样输出:
dos.write(“ABC”.getBytes());
dos.write(“中国人”.getBytes());
write(string.getBytes()) 和?writeBytes(string) 有着本质的区别。
无论是??writeBytes(string) ,还是writeChars(String) 都不存在字符编码的转码的问题, 而write(string.getBytes()) 则涉及到字符编码转换问题。
dos.writeUTF(String):writeUTF()写出一个UTF-8编码的字符串前面会加上2个字节的长度标识,已标识接下来的多少个字节是属于本次方法所写入的字节数
读取的时候是dos.readUTF();
Demo:
public class TestDataOutStream {
public static void main(String[] args) {
// 使用DataInputStream,DataOutputStream写入文件且从文件里读取数据。
try {
// Data Stream写到输入流中
DataOutputStream dos = new DataOutputStream(new FileOutputStream(
"datasteam.txt"));
dos.write("世界".getBytes()); // 按UTF8编码(我的系统默认编码方式)写入
//dos.write("世界".getBytes("GBK")); //指定其它编码方式
dos.writeChars("世界"); // 依照Unicode写入
// 依照UTF-8写入(UTF8编码长度可变。开头2字节是由writeUTF函数写入的长度信息,方便readUTF函数读取)
dos.writeUTF("世界");
dos.flush();
dos.close();
// Data Stream 读取
DataInputStream dis = new DataInputStream(new FileInputStream(
"datasteam.txt"));
// 读取字节
byte[] b = new byte[6];//
dis.read(b);
System.out.println(new String(b, 0, 6));
// 读取字符
char[] c = new char[2];
for (int i = 0; i < 2; i++) {
c[i] = dis.readChar();
}
System.out.println(new String(c, 0, 2));
// 读取UTF
System.out.println(dis.readUTF());
dis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
六.网络编程(Socket原理机制,UDP传输,TCP传输,Http协议)
1.Socket原理机制
我们的主角Socket,它是应用层之下,传输层之上的一个接口层,也就是操作系统提供给用户访问网络的系统接口,
我们可以借助于Socket接口层,对传输层,网际层以及网络接口层进行操作,来实现我们不同的应用层协议,
举几个例子,如HTTP是基于TCP实现的,ping和tracerouter是基于ICMP实现的,libpcap(用wireshare做过网络抓包的可能更熟悉)则是直接读取了网络接口层的数据,但是他们的实现,都是借助于Socket完成的。可见,对于应用层,我们想实现网络功能,归根究底都是要通过Socket来实现的,否则,我们无法访问处于操作系统的传输层,网际层以及网络接口层。
TCP/UDP区别:
1).TCP是可靠的,也就是说,我们通过TCP发送的数据,网络协议栈会保证数据可靠的传输到对端;
UDP是不可靠的,如果出现丢包,协议栈不会做任何处理,可靠性的保证交由应用层处理。因此,TCP的性能会比UDP低,但是可靠性会比UDP好很多。
2).两者在传输数据时,也有形式上的不同,TCP的数据是流,大家可以类比文件流,而UDP则是基于数据包,也就是说数据会被打成包发送
在UDP中,每次发送数据报,需要附上本机的socket描述符和接收端的socket描述符.而TCP是基于连接的协议,在通信的socket之间需要在通信之前建立连接,即TCP的三次握手,,因此建立连接会有一定耗时
在UDP中,数据报数据在大小有64KB的限制。而TCP不存在这样的限制,一旦TCP通信的socket对建立连接,他们通信类似IO流。
UDP是不可靠的协议,发送的数据报不一定会按照其发送顺序被接收端的socket接收。而TCP是一种可靠的协议。接收端收到的包的顺序和包在发送端的顺序大体一致(这里不讨论丢包的情况)
3).说到这,至于选择哪种协议,还是取决于你的使用场景,当然目前见得比较多就是基于TCP协议的Socket通信。当然一些实时性较高的一些服务,局域网的一些服务用UDP的多一些。
基于TCP协议的Java Socket编程实例:
Socket通信步骤:(简单分为4步)
a.建立服务端ServerSocket和客户端Socket
b.打开连接到Socket的输出输入流
c.按照协议进行读写操作
d.关闭相对应的资源
4).相关联的API
a.类ServerSocket
此类实现服务器套接字。服务器套接字等待请求通过网络传入。它基于该请求执行某些操作,然后可能向请求者返回结果。
服务器套接字的实际工作由 SocketImpl 类的实例执行。应用程序可以更改创建套接字实现的套接字工厂来配置它自身,从而创建适合本地防火墙的套接字。
一些重要的方法:(具体大家查看官方api吧)
ServerSocket(int port, int backlog)
利用指定的 backlog 创建服务器套接字并将其绑定到指定的本地端口号。
bind(SocketAddress endpoint, int backlog)
将 ServerSocket 绑定到特定地址(IP 地址和端口号)。
accept()
侦听并接受到此套接字的连接
getInetAddress()
返回此服务器套接字的本地地址。
close()
关闭此套接字。
b.类Socket
此类实现客户端套接字(也可以就叫“套接字”)。套接字是两台机器间通信的端点。
套接字的实际工作由 SocketImpl 类的实例执行。应用程序通过更改创建套接字实现的套接字工厂可以配置它自身,以创建适合本地防火墙的套接字。
一些重要的方法:(具体大家查看官方api吧)
Socket(InetAddress address, int port)
创建一个流套接字并将其连接到指定 IP 地址的指定端口号。
getInetAddress()
返回套接字连接的地址。
shutdownInput()
此套接字的输入流置于“流的末尾”。
shutdownOutput()
禁用此套接字的输出流。
close()
关闭此套接字
c.代码实现:
服务端Server_Socket.java
(1).创建ServerSocket对象,绑定并监听端口
(2).通过accept监听客户端的请求
(3).建立连接后,通过输出输入流进行读写操作
(4).关闭相关资源
public class Server_Socket {
/**
* Socket服务端
*/
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(8888);
System.out.println("服务端已启动,等待客户端连接..");
Socket socket = serverSocket.accept();//侦听并接受到此套接字的连接,返回一个Socket对象
//根据输入输出流和客户端连接
InputStream inputStream = socket.getInputStream();//得到一个输入流,接收客户端传递的信息
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);//提高效率,将自己字节流转为字符流
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);//加入缓冲区
String temp = null;
String info = "";
while ((temp = bufferedReader.readLine()) != null) {
info += temp;
System.out.println("已接收到客户端连接");
System.out.println(
"服务端接收到客户端信息:" + info + ",当前客户端ip为:" + socket.getInetAddress().getHostAddress());
}
OutputStream outputStream = socket.getOutputStream();//获取一个输出流,向服务端发送信息
PrintWriter printWriter = new PrintWriter(outputStream);//将输出流包装成打印流
printWriter.print("你好,服务端已接收到您的信息");
printWriter.flush();
socket.shutdownOutput();//关闭输出流
//关闭相对应的资源
printWriter.close();
outputStream.close();
bufferedReader.close();
inputStream.close();
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
客户端Client_Socket.java
(1).创建Socket对象,指定服务端的地址和端口号
(2).建立连接后,通过输出输入流进行读写操作
(3).通过输出输入流获取服务器返回信息
(4).关闭相关资源
public class Client_Socket {
/**
* Socket客户端
*/
