原文地址:https://www.infoq.cn/article/PkWo_g6G5YGaXEiT8lm9
广告、电商和游戏是互联网变现的三个最主要手段,而电商中除了直接卖东西的部分,其他本质上也是广告。科大讯飞作为一家 AI 公司,拥有 90 余万开发者以及海量数据。利用自身的 AI 实力和大数据能力,科大讯飞广告业务实现了从零到百亿级的日交易量,它的业务架构是如何演进的?期间遇到哪些问题?架构中各子系统又是如何设计的?
在 TGO 鲲鹏会武汉分会活动现场,来自科大讯飞数字广告事业部技术负责人仉乾隆带来了《从零到百亿级日交易量:广告实时竞价平台架构演进之路》的主题分享,来看看科大讯飞如何以技术实力赋能营销升级。

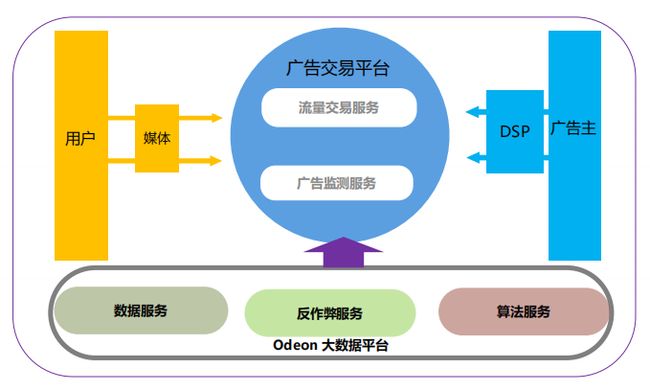
我先说一下当前的系统现状,整个系统平台是分为入口和出口,每天入口 PV 100 亿左右,竞价次数每日 300 亿左右,单次会话平均 40ms 左右,每天日志数量为 20TB+。上图是业务模型,中间是广告交易平台。广告交易平台核心是交易,所以肯定是有买有卖,卖的是流量,流量即媒体,广告主来买。
目前,绝大部分广告主要投广告的时候,一般是先找 DSP,然后通过我们的广告交易平台,最后找到媒体。
广告交易平台有两个核心服务,一是流量交易,二是广告监测。我们在广告上一直在不停尝试 AI 相关的算法,希望把广告做的更有效果,所以我们强依赖数据服务和算法服务。
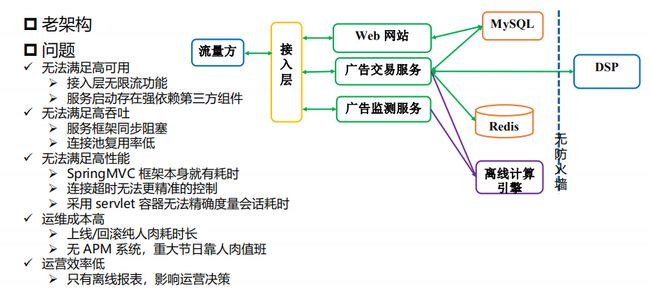
接下来再来说老架构,最开始时,我们只有几个程序员和产品,因此无论是服务,还是数据,我们都做得是最精简的。但随着业务量的增长,出现了几个问题:一、无法满足高可用;二、无法满足高吞吐;三、无法满足高性能;四、运维成本高;五、运营效率低。

这是当前的新架构,大框架与之前没有太大的变化,还是分为三个部分:流量网关、服务集群和 DSP。流量网关具备限流能力,相当于“保险丝”保护后面的系统,同时还具备流量统计、分流、故障隔离等功能。
内部容器集群分为三种,测试、联调、生产集群。业务日志全部进入统计计算引擎,这些数据会辅助做运营决策以及后面做一些监测,整个系统由 APM 负责监控。原来是没有防火墙的,随着业务的增长,为了确保安全,我们上线了并发性非常强的防火墙。
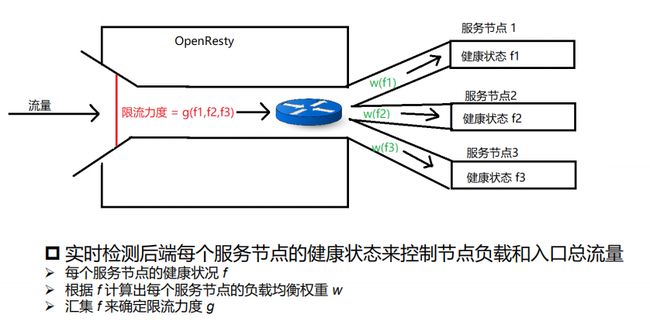
说一下流量网关的设计。为什么做流量网关呢?一是内部存在多个系统都需要用流量,不同的系统对接比较麻烦,对人力成本消耗比较大;二是流量对接与竞价耦合,流量接入迭代快上线动静大,因此我们做了拆分,把流量网关独立了出来。

上图是限流系统可视化的解释,首先我们要实时检测服务后端,当一个流量进来以后实时计算限流的力度,根据力度决定请求是继续还是回退。


不管限流力度还是权重都依赖于服务的健康状态,服务健康状态由多个指标进行衡量,如服务的处理时间、网络的传输时间、节点所在机器物理资源使用量等等。建立数学模型,可以看到最终效果就是想限哪个就把它压到那个值。

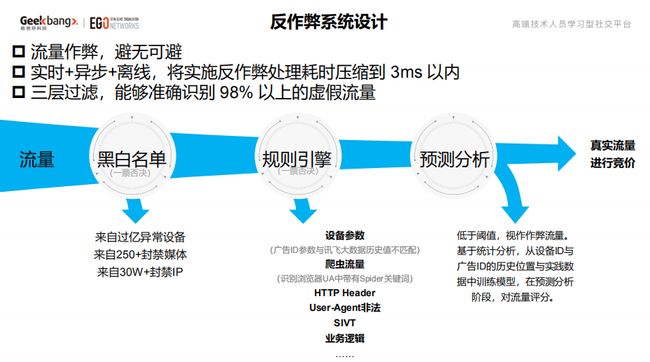
反作弊系统是整个系统的核心保障,流量作弊是没法规避,但如果加了这个额外处理会话时间肯定要上去。为了要保证实时性,因此我们把反作弊流程进行了分拆,分为实时和离线两个部分,同时将处理流程尽量异步化。最终把反作弊处理耗时压缩到了 3ms 以内。通过三层过滤,现在可以做到准确识别 98% 以上的虚假流量。
反作弊系统核心遵循两个原则,一个是实时和离线协同,二是机器和人工协同。AI 算法虽然厉害但是某些部分还是要靠人类智慧来总结规则,我们把实时的数据通过三层过滤得到结果,同时把实时数据和历史数据进行合并来训练模型,然后加上人工分析形成一些策略在模型训练的时候加进去,最终生成一个模型,这个模型会实时反馈更新系统。
Alan Kay 说过一句话,面向对象的核心是消息传递。设计一个庞大且持续增长的系统,最应该关注的是内部子系统之间怎么交互,而不是先考虑系统具备什么属性。Actor 模型在真正意义上实现了 Alan 所讲的面向对象概念。
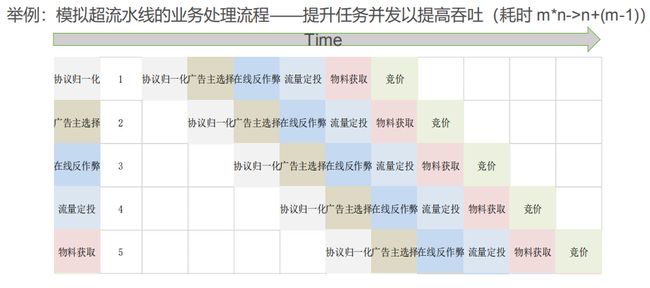
一次交易过程涉及的逻辑非常多,刚开始做的时候是同步阻塞式的,但是随着处理环节越来越多如果还是采用同步阻塞模式耗时就太高了,所以我们模拟 CPU 超流水线重构了业务处理流程,最终效果是提升了任务并发并提高了吞吐。

