一.JML语言
定义
Java建模语言(JML)是一种行为接口规范语言,可用于指定Java模块的行为 。它结合了Eiffel的契约方法设计 和Larch 系列接口规范语言的基于模型的规范方法 。
理论基础
JML是契约式语言的一种具体表现形式。
契约(Contact):声明一个函数/方法的时候,对函数的输入和输出所具备的性质是有所期望和规定的。有时候这种性质会被我们明确的写出来,有时候会被我们忽略掉。这些期望和规定就是Contract。
而契约设计的核心便是断言(assertion) :永远为真的布尔型语句,如果不为真,则程序必然存在错误。
因此我们可以通过一些三段论形式的规格语言来限制方法,并通过其检验是否符合标准。
应用工具链情况
OpenJml
目前通过JML语言实现Java程序检验的工具便是OpenJml:
OpenJml是Java程序的程序验证工具,不是定理证明器或模型检查器本身。OpenJml将JML规范转换为SMT-LIB格式,并将Java + JML程序隐含的证明问题传递给后端SMT求解器。
本质
OpenJml实际上充当的为翻译官的角色,将JML规范转换为SMT-LIB格式,这在官网上链接的Z3求解器也可看出:
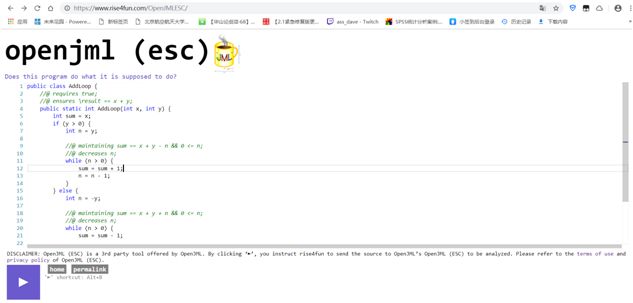
openjml官网求解界面: https://www.rise4fun.com/OpenJMLESC/
Z3求解器官网求解界面: https://rise4fun.com/Z3/tutorial/guide

目前OpenJML同样支持Eclipse与IDEA等主流Java编辑器,但两者的体验有所不同:
- IDEA的结果只有命令行输出,并没有得到官方的完全支持。
- Eclipse上的OpenJML可以轻松输出验证错误信息,提供问题代码高亮,提供全推导过程,甚至能够在代码中给出对有问题的代码的反例。
求解器支持
目前OpenJml支持主流的求解器:
CVC4:由斯坦福大学开发,目前持续更新
下载地址:http://cvc4.cs.stanford.edu/downloads/
Z3 :由Microsoft开发,但微软官网已经停止更新。(版本停滞在4.1)
GitHub持续更新地址:https://github.com/Z3Prover/z3
Yices:由斯坦福国际研究院开发。
下载地址:http://yices.csl.sri.com/
JMLUnitNG
可根据规格自动化生成测试样例,进行单元测试的JML测试工具
通常使用命令行或者编辑器内带Test插件完成测试
官网:http://insttech.secretninjaformalmethods.org/software/jmlunitng/
二.部署SMT Solver并验证方法
//TODO
三.部署JML UnitNG 并测试
由于在使用过程中遇到乱码文件,使用的HashMap等数据结构也不能很好识别。
自认为修改格式或数据结构,来符合测试所需,和本次实验目的不是特别符合。于是自写了规格简单实现path中的部分方法。实现代码如下所示:
package test;
public class testNG {
public int[] path;
public testNG(int num) {
path = new int[num];
}
//@ public normal_behaviour
//@ ensures \result == path.length;
public /*@ pure @*/ int size() {
return path.length;
}
/*@ public normal_behaviour
@ requires i < 10 && i >= 0 && num >= 0;
@ ensures path[i] == num;
*/
public void add(int i, int num) {
path[i] = num;
}
public static void main(String[] args) {
testNG ng = new testNG(5);
ng.add(3, 23);
ng.size();
}
}依次执行
$ java -jar jmlunitng.jar test/testNG.java