public static void main(String[] args) {
try {
//创建Socket对象
Socket socket = new Socket("localhost", 8888);
//根据输入输出流和服务端连接
OutputStream outputStream = socket.getOutputStream();//获取一个输出流,向服务端发送信息
PrintWriter printWriter = new PrintWriter(outputStream);//将输出流包装成打印流
printWriter.print("服务端你好,我是Balla_兔子");
printWriter.flush();
socket.shutdownOutput();//关闭输出流
InputStream inputStream = socket.getInputStream();//获取一个输入流,接收服务端的信息
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);//包装成字符流,提高效率
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);//缓冲区
String info = "";
String temp = null;//临时变量
while ((temp = bufferedReader.readLine()) != null) {
info += temp;
System.out.println("客户端接收服务端发送信息:" + info);
}
//关闭相对应的资源
bufferedReader.close();
inputStream.close();
printWriter.close();
outputStream.close();
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
以上代码实现了单客户端和服务端的连接,若要实现多客户端操作,需要涉及到多线程,只要你把每个接收到的Socket对象单独开一条线程操作,然后用一个死循环while(true)去监听端口就行,这边直接给代码了
线程操作类:SocketThread.java
public class SocketThread extends Thread {
private Socket socket;
public SocketThread(Socket socket) {
this.socket = socket;
}
public void run() {
// 根据输入输出流和客户端连接
try {
InputStream inputStream = socket.getInputStream();
// 得到一个输入流,接收客户端传递的信息
InputStreamReader inputStreamReader = new InputStreamReader(
inputStream);// 提高效率,将自己字节流转为字符流
BufferedReader bufferedReader = new BufferedReader(
inputStreamReader);// 加入缓冲区
String temp = null;
String info = "";
while ((temp = bufferedReader.readLine()) != null) {
info += temp;
System.out.println("已接收到客户端连接");
System.out.println("服务端接收到客户端信息:" + info + ",当前客户端ip为:"
+ socket.getInetAddress().getHostAddress());
}
OutputStream outputStream = socket.getOutputStream();// 获取一个输出流,向服务端发送信息
PrintWriter printWriter = new PrintWriter(outputStream);// 将输出流包装成打印流
printWriter.print("你好,服务端已接收到您的信息");
printWriter.flush();
socket.shutdownOutput();// 关闭输出流
// 关闭相对应的资源
bufferedReader.close();
inputStream.close();
printWriter.close();
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
服务端变成
public class Server_Socket {
/**
* Socket服务端
*/
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(8881);
System.out.println("服务端已启动,等待客户端连接..");
while (true) {
Socket socket = serverSocket.accept();// 侦听并接受到此套接字的连接,返回一个Socket对象
SocketThread socketThread = new SocketThread(socket);
socketThread.start();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Socket一个服务端和客户端可以互相对话的Demo
服务端:
public class Server_Test extends Thread{
ServerSocket server = null;
Socket socket = null;
public Server_Test(int port) {
try {
server = new ServerSocket(port);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void run(){
super.run();
try{
System.out.println("wait client connect...");
while(true){
socket = server.accept();
new sendMessThread().start();//连接并返回socket后,再启用发送消息线程
System.out.println(socket.getInetAddress().getHostAddress()+"SUCCESS TO CONNECT...");
InputStream in = socket.getInputStream();
int len = 0;
byte[] buf = new byte[1024];
while ((len=in.read(buf))!=-1){
System.out.println("client saying: "+new String(buf,0,len));
}
}
}catch (IOException e){
e.printStackTrace();
}
}
class sendMessThread extends Thread{
@Override
public void run(){
super.run();
Scanner scanner=null;
OutputStream out = null;
try{
if(socket != null){
scanner = new Scanner(System.in);
out = socket.getOutputStream();
String in = "";
do {
in = scanner.next();
out.write(("server saying: "+in).getBytes());
out.flush();//清空缓存区的内容
}while (!in.equals("q"));
scanner.close();
try{
out.close();
}catch (IOException e){
e.printStackTrace();
}
}
}catch (IOException e) {
e.printStackTrace();
}
}
}
//函数入口
public static void main(String[] args) {
Server_Test server = new Server_Test(1235);
server.start();
}
}
客户端:
public class Client extends Thread {
//定义一个Socket对象
Socket socket = null;
public Client(String host, int port) {
try {
//需要服务器的IP地址和端口号,才能获得正确的Socket对象
socket = new Socket(host, port);
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void run() {
//客户端一连接就可以写数据个服务器了
new sendMessThread().start();
super.run();
try {
// 读Sock里面的数据
InputStream s = socket.getInputStream();
byte[] buf = new byte[1024];
int len = 0;
while ((len = s.read(buf)) != -1) {
System.out.println(new String(buf, 0, len));
}
} catch (IOException e) {
e.printStackTrace();
}
}
//往Socket里面写数据,需要新开一个线程
class sendMessThread extends Thread{
