python之编码译码与文件读写
decode是编码,解码
python中各种事物以对象的形式存在
计算机中0,1要实现和人类语言的互译,就需要由“字典”:
“字典”,被叫做编码表。简单来说,就是建立起人类语言和计算机语言一一对应的表。从人类语言到机器语言,我们称之为“编码(encode)”,从机器语言到人类语言,我们称之为“解码(decode)”。
英文,一个字符只占一个字节(一个字节,是二进制的八位数)。
中文占两个字节,编码表(ASCII)
注意:Python3默认使用Unicode编码来处理我们输入的内容。所以encode('Unicode')是不能使用的。
可以使用ord()的方法,来获取单个字符的十进制整数编码。
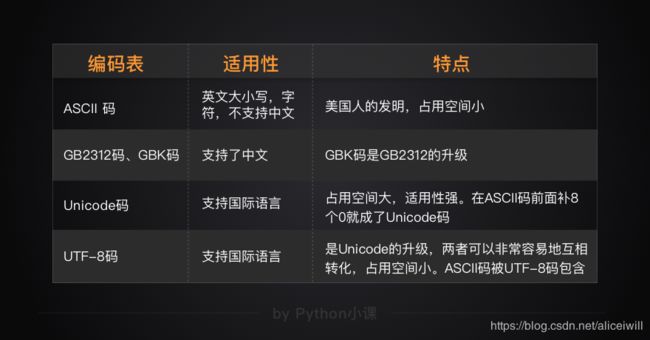
四种编码格式,应用于不同场景:
内存”。数据在内存当中处理时,使用的格式是Unicode,统一标准。
在硬盘上存储,或者是在网络上传输时,用的是UTF-8,因为省空间
一些中文的文件,中文的网站,还在使用GBK,和GB2312。
UTF-8和Unicode可以非常轻易地按照一个规则来互相转换
b代表‘字节’,字节类型数据
不同编码之间是可以转换的,利用encode与decode
1.ascii编码
print('K'.encode('ASCII'))
结果为b'K' 这两个K不一样,第一个K为字符串,第二个为bytes类型的数据,只占了一个字节
2.unicode编码
注意:因为python3利用unicode,所以不可以直接用encode
使用ord()的方法,来获取单个字符的十进制整数编码,使用char()来获取整数对应的相应字符
print(ord('地球')) print(char(12346))
3.GBK与UTF-8 (都使用了encode,decode方法)
print('枫'.encode('gbk'))
#将汉字'枫'使用gbk编码,得到:b'\xb7\xe3'