目前,我们对接了国内上百家的 DSP,在巨额宽带费用以及会话时间成本、人工运营成本增加的情况下,我们实现了一个智能 QPS 调节模块。

下面说一下缓存系统的设计,最开始我们所有做的东西是根据需求来,只要满足需求,就没有做太多的优化,因为当时量不大,所以是可以满足的。
随着业务量增加,老架构强依赖 DB 限制了服务水平扩展,同时还有配置生效实时性差、增量更新无法感知物理删除以及服务 GC 压力大、容易发生故障等问题。基于这个背景我们做了新架构,设计了新的缓存系统。
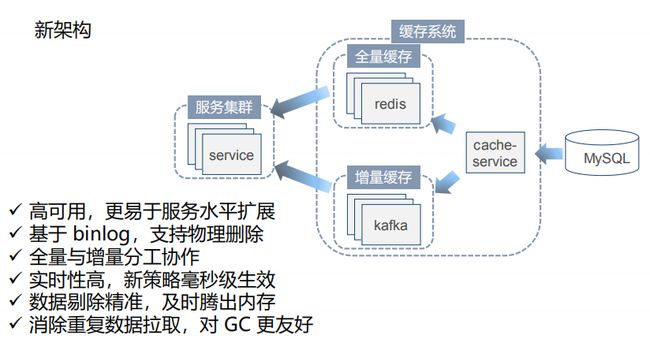
新架构不仅整个缓存系统高可用,而且更易于服务的水平扩展,而且新架构更新基于 binlog 支持了物理删除。再有就是全量与增量分工协作,实时性高,所有的策略毫秒级生效,另外是数据剔除更加精准,消除了重复数据拉取,对 GC 更友好。

日志系统的设计,通过这个改进以后,我们把服务跟 flume 客户端做了解耦,当前每天系统处理 20TB+ 日志量,实时报表可以秒级更新,离线报表做多维度全景观察,服务与日志系统解耦更加高可用,日志查询辅助问题定位。

现在的 APM 系统实现了 SaaS、PaaS、IaaS 全监控,状态可视化,随意组合,所有的数据秒级感知到,全链路追踪,而且可以启发优化点。
为什么搞这么多个告警网关呢?之前只有短信和邮件,邮件不是经常看,实时告警主要是依赖于短信,之前出现过短信延迟一小时的情况,因此用微信做了备份告警网关。

我们在 2018 年年初引进了 Kubernetes,基于 Docker 实现了全部服务的容器化。master 集群服务于上百台的服务机器集群,如果 master 挂了整个集群就瘫了。我们采用分布于 5 个独立机柜且独立子网的机器构成 master 集群,确保整个集群的高可用。
除了“一键”滚动升级与回滚,集群还支持定向弹性扩缩容、多租户隔离、多粒度资源配置管理,以及透明的服务注册与服务发现。

下面说一个比较务虚但是我认为比较重要的东西。要做到系统高可用、平台高可用,除了技术上的保障,还涉及到很多非技术的东西。一件事情如果需要多方参与,就不可避免出现协作上的问题,因此在整个过程中需要一些规范和一些制度来保障。我们所有的代码提交,都必须经过 code review,在 code review 过程中会给版本定级。同时我们还设有月度的 bug review,即每个月月底研发、测试会一起来审视当月测试过程中发现的 bugs,把 bugs 分级分类,看是哪些人犯的,有没有共性,下一步怎么改善,同时把这些跟个人绩效挂钩以防止再犯并鼓励大家把测试做好。我们采用 JIRA 来做需求流程管理,但我们做了一系列的定制,确保每一步的产出都是可交付可追溯的。从需求提出到产品设计方案、研发编码发版、测试人员进行测试、运维上线,最后反馈到产品,这整个流程必须全部可交付、可验证,而且要留档。只有这样才可以做相应的复盘、自我检查和自我改进。
最后是价值的跟踪,这个是流程管理的重要一环。我们针对全部需求做价值跟踪。一般需求分两类,一个是效益类(即需求上线提升了多少效益),另外是效率类(即需求上线节省了多少时间)。这些再进一步反馈到流程管理的需求提出的这一层。再就是 TDD,TDD 执行前期比较耗时,但是养成习惯以后非常有益于从源头做好方案设计。
除此之外,还需要具备风险意识,上线以后每一秒都在产生价值,全部代码都会影响营收,因此我们要求每个人有相应的风险意识。再者是 DevOps,这个不是开发运维而是开发运营,我们要求是每个研发人员都能主动往前走,走到需求方,看自己的代码到底满足了什么满足到了什么程度,然后再回过头看自己做的东西的价值,以及如何做得更好。这对整体业务是非常有帮助的。