@Override
public void run() {
super.run();
//写操作
Scanner scanner=null;
OutputStream os= null;
try {
scanner=new Scanner(System.in);
os= socket.getOutputStream();
String in="";
do {
in=scanner.next();
os.write((""+in).getBytes());
os.flush();
} while (!in.equals("bye"));
} catch (IOException e) {
e.printStackTrace();
}
scanner.close();
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//函数入口
public static void main(String[] args) {
//需要服务器的正确的IP地址和端口号
Client clientTest=new Client("127.0.0.1", 1235);
clientTest.start();
}
}
2.UDP传输
1).UDP协议
在有些应用程序中,保持最快的速度比保证每一位数据都正确到达更重要。
例如,在实时音频或视频中,丢失数据包只会作为干扰出现。干扰是可以容忍的,但当TCP请求重传或等待数据包到达而它却迟迟不到时,音频流中就会出现尴尬的停顿,这让人无法接受的。在其他应用中,可以在应用层实现可靠性传输。
例如:如果客户端向服务器发送一个短的UDP请求,倘若制定时间内没有响应返回,它会认为这个包已丢失。域名系统就是采用这样的工作方式。
事实上,可以用UDP实现一个可靠的文件传输协议,而且很多人确实是这样做的:网络文件系统,简单FTP都使用了UDP协议。在这些协议中由应用程序来负责可靠性。
java中的UDP实现分为两个类:DatagramPacket和 DatagramSocket。DatagramPacket类将数据字节填充到UDP包中,这称为数据报。
DatagramSocket来发送这个包。要接受数据,可以从DatagramSocket中接受一个 DatagramPack对象,然后从该包中读取数据的内容。
UDP是面向无连接的单工通信,它速度快。
a.DatagramSocket类
构造函数:
DatagramSocket()
创建实例,通常用于客户端编程,他并没有特定的监听端口,仅仅使用一个临时的。
DatagramSocket(int port)
创建实例,并固定监听Port端口的报文。
DatagramSocket(int port, InetAddress laddr)
这是个非常有用的构建器,当一台机器拥有多于一个IP地址的时候,由它创建的实例仅仅接收来自LocalAddr的报文。
DatagramSocket(SocketAddress bindaddr)
bindaddr对象中指定了端口和地址。
常用函数:
receive(DatagramPacket p)
接收数据报文到p中。receive方法是阻塞的,如果没有接收到数据报包的话就会阻塞在哪里。
send(DatagramPacket p)
发送报文p到目的地。
setSoTimeout(int timeout)
设置超时时间,单位为毫秒。
close()
关闭DatagramSocket。在应用程序退出的时候,通常会主动的释放资源,关闭Socket,但是由于异常的退出可能造成资源无法回收。所以应该在程序完成的时候,主动使用此方法关闭Socket,或在捕获到异常后关闭Socket。
b.DatagramPacket类
DatagramPacket类用于处理报文,将字节数组、目标地址、目标端口等数据包装成报文或者将报文拆卸成字节数组。
构造函数:
DatagramPacket(byte[] buf, int length, InetAddress addr, int port)
从buf字节数组中取出offset开始的、length长的数据创建数据对象,目标地址是addr,目标端口是port。
DatagramPacket(byte buf[], int offset, int length, SocketAddress address)
从buf字节数组中取出offset开始的、length长的数据创建数据对象,目标地址是address
常用函数:
getData() byte[]
从实例中取得报文中的字节数组编码。
setData(byte[] buf, int offset, int length)
设置数据报包中的数据内容
c.UDP通信的通信流程
UDP发送端:
(1).建立updsocket服务。
(2).提供数据,并将数据封装到数据包中。
(3).通过socket服务的发送功能,将数据包发出去。
(4).关闭资源。
UDP接收端:
(1).定义udpsocket服务,通常会监听一个端口。
(2).定义一个数据包,存储接收到的字节数据。
(3).通过socket服务的receive方法将收到的数据存入已定义好的数据包中。
(4).通过数据包对象的特有功能,将这些不同的数据取出,打印在控制台上。
(5).关闭资源
发送端
public class Send {
public static void main(String[] args) throws Exception {
DatagramSocket ds = new DatagramSocket();//通过DatagramSocket对象创建udp服务
BufferedReader bufr =
new BufferedReader(new InputStreamReader(System.in));//从键盘上面输入文本
String line = null;
while((line=bufr.readLine())!=null)//当输入不为空时
{
if("byebye".equals(line))//当输入为byebye时退出程序
break;
//确定好数据后,并把数据封装成数据包
byte[] buf = line.getBytes();
DatagramPacket dp =
new DatagramPacket(buf,buf.length, InetAddress.getByName("127.0.0.1"),30000);//发送至指定IP,指定端口
ds.send(dp);//通过send方法将数据包发送出去
}
ds.close();//关闭资源
}
}
接收端
public class Receive {
public static void main(String[] args) throws Exception
{
@SuppressWarnings("resource")
DatagramSocket ds = new DatagramSocket(30000);//接收端监听指定端口
while(true)
{
//定义数据包,用于存储数据
byte[] buf = new byte[1024];
DatagramPacket dp = new DatagramPacket(buf,buf.length);
ds.receive(dp);//通过服务的receive方法将收到数据存入数据包中,receive()为阻塞式方法,接收到数据报之前会一直阻塞
//通过数据包的方法获取其中的数据
String ip = dp.getAddress().getHostAddress();
String data = new String(dp.getData(),0,dp.getLength());
System.out.println(ip+"::"+data);
}
}
}
3.TCP传输
Socket的使用就是TCP传输的基本用法;见上1
4.UDP传输和TCP传输的比较
UDP通讯协议的特点:(DatagramPacket和 DatagramSocket)
a. 将数据极封装为数据包,面向无连接。
b. 每个数据包大小限制在64K中
c.因为无连接,所以不可靠
d. 因为不需要建立连接,所以速度快
e.udp 通讯是不分服务端与客户端的,只分发送端与接收端。
TCP通讯协议特点:(Socket和ServerScocket)
a. tcp是基于IO流进行数据 的传输 的,面向连接。
b. tcp进行数据传输的时候是没有大小限制的。
c. tcp是面向连接,通过三次握手的机制保证数据的完整性。 可靠协议。
d. tcp是面向连接的,所以速度慢。
e. tcp是区分客户端与服务端 的。
顺便附上我们在利用JAVA写两个协议的过程:
UDP:
发送端的使用步骤:
a. 建立udp的服务。
b. 准备数据,把数据封装到数据包中发送。 发送端的数据包要带上ip地址与端口号。
c. 调用udp的服务,发送数据。
d. 关闭资源。
接收端的使用步骤:
a. 建立udp的服务
b. 准备空 的数据 包接收数据。
c. 调用udp的服务接收数据。
d. 关闭资源
TCP:
tcp的客户端使用步骤:
a. 建立tcp的客户端服务。
b. 获取到对应的流对象。
c.写出或读取数据
d. 关闭资源。
ServerSocket的使用 步骤:
a. 建立tcp服务端 的服务。
b. 接受客户端的连接产生一个Socket.
c. 获取对应的流对象读取或者写出数据。
d. 关闭资源。
5.Http协议
1).介绍
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1。
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
HTTP协议是一个传输层基于TCP的应用层协议!
2).利用java代码测试各个协议头
一个完整的http协议包括请求和响应,
注意:使用HTTP协议,无法实现在客户端没有发起请求的时候,服务器将消息推送给客户端.
a.请求篇
http请求由三部分组成,分别是:请求行、消息报头、请求正文
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本,格式如下:Method Request-URI HTTP-Version CRLF
其中 Method表示请求方法;Request-URI是一个统一资源标识符;HTTP-Version表示请求的HTTP协议版本;CRLF表示回车和换行(除了作为结尾的CRLF外,不允许出现单独的CR或LF字符)。
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
GET 请求获取Request-URI所标识的资源
POST 在Request-URI所标识的资源后附加新的数据
HEAD 请求获取由Request-URI所标识的资源的响应消息报头
PUT 请求服务器存储一个资源,并用Request-URI作为其标识
DELETE 请求服务器删除Request-URI所标识的资源
TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT 保留将来使用
OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求
b.响应篇
响应消息包括状态行、若干头部行和附属体(html数据实体)。
状态行
状态行包括:HTTP协议版本号、状态码、状态码的文本描述信息。如:HTTP/1.1 200 OK
状态码由一个三位数组成,状态码大体有5种含义:
1. 1xx。信息,请求收到,继续处理。
2. 2xx。成功。200请求成功;206断点续传。
3. 3xx。重定向。一般跳转到新的地址。
4. 4xx。客户端错误。404文件不存在
5. 5xx。服务器错误。500内部错误。
常见状态代码、状态描述、说明:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
eg:HTTP/1.1 200 OK (CRLF)
头部行
Set-Cookie:服务器设置客户端Cookie。设置格式是name=value,设置多个参数时中间用分号隔开。Set-Cookie时还会用到几个参数:PATH设置有效的路径,DOMAIN设置cookie生效的域名,Expire设置cookie的有效时间,0表示关闭浏览器就失效。
Location:当服务器返回3xx重定向时,该参数实现重定向。广告链接的跳转就使用这种协议。
Content-Length:附属体(数据实体)的长度
3).java中的Http通信
a.使用HTTP的Get方式读取网络数据
public class ReadByGet extends Thread {
@Override public void run() {
try {
//如果有参数,在网址中携带参数
URL url = new URL("http://gank.io/api/today");
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
//伪造一下UA就可以了
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36)");
InputStream is = conn.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
int responsecode = conn.getResponseCode();
if(responsecode == 200){
String line;
StringBuilder builder = new StringBuilder();
while((line=br.readLine())!=null){
builder.append(line);
}
br.close();
isr.close();
is.close();
System.out.println(builder.toString());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
new ReadByGet().start();
}
}
b.使用HTTP的Post方式与网络交互通信
public class ReadByPost extends Thread {
@Override public void run() {
try {
URL url = new URL("网址");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.addRequestProperty("encoding", "UTF-8");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setRequestMethod("POST");
OutputStream os = conn.getOutputStream();
OutputStreamWriter osw = new OutputStreamWriter(os);
BufferedWriter bw = new BufferedWriter(osw);
bw.write("");
bw.flush();
InputStream is = conn.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String line;
StringBuilder builder = new StringBuilder();
while ((line = br.readLine()) != null) {
builder.append(line);
}
//关闭资源
System.out.println(builder.toString());
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (ProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main() {
new ReadByPost().start();
}
}
c.使用HttpClient进行Get方式通信,apache有一个HttpClient包
public class Get extends Thread {
@Override public void run() {
HttpClient client = HttpClients.createDefault();
HttpGet get = new HttpGet("http://gank.io/api/today");
try {
HttpResponse response = client.execute(get);
HttpEntity entity = response.getEntity();
String result = EntityUtils.toString(entity, "UTF-8");
System.out.println(result);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
new Get().start();
}
}
d.使用HttpClient进行Post方式通信
public class Post extends Thread {
HttpClient client = HttpClients.createDefault();
@Override public void run() {
HttpPost post = new HttpPost("网址");
//设置要传的参数
List parameters = new ArrayList();
parameters.add(new BasicNameValuePair("key", "value"));
try {
post.setEntity(new UrlEncodedFormEntity(parameters, "UTF-8"));
HttpResponse response = client.execute(post);
HttpEntity entity = response.getEntity();
String result = EntityUtils.toString(entity, "UTF-8");
System.out.println(result);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
new Post().start();
}
}
/*android {
//声明 使用
useLibrary 'org.apache.http.legacy'
}
dependencies {
implementation 'org.apache.httpcomponents:httpclient-android:4.3.5.1'
}*/
七.java高级技术(反射,泛型,注解)
1.反射
1).理解Class类
a.什么是RTTI:
运行时类型检查,即Run-time Type Identification。运行时类型信息使得你可以在程序运行时发现和使用类型信息。
类的装载:
Java的程序在其开始运行之前,并不会被完全加载。所有的类都是在其第一次被使用时,动态的加载到内存当中。
所谓的第一次被使用时加载。也就是指当程序创建第一个对类的静态成员的引用的时候,就会被加载。
对一个类进行装载的工作过程很简单:类装载器(ClassLoader)会首先检查类是否已经被加载过;
如果检查到之前该类型还没有被进行过装载,则根据类名查找对应的.class文件将其装载进内存当中。
“class of classes” 类的类:
我们知道一个Java程序实际上就是由一个个的类(即class)组合而成的,但这里的此”Class”并非 彼“class”。
更形象的比喻来说,”Class对象”又被称作”class of classes“,即”类的类“。
之所以我们进行这样的比喻,实际上正是因为每一个类都会有一个”Class对象”;
每当我们编写一个新类,就会产生一个新的”Class对象”(被保存在同名的.class文件)。
事实上,“Class对象”的作用 就是用来创建对应类型的所有“常规”对象的。
(所以我们可以把这个对象看做是“雕版”,我们程序中创建使用的对象即印刷出的“百元大钞”)
更加细致的来说,也就是当类被类装载器装载进内存之后,就会有一个对应的”Class”类型对象进入内存。
被装载进的这个“Class对象”保存该类的所有自身信息,而JVM也正是通过这个对象来进行RTTI(程序运行时类型检查)工作的。
2).Class对象
每个类都会产生一个对应的Class对象,也就是保存在.class文件。所有类都是在对其第一次使用时,动态加载到JVM的,当程序创建一个对类的静态成员的引用时,就会加载这个类。
Class对象仅在需要的时候才会加载,static初始化是在类加载时进行的。
public class TestMain {
public static void main(String[] args) {
System.out.println(XYZ.name);
}
static class XYZ {
public static String name = "luoxn28";
static {
System.out.println("xyz静态块");
}
public XYZ() {
System.out.println("xyz构造了");
}
}
}
Output:
xyz静态块
luoxn28
类加载器首先会检查这个类的Class对象是否已被加载过,如果尚未加载,默认的类加载器就会根据类名查找对应的.class文件。
想在运行时使用类型信息,必须获取对象(比如类Base对象)的Class对象的引用,
使用功能Class.forName(“Base”)可以实现该目的,或者使用base.class。
注意,有一点很有趣,使用功能”.class”来创建Class对象的引用时,不会自动初始化该Class对象,
使用forName()会自动初始化该Class对象。
为了使用类而做的准备工作一般有以下3个步骤:
加载:由类加载器完成,找到对应的字节码,创建一个Class对象
链接:验证类中的字节码,为静态域分配空间
初始化:如果该类有超类,则对其初始化,执行静态初始化器和静态初始化块
public class TestBase {
static int num = 1;
static {
System.out.println("Base " + num);
}
}
public class TestMain {
public static void main(String[] args) {
// 不会初始化静态块
Class clazz1 = TestBase.class;
System.out.println("------");
// 会初始化
try {
Class clazz2 = Class.forName("com.kunzhuo.xuechelang.test.TestBase");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
Output
------
Base 1
3).类型转换前先做检查
a.instanceof关键字
instanceof是Java中的二元运算符,左边是对象,右边是类;当对象是右边类或子类所创建对象时,返回true;否则,返回false。
这里说明下:
类的实例包含本身的实例,以及所有直接或间接子类的实例
instanceof左边显式声明的类型与右边操作元必须是同种类或存在继承关系,也就是说需要位于同一个继承树,否则会编译错误
null用instanceof跟任何类型比较时都是false
向上转型
public class Student extends Person{
public static void main(String[] args) {
if ("a" instanceof String) {
//所有的字符串都是String的实例
System.out.println("字符串是Stringde实例");
}
//只是声明了对象并没有创建,所以instanceof判断是false
Student s1 = null;
Student s2 = null;
if (s1 instanceof Student) {
System.out.println("s1是Student的实例");
}
if (s2 instanceof Student) {
System.out.println("s2是Student的实例");
}
//创建了对象实例,判断为true
s1 = new Student();
s2 = new Student();
if (s1 instanceof Student) {
System.out.println("s1是Student的实例");
}
if (s2 instanceof Student) {
System.out.println("s2是Student的实例");
}
/*任何类的父类都是Object类,可以这样理解,我们在创建子类对象的时候,
调用子类的构造方法时会默认调用父类无参的构造方法,其实是会创建父类的对象的,,有继承关系的可以判断出为true*/
if (s1 instanceof Object) {
System.out.println("s1是Object的实例");
}
Object obj = new Student();
if (obj instanceof Student) {
System.out.println("obj是Student的实例");
}
Student s3 = new Student();
if (s3 instanceof Person) {
System.out.println("s3是Student的父类Person的实例");
}
}
}
class Person{}
b.编译器将检查类型向下转型是否合法,如果不合法将抛出异常。向下转换类型前,可以使用instanceof判断。
public class TestBase {}
public class TestDriver extends TestBase{}
public class TestMain {
public static void main(String[] args) {
TestBase base = new TestDriver();
if (base instanceof TestDriver) {
// 这里可以向下转换了
System.out.println("ok");
} else {
System.out.println("not ok");
}
}
}
4).反射(Field关键字):运行时类信息
Class类与java.lang.reflect类库一起对反射进行了支持,该类库包含Field、Method和Constructor类,这些类的对象由JVM在启动时创建,用以表示未知类里对应的成员。
这样的话就可以使用Contructor创建新的对象,用get()和set()方法获取和修改类中与Field对象关联的字段,用invoke()方法调用与Method对象关联的方法。
另外,还可以调用getFields()、getMethods()和getConstructors()等许多便利的方法,以返回表示字段、方法、以及构造器对象的数组,这样,对象信息可以在运行时被完全确定下来,而在编译时不需要知道关于类的任何事情。
对于RTTI和反射之间的真正区别只在于:
RTTI,编译器在编译时打开和检查.class文件
反射,运行时打开和检查.class文件
如何获取Field类对象
一共有4种方法:
Class.getFields(): 获取类中public类型的属性,返回一个包含某些?Field 对象的数组,该数组包含此 Class 对象所表示的类或接口的所有可访问公共字段
getDeclaredFields(): 获取类中所有的属性(public、protected、default、private),但不包括继承的属性,返回 Field 对象的一个数组
getField(String name): 获取类特定的方法,name参数指定了属性的名称
getDeclaredField(String name): 获取类特定的方法,name参数指定了属性的名称
PropertyDescriptor类:(属性描述器)
PropertyDescriptor类表示JavaBean类通过存储器导出一个属性。主要方法:
1. getPropertyType(),获得属性的Class对象;
2. getReadMethod(),获得用于读取属性值的方法;
3. getWriteMethod(),获得用于写入属性值的方法;
4. hashCode(),获取对象的哈希值;
5. setReadMethod(Method readMethod),设置用于读取属性值的方法;
6. setWriteMethod(Method writeMethod),设置用于写入属性值的方法。
Demo:
public class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public static void main(String[] args) throws IntrospectionException {
Person person = new Person("luoxn28", 23);
Class clazz = person.getClass();
Field[] fields = clazz.getDeclaredFields();//获取类中所有的属性(public、protected、default、private),但不包括继承的属性,返回 Field 对象的一个数组
for (Field field : fields) {
String key = field.getName();// 获取属性的名字
PropertyDescriptor descriptor = new PropertyDescriptor(key, clazz);
Method method = descriptor.getReadMethod();
Object value = null;
try {
value = method.invoke(person);
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(key + ":" + value);
}
}
}
以上通过getReadMethod()方法调用类的get函数,可以通过getWriteMethod()方法来调用类的set方法。通常来说,我们不需要使用反射工具,但是它们在创建动态代码会更有用,反射在Java中用来支持其他特性的,例如对象的序列化和JavaBean等。
5).动态代理
代理模式是为了提供额外或不同的操作,而插入的用来替代”实际”对象的对象,这些操作涉及到与”实际”对象的通信,因此代理通常充当中间人角色。
Java的动态代理比代理的思想更前进了一步,它可以动态地创建并代理并动态地处理对所代理方法的调用。在动态代理上所做的所有调用都会被重定向到单一的调用处理器上,它的工作是揭示调用的类型并确定相应的策略。
在java的动态代理机制中,有两个重要的类或接口,一个是 InvocationHandler(Interface)、另一个则是 Proxy(Class),这一个类和接口是实现我们动态代理所必须用到的。
InvocationHandler:
InvocationHandler is the interface implemented by the invocation handler of a proxy instance.
Each proxy instance has an associated invocation handler. When a method is invoked on a proxy instance, the method invocation is encoded and dispatched to the invoke method of its invocation handler.
每一个动态代理类都必须要实现InvocationHandler这个接口,并且每个代理类的实例都关联到了一个handler,当我们通过代理对象调用一个方法的时候,这个方法的调用就会被转发为由InvocationHandler这个接口的 invoke 方法来进行调用。
我们来看看InvocationHandler这个接口的唯一一个方法 invoke 方法:
Object invoke(Object proxy, Method method, Object[] args) throws Throwable
我们看到这个方法一共接受三个参数,那么这三个参数分别代表什么呢?
Object invoke(Object proxy, Method method, Object[] args) throws Throwable
proxy: 指代我们所代理的那个真实对象
method: 指代的是我们所要调用真实对象的某个方法的Method对象
args: 指代的是调用真实对象某个方法时接受的参数
Proxy.newProxyInstance(ClassLoader loader,Class[] interfaces,InvocationHandler h) throws IllegalArgumentException;
loader: 一个ClassLoader对象,定义了由哪个ClassLoader对象来对生成的代理对象进行加载
interfaces: 一个Interface对象的数组,表示的是我将要给我需要代理的对象提供一组什么接口,如果我提供了一组接口给它,那么这个代理对象就宣称实现了该接口(多态),这样我就能调用这组接口中的方法了
h: 一个InvocationHandler对象,表示的是当我这个动态代理对象在调用方法的时候,会关联到哪一个InvocationHandler对象上
Demo:
接口和实现
public interface Interface {
void doSomething();
void somethingElse(String arg);
}
class RealObject implements Interface {
public void doSomething() {
System.out.println("doSomething.");
}
public void somethingElse(String arg) {
System.out.println("somethingElse " + arg);
}
}
//动态代理对象处理器
public class DynamicProxyHandler implements InvocationHandler {
private Object proxyed;
public DynamicProxyHandler(Object proxyed) {
this.proxyed = proxyed;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 在代理真实对象前我们可以添加一些自己的操作
System.out.println("before rent house");
System.out.println("Method:" + method);
// 当代理对象调用真实对象的方法时,其会自动的跳转到代理对象关联的handler对象的invoke方法来进行调用
method.invoke(proxyed, args);
// 在代理真实对象后我们也可以添加一些自己的操作
System.out.println("after rent house");
return null;
}
}
//main方法
public class TestMain {
public static void main(String[] args){
// 我们要代理的真实对象
RealObject realSubject = new RealObject();
// 我们要代理哪个真实对象,就将该对象传进去,最后是通过该真实对象来调用其方法的
InvocationHandler handler = new DynamicProxyHandler(realSubject);
/*
* 通过Proxy的newProxyInstance方法来创建我们的代理对象,我们来看看其三个参数
* 第一个参数 handler.getClass().getClassLoader() ,我们这里使用handler这个类的ClassLoader对象来加载我们的代理对象
* 第二个参数realSubject.getClass().getInterfaces(),我们这里为代理对象提供的接口是真实对象所实行的接口,表示我要代理的是该真实对象,这样我就能调用这组接口中的方法了
* 第三个参数handler, 我们这里将这个代理对象关联到了上方的 InvocationHandler 这个对象上
*/
Interface subject = (Interface)Proxy.newProxyInstance(handler.getClass().getClassLoader(), realSubject
.getClass().getInterfaces(), handler);
System.out.println(subject.getClass().getName());
subject.doSomething();
subject.somethingElse("luoxn28");
}
}
Output:
com.sun.proxy.$Proxy0
before rent house
Method:public abstract void test.Interface.doSomething()
doSomething.
after rent house
before rent house
Method:public abstract void test.Interface.somethingElse(java.lang.String)
somethingElse luoxn28
after rent house
我们首先来看看 com.sun.proxy.$Proxy0 这东西,我们看到,这个东西是由 System.out.println(subject.getClass().getName()); 这条语句打印出来的,那么为什么我们返回的这个代理对象的类名是这样的呢?
Interface subject = (Interface)Proxy.newProxyInstance(handler.getClass().getClassLoader(), realSubject
.getClass().getInterfaces(), handler);
可能我以为返回的这个代理对象会是Interface类型的对象,或者是InvocationHandler的对象,结果却不是,首先我们解释一下为什么我们这里可以将其转化为Interface类型的对象?
原因就是在newProxyInstance这个方法的第二个参数上,我们给这个代理对象提供了一组什么接口,那么我这个代理对象就会实现了这组接口,这个时候我们当然可以将这个代理对象强制类型转化为这组接口中的任意一个,因为这里的接口是Interface类型,所以就可以将其转化为Interface类型了。
同时我们一定要记住,通过 Proxy.newProxyInstance 创建的代理对象是在jvm运行时动态生成的一个对象,它并不是我们的InvocationHandler类型,也不是我们定义的那组接口的类型,而是在运行是动态生成的一个对象,并且命名方式都是这样的形式,以$开头,proxy为中,最后一个数字表示对象的标号。
接着我们来看看这两句
subject.doSomething();
subject.somethingElse("luoxn28");
这里是通过代理对象来调用实现的那种接口中的方法,这个时候程序就会跳转到由这个代理对象关联到的 handler 中的invoke方法去执行,
而我们的这个 handler 对象又接受了一个 RealObject类型的参数,表示我要代理的就是这个真实对象(new DynamicProxyHandler(realSubject)),
所以此时就会调用 handler 中的invoke方法去执行:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 在代理真实对象前我们可以添加一些自己的操作
System.out.println("before rent house");
System.out.println("Method:" + method);
// 当代理对象调用真实对象的方法时,其会自动的跳转到代理对象关联的handler对象的invoke方法来进行调用
method.invoke(proxyed, args);
// 在代理真实对象后我们也可以添加一些自己的操作
System.out.println("after rent house");
return null;
}
我们看到,在真正通过代理对象来调用真实对象的方法的时候,我们可以在该方法前后添加自己的一些操作,同时我们看到我们的这个 method 对象是这样的:
Method:public abstract void test.Interface.doSomething()
Method:public abstract void test.Interface.somethingElse(java.lang.String)
正好就是我们的Interface接口中的两个方法,这也就证明了当我通过代理对象来调用方法的时候,起实际就是委托由其关联到的 handler 对象的invoke方法中来调用,并不是自己来真实调用,而是通过代理的方式来调用的。
这就是我们的java动态代理机制
2.泛型
1).泛型定义:泛型即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?
顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),
然后在使用/调用时传入具体的类型(类型实参)。
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,
操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
特性:泛型只在编译阶段有效
2).泛型类、泛型接口、泛型方法
a.泛型类
泛型类型用于类的定义中,被称为泛型类。通过泛型可以完成对一组类的操作对外开放相同的接口。最典型的就是各种容器类,如:List、Set、Map。
泛型类的最基本写法(这么看可能会有点晕,会在下面的例子中详解):
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic{
//key这个成员变量的类型为T,T的类型由外部指定
private T key;
public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定
this.key = key;
}
public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定
return key;
}
}
public class Main {
public static void main(String[] args) {
//泛型的类型参数只能是类类型(包括自定义类),不能是简单类型
//传入的实参类型需与泛型的类型参数类型相同,即为Integer.
Generic genericInteger = new Generic(123456);
//传入的实参类型需与泛型的类型参数类型相同,即为String.
Generic genericString = new Generic("key_vlaue");
System.out.println("泛型测试 "+"key is " + genericInteger.getKey());
System.out.println("泛型测试 "+"key is " + genericString.getKey());
}
}
Output
泛型测试 key is 123456
泛型测试 key is key_vlaue
定义的泛型类,就一定要传入泛型类型实参么?并不是这样,在使用泛型的时候如果传入泛型实参,则会根据传入的泛型实参做相应的限制,此时泛型才会起到本应起到的限制作用。
如果不传入泛型类型实参的话,在泛型类中使用泛型的方法或成员变量定义的类型可以为任何的类型。
public class Main {
@SuppressWarnings({ "unchecked", "rawtypes" })
public static void main(String[] args) {
//泛型的类型参数只能是类类型(包括自定义类),不能是简单类型
Generic generic = new Generic("111111");
Generic generic1 = new Generic(4444);
Generic generic2 = new Generic(55.55);
Generic generic3 = new Generic(false);
System.out.println("泛型测试 "+"key is " + generic.getKey());
System.out.println("泛型测试 "+"key is " + generic1.getKey());
System.out.println("泛型测试 "+"key is " + generic2.getKey());
System.out.println("泛型测试 "+"key is " + generic3.getKey());
}
}
Output
泛型测试 key is 111111
泛型测试 key is 4444
泛型测试 key is 55.55
泛型测试 key is false
注意:
泛型的类型参数只能是类类型,不能是简单类型。
不能对确切的泛型类型使用instanceof操作。如下面的操作是非法的,编译时会出错。
if(ex_num instanceof Generic){ }
b.泛型接口
泛型接口与泛型类的定义及使用基本相同。泛型接口常被用在各种类的生产器中,可以看一个例子:
//定义一个泛型接口
public interface Generator {
public T next();
}
当实现泛型接口的类,未传入泛型实参时:
/**
* 未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中
* 即:class FruitGenerator implements Generator{
* 如果不声明泛型,如:class FruitGenerator implements Generator,编译器会报错:"Unknown class"
*/
class FruitGenerator implements Generator{
@Override
public T next() {
return null;
}
}
/**
* 传入泛型实参时:
* 定义一个生产器实现这个接口,虽然我们只创建了一个泛型接口Generator
* 但是我们可以为T传入无数个实参,形成无数种类型的Generator接口。
* 在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型
* 即:Generator,public T next();中的的T都要替换成传入的String类型。
*/
public class FruitGeneratorImp implements Generator{
String[] str = new String[]{"woc", "wori", "nimab"};
@Override
public String next() {
Random rand = new Random();
return str[rand.nextInt()];
}
}
c.泛型通配符(?)
我们知道Ingeter是Number的一个子类,同时在特性章节中我们也验证过Generic与Generic实际上是相同的一种基本类型。那么问题来了,在使用Generic作为形参的方法中,能否使用Generic的实例传入呢?在逻辑上类似于Generic和Generic是否可以看成具有父子关系的泛型类型呢?
为了弄清楚这个问题,我们使用Generic这个泛型类继续看下面的例子:
public class Main {
public static void showKeyValue(Generic obj){
System.out.println("泛型测试 "+"key value is " + obj.getKey());
}
public static void main(String[] args) {
Generic gInteger = new Generic(123);
Generic gNumber = new Generic(456);
showKeyValue(gNumber);
//showKeyValue(Generic obj)
// showKeyValue这个方法编译器会为我们报错:Generic
// cannot be applied to Generic
showKeyValue(gInteger);
}
}
类型通配符一般是使用?代替具体的类型实参,注意了,此处’?’是类型实参,而不是类型形参 。
重要说三遍!此处’?’是类型实参,而不是类型形参 ! 此处’?’是类型实参,而不是类型形参 !
再直白点的意思就是,此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。
可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
d.泛型方法
泛型方法使得该方法能独立于类而产生变化。我们可以写一个泛型方法,该方法在调用时可以接收不同类型的参数。根据传递给泛型方法的参数类型,编译器适当地处理每一个方法调用。
无论何时,只要你能做到,你就应该尽量使用泛型方法。也就是说,如果使用泛型方法可以取代将整个类泛型化,那么就应该只使用泛型方法,因为它可以使事情更清楚明白。另外,对于一个static的方法而言,无法访问泛型类的类型参数。所以,如果static方法需要使用泛型能力,就必须使其成为泛型方法。
下面是定义泛型方法的规则:?
(1).所有泛型方法声明都有一个类型参数声明部分(由尖括号分隔),该类型参数声明部分在方法返回类型之前(在下面例子中的)。
(2).每一个类型参数声明部分包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。
(3).类型参数能被用来声明返回值类型,并且能作为泛型方法得到的实际参数类型的占位符。
(4).泛型方法体的声明和其他方法一样。注意类型参数只能代表引用型类型,不能是原始类型(像int,double,char的等)。
下面举一些泛型方法的示例:
/**
* public 与 返回值中间非常重要,可以理解为声明此方法为泛型方法。
* 只有声明了等的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。
* 表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。
* 与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型。
*/
public class GenericMethods {
public void genericMethod1(T t){
System.out.println(t.getClass().getName());
}
public T genericMethod2( Class tClass ) throws InstantiationException ,
IllegalAccessException {
T t = tClass.newInstance();
return t;
}
public static void genericMethod3( T[] inputArray ) {
// 输出数组元素
for ( T element : inputArray ){
System.out.printf( "%s ", element );
}
}
}
说明一下,定义泛型方法时,必须在返回值前边加一个,来声明这是一个泛型方法,持有一个泛型T,然后才可以用泛型T作为方法的返回值或参数类型等。
泛型类是在实例化类的时候指明泛型的具体类型,而泛型方法是在调用方法的时候指明泛型的具体类型 。
泛型方法可以在任何地方和任何场景中使用,但是有一种情况是非常特殊的,当泛型方法出现在泛型类中时,我们再通过一个例子看一下:
/**
* 泛型类
* @author Administrator
*
* @param
*/
public class GenericClassDemo {
/**
* 这个不是泛型方法,只是使用了泛型类中已声明的T
*/
public void show1(T t){
System.out.println(t.toString());
}
/**
* 泛型方法,使用泛型E,这种泛型E可以为任意类型。可以类型与T相同,也可以不同。
* 由于下面的泛型方法在声明的时候声明了泛型,因此即使在泛型类中并未声明泛型,
* 编译器也能够正确识别泛型方法中识别的泛型。
*/
public void show2(E e){
System.out.println(e.toString());
}
/**
* 在泛型类中声明了一个泛型方法,使用泛型T,注意这个T是一种全新的类型;
* 可以与泛型类中声明的T不是同一种类型。
*/
public void show3(T t){
System.out.println(t.toString());
}
}
泛型方法和可变参数
public class Main {
public void printArgs( T... args ){
for(T t : args){
System.out.println(t + " ");
}
}
public static List toList(T... args){
List result = new ArrayList();
for(T item:args)
result.add(item);
return result;
}
public static void main(String[] args) {
Main gmt = new Main();
gmt.printArgs("A","B"); // A B
List ls = Main.toList("A", "vcwasd");
System.out.println(ls); // [A]
ls = Main.toList("A","B","C");
System.out.println(ls); // [A,B,C]
}
}
静态方法使用泛型
静态方法无法访问类上定义的泛型,如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。即:如果静态方法要使用泛型的话,必须将静态方法也定义成泛型方法 。
/**
* 如果在类中定义使用泛型的静态方法,需要添加额外的泛型声明
* 即使静态方法不可以使用泛型类中已经声明过的泛型(需将这个方法定义成泛型方法)
* 如:public static void genericMethod(T t){..},此时编译器会提示错误信息:
* "StaticGenerator cannot be refrenced from static context"
*/
public static void genericMethod(T t) {
// ...
