Tencent ML-Images: A Large-Scale Multi-Label Image Database for Visual Representation Learning
摘要:
现有的视觉表达学习任务中,深度神经网络通常由单个标签的图像训练而来,例如ImageNet。然而单个标签很难描述样本中所有的重要内容,有些有用的视觉信息在训练时可能会浪费掉了。本文中,我们期望利用多标签的图像训练CNNs,从而增强训练出来的CNN模型的表达质量。为了达到目的,我们建立一个包含18M图像,11K类别的大规模多标签样本集,称为Tencent ML-Images。我们高效的利用大规模分布式深度学习框架,例如TFplus,在Tencent ML-Images数据集上训练ResNet-101模型,花了90小时迭代了60epoches。通过ImageNet和Caltech-256上的单标签图像分类、PASCAL VOC 2007上的目标检测、PASCAL VOC 2012上的语义分割三个转移学习任务,验证了腾讯ML-Images检查点的良好视觉表示质量。腾讯ML-Images数据库,ResNet-101的checkpoints,以及所有的训练代码已经在https://github.com/Tencent/tencent-ml-images开源。预期它将促进研究和工业界的未来其他任务。
1、Introduction
本文介绍了新建多标签数据集Tencent ML-Images大规模识别表示学习工作。我们从讨论接下来两个问题开始。
- 为什么我们需要大规模图像数据集?深度学习经历了一个较长的低谷期,直到2012年,AlexNet【1】在ILSVRC2012比赛的单标签图像分类任重中取得了令人吃惊的结果。深度神经网络的潜力通过大规模图像数据集,例如ImageNet-ILSVRC2012【2】释放出来。除此之外,许多计算机视觉任务,例如目标检测、语义分割等获取训练数据成本都很高。由于训练数据的不足,我们需要在大规模数据集上训练的拥有好的视觉表达能力的checkpoint作为预训练模型,用于其他任务的初始化(例如用于单标签图像分类的ImageNet-ILSVRC2012)。
- 为什么我们需要多标签图像数据集?由于在大多数自然图片中都会有多个目标,单个标注可能会漏掉一些有用的信息,并且误导CNN网络的训练。例如两张视觉相似的包含牛和草的图片可能分别被标注为草跟牛。合理的方式是告诉CNN模型这两张图片同时包含牛和草。
上述的讨论解释了为什么我们需要大规模多标签图像数据集用来进行深度学习视觉表达的学习。然而,与标注单个标签相比一张图片标注多个标签要耗时的多,并且很难控制标注的质量。据我们所知,最大的开源多标签图像数据集是Open Images【3】,包含9百万样本与6千类,包含20%的标签噪声。然而,仅仅是在Open Images上面训练的多标签输出的模型,它例如单标签分类对于其他视觉任务的通用性并没有研究【4】。当前,文献【5】在JFT-300M(一个有3亿样本的多标签数据集)上训练的预训练模型在ImageNet数据集上进行微调,获得ImageNet验证集上top-1准确率79.2%。与之相比,在ImageNet-ILSVRC2012数据集上重头开始训练的模型得到了77.5%的top-1准确率。然而,JFT-300M花了2个月时间训练了4epoches,JFT-300M训练集大小是ImageNet-ILSVRC2012的250倍。此外,JTF-300M与它的checkpiont并没有开源。
本文中,我们建立了一个新的大规模多标签数据集,称为Tencent ML-Images。与以往其他数据集从Google搜索或者Flickr收集新数据不同,我们从现有数据集收集样板,例如OpenImages【3】与ImageNet【2】。特别是,我们将他们的词典合并成一个统一的词典,并移除的少见或者冗余的类别和与之对应的样本。我们进一步参照WordNet【6】构建了统一词典的语义层级。我们还派生了类别之间的类共现,然后根据Open Images和ImageNet的原始注释,将其与语义层次结构一起使用,以增强注释。为了验证构建的Tencent ML-Images数据集质量,我们进行深度神经网络的大规模视觉表达学习,我们选择了流行的ResNet-101 V2结构。利用多标签的样本集的大规模学习有两个主要的特点:严重的类间样本不均衡与冗长的训练进程。为了减轻类间不均衡带来的负面影响,我们设计了一种先进的损失函数,同时考虑交叉熵权重、训练过程中的自适应损失权重与每个minibatch中负样本的下采样。为了加速训练进程,我们使用大规模分布式深度学习架构,例如,TFplus,使用MPI与NCCL【7】。所以,整个训练进程花费了90个小时,进行了60个epoches,使用了128块GPUs。单块GPU的效率是【5】中报告的5倍。此外,为了验证ResNet-101在Tencent Images数据集预训练模型的视觉表达质量,我们进行了三种其他类型视觉任务的迁移学习,包括单标签分类,目标检测与语义分割。我们将结果与JFT-300M与ImageNet-ILSVRC2012预训练模型的迁移学习效果分布进行对比。TencntML-Images数据集训练模型更好的迁移学习效果证明了TencentML-Images数据集与预训练模型的高质量。
