浅析MySQL的HASH数据结构分析
MySQL目前版本尽管不支持HASH索引,但在源码实现中,HASH数据结构的应用却非常广泛。MySQL的HASH数据结构使用链地址法处理键值冲突,特别的是,HASH的存储使用动态数组,采用静态链表的方式存储。以下内容中,对MySQL的HASH数据结构及核心处理方法进行详细的分析,并简单举例,更清晰的描述HASH数据结构的处理过程。
数据结构
HASH相关的数据结构定义在mysql源码的include/hash.h和mysys/hash.c文件中,具体定义如下所示:
| typedef uchar *(*my_hash_get_key)(const uchar *,size_t*,my_bool); typedef struct st_hash { size_t key_offset,key_length; /* Length of key if const length */ size_t blength; ulong records; uint flags; DYNAMIC_ARRAY array; /* Place for hash_keys */ my_hash_get_key get_key; void (*free)(void *); CHARSET_INFO *charset; } HASH; typedef struct st_hash_info { uint next; /* index to next key */ uchar *data; /* data for current entry */ } HASH_LINK; |
从定义可知,函数指针my_hash_get_key主要用于获得hash中的键值,在HASH数据结构中作为回调函数,根据实际应用场景定义。HASH数据结构中,key_offset表示关键字的偏移量;key_length表示关键字的长度;blength用于计算数据存放在array中的地址;records表示HASH中的记录数;flags表示HASH的操作相关的标志位;array存储HASH的键值,为DYNAMIC_ARRAY数据结构,相关操作参考《MySQL数据结构分析--DYNAMIC_ARRAY》;get_key为获取键值函数指针;free为释放HASH数据结构的函数;charset为HASH字符集。HASH_LINK数据结构用于初始化HASH结构中array的元素,其中data表示数据内容;next表示下一个键值的索引。
源码实现
MySQL数据结构HASH的基本思想是:首先,使用数据结构HASH_LINK作为DYNAMIC_ARRAY数组array的元素,使得其组织方式是使用静态链地址法来存放HASH_LINK的每个元素,如果键值冲突,使用next指向下一个相同键值的元素在array中的地址,来获得相同键值的元素。如果存储数据不能重复,则通过flag标志,通过查找array中相同键值的元素是否匹配该数据即可。键值计算方法根据字符集的hash_sort方法进行计算。
以下内容中,对几个重要的方法进行了说明,详细分析了几个核心的并且非常复杂的处理逻辑。更加详细的内容,参照mysys/hash.c源码文件。
_my_hash_init()函数
_my_hash_init()函数是HASH数据结构的初始化函数,根据输入的参数,初始化HASH中的各个参数变量。特别注意的是,初始化array变量时,调用my_init_dynamic_array_ci()函数,array中每个元素的长度为HASH_LINK数据结构的大小。
my_hash_free()函数
my_hash_free()函数是HASH数据结构的析构函数。首先调用my_hash_free_elements()析构array中的每个元素,并释放array结构,然后将free函数置空。
calc_hash()函数
calc_hash()函数用于计算HASH值的方法,该函数通过调用字符集的处理函数hash_sort()获得。
my_hash_key()函数
my_hash_key()函数用于从存储数据中,提取HASH的关键字。如果应用中提供了get_key函数,则通过get_key函数获得。否则通过key_offset值获得。
my_hash_mask()函数
my_hash_mask()函数是通过关键字,计算array中的位置。该函数根据关键字的键值、blength参数的值和HASH中的记录数。
my_hash_rec_mask()函数
my_hash_rec_mask()函数根据当前记录,获得关键字,调用calc_hash()重新计算键值并调用my_hash_mask()函数计算array中存储的位置。
my_hash_search()函数
my_hash_search()函数通过关键字,查找数据内容。该函数调用my_hash_first()函数,查找第一个符合的数据并返回。
my_hash_search_using_hash_value()函数
my_hash_search_using_hash_value()函数是通过HASH键值和关键字,查找相应的数据内容。该函数调用my_hash_first_from_hash_value()函数获得。
my_hash_first()函数
my_hash_first()函数用于查找第一个符合查询关键字的记录。该函数调用my_hash_first_from_hash_value()函数获得。
my_hash_first_from_hash_value()函数
my_hash_first_from_hash_value()函数是查找关键字或键值对应数据记录的实际处理函数。其处理逻辑是:首先根据键值,获得array中的地址,然后比较关键字是否匹配。匹配成功,直接返回当前数据内容。否则,调用my_hash_rec_mask()函数计算array的地址,如果与当前偏移不相等,则中断继续查询,查找失败,否则根据next的值,获得下一个相同键值数据记录的偏移地址,直到没有下一条数据为止。其中,hashcmp()函数用于比较关键字是否匹配,比较时依赖字符集,不做详细分析和说明。
my_hash_first_from_hash_value()函数流程图如下所示:
my_hash_next()函数
my_hash_next()函数查找键值的下一条数据记录,该函数必须首先调用my_hash_search()函数,根据返回到HASH_SEARCH_STATE的值,查找下一条数据记录。
my_hash_insert()函数
my_hash_insert()函数用于插入记录到HASH中。主要处理逻辑是:首先,如果当前HASH必须关键字唯一,那么通过调用my_hash_search()函数查找是否有当前关键字,如果存在则直接返回。其次,根据关键字,为当前数据记录查找一个存储位置。在查找过程中,有两种处理方式,其中一种需要移动存储位置。最后,将当前记录插入到存储位置。
my_hash_delete()函数
my_hash_delete()函数是从HASH表中删除记录。该函数的处理逻辑是:首先根据记录的关键字,计算键值,根据键值计算记录在array中的存储位置。如果记录不匹配,查找下一条记录。查找到相应的记录后,将array中最后一条数据记录进行调整。如果是键值相同,直接将最后一个位置的数据记录调整到删除位置,并修改链地址。否则需要进行调用movelink()函数进行链接调整。
my_hash_update()函数
my_hash_update()函数是修改数据的处理函数。该函数的逻辑是:首先,如果不允许数据重复,那么需要首先验证当前记录是否在HASH表中,如果存在直接返回。其次,分别计算原关键字和当前记录关键字存储的位置,如果相等,不需要处理。否则,需要调整记录到正确的位置。
my_hash_update()函数流程图如下所示:
以上是HASH数据结构的主要处理函数,实际上最核心的处理方法是my_hash_insert()、my_hash_delete()、my_hash_update()和my_hash_first_from_hash_value()四个函数。通过这四个函数就可以实现对HASH数据结构的增、删、改、查基本操作。
举例
由于以上逻辑分析比较难懂,为了进一步更加清晰的了解HASH的工作原理,以下网站运营将举例说明HASH数据结构的基本操作流程。
为了简单起见,定义四条记录,分别是“a”、“b”、“c”、“a”、“d”,并且关键字也是这四个值,关键字长度是1,关键字偏移量是0,字符集为utf8。
1、计算关键字的键值
根据字符集的sort_order函数计算,得到四条记录的键值分别为:580、587、590、580、597。
2、插入操作
最初HASH表中为空,然后依次插入“a”、“b”、“c”、“a”、“d”五条记录。并且,插入过程输入的flag为0。HASH中array中的存储过程图示如下:
1) 插入“a”
array中“a”的存储地址索引idx=my_hash_mask(580,1,1)=0,插入位置pos=array+0,将pos位置的data指针指向“a”,next值为-1。插入之后,info->records=1,info->blength=2。具体如下所示
2) 插入“b”
起初,array中的存储状态如下(1)所示。根据判断条件if (!(hash_nr & halfbuff)),即(!(580&1)),条件成功,不需要移动数据;此时,将gpos指针指向pos位置,如下(2)所示;计算“b”存放的地址,my_hash_mask(587,2,2)=1,将pos指向data+1位置,如下(3)所示;将pos->data指向“b”,pos->next=-1,如下(4)所示。此时,info->records=2,info->blength=4。
3) 插入“c”
插入“c”的过程同“b”类似,在(3)中,计算计算“c”存放的地址,my_hash_mask(590,4,3)=2,将pos指向data+2位置。插入后,info->records=3,info->blength=4。
4) 插入“a”
首先,插入前的状态如下(1)中所示;根据判定条件if (!(hash_nr & halfbuff)),即if(!(587&2))为假,此时需要移动数据,确定移动位置gpos2指向最后位置,empty指向pos位置,并将ptr_to_rec2指向移动记录“b”,如下(2)所示;如下(3)所示,将“b”移动到gpos2位置,next=-1;最后,计算当前记录“a”的索引地址idx=my_hash_mask(580,4,4)=0,
pos指向data+idx位置。由于当前位置pos不是empty存放位置,那么将pos复制给empty,即empty指向最先插入的“a”,gpos=data+my_hash_mask(580,4,4)=0,由于当前pos=gpos,则pos->data指向新插入的记录“a”,pos->next=(empty-data)=1。具体如下(4)所示。此外,info->records=4,info->blength=8。
5) 插入“d”
插入“d”之前,array的状态如下(1)所示;根据判定条件if (!(hash_nr & halfbuff)),即if(!(580&4))为假,此时需要移动数据,确定移动位置gpos2指向最后位置,empty指向pos位置,并将ptr_to_rec2指向移动记录“a”,如下(2)所示;由于(pos->next=1)!=-1,继续查找下一条记录,pos指向下一条记录,并且仍然需要移动数据。第一次循环后,flag=4,因此if(!(flag & HIGHFIND))条件为假,但if (!(flag & HIGHUSED))条件为真,将gpos2->data指向上一次的数据ptr_to_rec2,gpos2->next=1,flag=12,如下(3)所示;循环结束后,如下(4)所示,并且将gpos2指向pos位置,ptr_to_rec2指向pos->data;“d”的索引idx=my_hash_mask(597,8,5)=1,由于pos!=empty,将empty赋值为pos,gpos=data+my_hash_mask(580,8,5)=4,即gpos指向data+4。此时,由于gpos!=pos,则将pos->data指向“d”,pos->next=-1。此时,需要移动链地址的链接,调用movelink()函数,从gpos开始,将pos之前的记录的next指向empty,如下(5)所示;插入“d”之后,array中的状态如下(6)所示。此外,此时info->records=5,info->blength=8。
从以上插入可以看出,blength主要用于计算数据存放的掩码值,当records等于blength时,该值增大一倍。如果出现键值冲突时,需要进行移动数据位置,调整链接值,新插入的数据总是放在链地址的末尾。
3、删除操作
删除处理过程将以数据第一个“a”删除为例,进行详细说明。
删除之前,需要首先获取“a”记录,然后再删除该记录。HASH中进行比较的是地址,因此只有相同地址的数据内容才能被删除。
如下(1)所示,pos=data+my_hash_mask(580,8,5)=data+4;删除pos的link,empty=data+pos->next,pos->data=empty->data,pos->next=1,如下(2)所示;最后位置的数据的键值lastpos_nr=580,pos=data+my_hash_mask(580,8,4)=data+0,如下(3)所示;最后将最后的数据“a”删除,如下(4)所示。此时,hash->records=4。
|
|
|
| (1) |
(2) |
|
|
|
| (3) |
(4) |
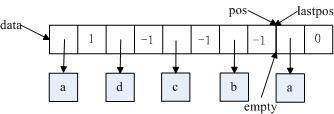
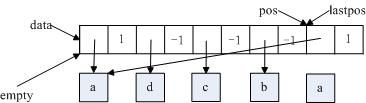
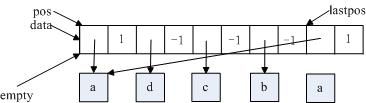
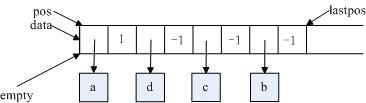
从删除操作来看,基本处理策略是将匹配的数据置换到最后位置,并调整置换数据的链地址,最终释放该数据资源即可。
update操作相对较容易,主要是找到更新的数据,然后重新计算键值,调整之前的链地址和修改后数据的链地址。
结论
通过详细分析HASH数据结构及核心操作的基本处理逻辑,并举例说明HASH具体的处理过程,对MySQL的HASH有深入的理解。分析发现,该HASH实现通过静态链地址法,连续存储数据,有效的提高了空间的利用率。然而,这也使得在键值出现冲突时,需要进行调整链地址和修改数据指针,调整代价较高。此外,使用blength来计算键值存放地址时,会导致键值冲突较频繁,以举例的插入即可看出。
HASH数据结构在MySQL的很多处理过程及子系统中都有应用,如:用户认证子系统、plugin子系统、replication复制子系统、sql层的很多处理过程中等都有使用。