System.out.println(t.toString());
}
3.注解
1).注解基本概念及java内置注解
注解(元数据)为我们在代码中添加信息提供一种形式化的方法,我们可以在某个时刻非常方便的使用这些数据。
将的通俗一点,就是为这个方法增加的说明或功能。例如:@Overvide这个注解就用来说明这个方式重写父类的。
Java目前内置了三种注解@Override、@Deprecated、@SuppressWarnnings
@Override:用于标识方法,标识该方法属于重写父类的方法
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
@Deprecated:用于标识方法或类,标识该类或方法已过时,建议不要使用
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(value={CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPE})
public @interface Deprecated {
}
@SuppressWarnnings:用于有选择的关闭编译器对类、方法、成员变量、变量初始化的警告
@Target({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE})
@Retention(RetentionPolicy.SOURCE)
public @interface SuppressWarnings {
String[] value();
2).元注解
Java提供了四种元注解,即修饰注解的注解。观察上面源码可以发现三种,即:@Target、@Retention、@Document、@Inherited
a.@Target
表示该注解用于什么地方,可能的值在枚举类 ElemenetType 中,包括:
ElemenetType.CONSTRUCTOR 构造器声明
ElemenetType.FIELD 域声明(包括 enum 实例)
ElemenetType.LOCAL_VARIABLE 局部变量声明
ElemenetType.ANNOTATION_TYPE 作用于注解量声明
ElemenetType.METHOD 方法声明
ElemenetType.PACKAGE 包声明
ElemenetType.PARAMETER 参数声明
ElemenetType.TYPE 类,接口(包括注解类型)或enum声明
b.@Retention
定义注解的保留策略
@Retention(RetentionPolicy.SOURCE) //注解仅存在于源码中,在class字节码文件中不包含
@Retention(RetentionPolicy.CLASS) // 默认的保留策略,注解会在class字节码文件中存在,但运行时无法获得,
@Retention(RetentionPolicy.RUNTIME) // 注解会在class字节码文件中存在,在运行时可以通过反射获取到
首先要明确生命周期长度 SOURCE < CLASS < RUNTIME ,所以前者能作用的地方后者一定也能作用。
一般如果需要在运行时去动态获取注解信息,那只能用 RUNTIME 注解;
如果要在编译时进行一些预处理操作,比如生成一些辅助代码(如 ButterKnife),就用 CLASS注解;
如果只是做一些检查性的操作,比如 @Override 和 @SuppressWarnings,则可选用 SOURCE 注解。
c.@Document:说明该注解将被包含在javadoc中
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.ANNOTATION_TYPE)
public @interface Documented {
}
即拥有这个注解的元素可以被javadoc此类的工具文档化。它代表着此注解会被javadoc工具提取成文档。在doc文档中的内容会因为此注解的信息内容不同而不同。相当与@return,@param 等。
d.@Inherited:说明子类可以继承父类中的该注解
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.ANNOTATION_TYPE)
public @interface Inherited {
}
Demo:
//适用类、接口(包括注解类型)或枚举
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface ClassInfo {
String value();
}
//适用field属性,也包括enum常量
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface FieldInfo {
int[] value();
}
//适用方法
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MethodInfo {
String name() default "long";
String data();
int age() default 28;
}
@ClassInfo("Test Class")
public class TestRuntimeAnnotation {
@FieldInfo(value = {1,2})
public String filedInfo = "FiledInfo";
@FieldInfo(value = {100000})
public int i = 100;
@MethodInfo(name = "BlueBird", data = "Big", age = 418523)
public static String getMethodInfo(){
return TestRuntimeAnnotation.class.getSimpleName();
}
}
@ClassInfo("Test Class")
public class TestRuntimeAnnotation {
@FieldInfo(value = {1,2})
public String filedInfo = "FiledInfo";
@FieldInfo(value = {100000})
public int i = 100;
@MethodInfo(name = "BlueBird", data = "Big", age = 418523)
public static String getMethodInfo(){
return TestRuntimeAnnotation.class.getSimpleName();
}
}
public class Main {
public static void main(String[] args) {
_testRunTimeAnnotation();
}
//在代码中获取注解信息
private static void _testRunTimeAnnotation(){
StringBuffer sb = new StringBuffer();
Class cls = TestRuntimeAnnotation.class;
Constructor[] constructors = cls.getConstructors();
//获取指定类型的注解
//Class注解
sb.append("Class注解:").append("\n");
ClassInfo classInfo = cls.getAnnotation(ClassInfo.class);
if(classInfo != null){
sb.append(Modifier.toString(cls.getModifiers()))
.append(" ")
.append(cls.getSimpleName())
.append("\n");
sb.append("注解值").append(" ")
.append(classInfo.value().toString())
.append("\n\n");
}
//Field注解
sb.append("Field注解: ").append("\n");
Field[] fields = cls.getDeclaredFields();
for(Field field : fields){
FieldInfo fieldInfo = field.getAnnotation(FieldInfo.class);
if(fieldInfo != null){
sb.append(Modifier.toString(field.getModifiers()))
.append(" ")
.append(field.getType().getSimpleName())
.append(" ")
.append(field.getName()).append("\n");
sb.append("注解值: ")
.append(Arrays.toString(fieldInfo.value()))
.append("\n\n");
}
}
//method注解
sb.append("Method注解:").append("\n");
Method[] methods = cls.getDeclaredMethods();
for(Method method : methods){
MethodInfo methodInfo = method.getAnnotation(MethodInfo.class);
if(methodInfo != null){
sb.append(Modifier.toString(method.getModifiers()))
.append(" ")
.append(method.getReturnType().getSimpleName())
.append(" ")
.append(method.getName())
.append("\n");
sb.append("注解值: ").append("\n");
sb.append("name: ").append(methodInfo.name()).append("\n");
sb.append("data: ").append(methodInfo.data()).append("\n");
sb.append("age: ").append(methodInfo.age()).append("\n");
}
}
System.out.println(sb.toString());
}
}
Output
Class注解:
public TestRuntimeAnnotation
注解值 Test Class
Field注解:
public String filedInfo
注解值: [1, 2]
public int i
注解值: [100000]
Method注解:
public static String getMethodInfo
注解值:
name: BlueBird
data: Big
age: 418523
3).自定义注解
语法: public @interface xxx{}
使用:@xxx
注解只有成员变量,没有方法
Demo:
public @interface DiyInfo {
public String value();
}
class TestAnnotation{
@DiyInfo("fcsdad")
public void getMsg(){
}
}
就此,如有错误,望指正!