问题描述
这个问题来自于SemEval-2015Task3: Answer Selection in Community Question Answering.
简单的说就是从一堆问题和答案中找出他们之间的相关性。
这个Task包含两个Subtasks:
1.给定一个问题和一些答案,将答案进行为3类:good/potential/bad。
2.给定一个判定问题(Yes/No/Unsure)和一些答案,判定该问题是Yes/No/Unsure。
这里主要讨论subtask1。
详见:http://alt.qcri.org/semeval2015/task3/
实现框架
整体实现框架如下图所示:

简单来说,分为一下几个步骤:
1.预处理:通过一些基本的“词”级别的处理,为特征提取准备规范数据。
2.特征提取:通过对原始数据和预处理后的数据进行分析,并基于一定的假设,确定选取特征,提取特征。
3.模型构建:根据问题描述,选择学习模型,构建训练集,训练模型。
4.实验评估:构建测试集,对比各模型效果。
具体实现框架如下图所示:
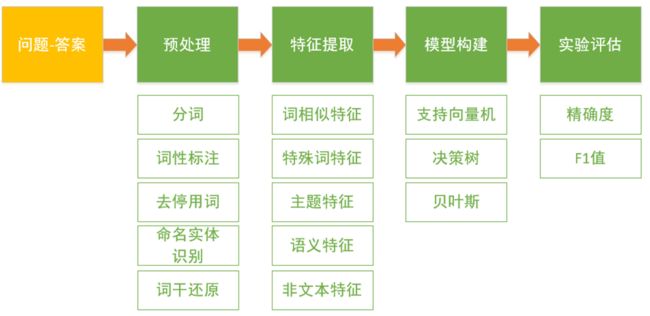
接下来详细描述整个过程。
预处理
个人认为,特征选择在实现上发生在预处理之后,但实则发生在预处理前后。
根据上述问题描述,和自己的先验知识,先对该问题做了一定的假设:
假设问题和答案是有相关性的。
假设问题和好的答案相关性更大,和不好的答案相关性更小。
假设问题和各种类别(good/potential/bad)的答案在“词”的特征上,是有一定规律的。
假设问题和各种类别(good/potential/bad)的答案在语义上,是有一定规律的。
特征选择
词相似特征
1.Word cosine similarity:我们假设问题和好的答案词相似,所以设计回答和问题的词的相似度特征。构建词典,以词典顺序作为向顺序,tfidf作为权重,统计每个回答和问题的空间向量,然后计算对应的问题和回答之间的余弦相似度。
2.NE cosine similarity:关键词通常是名词实体,我们假设问题和好的回答的关键词相近,所以我们构建了问题与回答之间的名词实体余弦。识别名词实体,构建名词实体字典。以字典为顺序,tfidf为权重,构建每个问题和答案的名词实体向量,并计算相应的余弦值。
特殊词特征
1.Special symbol feature:我们将训练数据各个类别的答案所出现的符号经过统计分析发现,有些特殊符号比如“>..<,!:(,:(,:-(”只出现在了bad类别的答案中,而“>,<”只出现在good类别的答案中,因此我们将此作为一维特征。定义:3表示出现good类符号;2表示不出现good和bad类符号;1表示出现bad类符号。
2.Bad words feature:我们假设某些词倾向出现在坏的答案里或者好的答案里,根据经验,这样的特征对识别坏的词有帮助。所以我们统计仅出现在bad的回答的词。问题中若是出现bad的词,则这维特征记为1,否则记为0.
主题特征
1.Topic feature:我们假设问题的主题和回答的主题是相似的,所以这维特征计算问题和答案的主题相似度分数。我们借助gensim工具的LDA模型来训练主题模型。
我们训练10个主题的主题模型,然后拿到每条答案或者问题的主题向量(每条记录属于每个主题的分数)。拿到每条记录的主题向量之后,计算对应的问题和答案的余弦相似度。从而得到问题与答案的主题相似度特征。
gensim的LDA方法详见:https://radimrehurek.com/gensim/models/ldamodel.html
语义特征
1.Word alignment feature:这一维特征是通过Meteor工具来计算得到的,Meteor工具是用来评估两句话在翻译层面上的相似度。我们假定问题和对应的好的答案之间应该具有更高的相似度。因此我们将Meteor工具计算出来的问题与答案之间的score做为一维特征。
Meteor详见:http://www.cs.cmu.edu/~alavie/METEOR/
2.word2vector feature:我们假设问题和回答所用的词在语义上是相似的,与问题的词越是相似的越有可能是好的回答。我们借助gensim具来训练word2vec特征。这样我们就得到每个词的词向量。然后借助以下公式拿到对应问题与答案的词向相似度得分。
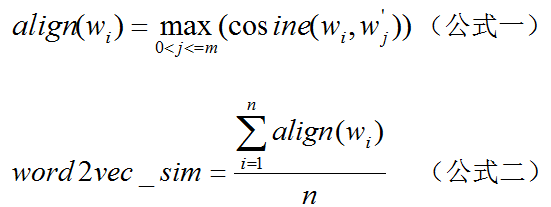
其中wi是问题的第1个词,wj是回答的第j个词。n是问题的词的个数,m是回答的词的个数。gensim的word2vec方法详见:https://radimrehurek.com/gensim/models/word2vec.html
非文本特征
1.QA author feature:通过分析训练数据发现,如果答案和问题来自同一个用户,在很多情况下不是一个好的答案,因此我们将此作为一维特征。定义:0表示答案和问题来自不同用户;1表示答案和问题来自同一用户。
2.User posts feature:这个特征和知乎的大V原理有点类似,我们认为,一个用户回答的问题越多,他(她)的答案越有可能是一个好的答案。因此我们将用户提问和回答问题的数量作为一维特征。
模型训练
我们采用了一下三种模型,均采用sklearn工具包的默认方法,未设置任何超参数。
1.SVM
2.朴素贝叶斯
3.决策树
效果评估
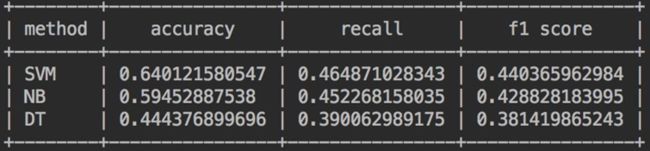
训练集:train,测试集:dev
训练集:train,测试集:test
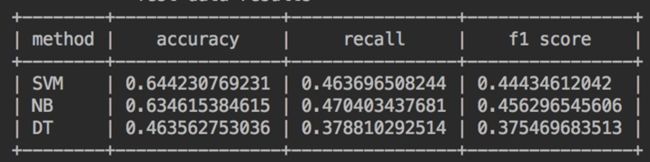
训练集:train+dev,测试集:test
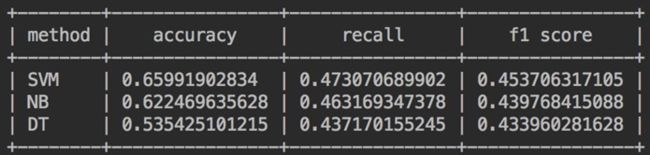
效果一般,正在进行后续调参改进,敬请期待文章更新。
数据分布
TRAINING:
QUESTIONS:
TOTAL: 2,600
GENERAL: 2,376 (91.38%)
YES_NO: 224 (8.62%)
COMMENTS:
TOTAL: 16,541
MIN: 1
MAX: 143
AVG: 6.36
CGOLD VALUES:
Good: 8,069 (48.78%)
Bad: 2,981 (18.02%)
Potential: 1,659 (10.03%)
Dialogue: 3,755 (22.70%)
Not English: 74 ( 0.45%)
Other: 3 ( 0.02%)
CGOLD_YN COMMENT VALUES (excluding"Not Applicable"):
yes: 346 (43.52%)
no: 236 (29.69%)
unsure: 213 (26.79%)
QGOLD_YN VALUES (excluding "NotApplicable"):
yes: 87 (38.84%)
no: 47 (20.98%)
unsure: 90 (40.18%)
DEVELOPMENT:
QUESTIONS:
TOTAL: 300
GENERAL: 266 (88.67%)
YES_NO: 34 (11.33%)
COMMENTS:
TOTAL: 1645
MIN: 1
MAX: 32
AVG: 5.48
CGOLD VALUES:
Good: 875 (53.19%)
Bad: 269 (16.35%)
Potential: 187 (11.37%)
Dialogue: 312 (18.97%)
Not English: 2 ( 0.12%)
Other: 0 ( 0.00%)
CGOLD_YN COMMENT VALUES (excluding"Not Applicable"):
yes: 62 (53.91%)
no: 32 (27.83%)
unsure: 21 (18.26%)
QGOLD_YN VALUES (excluding "NotApplicable"):
yes: 16 (47.06%)
no: 8 (23.53%)
unsure: 10 (29.41%)
test:
QUESTIONS:
TOTAL: 329
GENERAL: 300(91.19%)
YES_NO:29(8.81%)
COMMENTS:
TOTAL: 1976
MIN: 1
MAX: 66
AVG: 6.01
CGOLDVALUES:
TOTAL: 1976
Good: 997(50.46%)
Bad: 362(18.32%)
Potential: 167(8.45%)
Not English: 15(0.76%)
Other: 0(0.00%)
QGOLD_YNVALUES:
yes: 18(62.07%)
no: 4(13.79%)
unsure: 7(24.14%)
参考文献
[1]毛先领,李晓明.问答系统研究综述[J].计算机科学与探索, 2012, 6(3):193-207.
[2]Denkowski M, Lavie A. Meteor 1.3: automatic metric for reliable optimizationand evaluation of machine translation systems[C]// The Workshop on StatisticalMachine Translation. Association for Computational Linguistics, 2011:85-91.
[3]Quan H T, Tran V, Tu V, et al. JAIST: Combining multiple features for AnswerSelection in Community Question Answering[C] International Workshop on SemanticEvaluation. 2015:215-219.
[4]Matthew Hoffman, David M Blei, Francis Bach.Advancesin Neural Information Processing Systems.2010/1/2:856-864.
[5]MikolovT, Chen K, Corrado G, et al. Efficient Estimation of Word Representations inVector Space[J]. Computer Science, 2013.
[6]Goldberg Y, Levy O. word2vec Explained: deriving Mikolov et al.'s
negative-sampling word-embedding method[J]. Eprint Arxiv, 2014.