$ javac -cp jmlunitng.jar test/*.java
$ java -jar openjml.jar -rac test/testNG.java
$ java -cp jmlunitng.jar test.testNG_JML_Test
测试结果如下所示:
[TestNG] Running:
Command line suite
Passed: racEnabled()
Failed: <>.add(-2147483648, -2147483648)
Failed: <>.add(0, -2147483648)
Failed: <>.add(2147483647, -2147483648)
Failed: <>.add(-2147483648, 0)
Failed: <>.add(0, 0)
Failed: <>.add(2147483647, 0)
Failed: <>.add(-2147483648, 2147483647)
Failed: <>.add(0, 2147483647)
Failed: <>.add(2147483647, 2147483647)
Passed: <>.size()
Passed: static main(null)
Failed: constructor testNG(-2147483648)
Passed: constructor testNG(0)
Failed: constructor testNG(2147483647)
===============================================
Command line suite
Total tests run: 15, Failures: 11, Skips: 0
=============================================== 可以看出边缘数据超出了int型范围时或者为负数是,均无法通过测试,与我们的预期相符。
四.作业架构梳理及错误分析
第9次作业
结构图
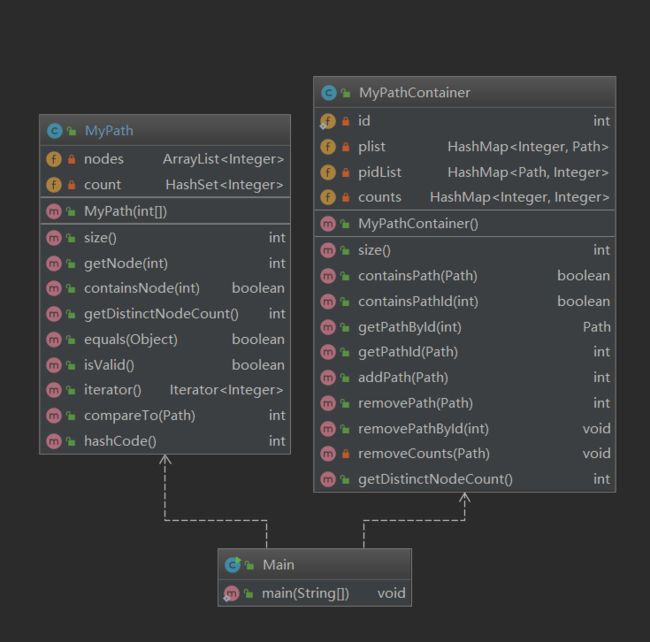
可以看出,第九次作业的架构非常简单,基本上完全是按照规格进行书写。
其中Path类中采用了ArrayList与Hashset来储存Path中的节点数据,其中ArrayList由于其有序性,对于获取指定编号的节点复杂度较低,而HashSet具有内部元素不能重复的特点,可以直接获取Path中不同节点的个数。
而PathContainer类中采用了
private HashMap plist;
private HashMap pidList;
private HashMap counts; 可以通过plist和pidList,实现Path与id中复杂度为1的互相转换。
而counts通过记录每条Path中的不同节点的出现次数,来记录整个容器中不同节点的总数。
bug出现及修改
由于之前作业中从未出现过超时错误,导致对于复杂度的关注度较低,只片面地追求了正确性,导致强测最后得分仅有50分。通过超时点分析,发现主要原因在于一开始并没有实现pidlist,而所有查找均通过pidpath实现,导致超时。
是的,我竟然没有在指导书上发现创建删除指令与查找指令的比例关系,导致没有认清占用时间最长的请求是查询。
通过将pidlist加入,并自己实现了path的hashcode和equals方法,将bug成功改正。
第10次作业
结构图

第二次作业中相较于第一次作业加入了自己的Node(节点类),殊不知这成为本次作业最大的败笔所在。
除了第一次代码被全部复用外,额外加入了以下两个数据结构:
private HashMap nodes;
private HashMap> distance; nodes通过节点的id找到Node类,并在Node类中记录该节点的度。
distance为存储距离的hashmap,三个Interger分别代表出发节点,目的节点以及距离。
距离采用Floyd算法,并利用无向图最短路矩阵为对称矩阵的特性,进行剪枝处理。
bug出现及修改
上面说到本次最大的败笔在于自己设计的Node类 : 原本可以通过简单的多重Hashmap实现的功能,却通过新建类来实现
本次作业中,测试数据同样出现了查询指令占大多数,增删指令占极少数的分布方式。
而按照我的设计方法,每次查询时均需要new一至两个Node对象,这一设计的直接后果导致最后时间激增,强测数据全部GG,最后连互测都没有进。
之后看到大家Hashmap嵌套Hashmap的结构,感到一丝讽刺意味。自作聪明实现一个本无需实现的类强行实现出来,相当于自掘坟墓。最后由于时间原因,通过对Floyd算法进行极限减枝,使得时间最后在超时边缘疯狂试探,但成功进行了bug修复。
第11次作业
结构图
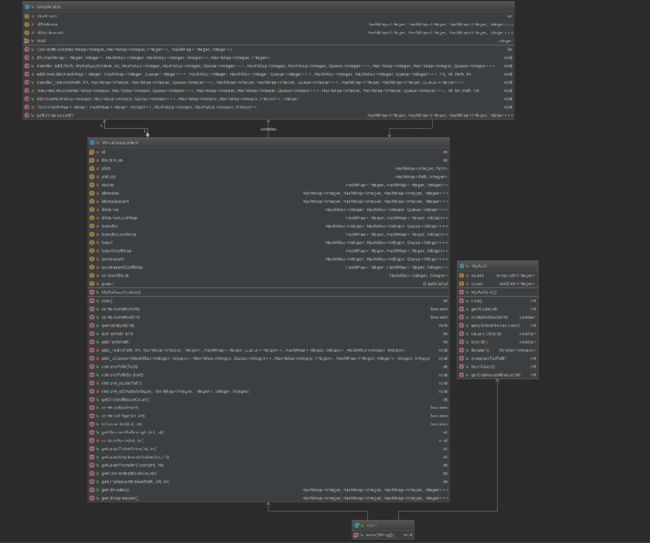
本次作业是三次作业中设计的最满意的一次,由于前两次作业都由于态度不端正导致出现了很多错误。本次实验充分吸取了前两次作业的的失败经验,设计了以下的数据结构:
private HashMap plist;
private HashMap pidList;
private HashMap> nodes;
private HashMap>> idNodes;
private HashMap>> idUnpleasant;
private HashMap>> distance;
private HashMap> distanceCostMap;
private HashMap>> transfer;
private HashMap> transferCostMap;
private HashMap>> ticket;
private HashMap> ticketCostMap;
private HashMap>> unpleasant;
private HashMap> unpleasantCostMap;
private HashMap connectBlock;
private GraphCalcul graph; 其中
connectBlock为记录节点联通块的数据结构,采用DFS算法进行计算。两个Integer分别代表结点编号,联通块在每次增删指令后首先运算,从而简化其他路径的运算。(若两节点处于不同联通块中,则无需后续计算)
distanceCostMap,transferCostMap,ticketCostMap和unpleasantCostMap为记录最短权重矩阵的数据结构,采用Dijkstra堆优化算法计算,每次的查询指令输入后进行判断
- 若已经被计算最短权重路径,这直接获取输出
- 若没有被计算最短权重路径,则根据上述算法计算出该起点对应的单元最短路径
distance, transfer, ticket和unpleasant为记录原始权重路径的数据结构,供Dijkstra堆优化算法使用。
- 在计算最短换乘与最短路径时采用直接赋值的方法
- 在计算最小不满意度和最少车费时采用对一条路径的两两节点依次赋权边的方式
- 详细的赋边权方法参考了讨论区葛毅飞同学的方法
考虑到可能出现的自环现象,会导致依次赋权边的方法出现错误,因此应在这之前算出Path内两两节点的最短路径,本次考虑到一条路径中的节点数不是很多,且每两节点之间的最短路均需要,因此采用了Floyd算法。
因此最短路径的计算被分散到增删路径与查找路径阶段,通过将查找阶段的运算结果进行保存,做到越查越快的目的。
本次本来也考虑的是拆点方法,但看到巧妙赋边权统一建模的思想时,感觉茅塞顿开,为本次作业的顺利进行提供了很大帮助。
bug出现与修改
本次强测过程终于以满分通过,但在自己debug阶段发现一些问题,主要是对Dijkstra理解不深入导致的。
- 由于单元最短路径的局限性,导致当起点不同时需要重新计算,而并非想象中的对称式
- Dijkstra算法在单元最短路径未全部算完之前,虽然一些点已经成功赋值,但并非最短路径,因此不能运算一半便终止运算。
五.体会与感想
本三次作业主要考察了大家阅读JML格式以及算法方面的知识。虽然JML看起来还无法胜任我们期望它完成的所有工作,但我觉得课程组是基于下面几点考虑:
- JML依然是目前业界最成熟的规格表达方式。
- 形式化设计可以揪出隐藏的bug。若按照提供的JML格式文档,错误率将大大降低。
- 这类语言在质量要求高的场合运用广泛,虽目前功能不足,但前景广阔。

- 三次作业模拟了真实开发过程:确定需求,设计规格,测试/功能模块编写,测试代码正确性,为以后真正的工程设计提供了基础。