windows下pyspark访问hive所需的环境搭建
文章目录
- 简介
- 环境搭建与效果演示
- 更细节的搭建方法
- 搭建HDFS、Spark或hive的前提
- 已经有了远程可访问的测试集群
- 搭建hadoop2.7.2
- 修改hadoop配置
- 格式化hdfs
- 测试
- 搭建spark-2.4.5
- 解压hive-2.1.0
- 创建hive元数据库的schema
- 测试spark-sql
- spark-sql访问已经被hive创建的表出现的问题
- 测试hive
- jupyter中使用pyspark
- 使用pyspark访问本地hive
- 测试pyspark
简介
学习大数据最痛苦和费时间的就是入门时的环境搭建,对于大数据工程师而言,这个过程必不可少,但对于一些简单的测试,每次都要打开自己搭建好的虚拟机,未免有些麻烦。
对于数据分析师而言,一般只需要使用hive和spark就好,搭建集群实在是一件费力没有效果的事。如果有一种方法让数据分析师能够在不搭建linux集群的情况下就能把spark,hive在本地跑起来直接使用,那或许会非常方便。
我为了让需要使用大数据组件的朋友很方便的在本地使用hive和spark,已经多次测试了从零到1在windows平台下搭建hadoop、hive和spark,并且直接跑起来。为了减少广大读者环境带来的坑,我删除了原有的老版本,专门下载新版本的spark和对应的hadoop版本进行测试。
按照本文的方法搭建好之后,你就可以直接在windows上启动hdfs、hive和spark各组件,并直接跑起来,然后我会演示如何使用python调用spark,并让pyspark访问现有的hive集群的数据。
每个人机器的环境也都不一样,我之所以写这篇文章这么久就是反复考虑大多数人可能出现的环境问题,但仍然不可能面面俱到。我已经在自己机器上测试通过,若有读者测试中遇到问题无法解决,欢迎反馈。
前面windows下pyspark访问hive所需的环境部分,是演示windows基础环境的搭建,如果你已经有了现成的可以直接远程连接的测试集群,则不需要在本地搭建额外的测试集群可以直接跳过不读本文,但本文提到的一个图形化操作HDFS的工具或许对你有用,它支持windows远程连接HDFS集群,也支持连接使用了kerberos认证的HDFS的集群。
为了大家的方便,我已经将本文涉及的配置好的包和工具上传到网盘,下载地址:
链接:https://pan.baidu.com/s/1XIHFg6sO02HKwtGhBQl5qQ
提取码:5cmd
部分新手可能阅读本文后依然花了很长时间才把本地环境搭建好,初次搭建对于你来说可能很复杂很费时,但想想每次测试都不用再都打开虚拟机了,其实相对来说就省了很多时间,除非你以后不打算再玩大数据。另外,在本地linux虚拟机上跑程序比直接在宿主机上跑程序慢很多,相对每次基础测试都带来的时间节省,我觉得还是很值得的。
最后将演示如何使用python调用spark,并用pyspark访问现有的hive集群。你也可以把你现有集群的hive配置按照文章最后一部分的方法放入指定目录中,使pyspark直接访问你已经配置的hive集群。
环境搭建与效果演示
已经给大家录制了相应的操作视频,整个搭建过程不算上讲解仅需三分钟,快来看看吧:
windows平台搭建和使用hdfs、spark和hive以及pyspark的使用
视频链接:https://www.bilibili.com/video/BV1Ff4y1U7GU/
更细节的搭建方法
下面的方法是全部自己下载包的情况下如何搭建,所以过程有些繁琐,上面的方法已经能够让你成功快速的搭建整个过程,不想了解细节的下面的内容都几乎可以不用再看啦。
搭建HDFS、Spark或hive的前提
电脑中已经安装过java1.8版本,并将JAVA_HOME配置到环境变量中,PATH环境变量也添加了
%JAVA_HOME%\bin和%JAVA_HOME%\jre\bin
为了远程管理并共享hive元数据库,我们使用mysql关系型数据库作管理。使用其他关系型数据库也可以,但本文只演示使用mysql作为hive元数据库。
已经有了远程可访问的测试集群
那本章你就基本不用看了,除非你也想在windows本地搭建一个。
仅需要python调用pyspark,那你只需要电脑本身已经安装了python3.6以上版本即可,没有jupyter就运行以下命令安装
pip install jupyter
然后按照文章 最后一部分的方法 将hive配置文件添加到pip所安装的库对应的目录中。
搭建hadoop2.7.2
下载hadoop2.7.2版本的包:http://archive.apache.org/dist/hadoop/core/hadoop-2.7.2/hadoop-2.7.2.tar.gz,将其解压到你喜欢的位置。
例如我解压到D:/jdk中,然后将D:\jdk\hadoop-2.7.2重命名为D:\jdk\hadoop
配置环境变量HADOOP_HOME=D:\jdk\hadoop

