数据库复习笔记----关系数据库
关系数据库
简介:提出关系模型的是美国IBM公司的E.F.Codd1970年提出关系数据模型E.F.Codd, “A Relational Model of Data for Large Shared Data Banks”, 《Communication of the ACM》,1970之后,提出了关系代数和关系演算的概念,1972年提出了关系的第一、第二、第三范式,1974年提出了关系的BC范式。
一、关系数据结构及形式化定义
1.关系
★单一的数据结构----关系
—现实世界的实体以及实体间的各种联系均用关系来表示
★逻辑结构----二维表
—从用户角度,关系模型中数据的逻辑结构是一张二维表
★建立在集合代数的基础上
1.1 域(Domain)
定义:域是一组具有相同数据类型的值的集合。例:
- 整数
- 实数
- 介于某个取值范围的整数
- 指定长度的字符串集合
- {‘男’,‘女’}
等等…
1.2 笛卡尔积(Cartesian Product)
(1)含义:给定一组域D1,D2,…,Dn,允许其中某些域是相同的。D1,D2,…,Dn的笛卡尔积为:
D1×D2×…×Dn = {(d1,d2,…,dn)|diDi,i=1,2,…,n}
注意:
★— 所有域的所有取值的一个组合
★— 不能重复
(2)元组(Tuple)
**定义:**笛卡尔积中每一个元素(d1,d2,…,dn)叫作一个n元组(n-tuple)或简称元组
—★(刘备,计算机专业,赵云)
—★(刘备,计算机专业,马超) 等 都是元组。 (备注:导师 --专业 --研究生)
(3)分量(Component)
定义:笛卡尔积元素(d1,d2,…,dn)中的每一个值di 叫作一个分量,张清玫、计算机专业、李勇、刘晨等都是分量
(4)基数(Cardinal number)
若Di(i=1,2,…,n)为有限集,其基数为mi(i=1,2,…,n),则D1×D2×…×Dn的基数M为:
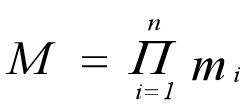
(5)笛卡尔积的表示方法
★笛卡尔积可表示为一张二维表
★表中的每行对应一个元组,表中的每列对应一个域
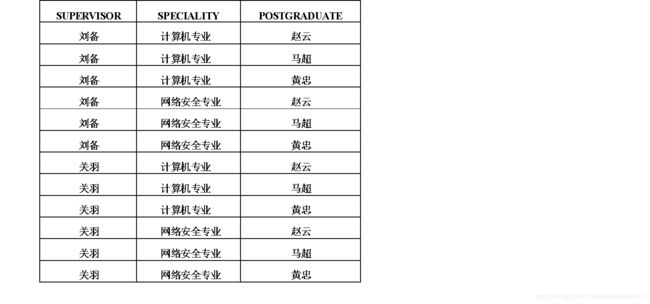
例如,给出3个域:
D1=导师集合SUPERVISOR={刘备,关羽}
D2=专业集合SPECIALITY={计算机专业,网络安全专业}
D3=研究生集合POSTGRADUATE={赵云,马超,黄忠}
D1,D2,D3的笛卡尔积为:
- D1×D2×D3={
(刘备,计算机专业,赵云),(刘备,计算机专业,马超),
(刘备,计算机专业,黄忠),(刘备,网络安全专业,赵云),
(刘备,网络安全专业,马超),(刘备,网络安全专业,黄忠),
(关羽,计算机专业,赵云),(关羽,计算机专业,马超),
(关羽,计算机专业,黄忠),(关羽,网络安全专业,赵云),
(关羽,网络安全专业,马超),(关羽,网络安全专业,黄忠) } - 基数为2×2×3=12
- 表1.2.5如下:
1.3 关系(Relation)
(1) 关系,D1×D2×…×Dn的子集叫作在域D1,D2,…,Dn上的关系,表示为:
R(D1,D2,…,Dn)
●R:关系名
●n:关系的目或度(Degree)
(2)元组,关系中的每个元素是关系中的元组,通常用t表示。
(3)单元关系与二元关系
当n=1时,称该关系为单元关系(Unary relation),或一元关系 ;
当n=2时,称该关系为二元关系(Binary relation)。
(4)关系的表示
关系也是一个二维表,表的每行对应一个元组,表的每列对应一个域。
(5)属性
●关系中不同列可以对应相同的域
●为了加以区分,必须对每列起一个名字,称为属性(Attribute)
●n目关系必有n个属性
(6)码
候选码(Candidate key):若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为候选码
简单的情况:候选码只包含一个属性
全码(All-key):最极端的情况:关系模式的所有属性组是这个关系模式的候选码,称为全码(All-key)。
主码:若一个关系有多个候选码,则选定其中一个为主码(Primary key)
主属性:候选码的诸属性称为主属性(Prime attribute),不包含在任何侯选码中的属性称为非主属性(Non-Prime attribute)或非码属性(Non-key attribute)。
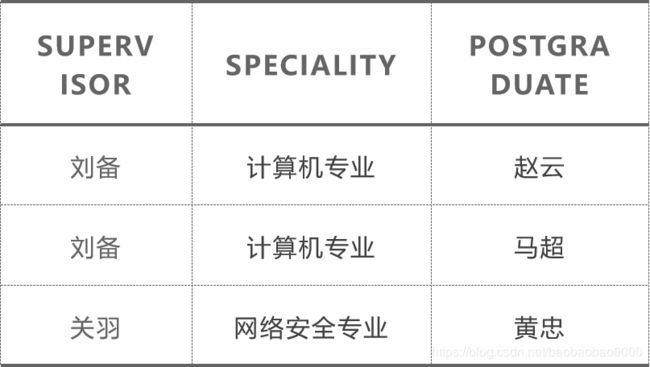
★★D1,D2,…,Dn的笛卡尔积的某个子集才有实际含义
例:表1.2.5 的笛卡尔积没有实际意义,取出有实际意义的元组来构造关系
关系:SAP(SUPERVISOR,SPECIALITY,POSTGRADUATE)
假设:导师与专业:n:1, 导师与研究生:1:n
主码:POSTGRADUATE(假设研究生不会重名)
(7)三类关系
- 基本关系(基本表或基表):实际存在的表,是实际存储数据的逻辑表示
- 查询表:查询结果对应的表
- 视图表:由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据
(8)基本关系的性质
① 列是同质的(Homogeneous)
② 不同的列可出自同一个域,●其中的每一列称为一个属性 ●不同的属性要给予不同的属性名
③ 列的顺序无所谓,,列的次序可以任意交换
④ 任意两个元组的候选码不能相同
⑤ 行的顺序无所谓,行的次序可以任意交换
⑥ 分量必须取原子值,这是规范条件中最基本的一条
不能出现如下情况:
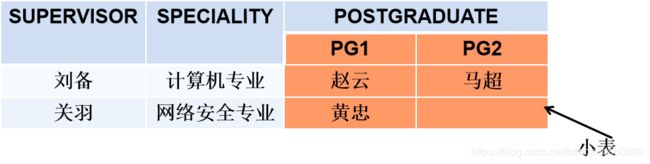
2.关系模式
2.1 什么是关系模式
(1)关系模式(Relation Schema)是型。
(2)关系是值。
(3)关系模式是对关系的描述:
★元组集合的结构
- 属性构成
- 属性来自的域
- 属性与域之间的映象关系
★完整性约束条件
2.2 定义关系模式
(1)关系模式可以形式化地表示为:
R(U,D,DOM,F)
R 关系名
U 组成该关系的属性名集合
D U中属性所来自的域
DOM 属性向域的映象集合
F 属性间数据的依赖关系的集合
例:
导师和研究生出自同一个域——人,
取不同的属性名,并在模式中定义属性向域
的映象,即说明它们分别出自哪个域:
DOM(SUPERVISOR-PERSON)
= DOM(POSTGRADUATE-PERSON)
= PERSON
(2)关系模式通常可以简记为
R (U) 或 R (A1,A2,…,An)
- R: 关系名
- A1,A2,…,An : 属性名
注:域名及属性向域的映象常常直接说明为属性的类型、长度
2.3 关系模式与关系
(1)关系模式
- 对关系的描述
- 静态的、稳定的
(2)关系
- 关系模式在某一时刻的状态或内容
- 动态的、随时间不断变化的
(3)关系模式和关系往往笼统称为关系,通过上下文加以区别
3.关系数据库
(1)关系数据库
- 在一个给定的应用领域中,所有关系的集合构成一个关系数据库
(2)关系数据库的型与值
- 关系数据库的型: 关系数据库模式,是对关系数据库的描述
- 关系数据库的值: 关系模式在某一时刻对应的关系的集合,通常称为关系数据库
4.关系模型的存储结构
关系数据库的物理组织:
- 有的关系数据库管理系统中一个表对应一个操作系统文件,将物理数据组织交给操作系统完成
- 有的关系数据库管理系统从操作系统那里申请若干个大的文件,自己划分文件空间,组织表、索引等存储结构,并进行存储管理
二、关系操作
1.基本的关系操作
(1)常用的关系操作
- 查询操作:选择、投影、连接、除、并、差、交、笛卡尔积,而选择、投影、并、差、笛卡尔积是5种基本操作
- 数据更新:插入、删除、修改
(2)关系操作的特点
集合操作方式:操作的对象和结果都是集合,一次一集合的方式
2.关系数据库语言的分类
(1)关系代数语言
- 用对关系的运算来表达查询要求
- 代表:ISBL
(2)关系演算语言:用谓词来表达查询要求
●元组关系演算语言
- 谓词变元的基本对象是元组变量
- 代表:APLHA, QUEL
●域关系演算语言
- 谓词变元的基本对象是域变量
- 代表:QBE
(3)具有关系代数和关系演算双重特点的语言
- 代表:SQL(Structured Query Language)
三、关系的完整性
★关系的三类完整性约束:
-●实体完整性和参照完整性
- 关系模型必须满足的完整性约束条件称为关系的两个不变性,应该由关系系统自动支持
-●用户定义的完整性
- 应用领域需要遵循的约束条件,体现了具体领域中的语义约束
1.实体完整性
1.1 实体完整性规则(Entity Integrity)
(1)若属性A是基本关系R的主属性,则属性A不能取空值
(2)空值就是“不知道”或“不存在”或“无意义”的值
例:
选修(学号,课程号,成绩)
●“学号、课程号”为主码
●“学号”和“课程号”两个属性都不能取空值
1.2 实体完整性规则的说明
(1)实体完整性规则是针对基本关系而言的。 一个基本表通常对应现实世界的一个实体集。
(2)现实世界中的实体是可区分的,即它们具有某种唯一性标识。
(3)关系模型中以主码作为唯一性标识。
(4)主码中的属性即主属性不能取空值。主属性取空值,就说明存在某个不可标识的实体,即存在不可区分的实体,这与第(2)点相矛盾,因此这个规则称为实体完整性
2.参照完整性
2.1 关系间的引用
(1)在关系模型中实体及实体间的联系都是用关系来描述的,自然存在着关系与关系间的引用。
例2.11:
学生实体、专业实体
学生(学号,姓名,性别,专业号,年龄)-----学号为主码
专业(专业号,专业名)-----专业号为主码
- 学生关系引用了专业关系的主码“专业号”。
- 学生关系中的“专业号”值必须是确实存在的专业的专业号
例2.12:
学生、课程、学生与课程之间的多对多联系
学生(学号,姓名,性别,专业号,年龄)
课程(课程号,课程名,学分)
选修(学号,课程号,成绩)
例2.13:
学生实体及其内部的一对多联系
学生(学号,姓名,性别,专业号,年龄,班长)
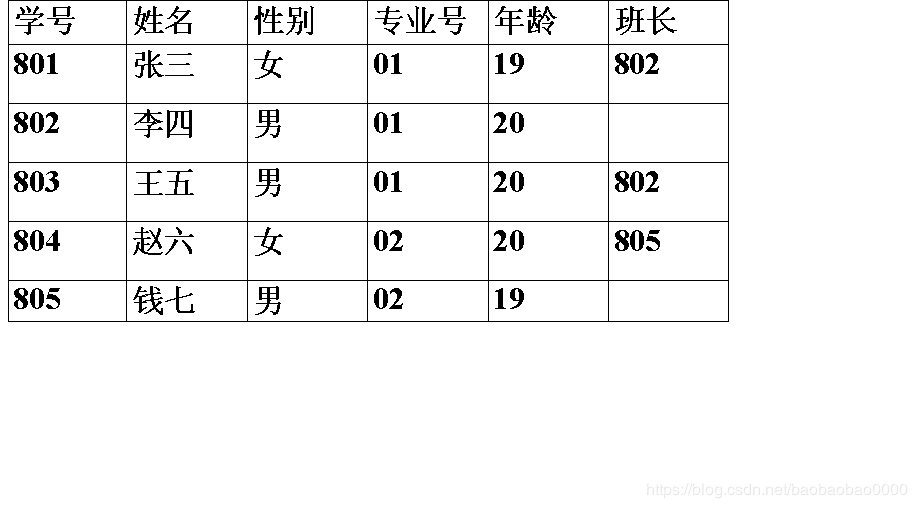
★“学号”是主码,“班长”是外码,它引用了本关系的“学号” ,“班长” 必须是确实存在的学生的学号
ps:熟记上面的例子下面都会围绕三个例子来讲解
2.2 外码(Foreign Key)
(1)设F是基本关系R的一个或一组属性,但不是关系R的码。如果F与基本关系S的主码Ks相对应,则称F是R的外码
(2)基本关系R称为参照关系(Referencing Relation)
(3)基本关系S称为被参照关系(Referenced Relation)或目标关系(Target Relation)
(4)上例2.11中学生关系的“专业号”与专业关系的主码“专业号”相对应
- “专业号”属性是学生关系的外码
- 专业关系是被参照关系,学生关系为参照关系

(5)例2.12中
●选修关系的“学号” 与学生关系的主码“学号”相对应
●选修关系的“课程号”与课程关系的主码“课程号”相对应
- “学号”和“课程号”是选修关系的外码
- 学生关系和课程关系均为被参照关系
- 选修关系为参照关系
(6)例2.13中 “班长”与本身的主码“学号”相对应
- “班长”是外码
- 学生关系既是参照关系也是被参照关系

(7)关系R和S不一定是不同的关系
(8)目标关系S的主码Ks 和参照关系的外码F必须定义在同一个(或一组)域上
(9)外码并不一定要与相应的主码同名
- 当外码与相应的主码属于不同关系时,往往取相同的名字,以便于识别
2.3 参照完整性规则
(1)参照完整性规则:若属性(或属性组)F是基本关系R的外码它与基本关系S的主码Ks相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须为:
- 或者取空值(F的每个属性值均为空值)
- 或者等于S中某个元组的主码值
(2)在例2.11中:
学生关系中每个元组的“专业号”属性只取两类值:
- 空值,表示尚未给该学生分配专业
- 非空值,这时该值必须是专业关系中某个元组的“专业号”值,表示该学生不可能分配一个不存在的专业
(3)例2.12中
选修(学号,课程号,成绩)
“学号”和“课程号”可能的取值 :
- 选修关系中的主属性,不能取空值
- 只能取相应被参照关系中已经存在的主码值
(4)例2.13中
学生(学号,姓名,性别,专业号,年龄,班长)
“班长”属性值可以取两类值:
- 空值,表示该学生所在班级尚未选出班长
- 非空值,该值必须是本关系中某个元组的学号值
3.用户定义的完整性
(1)针对某一具体关系数据库的约束条件,反映某一具体应用所涉及的数据必须满足的语义要求
(2)关系模型应提供定义和检验这类完整性的机制,以便用统一的系统的方法处理它们,而不需由应用程序承担这一功能
例3.31:
课程(课程号,课程名,学分)
“课程号”属性必须取唯一值
非主属性“课程名”也不能取空值
“学分”属性只能取值{1,2,3,4}
四、 关系代数
★关系代数是一种抽象的查询语言,它用对关系的运算来表达查询
★关系代数
- 运算对象是关系
- 运算结果亦为关系
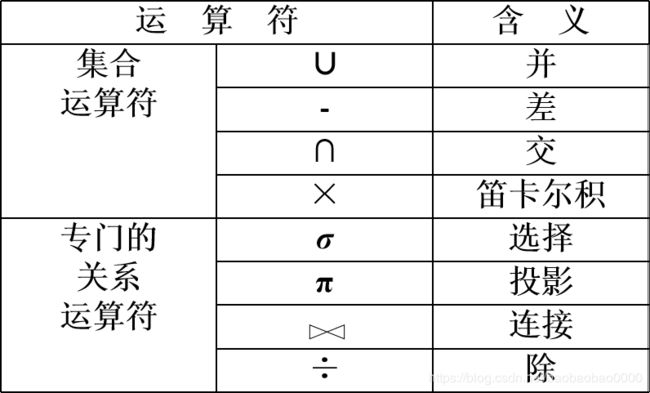
- 关系代数的运算符有两类:集合运算符和专门的关系运算符
★传统的集合运算是从关系的“水平”方向即行的角度进行
★专门的关系运算不仅涉及行而且涉及列
关系代数运算符如下:
1.传统的集合运算
(1) 并(Union)
●R和S
- 具有相同的目n(即两个关系都有n个属性)
- 相应的属性取自同一个域
●R∪S
- 仍为n目关系,由属于R或属于S的元组组成 R∪S = { t ∣ t ∈ R ∨ t ∈ S { t | t \in R ∨ t \in S } t∣t∈R∨t∈S}
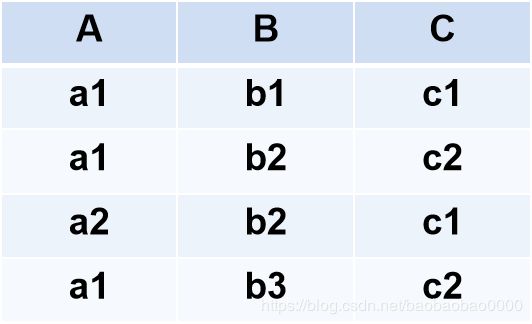
R如下:
S如下:
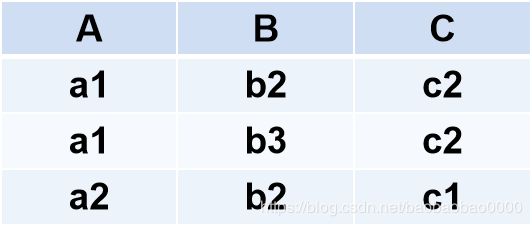
则RUS如下:
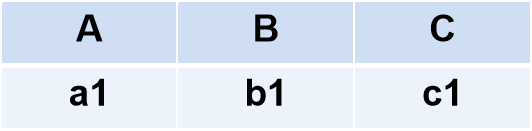
(2)差(Difference)
●R和S
- 具有相同的目n
- 相应的属性取自同一个域
●R - S
- 仍为n目关系,由属于R而不属于S的所有元组组成R-S = { t ∣ t ∈ R ∧ t ∉ S { t | t \in R ∧ t \notin S } t∣t∈R∧t∈/S}
则R-S 为:
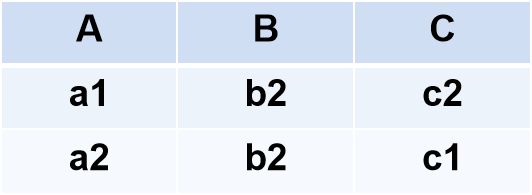
(3) 交(Intersection)
●R和S
- 具有相同的目n
- 相应的属性取自同一个域
●R∩S
- 仍为n目关系,由既属于R又属于S的元组组成
R∩S = { t ∣ t ∈ R ∧ t ∈ S { t | t \in R ∧ t \in S } t∣t∈R∧t∈S}
R∩S = R –(R-S)
则R∩S值为:
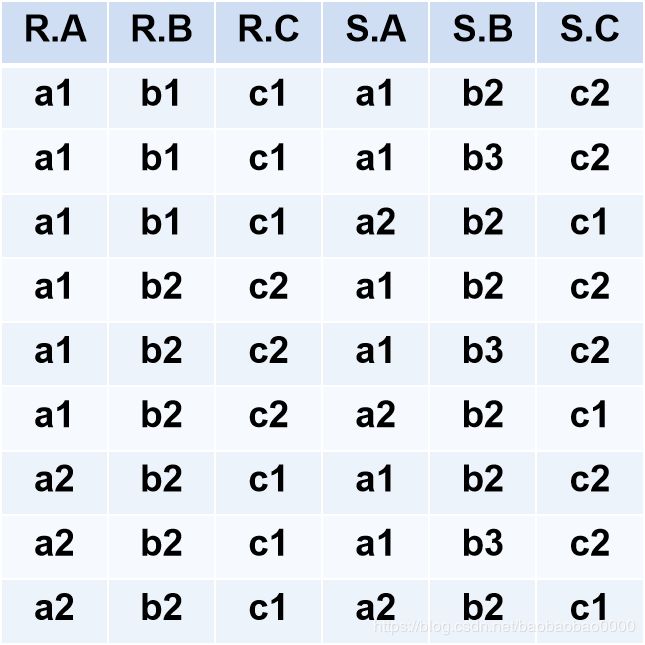
(4) 笛卡尔积(Cartesian Product)
●严格地讲应该是广义的笛卡尔积(Extended Cartesian Product)
●R: n目关系,k1个元组
●S: m目关系,k2个元组
●R×S
- 列:(n+m)列元组的集合
- 元组的前n列是关系R的一个元组
- 后m列是关系S的一个元组 - 行:k1×k2个元组
R×S = t r t s ⏞ ∣ t r ∈ R ∧ t s ∈ S {\overbrace{{t_r t_s}} |t_r \in R ∧ t_s \in S } trts ∣tr∈R∧ts∈S
则R×S为:
2.专门的关系运算
2.1先引入几个记号
(1) R, t ∈ R t \in R t∈R,t[Ai]
● 设关系模式为R(A1,A2,…,An)
● 它的一个关系设为R
● t ∈ R t \in R t∈R表示t是R的一个元组
● t[Ai]则表示元组t中相应于属性Ai的一个分量
(2) A , t [ A ] , A ‾ A,t[A], \overline{A} A,t[A],A
●若A={Ai1,Ai2,…,Aik},其中Ai1,Ai2,…,Aik是A1,A2,…,An中的一部分,则A称为属性列或属性组。
t[A]=(t[Ai1],t[Ai2],…,t[Aik])表示元组t在属性列A上诸分量的集合。
● A ‾ 则 表 示 A 1 , A 2 , … , A n 中 去 掉 A i 1 , A i 2 , … , A i k 后 剩 余 的 属 性 组 。 \overline{A}则表示{A1,A2,…,An}中去掉{Ai1,Ai2,…,Aik}后剩余的属性组。 A则表示A1,A2,…,An中去掉Ai1,Ai2,…,Aik后剩余的属性组。
(3) t r t s ⏞ \overbrace{{t_r t_s}} trts
R为n目关系,S为m目关系。
t r ∈ R , t s ∈ S , t r t s ⏞ 称 为 元 组 的 连 接 t_r \in R, t_s \in S,\overbrace{{t_r t_s}}称为元组的连接 tr∈R,ts∈S,trts 称为元组的连接
t r t s ⏞ 是 一 个 n + m 列 的 元 组 , 前 n 个 分 量 为 R 中 的 一 个 n 元 组 , 后 m 个 分 量 为 S 中 的 一 个 m 元 组 。 \overbrace{{t_r t_s}}是一个n + m列的元组,前n个分量为R中的一个n元组,后m个分量为S中的一个m元组。 trts 是一个n+m列的元组,前n个分量为R中的一个n元组,后m个分量为S中的一个m元组。
(4)象集Zx
给定一个关系R(X,Z),X和Z为属性组。
当t[X]=x时,x在R中的象集(Images Set)为:
Zx={t[Z] | t ∈ R t \in R t∈R,t[X]=x}
它表示R中属性组X上值为x的诸元组在Z上分量的集合
例:

●x1在R中的象集
- Zx1 ={Z1,Z2,Z3},
●x2在R中的象集
- Zx2 ={Z2,Z3},
●x3在R中的象集
- Zx3={Z1,Z3}
2.2 选择
ps:下面内容围绕下表讲解
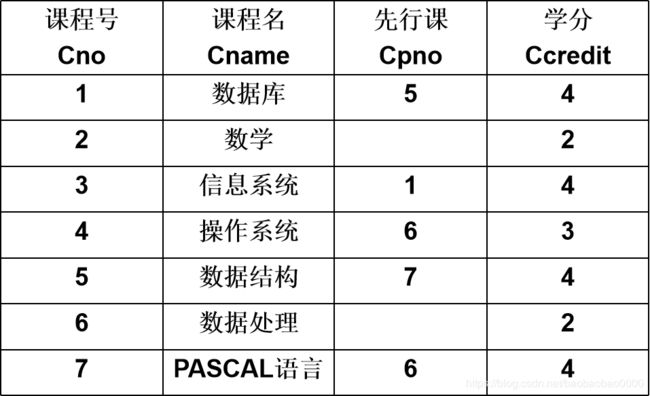
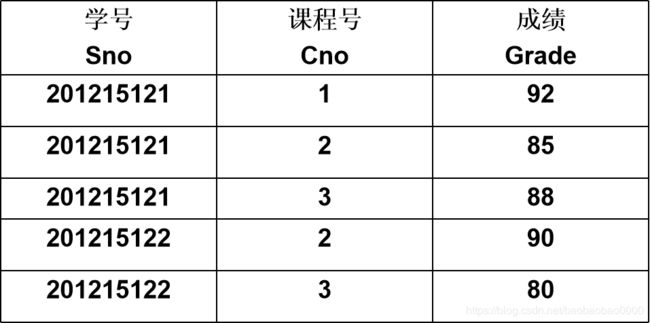
学生-课程数据库:
学生关系Student、课程关系Course和选修关系SC
Student 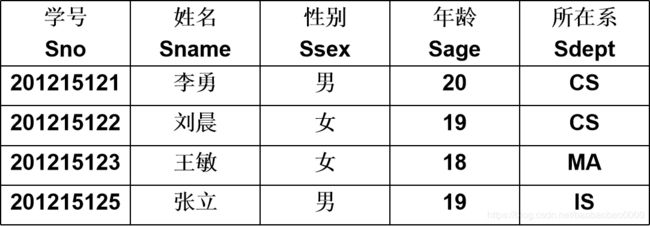
Course
SC
(1)选择又称为限制(Restriction)
(2)选择运算符的含义
●在关系R中选择满足给定条件的诸元组
σ F ( R ) = { σ_F(R)}= σF(R)=
{t | t ∈ R t \in R t∈R∧F(t)= ‘真’}
●F:选择条件,是一个逻辑表达式,取值为“真”或“假”
- 基本形式为: X 1 θ Y 1 X_1 θ Y_1 X1θY1
- θ表示比较运算符,它可以是>,≥,<,≤,=或<>
(3)选择运算是从关系R中选取使逻辑表达式F为真的元组,是从行的角度进行的运算
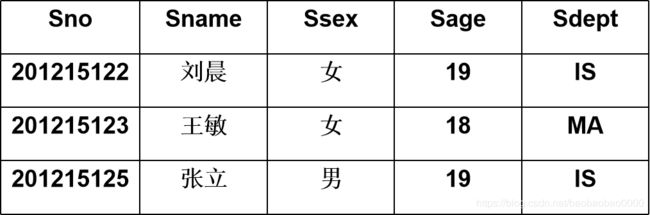
例:查询信息系(IS系)全体学生。
![]()
结果:
例:查询年龄小于20岁的学生。
![]()
结果:
2.3 投影
(1)从R中选择出若干属性列组成新的关系
π A ( R ) = t [ A ] ∣ t ∈ R π_A(R) = { t[A] | t \in R } πA(R)=t[A]∣t∈R
A:R中的属性列
(2)投影操作主要是从列的角度进行运算
(3)投影之后不仅取消了原关系中的某些列,而且还可能取消某些元组(避免重复行)
例:查询学生的姓名和所在系。
即求Student关系上学生姓名和所在系两个属性上的投影
![]()
结果: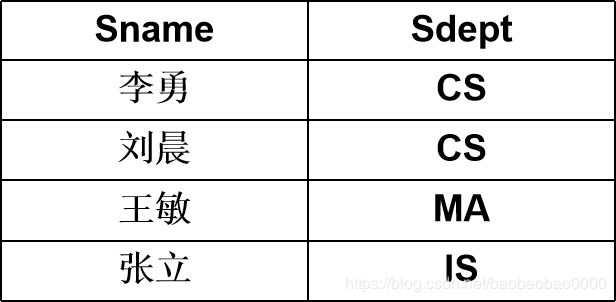
例:查询学生关系Student中都有哪些系。
![]()
结果:
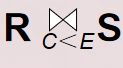
2.4 连接
(1)连接也称为θ连接
(2)连接运算的含义
从两个关系的笛卡尔积中选取属性间满足一定条件的元组

- A和B:分别为R和S上度数相等且可比的属性组
- θ:比较运算符
●连接运算从R和S的广义笛卡尔积R×S中选取R关系在A属性组上的值与S关系在B属性组上的值满足比较关系θ的元组
(3)两类常用连接运算
●等值连接(equijoin)
- θ为“=”的连接运算称为等值连接
- 从关系R与S的广义笛卡尔积中选取A、B属性值相等的那些元组,即等值连接为:
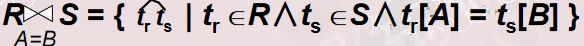
●自然连接(Natural join)
- 自然连接是一种特殊的等值连接
两个关系中进行比较的分量必须是相同的属性组
在结果中把重复的属性列去掉
- 自然连接的含义:R和S具有相同的属性组B

(4)●一般的连接操作是从行的角度进行运算。
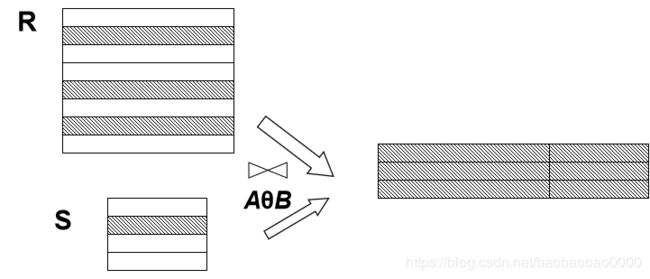
●自然连接还需要取消重复列,所以是同时从行和列的角度进行运算。
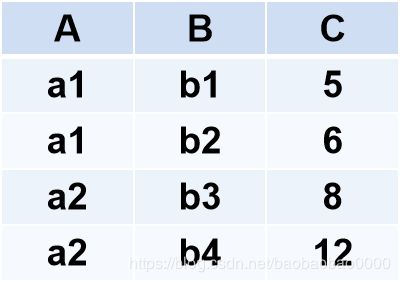
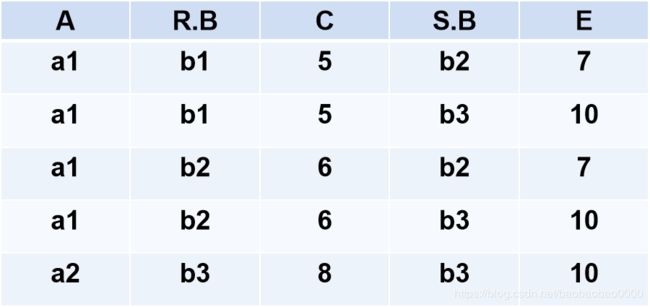
例2.44:
关系R和关系S 如下所示:
R
S
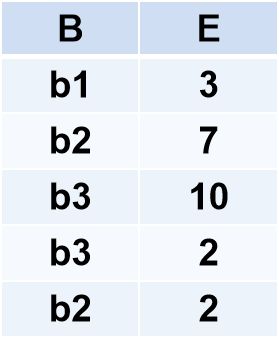
一般连接
的结果如下:
等值连接
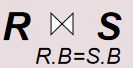
的结果如下:
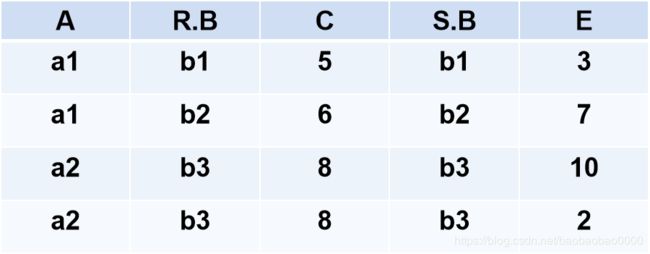
自然连接
![]()
的结果如下:
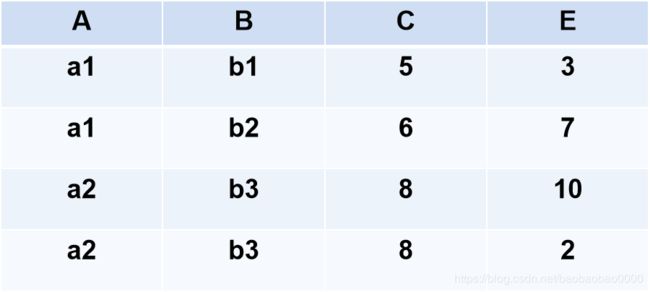
(5)悬浮元组(Dangling tuple)
- 两个关系R和S在做自然连接时,关系R中某些元组有可能在S中不存在公共属性上值相等的元组,从而造成R中这些元组在操作时被舍弃了,这些被舍弃的元组称为悬浮元组。
(6)外连接(Outer Join)
●如果把悬浮元组也保存在结果关系中,而在其他属性上填空值(Null),就叫做外连接
●左外连接(LEFT OUTER JOIN或LEFT JOIN)
- 只保留左边关系R中的悬浮元组
●右外连接(RIGHT OUTER JOIN或RIGHT JOIN)
- 只保留右边关系S中的悬浮元组
下图是例2.44中关系R和关系S的外连接
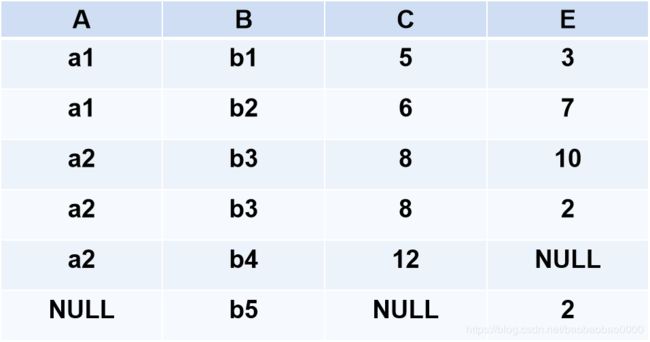
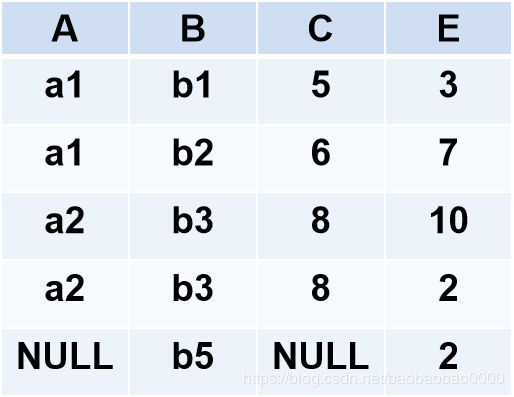
例2.8中关系R和关系S的左外连接

例2.8中关系R和关系S的右外连接
2.5 除运算
给定关系R (X,Y) 和S (Y,Z),其中X,Y,Z为属性组。R中的Y与S中的Y可以有不同的属性名,但必须出自相同的域集。R与S的除运算得到一个新的关系P(X),P是R中满足下列条件的元组在 X 属性列上的投影:元组在X上分量值x的象集Yx包含S在Y上投影的集合,记作:

(1)除操作是同时从行和列角度进行运算

例2.51
R
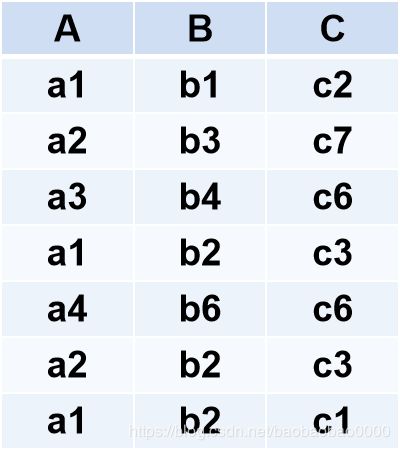
S
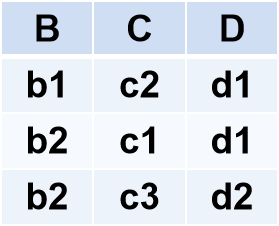
R÷S结果为:

(2)在关系R中,A可以取四个值{a1,a2,a3,a4}
a1的象集为 {(b1,c2),(b2,c3),(b2,c1)}
a2的象集为 {(b3,c7),(b2,c3)}
a3的象集为 {(b4,c6)}
a4的象集为 {(b6,c6)}
(3)S在(B,C)上的投影为
{(b1,c2),(b2,c1),(b2,c3) }
(4)只有a1的象集包含了S在(B,C)属性组上的投影, 所以 R÷S ={a1}
例2.541:
查询至少选修1号课程和3号课程的学生号码 。
首先建立一个临时关系K:

然后求:
![]()
![]()
关系表如下:
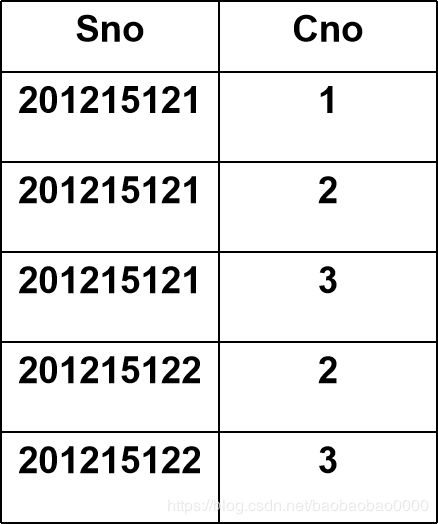
201215121象集{1,2,3}
201215122象集{2,3}
K={1,3}
于是结果为:
![]()
例2.542 查询选修了2号课程的学生的学号。
![]()
下面两个自己动手试试看,答案我下次公布在评论区。
例2.543 查询至少选修了一门其直接先行课为5号课程的学生姓名
例2.544 查询选修了全部课程的学生号码和姓名。
ps:其实本章节还有一个关系演算然而不考察,本科也没讲,所以这里就不说了
附上本章成电复试重点:
- 数据库的关系操作有哪些?各有什么作用?
答:
★关系模型中常用的关系操作包括:选择(Select)、投影(Project)、连接(Join)、
除(Divide)、并(Union)、交(Intersection)、差(Difference)、笛卡尔积等查
询(Query)操作和增加(Insert)、删除(Delete)、修改(Update)操作两大部分。
查询的表达能力是其中最主要的部分。
★关系操作的特点是集合操作方式,即操作的对象和结果都是集合。这种操作方式也称为一次一集合(set-at-a-time)的方式。相应地,非关系数据模型的数据操作方式则为一次一记录(record-at-a-time)的方式。