本文的主要贡献包括如下四个部分:
- 我们构建了一个包含1800万图片与11000个类别的多标签样本集,称为Tencent ML-Images,是目前最大的多标签开源数据集。
- 我们在TencentML-Images数据集上利用大规模分布式深度学习框架高效的训练了ResNet101模型。此外,我们设计了一种先进的损失函数,降低大规模多标签数据集中严重的类别不均衡带来的负作用。
- 我们展示了TencentML-Images与它的预训练模型的高质量,通过3个不同视觉任务的迁移学习表现。
- 我们开源了TencentML-Images数据集,预训练ResNet101模型与用于图像分类与特征提取的数据准备、预训练、微调所有相关代码,代码在https://github.com/Tencent/tencent-ml-images。希望可以促进其他视觉任务的研究与工业界的讨论。
本文的组织如下。第二章介绍相关文献的回顾。第三章介绍多标签数据集的构建,包括图像源、类词典、语义层次和标签扩展与统计。第四章展示了TencentML-Images在视觉表达学习的表现。对于单标签分类、目标检测与语义分割的迁移学习表现在第5章中展示,第6章进行总结。
2、相关工作
本章节,我们回顾视觉表达学习中用到的图像数据集。他们可以总体分为两类。一类是单标签图像数据集,每张样本都标注为唯一的标签。另外一类是多标签图像数据集,每张样本都标注了多个标签。
广泛应用的单标签数据集包括CIFAR-10【8】,Caltech-256【9】,MNIST【10】,ImageNet【2】,WebVision【11】,SUN【12】与Places【13】等。深度学习时代之前(2012年之前),大多数数据集都不是很大。CIFAR-10【8】包含6万张分10类的小尺寸自然图片。Caltech-256【9】包含30607张样本,256个目标类别。MNIST【10】包含70K手写数据样本,从0到9。深度学习时代开始(2012),ImageNet【2】是最流行的数据集。它的第一个用于ILSVRC2012的版本包含128K图像,1000个类别。现在扩展称为包含14M图片。许多深度学习模型(例如AlexNet【14】,VGG【15】,ResNet【16】)是在ImageNet上训练与验证来展示他们的表现,基于ImageNet预训练的checkpoints广泛应用在帮助其他视觉任务,例如图像标注,目标检测等。WebVision【11】包含2.4M样本,拥有与ImageNet相同的1000个类别。WebVision与ImageNet主要的不同是WebVision的标注噪声较多,而ImageNet的标注是较为精准的。然而,WebVision的作者通过实验证明,利用足够但是有噪声训练出的AlexNet模型可以获得与在ImageNet上训练的模型相当甚至更好的视觉表达。然而,SOTA的CNN模型,例如,ResNet并没有被评估。除了上述物体类别的数据集以外,还有两个流行的场景分类数据集,包括SUN与Places。SUN【12】包含108754张样本与397场景语义类别。Places【13】包含10M样本,包含434个场景语义类别。然而,场景类别与物体类别相比是较高的语义级别。在场景数据集下训练的视觉表达深度模型可能对于其它视觉任务例如目标检测或者识别不太合适。然而,如第一章提到的,一张样本的主要内容不能被一个标签良好的表达。在单标签样本上学习的视觉表达会浪费训练样本的有效信息,给深度模型带来困扰,因为两张视觉相似的样本可能会标注为两个不同的类别。
也有许多多标签图像数据集。在深度学习时代之前,大多数图像数据集用来评估多标签模型或者图像标注方法。常见的数据集包括:Corel 5k【17】(包括268类目标,4999张样本),IAPRTC-12【19】(包括291类,19627张样本),NUSWIDE【20】(包括27万样本,81类),MS COCO【21】(包括33万样本,80类)与PASCAL VOC 2007【22】(包括9963张样本,平均每张样本标注了2.47个标签)。然而,很少有用他们来训练视觉表达学习的深度模型。他们的规模不足以用来训练例如VGG或者ResNet模型这些流行的模型并且得到好的参数,因为图像数量甚至比深度模型的参数还少。此外,小规模的类别词典也不够有足够的区分度,训练对于其它视觉任务有足够通用性的模型。