Path环境变量本质上是一个;分割的路径字符串,再向Path中添加
%HADOOP_HOME%\bin和%HADOOP_HOME%\sbin这两个路径
例如Path原本的值为
C:\Windows\system32;C:\Windows
添加后就是
C:\Windows\system32;C:\Windows;%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin
下载已经编译好的window平台的hadoop,版本为2.7.2
http://w3.153.d3s1puv.cn:82/uploadfile/2018/binwin7hadoop.rar
将其解压到%HADOOP_HOME%路径里面,覆盖bin目录中的文件
然后将%HADOOP_HOME%\bin\hadoop.dll复制到C:\Windows\System32

修改hadoop配置
core-site.xml配置:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/tmp/hadoop/datavalue>
property>
<property>
<name>hadoop.proxyuser.Administrator.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.Administrator.groupsname>
<value>*value>
property>
configuration>
hdfs-site.xml配置:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>
格式化hdfs
命令行中输入命令hdfs namenode -format:
D:\>hdfs namenode -format
注意:我在hadoop.tmp.dir的配置中为/tmp/hadoop/data没有加盘符,此时命令行执行位置所在路径决定了hdfs的数据文件的存放位置。由于我在D盘执行的命令,所以最终hdfs的数据文件会放在D:\tmp\hadoop\data中。当然也可以配置为/D:/tmp/hadoop/data(最前面的/不能省略,也不允许在/前面加file:,必须以/开头+盘符才能指定盘符),这样即使在C盘执行命令也会放在D盘。

出现has been successfully formatted.表示格式化成功。
测试
启动hdfs:
start-dfs.cmd

会启动namenode和datanode两个进程。
游览器访问http://localhost:50070/可查询UI界面:
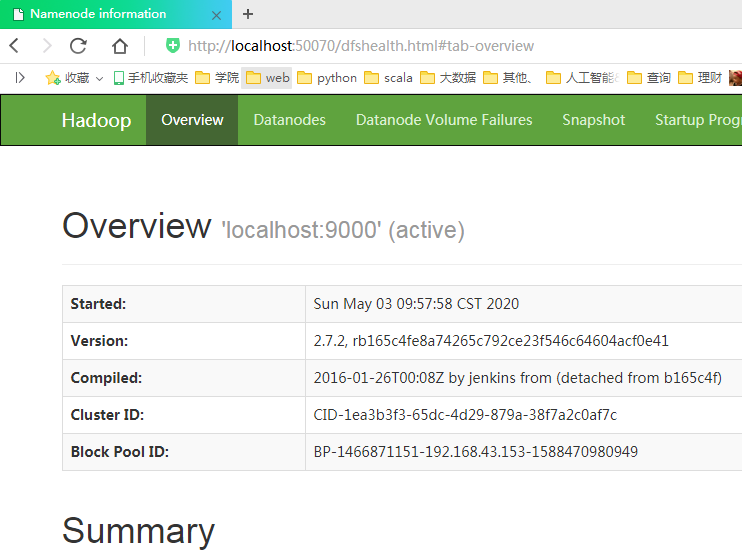
用HDFS游览器访问刚才搭建好的HDFS:

地址和端口填写上面连接HDFS的webUI的ip和端口,上面的连接地址是http://localhost:50070/,所以地址填localhost,端口填50070。
然后测试上传文件:
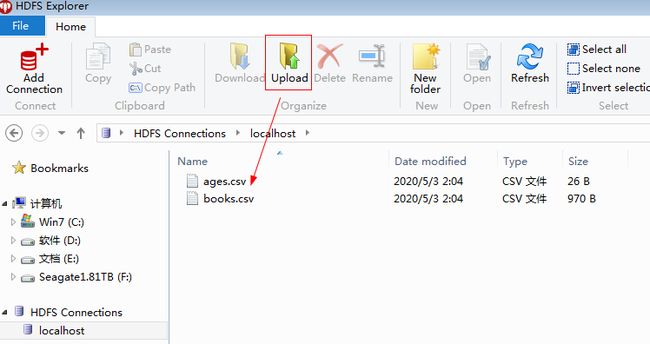
也没有问题,想要这个小工具可以关注公众号data_xxm后台留言获取噢。
再测试一下shell命令行里访问:

也完全正常。
搭建spark-2.4.5
下载spark-2.4.5:http://archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
解压到你喜欢的任意位置,例如我解压到D:\jdk,就将D:\jdk\spark-2.4.5-bin-hadoop2.7\bin添加到Path环境变量中,然后在D:\jdk\spark-2.4.5-bin-hadoop2.7\jars中放入mysql的驱动jar包,例如mysql-connector-java-5.1.38-bin.jar
解压hive-2.1.0
下载:http://archive.apache.org/dist/hive/hive-2.1.0/apache-hive-2.1.0-bin.tar.gz
解压到你喜欢的任意位置,例如,我解压到D:\jdk
配置环境变量HIVE_HOME=D:\jdk\apache-hive-2.1.0-bin
并向Path环境变量中加入%HIVE_HOME%\bin
conf中新建hive-site.xml文件,内容如下:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/tmp/hive/warehousevalue>
property>
<property>
<name>hive.cli.print.headername>
<value>truevalue>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
property>
configuration>
前三项分别是你的mysql连接url,用户名和密码,按照实际情况修改即可。连接url中hive也可以修改为其他名字,表示hive存储元数据的数据库的名称。
hive.metastore.warehouse.dir表示默认情况hive管理表的数据存储位置。
注意:上面hive-site.xml配置了hive.metastore.warehouse.dir=/tmp/hive/warehouse,这个路径在spark中会识别为以程序启动所在盘符下的本地路径,可以指定具体盘符,例如D:/tmp/hive/warehouse则路径不受程序启动位置的限制。
而在这个配置的hive下创建数据库或表,/tmp/hive/warehouse会识别为以fs.defaultFS为前缀的hdfs路径,在本文的配置中就是hdfs://localhost:9000/tmp/hive/warehouse,如果hive.metastore.warehouse.dir被配置为D:/tmp/hive/warehouse则hive会认为是hdfs://localhost:9000/D:/tmp/hadoop/data导致hive无法创建不指定手动指定路径主控表。
要想让hive创建的表也被识别为本地路径,必须配置为file:/D:/tmp/hive/warehouse指定file协议。
创建hive元数据库的schema
hive启动在需要mysql中存在scheme 表格结构,在hive1.x版本原本是可以自动创建的,但2.x版本中必须手工通过下面这个命令:
schematool --dbType mysql --initSchema
但是这个命令在windows平台不好使,会报如下错误,当前路径都会自动给你切换:
D:\jdk\apache-hive-2.1.0-bin\bin\ext>schematool.cmd --dbType mysql --initSchema
C:\Windows\system32
找不到文件
系统找不到指定的路径。
C:\Windows\System32>
其实我之前在windows平台上搭建hive,使用schematool命令,但这次为了演示却不成功了。
如果有读者知道在windows平台如何正确使用schematool命令,欢迎讨论。
既然这个方法不好使,所以我就直接从原理层面直接操作了。这个命令本质是使用了预先定义保存在模板文件的一些sql语句,根据不同的条件选择模板问题,并填充里面的变量。
但是我经过观察发现,这些模板文件需要变量填充的部分执行与否都无所谓,根本不用自己再开发一个填充变量的程序,直接执行这些模板文件的合法sql脚本内容即可。
这样就能实现创建scheme的效果,具体scheme模板文件的路径是%HIVE_HOME%/scripts/metastore/upgrade/mysql/ 目录下的 hive-schema-2.1.0.mysql.sql (其他关系型数据库同理)。
于是只要无视错误的导入D:\jdk\apache-hive-2.1.0-bin\scripts\metastore\upgrade\mysql\hive-schema-2.1.0.mysql.sql脚本到hive数据库就可以创建元数据库scheme了。
下面具体操作一下,先创建hive数据库(字符集必须指定为latin1,排序规则默认值即可):
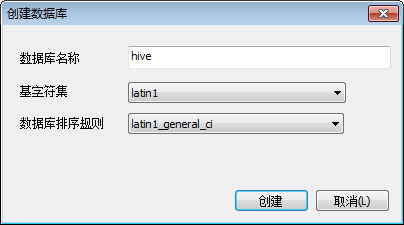
再导入sql脚本(下图使用sqlyog操作):
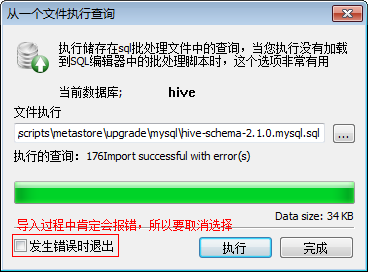
共导入46张表(使用Navicat查看):

测试spark-sql
首先将%HIVE_HOME%\hive-site.xml文件添加到D:\jdk\spark-2.4.5-bin-hadoop2.7\conf目录下:

运行D:\jdk\spark-2.4.5-bin-hadoop2.7\bin\spark-sql2.cmd并创建几张表(已经将D:\jdk\spark-2.4.5-bin-hadoop2.7\bin添加到Path环境变量中):

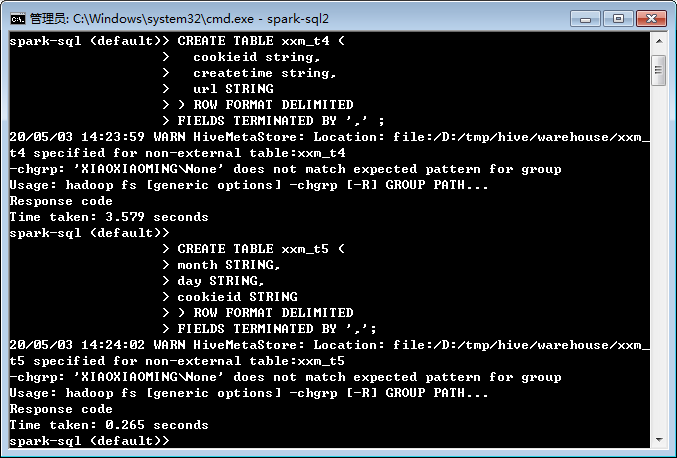
导入数据:
由于我配置的数据存储路径都是本地文件系统,未使用hdfs文件系统,则直接将数据文件扔到存储表对应的目录即可,本文中的配置就是D:\tmp\hive\warehouse下面的子目录。
上述表涉及的数据可见:
http://mp.weixin.qq.com/mp/homepage?__biz=MzA4NzcxOTQ1NA==&hid=2&sn=24824d7bbf36edb89470e03efa2d1545&scene=18#wechat_redirect
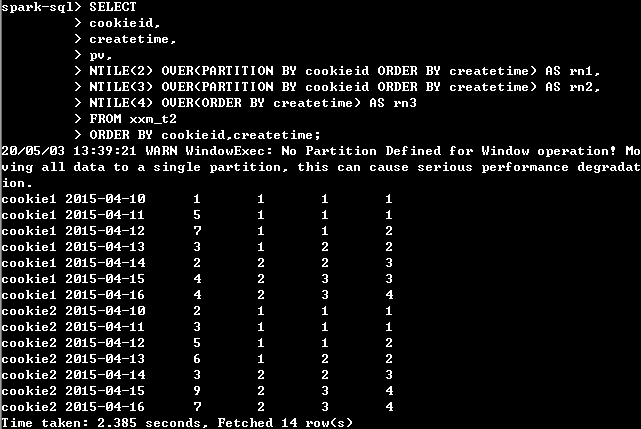
测试查询:

spark-sql访问已经被hive创建的表出现的问题
如果你是按照上面的方法,通过spark创建的hive表,是不会遇到这个坑的,但是如果上面的表你是通过hive先创建的,再次打开spark-sql就有可能会报如下错误:
Caused by: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS s
hould be writable. Current permissions are: rwx------
at org.apache.hadoop.hive.ql.session.SessionState.createRootHDFSDir(Sess
ionState.java:612)
at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(Sess
ionState.java:554)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.jav
a:508)
... 14 more
就是因为当前用户不具备对\tmp\hive的操作权限:
D:\>winutils ls \tmp\hive
drwx------ 1 BUILTIN\Administrators XIAOXIAOMING\None 0 May 4 2020 \tmp\hive
解决办法是把\tmp\hive目录的权限改为777:
D:\>winutils chmod 777 \tmp\hive
D:\>winutils ls \tmp\hive
drwxrwxrwx 1 BUILTIN\Administrators XIAOXIAOMING\None 0 May 4 2020 \tmp\hive
然后再次尝试即可顺利访问。
winutils更多的操作方法可直接敲winutils命令查看:
D:\>winutils
Usage: winutils [command] ...
Provide basic command line utilities for Hadoop on Windows.
The available commands and their usages are:
chmod Change file mode bits.
chown Change file owner.
groups List user groups.
hardlink Hard link operations.
ls List file information.
readlink Print the target of a symbolic link.
systeminfo System information.
task Task operations.
Usage: task create [OPTOINS] [TASKNAME] [COMMAND_LINE]
task createAsUser [TASKNAME] [USERNAME] [PIDFILE] [COMMAND_LINE]
Creates a new task jobobject with taskname as the user provided
task isAlive [TASKNAME]
Checks if task job object is alive
task kill [TASKNAME]
Kills task job object
task processList [TASKNAME]
service Service operations.
测试hive
spark-sql可以在不启动hdfs的情况下使用,但hive即使所有表都指定本地文件系统,使用前也必须先启动hdfs,否则出现如下错误:
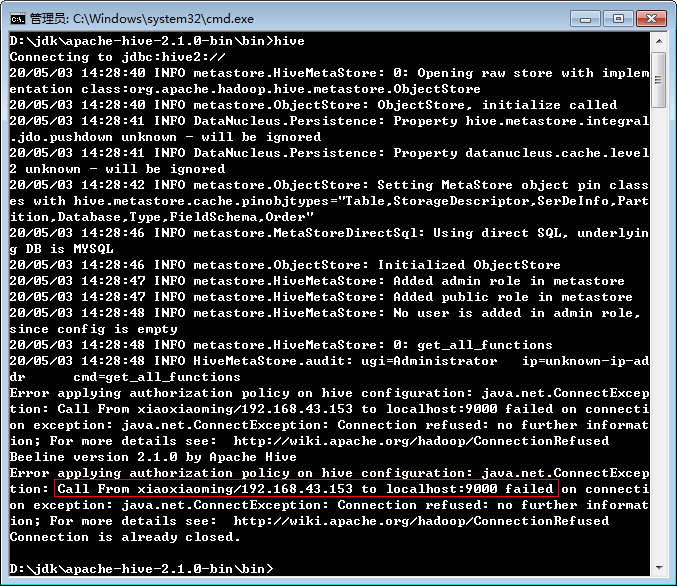
正确启动后:

查看一下hive表:

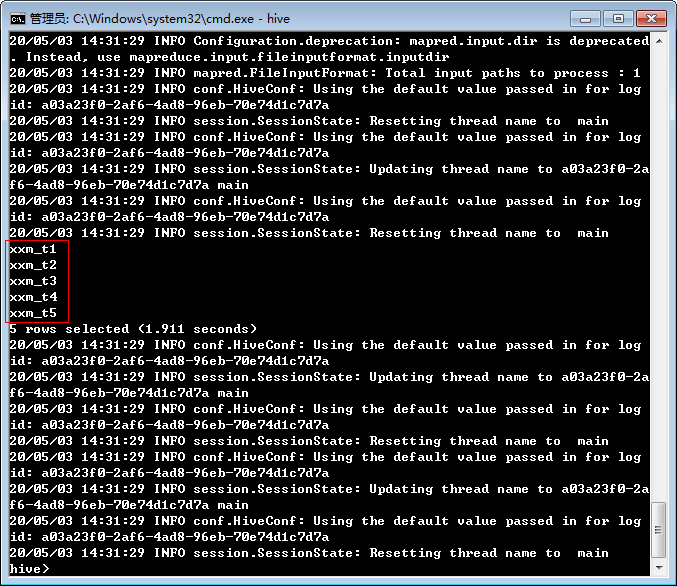
windows版的hive最大的缺点就是日志过多,另外是一些分区修护的命令不好使,但是常规的查询还是可以在hive上测试的。
本人已经多次测试修改hive的多个log4f配置文件,仍然没有生效,INFO日志依然打印的不停,如果有哪位大佬知道改那个配置可以取消这些烦人的日志,欢迎讨论。
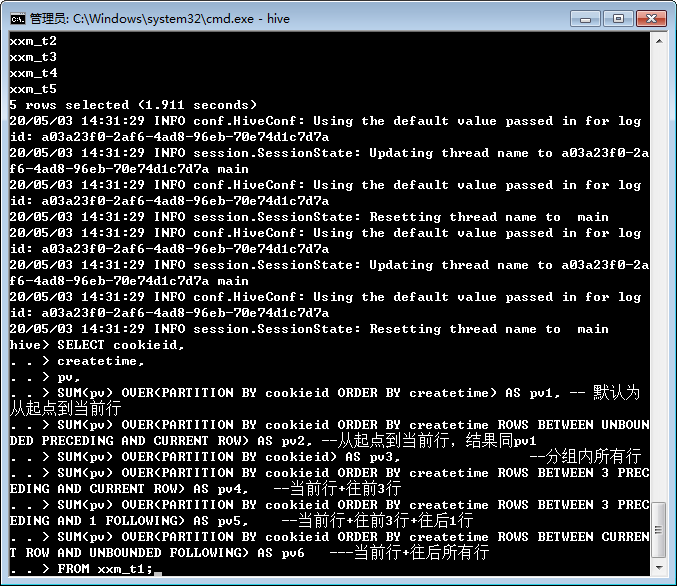
准备执行:
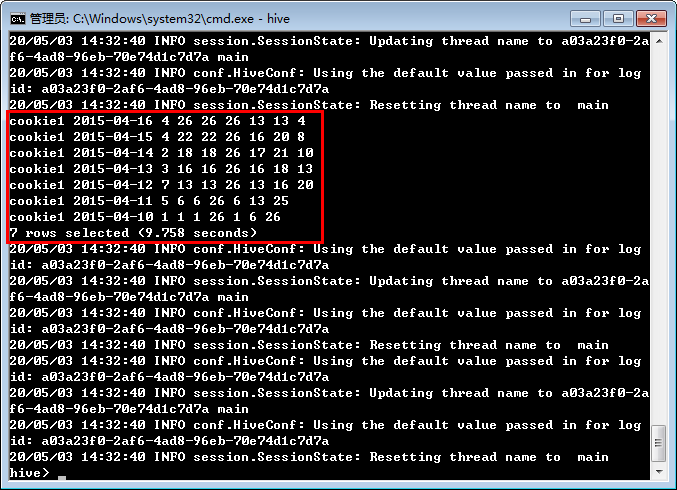
运行结果:
jupyter中使用pyspark
使用pyspark访问本地hive
首先安装与本地hadoop兼容的pyspark版本,跟前面的spark版本一致即可:
pip install pyspark==2.4.5
然后将hive-site.xml配置文件放入D:\Anaconda3\Lib\site-packages\pyspark\conf中
D:\Anaconda3\Lib\site-packages更换为命令pip show pyspark查看到的地址(Location)
(base) C:\Users\Administrator>pip show pyspark
Name: pyspark
Version: 2.4.5
Summary: Apache Spark Python API
Home-page: https://github.com/apache/spark/tree/master/python
Author: Spark Developers
Author-email: [email protected]
License: http://www.apache.org/licenses/LICENSE-2.0
Location: d:\anaconda3\lib\site-packages
Requires: py4j
Required-by:
再将mysql连接驱动例如mysql-connector-java-5.1.38-bin.jar放入D:\Anaconda3\Lib\site-packages\pyspark\jars中。
为了加速pip的下载,可以在~/pip中添加pip.ini文件,内容如下:
[global]
trusted-host=mirrors.aliyun.com
index-url=http://mirrors.aliyun.com/pypi/simple/
测试pyspark
先获取SparkSession和SparkContext对象:
from pyspark.sql import SparkSession
from pyspark.sql import Row
spark = SparkSession \
.builder \
.appName("Python Spark SQL Hive integration example") \
.enableHiveSupport() \
.getOrCreate()
sc = spark.sparkContext
spark

测试一下文本读取,先获取自己所在目录下所有文件的行数:
textFile = spark.read.text(".")
textFile.count()
5031
获取第一条数据:
textFile.first()
Row(value='Sun May 03 06:58:24 CST 2020 Thread[Thread-4,5,main] Cleanup action starting')
测试一下sql,先获取存在的表:
spark.sql("show tables").show()
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| default| xxm_t1| false|
| default| xxm_t2| false|
| default| xxm_t3| false|
| default| xxm_t4| false|
| default| xxm_t5| false|
+--------+---------+-----------+
顺利访问到前面创建的表。
测试窗口函数:
sql="""
SELECT cookieid,
createtime,
pv,
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime) AS pv1, -- 默认为从起点到当前行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS pv2, --从起点到当前行,结果同pv1
SUM(pv) OVER(PARTITION BY cookieid) AS pv3, --分组内所有行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv4, --当前行+往前3行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) AS pv5, --当前行+往前3行+往后1行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS pv6 ---当前行+往后所有行
FROM xxm_t1
"""
spark.sql(sql).show()
+--------+----------+---+---+---+---+---+---+---+
|cookieid|createtime| pv|pv1|pv2|pv3|pv4|pv5|pv6|
+--------+----------+---+---+---+---+---+---+---+
| cookie1|2015-04-10| 1| 1| 1| 26| 1| 6| 26|
| cookie1|2015-04-11| 5| 6| 6| 26| 6| 13| 25|
| cookie1|2015-04-12| 7| 13| 13| 26| 13| 16| 20|
| cookie1|2015-04-13| 3| 16| 16| 26| 16| 18| 13|
| cookie1|2015-04-14| 2| 18| 18| 26| 17| 21| 10|
| cookie1|2015-04-15| 4| 22| 22| 26| 16| 20| 8|
| cookie1|2015-04-16| 4| 26| 26| 26| 13| 13| 4|
+--------+----------+---+---+---+---+---+---+---+
顺利执行。
关于sparksql的函数可参考:http://spark.apache.org/docs/latest/api/sql/index.html
当然sparksql对hive的函数几乎全部都支持,只看hive的函数也可以。
测试一下机器学习:
from pyspark.mllib.linalg import Matrices, Vectors
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.stat import Statistics
vec = Vectors.dense(0.1, 0.15, 0.2, 0.3, 0.25) # a vector composed of the frequencies of events
# compute the goodness of fit. If a second vector to test against
# is not supplied as a parameter, the test runs against a uniform distribution.
goodnessOfFitTestResult = Statistics.chiSqTest(vec)
# summary of the test including the p-value, degrees of freedom,
# test statistic, the method used, and the null hypothesis.
print("%s\n" % goodnessOfFitTestResult)
mat = Matrices.dense(3, 2, [1.0, 3.0, 5.0, 2.0, 4.0, 6.0]) # a contingency matrix
# conduct Pearson's independence test on the input contingency matrix
independenceTestResult = Statistics.chiSqTest(mat)
# summary of the test including the p-value, degrees of freedom,
# test statistic, the method used, and the null hypothesis.
print("%s\n" % independenceTestResult)
obs = sc.parallelize(
[LabeledPoint(1.0, [1.0, 0.0, 3.0]),
LabeledPoint(1.0, [1.0, 2.0, 0.0]),
LabeledPoint(1.0, [-1.0, 0.0, -0.5])]
) # LabeledPoint(label, feature)
# The contingency table is constructed from an RDD of LabeledPoint and used to conduct
# the independence test. Returns an array containing the ChiSquaredTestResult for every feature
# against the label.
featureTestResults = Statistics.chiSqTest(obs)
for i, result in enumerate(featureTestResults):
print("Column %d:\n%s" % (i + 1, result))
Chi squared test summary:
method: pearson
degrees of freedom = 4
statistic = 0.12499999999999999
pValue = 0.998126379239318
No presumption against null hypothesis: observed follows the same distribution as expected..
Chi squared test summary:
method: pearson
degrees of freedom = 2
statistic = 0.14141414141414144
pValue = 0.931734784568187
No presumption against null hypothesis: the occurrence of the outcomes is statistically independent..
Column 1:
Chi squared test summary:
method: pearson
degrees of freedom = 0
statistic = 0.0
pValue = 1.0
No presumption against null hypothesis: the occurrence of the outcomes is statistically independent..
Column 2:
Chi squared test summary:
method: pearson
degrees of freedom = 0
statistic = 0.0
pValue = 1.0
No presumption against null hypothesis: the occurrence of the outcomes is statistically independent..
Column 3:
Chi squared test summary:
method: pearson
degrees of freedom = 0
statistic = 0.0
pValue = 1.0
No presumption against null hypothesis: the occurrence of the outcomes is statistically independent..
执行后UI界面的变化: