目录
- 一、梳理JML语言的理论基础、应用工具链情况
- 关于JML(Java Modeling Language)
- JML语法
- JML相关工具链
- openJML的使用
- 转机
- 二、部署SMT Solver
- 三、实现自动生成测试用例
- 使用JMLUnitNG
- 再次尝试对的
MyPath.java进行测试 - 一点小结论
- 四、梳理架构设计
- 第一次作业
- 第二次作业
- 第三次作业
- 五、出现的Bug与修复情况
- 自己的Bug
- 别人的Bug
- 六、对规格撰写和理解上的心得体会
一、梳理JML语言的理论基础、应用工具链情况
关于JML(Java Modeling Language)
- JML是一种形式化的、面向JAVA的行为接口规格语言(behavioral interface specification language)
- JML允许在规格中混合使用Java语法成分和JML引入的语法成分
- JML使用Javadoc的注释方式
- JML已经拥有了相应的工具链,可以自动识别和分析处理JML规格(如
OpenJML,JML UnitNG等)
JML语法
JML语法很多,但大部分看着和伪代码一样,很容易理解。这里挑一些重要的、常用的进行归纳总结。
- 注释:结构化、扩展性强
- 块注释:
/*@......@*/ - 行注释:
//@ ......
- 块注释:
- Previous expression value:
\old(E) - Exception:
/*@ signal (Exception e) P;@*/ - Iterating over all variables:
(\forall T x; R(x); P(x)) - Verifying if exist variables:
(\exists T x; R(x); P(x))
JML相关工具链
- OpenJml:
-esc静态检查程序可能存在的问题;-check检查JML规范性,不检查程序的Java代码; - SMT Solver:如OpenJML中的
cvc4,z3等,用来检查代码与规格的等价性 - JMLUnitNG:可以用来生成数据代码
- 我个人还使用VScode中的jml-vscode插件用于高亮jml语法,方便查看
openJML的使用
这简直是一场灾难。
使用OpenJML检查JML语法的命令是:
#!/bin/bash
java -jar openjml.jar "$@"把这个保存在一个shell脚本中,方便以后使用。
OpenJML不支持\forall int[] 和 \exists int[]等语法。
我对MyPath.java的JML语法进行了检查,结果疯狂报错。
package path;
import java.util.ArrayList;
public class MyPath {
private /*@spec_public*/ ArrayList nodes;
public MyPath(int... nodeList) {
nodes = new ArrayList(nodeList.length);
for (int i : nodeList) {
nodes.add(i);
}
}
//@ ensures \result == nodes.size();
public /*@pure@*/int size() {
return nodes.size();
}
/*@ requires index >= 0 && index < size();
@ assignable \nothing;
@ ensures \result == nodes.get(index);
@*/
public /*@pure@*/ int getNode(int index) {
return nodes.get(index);
}
//@ ensures \result == (nodes.size() >= 2);
public /*@pure@*/ boolean isValid() {
return (nodes.size() >= 2);
}
} 
无奈之下换用讨论区中大佬们提供的案例,进行实验。
public class JMLTest {
/*@
@ public normal_behaviour
@ requires lhs > 0 && rhs > 0;
*/
private static int compare(int lhs, int rhs) {
return lhs - rhs;
}
public static void main(String[] args) {
compare(114514, 1919810);
}
}使用openjml.sh -check src/JMLTest.java对其进行语法进行检查得到如下的结果:

懵了。我也不知道到底哪里出问题了,JML语法是没有问题的。我确实是JDK8呀……
Internal JML bug - please report. BuildOpenJML-0.8.42-20190401
可能也是OpenJML等相关工具问题太多,导致JML过于小众吧。OpenJML是实验就这么告一段落了,我心好累。
转机
经过多次尝试,我终于发现了问题盲点所在。文件夹的名字里面不能有空格!!!
那么重新使用OpenJML对MyPath.java进行JML语法检查,得到如下结果:

终于得到了预期的结果。产生上述错误的原因是nodes是ArrayList而不是普通的数组。OpenJML可以正常使用了,所以暂时告一段落。
二、部署SMT Solver
使用openjml.sh -esc对代码进行静态逻辑检查。但是在命令行中,由于cvc4-1.6运行报错,z3-4.3.2运行不起来,所以改成在IDEA中使用z3-4.7.1进行静态检查。

说明Solver检查出getNode()方法中,未检查index的范围可能导致出错,与下面JMLUnitNG得到的结果类似。
三、实现自动生成测试用例
使用JMLUnitNG
由于规格中的数据结构与实际实现的数据结构有较大的差异,所以这里使用讨论区中的一个简单的例子来实验JMLUnitNG。
public class Demo {
/*@ public normal_behaviour
@ ensures \result == lhs - rhs;
*/
public static int compare(int lhs, int rhs) {
return lhs - rhs;
}
public static void main(String[] args) {
compare(114514,1919810);
}
}接下来依次执行下面的指令,使用TestNG对Demo.java进行测试。
java -jar jmlunitng-1_4.jar demo/Demo.java
javac -cp jmlunitng-1_4.jar demo/**/*.java
java -jar openjml.jar -rac demo/Demo.java
javac -cp jmlunitng-1_4.jar demo/Demo_JML_Test.java
#此处发现Demo_JML_Test没有对应的.class文件,所以显式地重新编译一下,否则可能出现找不到主类的情况。
java -cp jmlunitng-1_4.jar demo.Demo_JML_Test得到如下的结果反馈:

可以看出,JMLUnitNG自动生成的测试用例主要测试的是一些边缘情况,比如Integer.MAX_VALUE,Integer.MIN_VALUE,null,0等特殊情况。
至此,使用JMLUnitNG自动生成测试用例到此结束取得了预期的成果。
再次尝试对的MyPath.java进行测试
此处需要注意的是,jmlunitng编译文件的时候不支持泛型的自动类型推断,请new的时候手动添加类型。
得到的结果如下:

主要错误是getNode()函数没有对index做出正确的判断和处理。这里感觉应该需要一个异常来处理错误。
一点小结论
JMLUnitNG最近一次的release是在2014年,是5年前了,对现在主流的IDE工具支持不完备(几乎没有),并且发布时间较早,很多Java的新特性并不支持。而且几乎全程使用命令行工具在操作,体验极差。整体JML相关的工具体验都不怎么样。
JML小众是有原因的。
四、梳理架构设计
第一次作业
第一次作业很简单,只需要按照给出的JML规格完成对应的设计即可。
需要注意的是,要降低时间复杂度,需要使用高效的容器。比如getDistinctNodeCount()应使用HashSet或其他Set类。而PathContainer为了提高增加元素和删除元素的效率,可以使用两个HashMap,让Path和PathId相互索引来提高查找、增删效率。
类图如下图所示:

第二次作业
第二次作业要在PathContainer的基础上,构建一个图,并求图的连通性以及最短路。为了扩展性,我是用了HashMap作为图的数据结构,为的是在扩展性和速度上保持一个平衡,所以没有使用二维数组。
在最短路方面,我选择Floyd算法作为最短路的算法,并添加一个类ShortestPathMatrix用于计算和保存最短路。
连通性方面也使用最短路矩阵判断,如果距离小于INFINITY则是连通的,避免了并查集或者广度优先遍历带来的多于时间开销。
类图如下图所示:

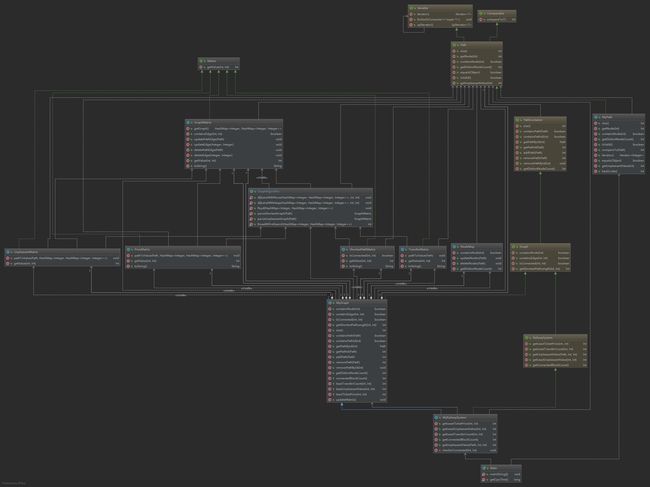
第三次作业
第三次作业的需求比前两次都复杂许多。在第二次作业的基础上,新增了连通块、换成次数、票价和不满意度四个需求。这四个新需求的难度依次递增。
我没有使用拆点的方式,而是通过定义边权来计算。
连通块我使用广度优先搜索BFS来计算。
对于换乘次数,我把边权重新定义为乘坐地铁线路的条数,即换乘次数=乘坐地铁的条数-1。则只需要根据把根据每一条Path,将同一条Path上的点在图中初始化为1,就可以使用Dijkstra或者Floyd算法计算出两个站点间的“最短路”——这里的最短路表示两个站点间需要乘坐的地铁的条数。查询换成次数时,只需要减一即可。
票价和不满意度的建模方式与最少换乘类似。由于Path内可能存在环,所以要对Path先建立一个图(只包含相邻站点),然后根据这个图算出Path内的最少票价或最少不满意度,然后将Path的最少票价图加入整个图的最少票价图,然后就能通过最短路算法来计算最少票价和最少不满意度。
最少换乘、最少票价、最少不满意度都抽象出一个类来单独维护。
对用公共的算法(例如Floyd, Dijkstra, BFS等)将他们设置为静态方法,统一放在GraphAlgorithm这个类中,减提高代码的复用性。
代码的大致结构如下:
类图如下图所示:
五、出现的Bug与修复情况
自己的Bug
第一次作业与第二次作业均100分通过强测并且互测没有Bug。
当我以为这个单元可以非常圆满的拿到三个A组100分,没想到最后一次作业还是翻车了。
最后一次作业最终强测只得了十分,唯一个Bug出现在Dijkstra算法。错误的在当前最短路径点时toNodeId时提前结束了算法。并且应该在最后对结果进行缓存,而不是在计算过程中对结果进行缓存。主要原因还是没有理解Dijkstra的本质贪心算法——所有的最短路都只是基于已知情况做出的判断,所以加入了错误的“优化”,导致正确性出错。
十点过写完数据生成器,和别人的输出比较就发现了自己的Bug。可惜我写完数据生成器已经过了提交时间,此时发现Bug也为时已晚了。这个Bug有些隐蔽,因为1000条指令的数据集没有测出问题,但是写完数据生成器,生成的5000条的指令就出现了问题。5000条指令中384条最短路查询指令,其中只有13条出错。
为此我专门写了一篇博客浅显的分析了一下两个最短路算法的区别,也让我对贪心算法和动态规划算法有了更深的理解。记一次错误的Dijkstra算法优化—动态规划与贪心,(骗一波访问量)。
附上正确的堆优化+缓存的Dijkstra算法的代码:
public class GraphAlgorithm {
public static final int INFINITY = Integer.MAX_VALUE >> 4;
// 堆优化的迪杰斯特拉算法
public static void dijkstraWithHeap(
HashMap> graph,
int fromNodeId) {
PriorityQueue sup = new PriorityQueue<>();
HashMap dist = new HashMap<>(graph.size());
Set found = new HashSet<>();
for (Integer vertex : graph.keySet()) {
dist.put(vertex, INFINITY);
}
dist.put(fromNodeId, 0);
sup.add(new HeapNode(fromNodeId, 0));
while (!sup.isEmpty()) {
HeapNode front = sup.poll();
int nowShortest = front.getId();
int minWeight = front.getValue();
if (found.contains(nowShortest)) {
continue;
}
found.add(nowShortest);
for (Integer ver : graph.get(nowShortest).keySet()) {
int value = graph.get(nowShortest).get(ver);
if (!found.contains(ver) && minWeight + value < dist.get(ver)) {
dist.put(ver, minWeight + value);
sup.add(new HeapNode(ver, minWeight + value));
}
}
}
// 最后缓存数据
for (Integer ver : dist.keySet()) {
int minWeight = dist.get(ver);
graph.get(fromNodeId).put(ver, minWeight);
graph.get(ver).put(fromNodeId, minWeight);
}
}
} 最后的Bug修复也很容易,改好这个Dijkstra算法就一波带走了24个Bug。
这告诉我,对于这些已有的、经典的、写进教科书的算法,不要对其做轻易的改变。直接抄模板的最稳妥的办法。
本来可以是开心的A组,开心的满分,结果……唉??

别人的Bug
我写了一个数据生成器,互测阶段手动与别人对拍。
第一次作业碰到使用ArrayList.hashcode()作为HashMap的key,而ArrayList.hashcode()方法是JDK中公开的那个乘31的算法,导致他被卡了哈希冲突的bug。这说明HashMap一定不要用hashcode()作为key,应该直接使用对象本身作为key。
六、对规格撰写和理解上的心得体会
- 我对规格的理解就是对方法/类/程序的数据、作用、行为的一种抽象表示。JML的介入可以精准的表述一个方法的对输入、返回值的约束,明确地列出各种异常情况。对于数据,JML也能清晰地描述数据应满足的要求、以及数据变化时应遵循的约束条件。这些规范化的描述时有利于编程规划的。
- JML描述的规格,对方法、类等程序单元进行了严格的约束,这些正确详实的规格,相较于自然语言,能更加规范地描述需求,减少歧义,保证开发的速度与质量。这种约定对于大型工程的协同开发有很多的好处。
- 但是感觉某些时候使用JML进行规格描述反而会复杂化某些问题。比如第三次作业的规格描述,我愣是看了半天没有看懂……认真读一读指导书理解地还更快。所以我认为在某些情况下,对于一些复杂的需求,使用JML对其进行规格描述不一定是最好的选择。但这并不是说JML不好,JML是一种避免程序出现问题的必要手段,只是不同的规格描述方式有其各自适用的地方。
- 规格是一种规范,而不是死板的约束。规格只是一种规定了方法或者类的行为结果,但是规格并没有约束我们具体实现的方式。数据结构的实现上不能拘泥于JML的描述,应该在满足规格描述的条件下实现尽可能高效的数据结构与算法。比如
MyPathContainer中应使用HashMap来提高速度,而不是使用JML中的数组。 - 本单元的学习也是对原先学习的数据结构的一次复习。温故而知新,这次的作业很好地体现了Dijkstra和Floyd算法各自的适用范围,对于贪心和动态规划两大算法思想的本质有了更深刻的理解。
感谢讨论区中无私发言、分享经验的各位同学。期待最后一个单元能收获更好的结果。???