相反,也有一些大型的多标签数据集。例如,Open Images【3】包括9M样本,6000类。然而,Open Images的作者仅提供在此数据集行训练的有5K独立输出(对应5K类别)的ResNet-101模型。此模型对单标签图像分类的通用性并没有人研究过。JFT-300M是谷歌内部数据集,包含300M样本,包括18291个类别,平均每张样本1.25个标签。文献【5】在JFT-300M数据集上训练ResNet-101模型,将权重用于其他视觉任务,包括ImageNet上的单标签图像分类任务,MS-COCO上与PASCAL VOC2007的目标检测任务,PASCAL VOC 2012上的语义分割与MS-COCO上的姿势估计。特别是在JEF-300M上预训练的ResNet-101模型在ImageNet数据集上微调后,在ImageNet验证集上得到79.2%的Top-1准确率。相反,利用ImageNet数据集从头开始训练的ResNet101只有77.5%的top-1准确率。这样的改进展示了JFT-300M对于学习更通用的视觉表达相当有效。然而,值得注意的是JFT-300M是ImageNet规模的250倍。在拥有18291类的300M数据集上训练ResNet-101模型是相当耗时的。如【5】张报告的,他们花了两个月训练4个epoches,使用异步梯度下降法在50张K80卡与17台参数服务器。此外,JFT-300M与他的权重文件并没有开源。他们不能被研究人员用于帮助其他视觉任务。相反,我们建立的Tencent ML-Images是最大的开源多标签图像数据集,我们基于分布式训练框架的训练方法也更加高效。
3、The Tencent ML-Images Database
3.1 Image Source and Class Vocabulary
Tencent ML-Images的图像与类别字典来自ImageNet【2】与Open Images【3】。下面我们分别介绍训练集、验证集与此字典的构建。
URLs与词典。首先,我们从ImageNet-11k中提取图像的URLs。它时候mxnet收集的ImageNet数据集的一个子集。它本来包含11797630张训练样本,包括11221类。然而,11221类中的1989类对于视觉领域属于比较抽象的类别,例如时间、夏天。我么你任务标注的那么抽象的图像类别对视觉表达没有什么帮忙。因此,我们移除了抽象的类别以及他们响应的样本,共9232类,10322935张图片。此外,根据类别间的语义信息,我们在ImageNet整个数据集的基础上给字典增加了800个细粒度类别。例如,如果在以上9232类中包含狗这类,我们将哈士奇也加入到Tencent ML-Images数据集的词典,以及在ImageNet中对应的图像。结果是我们从ImageNet获得了10756941个URLs,包括10032个类别。我们随机抽取了50000个URLs作为验证集URLs,并且保证每个类别的URLs数量不超过5个。换句话说,我们利用每类的阈值过滤Open Images的所有图片。如果某一类恰好小于650张样本,我们从数据集中移除。我们还如上文所述移除所有视觉领域抽象的类别。此外,由于Open Images里面的一些类别与上述的10032类相似或者一致,我们想冗余的类别合并到统一的分类中。如果一幅图的所有标签都被移除了,那么我们将这张图片放弃。这种方式,导致剩余6902811张训练样本,与38739张验证样本,包括1134唯一的类别。最后,我们将从ImageNet与OpenImage中选择出来的URLs进行合并,构建Tencent ML-Images的URLs与字典,包括17609752训练样本与88739张验证样本的URLs。此外,我们从原始图片的URLs下载了这些样本。
语义分层。我们首先将ImageNet与Open Images里的类别映射到WordNet里面的WordID。根据WordID,我们在11166类的基础上构建语义分层。包括4个独立数,根节点分别是物体、时间、物理目标与气候现象。最长的语义路径从叶节点到到根节点的距离是16,平均长度是7.47。
3.2 Tag Augmentation of Images
注意到ImageNet-11K的每张样本都标注的单个的标签。我们希望利用语义分层与这些类别的共性来进行图像标签的扩展。首先,根据语义分层,所有原始的单标签页标注为相同样本的单个原始标签。第二,我们计算ImageNet-11k与OpenImages里类别的共性矩阵CO。特别指出的是,我们基于Open Images数据集训练了拥有1134个类别输出的ResNet-101模型。利用这个训练模型,我们预测来自ImageNet-11k数据集样本的类别。如果一张图片的一个类别的后验概率大于95%,我们将这个类别设置为本样本的正样本标签。因此,我们如下计算共性矩阵:对于来自OpenImage的类别j与来自ImageNet-11k的类别i,我们将ImageNet-11k中类别i的正样本表示为ni,其中哪些也属于类别j的样本表示为nij,那么CO(i,j)=ni,j/ni∈[0,1]。如果CO(i,j)>0.5,且类别i与j之间没有语义相关(无论正反在语义分层上面都没有i与j之间的连接),那么我们将i与j的类别作为强共性的类别对。因此,我们将来自ImageNet-11k的样本表示如下:如果一张样本原来表示为i,我们还将其表示为j。
3.3 Data Statistics
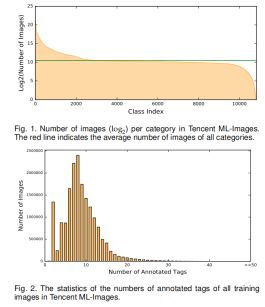
标注分布。每个类别的样本数量统计如图1所示。特别需要指出的是,类别最多的类包含1318058张样本,对应的类别时“目标,物理目标”;最小类别张数是0;平均张数是1447.2。不同类别间的分布是极度不均衡的。有些类别频繁出现,而其他的则很少出现。有10505个类别样本数大于100张,可以用来进行训练。类别间的不均衡可以见文献【23】。所有训练样本的标签数统计如图2。特别指出,所有训练样本标签的数量从1到91,平均数量是8。考虑到类别词典的大小(例如11K),所有样本标签的数量很小。换句话说,每张样本正标签比负标签要少得多。可以表达为单张样本正负标签的不均衡【23】。以上两种不均衡给模型训练带来了困难。如第四章介绍的,我们会在模型训练过程中考虑这种不均衡的情况。
噪声与漏标。标签噪声代表着错误的标签标注,而漏标【24】【25】【26】【27】【28】意味着样本里出现了这个类别却没有被标注出来。如【3】所示,OpenImages数据集里面大部分标签都是由机器标注的,只有少部分样本是人工标注。因此,这些噪声样本也被包含在Tencent ML-Images中。漏标意味着一张样本的正标签没有标注。大多数漏标来时ImageNet-11k,因为这些样本原来只标注了一个标签。如第3.2节中所述,我们使用类别相关性来扩充这些单标签样本。与Open Images里由机器自动产生的标签,我们的扩展相对保守。我们关注的是很难控制机器标注产生噪声的比例,我们相信噪声带来的负作用比漏标大得多。有些工作(例如【4】【5】)展示出从大量噪声标签样本中训练依然可以得到好的视觉表达。但是他们并没有研究噪声与漏标的取舍,因为这两种类型的标注都很难在大规模数据集中精确的统计。本文中,我们选择宁可漏标也不要错标的方式。
4、Visual Representation Learning On Tencent ML-Images
4.1Training ResNet-101 with Multi-label Outputs on Tencent ML-Images
4.1.1 Model and Loss Function
我们利用Tensorflow-1.6.0根据文献【29】中的模型结构,实现ResNet-101。由于我们的任务是多标签分类,ResNet-101的输出是m个独立的Sigmoid函数的激活函数,m是类别字典的大小。为了消除类间不均衡,我们提出了一种先进的加权交叉熵损失函数。为了表达清晰,我们以一张样本xi为前提对损失函数进行表示,如下:

这里![]() 表示每个类别j的后验概率,W是可训练的参数。
表示每个类别j的后验概率,W是可训练的参数。![]() 表示图像xi的真实标签。
表示图像xi的真实标签。
- 系数
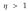 引入用来将正标签设置比负标签更大的权重,从而消除每个类别正负标签的不均衡。我们的实验中,指定系数为12。
引入用来将正标签设置比负标签更大的权重,从而消除每个类别正负标签的不均衡。我们的实验中,指定系数为12。 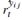 表示训练过程的自适应权重。组织如下:
表示训练过程的自适应权重。组织如下:
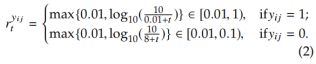
对于每个类别j,如果一个minibatch中的所有训练样本都是负样本,我们将状态记录为0;如果至少有一个训练样本是正样本,我们将状态记录为1。因此,我们的状态记录向量为(...,0,1,1,1,0,0,1,0,...)。这里t定义如下:如果当前minibatch的状态与上一个minibatch不同,例如01或者10,那么t=1;如果当前状态与上个状态相同,那么t=t+1。对于![]() ,如果对应类别j的参数在系列minibatchs中进行了更新,那么对应的损失函数的权重会被衰减。这样可以消除常见类别与罕见类别的样本不均衡。此外,由于正样本序列的minibatchs比负样本序列出现的更加频繁,我们设置
,如果对应类别j的参数在系列minibatchs中进行了更新,那么对应的损失函数的权重会被衰减。这样可以消除常见类别与罕见类别的样本不均衡。此外,由于正样本序列的minibatchs比负样本序列出现的更加频繁,我们设置![]() 来消除正负样本标签间的不均衡。
来消除正负样本标签间的不均衡。
4.1.2 Image Pre-processing
我们实验中图像预处理方法有一下6个系列步骤组成。
- 随机切割样本,保证切割预期是整张图的[0.05,1.0],宽高比例范围是[3/4,4/3]。
- 将切出来的样本resize到224*224。
- 以0.5的概率进行水平翻转。
- 在[-45,45]度范围内对图像进行翻转,概率为0.25。
- 以0.5的概率改变颜色。
- 将像素值从[0,1]rescale到[-1,1]。
4.1.3Training Algorithm and Hyper-parameters
我们利用带momentum参数的随机梯度下降法(SGD)与反向传播【30】来训练ResNet-101模型。我们的训练使用的超参数指定如下。一共有17609752张训练样本。Batchsize大小为4096,一个epoch包含4300steps。学习率使用带有warming-up策略的调整方式【31】。详细的说,在刚开始的8个epochs中,学习率为0.01,每个epoch增加1.297倍。在第九个epoch学习率为0.08。这个时候,每隔25个epochs学习率以0.1的系数下降。Momentum参数是0.9。最大的epoch是60。当更新BatchNorm的参数时,平均衰减系数为0.9,常数∈设置为0.001来避免变量值为0。参数的衰减系数为0.0001。
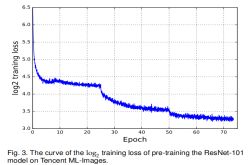
每个batch中,对于每个类别,大部分或者甚至所有训练样本都是负样本。对于类别i,如果当前batch中没有正样本,对应类别i的全连接层的参数以0.1的系数进行更新;如有第i类有正样本,我们会将负样本的数量降采样为正样本数量的5倍,然后在进行相应的正负样本参数更新。这样的参数设置可以使得每一类的参数都符合相似的分布,例如,负样本是正样本的5倍,尽管训练数据中绝对类间差还是存在的。这样可以在某些情况下消除类别分布不均匀产生的负面影响。此外,我们设置η为12,例如正样本的影响比负样本更高。这可以消除正负标签分布不均衡带来的负面影响。Log2损失值曲线如图3所示。
4.1.4Acceleration by Distributed Training
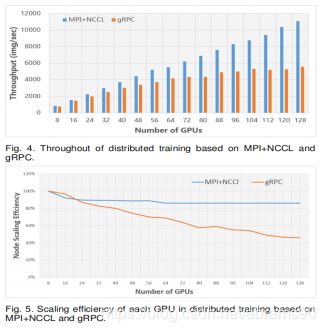
在18M样本上训练有11k输出的Resnet-101需要很大的算力。如果是用单机训练可能要花费几十天时间。本文中,所有的训练实验都是在大规模分布式的深度学习框架上进行的,例如TFplus,TFplus是在Tensorflow基础上通过歇息多机通信技术优化得到的。我们将原来的基于MPI的gRPC实现与NCCL库进行替换【7】。NCCL提供了高度优化的编程能力,例如all-gather、all-reduce、broadcast、reduce、reduce-scatter,特别是集成了带宽最优环全约简算法【32】,得到PCIe与NVIDIA GPU之间的高通信带宽。为了将规模从一块GPU扩展到多个节点过个GPUs,我们实现了几个APIS用于通信:1)在初始化阶段或从checkpoint恢复时,对所有gpu进行参数同步的广播操作;2)参数同步更新的分布式优化器warpper;3)数据分区、屏障等操作。由于MPI和NCCL都支持远程直接内存访问(RDMA),所以我们在一个支持40 GbE RDMA的网络上运行所有分布式培训作业。与原始的基于gRPC的分布式实现相比,我们在16个节点的集群上实现了大约2倍的速度,每个节点使用8个NVIDIA P40 gpu,如图4所示。具体来说,当使用128个gpu进行训练时,整个过程(MPI+NCCL的每秒处理图像数)高达11077,而gRPC的总处理图像数为5551。此外,基于MPI+NCCL的分布式训练在8个gpu到128个gpu之间的扩展效率为86%,而基于gRPC的仅为46%,如图5所示。
整个训练过程花费90个小时60个epochs,平均1.5小时/epochs。相对来说,如【5】所述,在JTF-300M数据加上的训练华为两个小时训练了4个epoch,基于50块NVIDIA K80 GPUs。特别指出,我们的训练进程华为218GPU小时(一个GPU运行218小时)来处理18M样本。我们所实现的每个GPU的书读是【5】中实现速度的5倍。
4.2Evaluations and Results
为了评估我们训练的多标签ResNet-101模型的表现,我们使用广泛应用的多标签实例级别的度量方式,包括识别级别的准确率,召回率与F1得分。由于每个类别的输出是后验概率,我们需要将连续的输出转换成二进制预测,从而计算上述度量结果。特别指出,对于样本i,我们将top-k个最大的后验概率作为正样本标签(例如1),其他类别作为负样本标签(例如0)。我们从而获得二进制预测向量 。那么评估的度量结果可以计算如下:
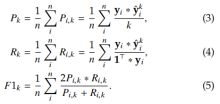
我们在表1中展示了top-5与top-10的预测结果。评估的值不是特别高。如3.1节中展示的那样,验证集只有训练集大小的1/200。而且,验证样本有许多标签都漏标了。因此,在小规模验证集上的得分不能充分的表达在Tencent ML-Images数据集上训练模型的视觉表达的能力。因此,他的能力可以通过其他视觉任务的迁移学习效果来评估,如下文所述。
5、Transfer Learning
5.1Transfer Learning to Single-Label Image Classification on ImageNet-ILSVRC2012
为了验证在Tencent ML-Images上的ResNet-101预训练模型的视觉表达能力,我们在打标签图像数据集上进行图像分类的迁移学习,例如ImageNet-ILSVRC2012。特别说明的是,我们使用在Tencent ML-Images数据集上训练的ResNet-101模型作为初始化权重,将输出层替换为1000个输出阶段,损失函数为softmax。我们在ImageNet-ILSVRC2012数据集上微调这个checkpoint。从这里开始,我们将ImageNet-ILSVRC2012简称为ImageNet。
5.1.1Fine-Tuning Approaches
学习率。注意到Tencent ML-Image数据集与ImageNet数据集有很大的不同。首先,视觉特征的分布于类别字典不同。其次,Tencent ML-Images标注了多标签,而ImageNet只标注了单标签。最后,Tencent ML-Images的标签噪声很多,ImageNet的标签较为干净。考虑到这些显著的差异,我们不能指望Tencent ML-Images训练出来的与训练模型在ImageNet不进行微调就可以取得很好的效果。标准的微调步骤对所有层都是用连续的学习率,这个学习率通常比预训练时的学习率小。这被称为基于学习率分层一致性的微调。然而,正如后续实验验证的那样,利用上述方法进行微调的方法比ImageNet的基准表现差。这展示出由于之前提到的三个主要区别Tencent ML-Images checkpoint中的有用信息并没有被充分利用。为了解决这个问题,我们利用分层自适应学习率来进行微调。特别说明的是,在我们对靠近顶层的层设置更好的学习率,而靠近底部的层设置更低的学习率。这么做的原因是顶层参数更加依赖训练样本与标签,而底部的参数更多的是表达低级的视觉特征。为了降低Tencent ML-Image与ImageNet两个数据集显著的不同带来的影响,顶层的参数相对于底层的参数,比checkpoint需要变化的更多。
图像大小。如【29】中展示的,训练与测试期间的图像大小对结果有显著的影响。此外,YOLO9000【33】提出在训练过程中调整图像的尺寸,这种方式被证明对检测表现是有好处的。此外,我们注意到【5】中的预训练、微调、评估的图像大小为299,而我们预训练的图像尺寸为224。为了与JFT-300M进行公平的对比,同时也为了探索图像尺寸对分类的影响,我们设计了三种不同图像尺寸的设置:1)保持224*224;2)早期的迭代使用224*224,后期的迭代使用299*299;3)图像尺寸保持299*299不变。

5.1.2Comparisons and Hyper-parameters
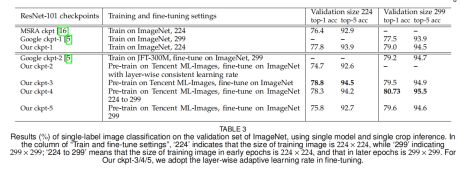
为了验证Tencent ML-Images checkpoint的视觉表达能力,我们对比了5个利用不同微调方法得到ResNet-101的checkpoint。训练这些checkpoint的超参数总结如表2。此外,我们还展示了其他实现的结果,包括:MSRA在ImageNet从头开始训练的结果;ImageNet上从头开始训练的Google checkpoint的结果;在JEF-300M进行预训练,在ImageNet上使用层间连续学习率进行微调的checkpoint的结果。结果见表3。
5.1.3Results
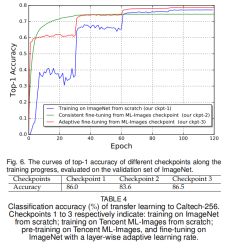
所有结果对比如表3所示。(1)对于baseline来说(例如,在ImageNet数据集上从头训练),我们的ckpt-1比无论是MSRA的ckpt【16】还是Google的ckpt-1【5】都要高。我们的实现与MSRA实现在模型结构与输入样本大小(224*224)都是相同的。主要的区别是图像预处理(见4.1.2节)与超参数,这应该是这两个baseline表现不同的主要原因。相反,模型结构与图像预处理过程并没有在文献【5】中展示,图像大小是299*299。我们的ckpt-1还是比Google的ckpt-1在299*299的验证样本上表现更好。这展示了我们baseline的实现的高质量。(2)此外,我们基准checkpoint(例如,表3中的我们的ckpt-1)和我们微调的checkpoint(例如,表3中我们ckpt-2/3/4/5)的对比展示出了两点。我们的ckpt-2模型准确率比ckpt-1的准确率要低的多。如5.1.1节分析的那样,Tencent ML-Images与ImageNet两个数据集之间有显著的不同,而且Tencent ML-Images数据集里面有很多噪声标签,这些都可能给模型表现带来负面影响。基于层间连续学习率的微调不能消除这种负面影响。相反,我们的每层学习率自适应调节的微调模型ckpt-3展示出了1%的top-1准确率与0.6%的top-5准确率。这展示出,每层学习率自适应的方法不仅可以利用Tencent ML-Images数据集checkpoint的良好底层视觉表达编码,还可以消除编码在顶层的两个数据集的不同带来的显著差异。这种现象告诉我们,Tencent ML-Images的checkpoint包含良好的视觉表达能力,但用于其它视觉任务时需要进行小心的微调。我们还在ImageNet的验证集上利用top-1准确率评估了不同epochs的差异,见图6。(3)Google的ckpt-2模型的top-1准确率与top-5准确率分别为79.2%与94.7%。在Google的ckpt-1上top-1与top-5准确率分别提升了1.7%与0.8%个百分点。这展示出JFT-300M数据集上预训练模型的高质量。相反当分辨率大小为299*299时,我们的ckpt-3/4/5/都比Google的ckpt-2的准确率高。我们的自适应输入样本尺寸的微调方法获得的模型ckpt-4准确率最高,top-1为80.73%,top-5为95.5%,相对我们的ckpt-1模型top-1与top-5准确率的提升分别为1.73%与1%。我们的checkpoint相对与Google的ckpt-2无论是准确率还是准确率相对于baseline的优化都更好。考虑到JFT-300M数据集的大小是Tencent ML-Image要大17倍,这证明了Tencent ML-Images数据集与我们的训练与微调的高质量。然而,来自JFT-300M数据集微调的模型准确率还是比来自我们checkpoint的高。
5.2Transfer Learning To Caltech-256
我们还在另外一个单标签小规模数据集Caltech-256【9】上进行了迁移学习,这个数据集包含30607张样本,256个目标类别。我们利用与训练的ResNet-101模型来提取Caltech-256数据集里每张样本的特征。特别的是,我们将ResNet-101的全局平均池化的输出作为特征向量(2048维)。我们训练一个多类SVM分离器来预测每个类别的标签。我们对三个checkpoit进行对比,包括:从头开始训练的ImageNet;ML-Image进行预训练与在ImageNet上利用分层自适应学习率进行微调。不同checkpoit的结果展示如表4。ImageNet checkpoint的结果比Tencent ML-Images上的结果要好。这再一次展示了Tencent ML-Image与单标签数据集分布的巨大不同。来自Tencent ML-Images的自适应微调checkpoint得到86.5%的准确率,比ImageNet的86%要高。这也证明了Tencent ML-Image的更好通用视觉表达可以通过自适应微调更好的探索。
5.3Transfer Learning To Object Detection
我们在包含20个目标类别的PASCAL VOC数据集的benchmark上进行到目标检测的迁移学习。为了与【5】进行公平对比,我们还是利用来自PASCAL VOC 2007与2012的trainval样本及逆行微调的训练集,包含16551张训练样本。所有的模型都在PASCAL VOC 2007的测试集上进行评估,这个测试集上包括4952张样本,使用50%阈值的IOU的平均准确率([email protected])。
对比。我们与【5】中的迁移学习进行对比,包括我们在ImageNet以及在JFT-300M与JFT-300M+ImageNet上预训练的baseline。我们第一个checkpoint(例如ckpt-1)也是利用从头训练的ImageNet与训练模型在VOC上进行微调。我么那第二个checkpoint(ckpt-2)首先在Tencent ML-Images上进行预训练,在ImageNet上进行微调(使用表3中的 ckpt-3相同的设置),进一步在VOC上进行微调。
实现细节。我们的实现基于Faster RCNN框架的TensorFlow实现【34】【35】。我们是用momentum为0.9的随机梯度下降法进行训练;初始化学习率设置为8×10-4,decays为每80k个step下降0.1;batch size设置成256;模型训练180k的steps;权重衰减设置为10-3。输入样本将短边resize到600个像素,而保持图像比例。
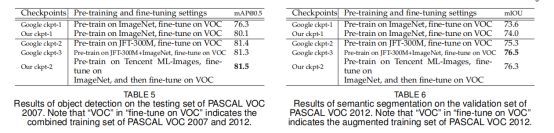
结果。实验结果总结如表5。在baseline的checkpoint对比中,我们ckpt-1达到80.1%,Google的ckpt-1为76.3%。相同的数据集与模型结构展示出我们的实现质量比Google的实现质量要好得多。Ckpt-2显示出比ckpt-1的1.4%的改进。这证明了Tencent ML-Images的预训练模型更好的视觉表达能力。相反,Google的ckpt-2与ckpt-3分别为81.4%与81.3%,比我们的ckpt-2略低。这展示出Tencent ML-Images预训练在ImageNet微调的模型与在JFT-300M与IFT-300M+ImageNet的预训练模型有相似的通用性。考虑到JFT-300M比Tencent ML-Image大17倍,我们可以说明Tencent ML-Image是更高质量的数据集。我们还尝试了在Tencent ML-Image上的预训练模型,在VOC上进行微调。他的表现没有其它的模型表现好,所以我们没有介绍它的结果。我们认为是Tencent ML-Image与VOC数据集间分布的差异导致的结果差异。
5.4Transfer Learning to Semantic Segmentation
我们在PASCAL VOC 2012数据集上进行迁移学习,包括20个前景类别与1个背景类别。为了与【5】进行公平的对比。我们利用PASCAL VOC 2012的扩展训练集进行微调,包含10582张训练样本。所有模型都在PASCAL VOC 2012的验证集上进行验证,包括1149张图片,使用mIOU作为度量标准。
对比。我们使用目标检测实验(见5.3节)中checkpoint的设置。因此,我们不再进行重复说明了。
实现细节。我们的实现时基于DeepLab【36】的语义分割结构。为了进行公平对比,我们的实现还使用DeepLab-ASPP-L结构,在ResNet-101模型的Conv5模块后还有4个分支。所有的ASPP分时使用3*3大小的核,但atrous rate 不同({6,12,18,24})。训练过程中,我们使用poly学习率策略(power=0.9),而且初始化学习率设置为3×10-3。权重衰减设置为5×10-4。模型利用随机梯度下降法训练50k的steps,momentum为0.9。Batch size设置为6,输入样本的尺寸resize成513*513。
结果。结果总结在在表6中。我们可以获得与在目标检测任务上迁移学习相似的结果(见5.3节与表5)。1)我们baseline checkpoint的实现比Google的摇号,我们的ckpt-1 74.0%vsGoogle的 ckpt-1 73.6%。2)我们的ckpt-2显示出比我们的ckpt-1的2.3%优化,证明了Tencent ML-Image预训练checkpoint更好的视觉表达效果。3)Google ckpt-2为75.3%而Google ckpt-3为76.5%。这展示出我们在Tencent ML-Images预训练,在ImageNet上进行微调的模型比在JFT-300M数据集上的模型通用性更好,与JFT-300M+ImageNet预训练模型结果相似。
6、Conclusions
本文中我们构建了一个大规模多标签的图像数据集,称为Tencent ML-Images,包括18M样本与11k类别。这是目前开源的最大多标签数据集。我们展示了在Tencent ML-Images数据集上利用深度卷积神经网络进行大规模视觉表示学习,使用包含MPI与NCCL的分布式训练框架。为了消除大规模多标签数据集中严重的样本不均衡问题,我们新设计了一个损失函数。我们还对其他视觉任务的迁移学习进行了一系列扩展实验,包括单标签分类、目标检测与语义分割,证明了Tencent ML-Image是高质量的数据集,预训练的checkpoint有很好的视觉表达能力。我们希望本文的工作可以作为一个新的大规模视觉表达的benchmark,在工业与学术领域促进其他视觉任务。Tencent ML-Images数据集,数据准备的完整代码,用于微调与特征提取的预训练模型和预训练和微调的ResNet-101模型都被开源在https://github.com/Tencent/tencent-ml-images。