print(b'\xb7\xe3'.decode('gbk'))
#解码,得到:枫
print('枫'.encode('utf-8'))
#将汉字'枫'使用utf-8编码,得到:b'\xe6\x9e\xab'
print(b'\xe6\x9e\xab'.decode('utf-8'))
#解码,得到:枫
可以看出,其用十六进制表达的
二、文件读写
类比 把大象放进冰箱
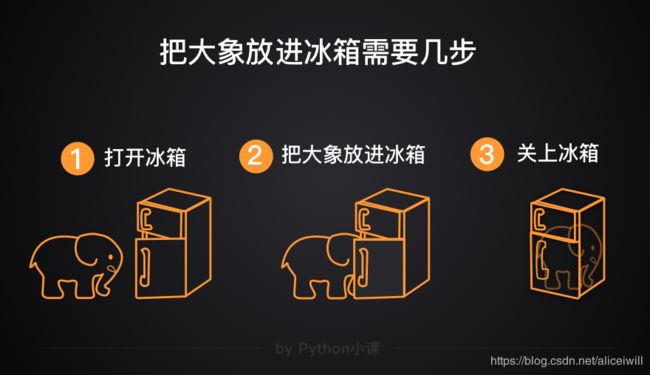
就是 开——读/写——关 这三个步骤
1.开的操作语句
file1 = open('/Users/motanyuan/Desktop/abc.txt','r/w',encoding='utf-8')
注意
这个句子第一个参数为文件的保存地址,如果计算机中没有这个文件,则系统自动创建一个
第二个参数为 以读的方式打开还是以写的方式打开(在这个很重要,因为计算机保护数据的方式不一样)
第三个参数是采用何种编码
下表为第二个参数的性质:
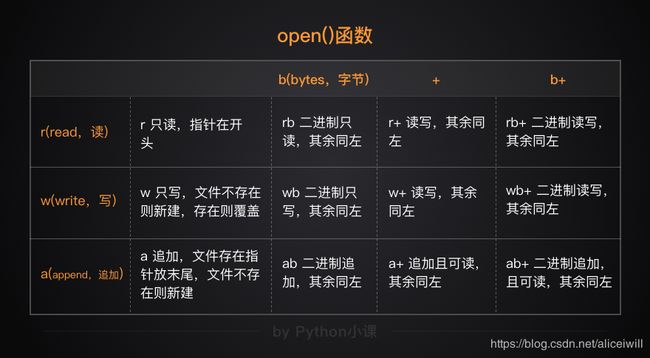
#要注意r/w/a 只能修改字符串,图片音频等格式需要rb/wb/ab参数
w是清空文件里的内容,重新覆盖 a是在源文件后添加内容
2.读写
打开了文件以后,使用read/write函数读写
3.关闭文件
例子:
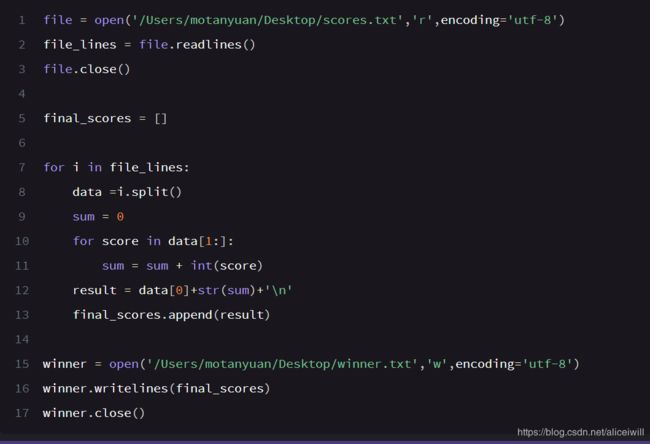
练习是:
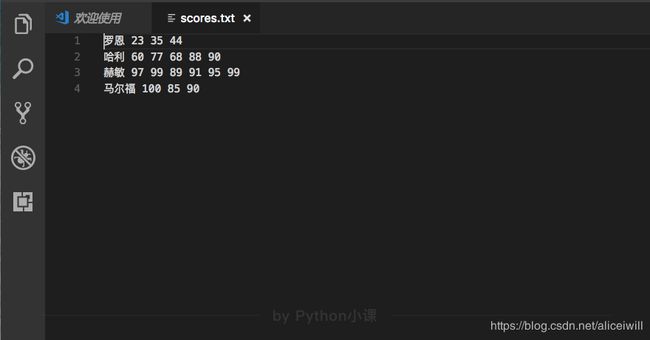
将四个人的总得分写入 1.txt文件中
提示:
将数据按每一行来读 readlines()函数<——结果是将每行数据都放到了列表里
将每一行都分割成小的字符串《——spilt()函数
split() 是把字符串分割的,而还有一个join(),是把字符串合并的: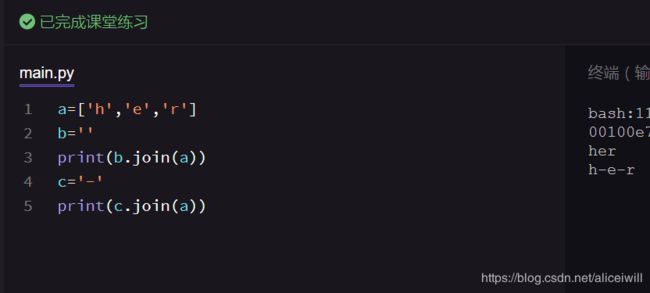
结果: