PyTorch图像分类
目录
一、torch和torchvision
1、torchvision.datasets
2、torchvision.models
3、torchvision.transforms
4、torchvision.utils
二、MNIST手写数字识别
1、获取MNIST训练集和测试集
2、数据装载
3、数据预览
4、构建卷积神经网络模型
5、对模型进行训练和参数优化
6、对训练模型进行保存和加载
7、MNIST手写数字识别完整代码
三、CIFAR10图像分类
1、CIFAR10数据集介绍
2、CIFAR10图像分类实现
3、在GPU上跑神经网络
一、torch和torchvision
PyTorch 中有两个核心的包,分别是 torch 和 torchvision。
torch.nn 包提供了很多与实现神经网络中的具体功能相关的类,torch.optim包中提供了非常多的可实现参数自动优化的类,torch.autograd实现自动梯度的功能等。
torchvision 包含了目前流行的数据集,模型结构和常用的图片转换工具,它的主要功能是实现数据的处理、导入和预览等,所以如果需要对计算机视觉的相关问题进行处理,就可以借用在torchvision包中提供的大量的类来完成相应的工作。
1、torchvision.datasets
torchvision.datasets 中包含以下数据集:MNIST,COCO,LSUN Classification,ImageFolder,Imagenet-12,CIFAR10 and CIFAR100,STL10等。
2、torchvision.models
torchvision.models 模块的子模块中包含以下模型结构:AlexNet,VGG,ResNet,SqueezeNet,DenseNet
3、torchvision.transforms
(1)torchvision.transforms.Compose(transforms)
torchvision.transforms.Compose 类看作是一种容器,它能够同时对多种数据变换进行组合。传入的参数是一个列表,列表中的元素就是对载入的数据进行的各种变换操作。
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5,0.5,0.5],
std=[0.5,0.5,0.5])])在 torchvision.transforms.Compose 类中只是用了一个类型的转换变化transfroms.ToTensor和一个数据标准化变换transforms.Normalize。这里使用的是标准化变换也叫标准差变换法,这种方法需要使用原始数据的均值(Mean)和标准差(Standard Deviation)来进行数据的标准化,在经过标准化变换之后,数据全部符合均值为0,标准差为1的标准正态分布。
(2)torchvision.transforms.Resize
用于对载入的图片数据按我们需求的大小进行缩放。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h ,w )的序列,其中,h 代表高度,w 代表宽度,但是如果使用的是一个整型数据,那么表示缩放的宽度和高度都是这个整型数据的值。
(3)torchvision.transforms.Scale
用于对载入的图片数据按我们需求的大小进行缩放,用法和 torchvision.transforms.Resize 类似。
(4)torchvision.transforms.CenterCrop
用于对载入的图片以图片中心为参考点,按我们需要的大小进行裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h ,w )的元组序列。
(5)torchvision.transforms.RandomCrop
用于对载入的图片按我们需要的大小进行随机裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h ,w )的元组序列。
(6)torchvision.transforms.RandomHorizontalFlip
用于对载入的图片按随机概率进行水平翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值0.5。
(7)torchvision.transforms.RandomVerticalFlip
用于对载入的图片按随机概率进行垂直翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值0.5。
(8)torchvision.transforms.ToTensor
用于对载入的图片数据进行类型转换,将之前构成PIL图片的数据转换成Tensor数据类型的变量,即将一个取值范围是[0, 255]的PIL.Image或shape为(H, W, C)的numpy.ndarray,转换成形状为[C, H, W],取值范围是[0, 1.0]的torch.FloatTensor,让PyTorch能够对其进行计算和处理。
(9) torchvision.transforms.ToPILImage
用于将Tensor变量的数据转换成PIL图片数据,主要是为了方便图片内容的显示。
(10)torchvision.transforms.RandomSizedCrop(size, interpolation=2)
先随机切,再resize成给定size大小。
(11)torchvision.transforms.Pad(padding, fill=0)
给所有边用给定的值填充。padding:要填充多少像素。
(12)torchvision.transforms.Normalize(mean, std)
给定均值与方差,正则化,即Normalized_image=(image-mean)/std
(13)通用变换:使用lambda作为转换器,transforms.Lambda(lambda)
4、torchvision.utils
(1)torchvision.utils.make_grid
utils.make_grid(tensor, nrow=8, padding=2, normalize=False, range=None, scale_each=False), 给定4D-mini-batch Tensor,形状为(B*C*H*W),或者一个a list of image,做成一个size为(B / nrow, nrow)的子图集,其中参数:normalize=True, 对图像像素归一化,range=(min, max),min和max是数字,则min, max用来规范化image,scale_each=True, 每个图片独立规范化。
(2)torchvision.utils.save_image
utils.save_image(tensor, filename, nrow=8, padding=2, normalize=False, range=None, scale_each=False),将给定的Tensor保存成image文件,如果是mini-batch tensor,就用make-grid做成子图集再保存。
二、MNIST手写数字识别
1、获取MNIST训练集和测试集
# 对数据进行载入及有相应变换,将Compose看成一种容器,他能对多种数据变换进行组合
# 传入的参数是一个列表,列表中的元素就是对载入的数据进行的各种变换操作(只有一个颜色通道)
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5,],std=[0.5,])])
# 获取MNIST训练集和测试集
data_train=datasets.MNIST(root='data/',transform=transform,train=True,download=True)
data_test=datasets.MNIST(root='data/',transform=transform,train=False)其中,root 用于指定数据集在下载之后的存放路径;transform用于指定导入数据集时需要对数据进行哪种变换操作,要提前定义这些变换操作;train用于指定在数据集下载完成后需要载入哪部分数据,如果设置为True,则说明载入的是该数据集的训练集部分;如果设置为False,则说明载入的是该数据集的测试集部分。
2、数据装载
在数据下载完成并且载入后,我们还需要对数据进行装载。我们可以将数据的载入理解为对图片的处理,在处理完成后,我们就需要将这些图片打包好送给我们的模型进行训练了,而装载就是这个打包的过程。在装载时通过batch_size的值来确认每个包的大小,通过shuffle的值来确认是否在装载的过程中打乱图片的顺序。
对数据的装载使用的是torch.utils.data.DataLoader类,类中的dataset参数用于指定我们载入的数据集名称,batch_size参数设置了每个包中的图片数据个数,代码中的值是64,所以在每个包中会包含64张图片。将shuffle参数设置为True,在装载的过程会将数据随机打乱顺序并进行打包。
# 数据装载
data_loader_train=torch.utils.data.DataLoader(dataset=data_train,batch_size=64,shuffle=True)
data_loader_test = torch.utils.data.DataLoader(dataset =data_test,batch_size = 64,shuffle = True)
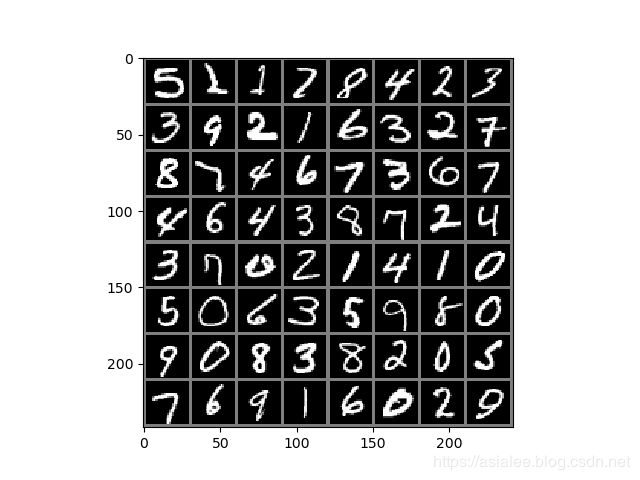
3、数据预览
#数据预览和图片显示
images,labels=next(iter(data_loader_train))
img=torchvision.utils.make_grid(images)
img=img.numpy().transpose(1,2,0)
std=[0.5,0.5,0.5]
mean=[0.5,0.5,0.5]
img=img*std+mean
print([labels[i] for i in range(16)])
plt.imshow(img)
plt.show()使用 iter 和 next 来获取一个批次的图片数据和其对应的图片标签;
使用 torchvision.utils.make_grid 类方法将一个批次的图片构造成网格模式。需要传递给它的参数就是一个批次的装载数据,每个批次的装载数据都是4维的,维度的构成从前往后分别为batch_size、channel、height和weight,分别对应一个批次中的数据个数、每张图片的色彩通道数、每张图片的高度和宽度。在通过torchvision.utils.make_grid之后,图片的维度变成了(channel,height,weight),这个批次的图片全部被整合到了一起,所以在这个维度中对应的值也和之前不一样了,但是色彩通道数保持不变。
使用 Matplotlib 将数据显示成正常的图片形式,则使用的数据首先必须是数组,其次这个数组的维度必须是 (height,weight,channel),即色彩通道数在最后面。所以我们要通过numpy和transpose完成原始数据类型的转换和数据维度的交换,这样才能够使用Matplotlib绘制出正确的图像。
打印输出了这个批次中的数据的全部标签,如下:
[tensor(5), tensor(2), tensor(1), tensor(7), tensor(8), tensor(4), tensor(2), tensor(3), tensor(3), tensor(9), tensor(2), tensor(1), tensor(6), tensor(3), tensor(2), tensor(7), tensor(8), tensor(7), tensor(4), tensor(6), tensor(7), tensor(3), tensor(6), tensor(7), tensor(4), tensor(6), tensor(4), tensor(3), tensor(8), tensor(7), tensor(2), tensor(4), tensor(3), tensor(7), tensor(0), tensor(2), tensor(1), tensor(4), tensor(1), tensor(0), tensor(5), tensor(0), tensor(6), tensor(3), tensor(5), tensor(9), tensor(8), tensor(0), tensor(9), tensor(0), tensor(8), tensor(3), tensor(8), tensor(2), tensor(0), tensor(5), tensor(7), tensor(6), tensor(9), tensor(1), tensor(6), tensor(0), tensor(2), tensor(9)]
对这个批次中的所有图片数据进行显示,如下:
4、构建卷积神经网络模型
CNN一般结构如下:
- 输入层:用于数据输入
- 卷积层:使用卷积核进行特征提取和特征映射
- 激励层:由于卷积也是一种线性运算,因此需要增加非线性映射
- 池化层:进行下采样,对特征图稀疏处理,减少特征信息的损失
- 输出层:用于输出结果
- CNN模型具体结构:卷积层,正则化层,激励层,最大池化层,全连接层
# 构建卷积神经网络模型
class CNN_Model(torch.nn.Module):
def __init__(self):
super(CNN_Model, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 64, kernel_size=3, stride=1, padding=1),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2,kernel_size=2))
self.conv2=torch.nn.Sequential(
torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
torch.nn.BatchNorm2d(128),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2, kernel_size=2))
self.dense = torch.nn.Sequential(
torch.nn.Linear(7 * 7 * 128, 1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024, 10))
# 前向传播
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x = x2.view(-1, 7 * 7 * 128)
x = self.dense(x)
return x
torch.nn.Conv2d:用于搭建卷积神经网络的卷积层,主要的输入参数有输入通道数、输出通道数、卷积核大小、卷积核移动步长和Paddingde值。其中,输入通道数的数据类型是整型,用于确定输入数据的层数;输出通道数的数据类型也是整型,用于确定输出数据的层数;卷积核大小的数据类型是整型,用于确定卷积核的大小;卷积核移动步长的数据类型是整型,用于确定卷积核每次滑动的步长;Paddingde 的数据类型是整型,值为0时表示不进行边界像素的填充,如果值大于0,那么增加数字所对应的边界像素层数。
torch.nn.MaxPool2d:用于实现卷积神经网络中的最大池化层,主要的输入参数是池化窗口大小、池化窗口移动步长和Padding的值。同样,池化窗口大小的数据类型是整型,用于确定池化窗口的大小。池化窗口步长的数据类型也是整型,用于确定池化窗口每次移动的步长。Padding的值和在torch.nn.Conv2d中定义的Paddingde值的用法和意义是一样的。
torch.nn.Dropout:用于防止卷积神经网络在训练的过程中发生过拟合,其工作原理简单来说就是在模型训练的过程中,以一定的随机概率将卷积神经网络模型的部分参数归零,以达到减少相邻两层神经连接的目的。可以对随机概率值的大小进行设置,如果不足任何设置,我们就使用默认的概率值0.5。
x=x2.view(-1,7 * 7 * 128):对参数实现扁平化,因为之后紧接着的就是全连接层,所以如果不进行扁平化,则全连接层的实际输出的参数维度和其定义输入的维度将不匹配,程序将会报错。
5、对模型进行训练和参数优化
# 对模型进行训练和参数优化
cnn_model = CNN_Model()
loss_func = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn_model.parameters(),lr=learning_rate)
n_epochs = 5
for epoch in range(n_epochs):
running_loss = 0.0
running_correct = 0.0
print("Epoch {}/{}".format(epoch, n_epochs))
for data in data_loader_train:
X_train, y_train = data
X_train, y_train = Variable(X_train), Variable(y_train)
outputs = cnn_model(X_train)
_, pred = torch.max(outputs.data, 1)
optimizer.zero_grad()
loss = loss_func(outputs, y_train)
loss.backward()
optimizer.step()
running_loss += loss.item()
running_correct += torch.sum(pred == y_train.data)
testing_correct = 0.0
for data in data_loader_test:
X_test, y_test = data
X_test, y_test = Variable(X_test), Variable(y_test)
outputs = cnn_model(X_test)
_, pred = torch.max(outputs, 1) #返回每一行中最大值的那个元素,且返回其索引
testing_correct += torch.sum(pred == y_test.data)
# print(testing_correct)
print("Loss is :{:.4f},Train Accuracy is:{:.4f}%,Test Accuracy is:{:.4f}%".format(
running_loss / len(data_train), 100 * running_correct / len(data_train),
100 * testing_correct / len(data_test)))6、对训练模型进行保存和加载
# 保存模型
torch.save(cnn_model, 'data/cnn_model.pt')
# 加载模型
cnn_model=torch.load('data/cnn_model.pt')
cnn_model.eval()7、MNIST手写数字识别完整代码
import torch
import torchvision
import matplotlib.pyplot as plt
from torchvision import datasets
from torchvision import transforms
from torch.autograd import Variable
# 参数设置
num_epochs = 10
batch_size = 64
learning_rate = 0.001
# 将数据处理成Variable, 如果有GPU, 可以转成cuda形式
def get_variable(x):
x = Variable(x)
return x.cuda() if torch.cuda.is_available() else x
# 对数据进行载入及有相应变换,将Compose看成一种容器,他能对多种数据变换进行组合
# 传入的参数是一个列表,列表中的元素就是对载入的数据进行的各种变换操作(只有一个颜色通道)
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5,],std=[0.5,])])
# 获取MNIST训练集和测试集
data_train=datasets.MNIST(root='data/',transform=transform,train=True,download=True)
data_test=datasets.MNIST(root='data/',transform=transform,train=False)
# 数据装载
data_loader_train=torch.utils.data.DataLoader(dataset=data_train,batch_size=batch_size,shuffle=True)
data_loader_test = torch.utils.data.DataLoader(dataset =data_test,batch_size = batch_size,shuffle = True)
#数据预览和图片显示
images,labels=next(iter(data_loader_train))
img=torchvision.utils.make_grid(images)
img=img.numpy().transpose(1,2,0)
std=[0.5,0.5,0.5]
mean=[0.5,0.5,0.5]
img=img*std+mean
print([labels[i] for i in range(64)])
plt.imshow(img)
plt.show()
# 构建卷积神经网络模型
class CNN_Model(torch.nn.Module):
def __init__(self):
super(CNN_Model, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 64, kernel_size=3, stride=1, padding=1),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2,kernel_size=2))
self.conv2=torch.nn.Sequential(
torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
torch.nn.BatchNorm2d(128),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2, kernel_size=2))
self.dense = torch.nn.Sequential(
torch.nn.Linear(7 * 7 * 128, 1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024, 10))
# 前向传播
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x = x2.view(-1, 7 * 7 * 128)
x = self.dense(x)
return x
# 对模型进行训练和参数优化
cnn_model = CNN_Model()
# 将所有的模型参数移动到GPU上
if torch.cuda.is_available():
cnn_model = cnn_model.cuda()
loss_func = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn_model.parameters(),lr=learning_rate)
for epoch in range(num_epochs):
running_loss = 0.0
running_correct = 0.0
print("Epoch {}/{}".format(epoch, num_epochs))
for data in data_loader_train:
X_train, y_train = data
X_train, y_train = get_variable(X_train),get_variable(y_train)
outputs = cnn_model(X_train)
_, pred = torch.max(outputs.data, 1)
optimizer.zero_grad()
loss = loss_func(outputs, y_train)
loss.backward()
optimizer.step()
running_loss += loss.item()
running_correct += torch.sum(pred == y_train.data)
testing_correct = 0.0
for data in data_loader_test:
X_test, y_test = data
X_test, y_test = get_variable(X_test),get_variable(y_test)
outputs = cnn_model(X_test)
_, pred = torch.max(outputs, 1) #返回每一行中最大值的那个元素,且返回其索引
testing_correct += torch.sum(pred == y_test.data)
# print(testing_correct)
print("Loss is :{:.4f},Train Accuracy is:{:.4f}%,Test Accuracy is:{:.4f}%".format(
running_loss / len(data_train), 100 * running_correct / len(data_train),
100 * testing_correct / len(data_test)))
# 保存模型
torch.save(cnn_model, 'data/cnn_model.pt')
# 加载模型
cnn_model=torch.load('data/cnn_model.pt')
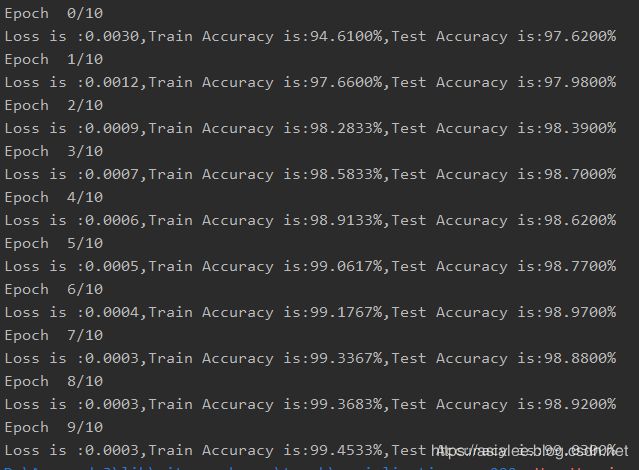
cnn_model.eval()运行结果如下:
三、CIFAR10图像分类
1、CIFAR10数据集介绍
CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练图片和 10000 张测试图片。与 MNIST 数据集相比, CIFAR-10 具有以下不同点:
-
CIFAR-10 是 3 通道的彩色 RGB 图像,而 MNIST 是灰度图像。
-
CIFAR-10 的图片尺寸为 32×32, 而 MNIST 的图片尺寸为 28×28,比 MNIST 稍大。
-
相比于手写字符, CIFAR-10 含有的是现实世界中真实的物体,不仅噪声很大,而且物体的比例、 特征都不尽相同,这为识别带来很大困难。
2、CIFAR10图像分类实现
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
#参数设置
num_epochs = 15
batch_size = 64
learning_rate = 0.001
# 构建CNN模型
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(64, 128, 5)
self.fc1 = nn.Linear(128* 5 * 5, 1024)
self.fc2 = nn.Linear(1024, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 128 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
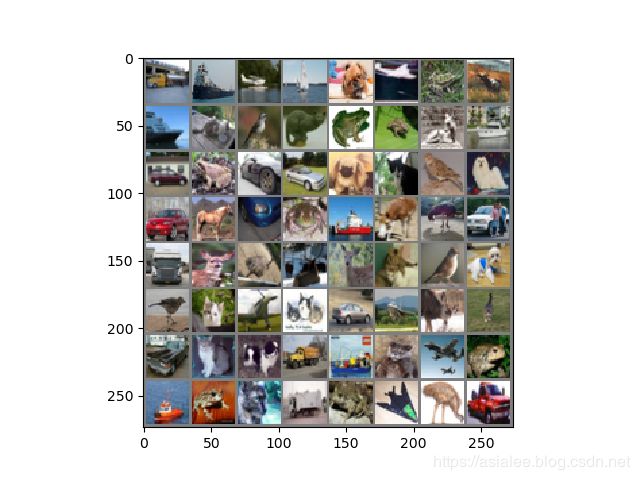
# 图片显示
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量Tensors
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 获取CIFAR10训练集和测试集
trainset=torchvision.datasets.CIFAR10(root='data/',train=True,download=True,transform=transform)
testset=torchvision.datasets.CIFAR10(root='data/',train=False,download=True,transform=transform)
# CIFAR10训练集和测试集装载
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,shuffle=True, num_workers=0)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,shuffle=False, num_workers=0)
# 图片类别
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 图片显示
images,labels=next(iter(trainloader))
imshow(torchvision.utils.make_grid(images))
# 定义损失函数和优化器
cnn_model=CNNNet()
criterion=nn.CrossEntropyLoss()
optimizer=optim.SGD(cnn_model.parameters(),lr=learning_rate,momentum=0.9)
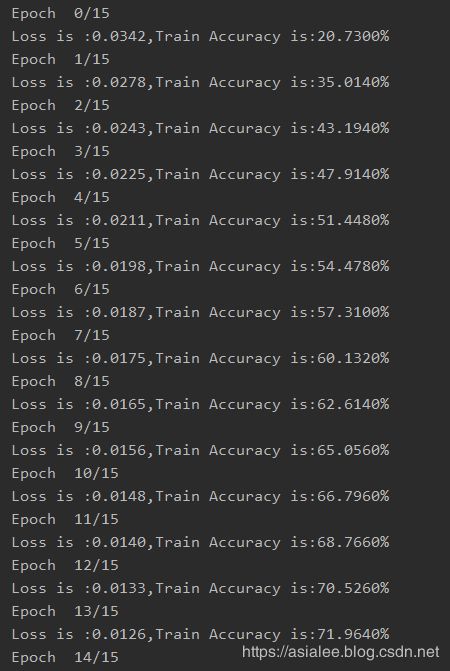
# 训练模型
for epoch in range(num_epochs):
running_loss=0.00
running_correct=0.0
print("Epoch {}/{}".format(epoch, num_epochs))
for i,data in enumerate(trainloader,0):
inputs,labels=data
optimizer.zero_grad()
outputs=cnn_model(inputs)
loss=criterion(outputs,labels)
loss.backward()
optimizer.step()
running_loss+=loss.item()
_, pred = torch.max(outputs.data, 1)
running_correct += torch.sum(pred == labels.data)
print("Loss is :{:.4f},Train Accuracy is:{:.4f}%".format(running_loss / len(trainset), 100 * running_correct / len(trainset)))
# 保存训练好的模型
torch.save(cnn_model, 'data/cnn_model.pt')
# 加载训练好的模型
cnn_model=torch.load('data/cnn_model.pt')
cnn_model.eval()
#使用测试集对模型进行评估
correct=0.0
total=0.0
with torch.no_grad(): # 为了使下面的计算图不占用内存
for data in testloader:
images, labels = data
outputs = cnn_model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
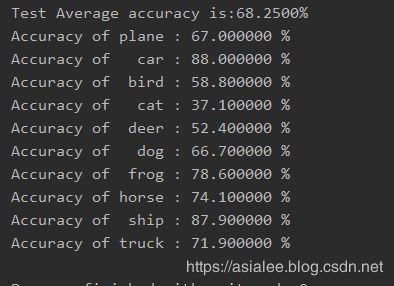
print("Test Average accuracy is:{:.4f}%".format(100 * correct / total))
# 求出每个类别的准确率
class_correct=list(0. for i in range(10))
class_total=list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images,labels=data
outputs=cnn_model(images)
_,predicted=torch.max(outputs,1)
c=(predicted==labels).squeeze()
try:
for i in range(batch_size):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
except IndexError:
continue
for i in range(10):
print('Accuracy of %5s : %4f %%' % (classes[i], 100 * class_correct[i] / class_total[i]))图片显示结果:
模型训练结果:
测试集平均准确率和每个类别的准确率:
3、在GPU上跑神经网络
device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
# 递归地遍历所有模块,并将它们的参数和缓冲器转换为CUDA张量
cnn_model.to(device)
# 必须在每一个步骤向GPU发送输入和目标
inputs,labels=inputs.to(device),labels.to(device)