百度飞桨PaddlePaddle——入门CV疫情特辑学习
一、入门知识
1.1 必备数学知识
1.2 Python入门
字典
字典是将键(key)映射到值(value)的无序数据结构。值可以是任何值(列表,函数,字符串,任何东西)。键(key)必须是不可变的,例如,数字,字符串或元组。
示例
字典:我们查找的单词是key,查找的定义是值
# Defining a dictionary
webstersDict = {'person': 'a human being, whether an adult or child', 'marathon': 'a running race that is about 26 miles', 'resist': ' to remain strong against the force or effect of (something)', 'run': 'to move with haste; act quickly'}
webstersDict
{'marathon': 'a running race that is about 26 miles',
'person': 'a human being, whether an adult or child',
'resist': ' to remain strong against the force or effect of (something)',
'run': 'to move with haste; act quickly'}访问字典中的值
# Finding out the meaning of the word marathon
# dictionary[key]
webstersDict['marathon']
'a running race that is about 26 miles'1.3 PaddlePaddle快速入门
PaddlePaddle基础命令
PaddlePaddle是百度开源的深度学习框架,类似的深度学习框架还有谷歌的Tensorflow、Facebook的Pytorch等,在入门深度学习时,学会并使用一门常见的框架,可以让学习效率大大提升。在PaddlePaddle中,计算的对象是张量,我们可以先使用PaddlePaddle来计算一个[[1, 1], [1, 1]] * [[1, 1], [1, 1]]。
示例:计算常量的加法:1+1
1、首先导入PaddlePaddle库
import paddle.fluid as fluid2、定义两个张量的常量x1和x2,并指定它们的形状是[2, 2],并赋值为1铺满整个张量,类型为int64.
# 定义两个张量
x1 = fluid.layers.fill_constant(shape=[2, 2], value=1, dtype='int64')
x2 = fluid.layers.fill_constant(shape=[2, 2], value=1, dtype='int64')3、定义一个操作,该计算是将上面两个张量进行加法计算,并返回一个求和的算子。PaddlePaddle提供了大量的操作,比如加减乘除、三角函数等,读者可以在fluid.layers找到。
# 将两个张量求和
y1 = fluid.layers.sum(x=[x1, x2])4、创建一个解释器,可以在这里指定计算使用CPU或GPU。当使用CPUPlace()时使用的是CPU,如果是CUDAPlace()使用的是GPU。解析器是之后使用它来进行计算过的,比如在执行计算之前我们要先执行参数初始化的program也是要使用到解析器的,因为只有解析器才能执行program。
# 创建一个使用CPU的解释器
place = fluid.CPUPlace()
exe = fluid.executor.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())5、执行计算,program的参数值是主程序,不是上一步使用的是初始化参数的程序,program默认一共有两个,分别是default_startup_program()和default_main_program()。fetch_list参数的值是在解析器在run之后要输出的值,我们要输出计算加法之后输出结果值。最后计算得到的也是一个张量。
# 进行运算,并把y的结果输出
result = exe.run(program=fluid.default_main_program(),
fetch_list=[y1])
print(result)DAY 1 新冠疫情可视化
爬取3月31日当天丁香园公开的统计数据,根据累计确诊数,使用pyecharts绘制疫情分布图
一、数据准备
爬虫的过程:
1.发送请求(requests模块)
2.获取响应数据(服务器返回)
3.解析并提取数据(re正则)
4.保存数据
request模块:
requests是python实现的简单易用的HTTP库,官网地址:http://cn.python-requests.org/zh_CN/latest/
re模块:
re模块是python用于匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现
import json
import re
import requests
import datetime
today = datetime.date.today().strftime('%Y%m%d') #20200315
def crawl_dxy_data():
"""
爬取丁香园实时统计数据,保存到data目录下,以当前日期作为文件名,存JSON文件
"""
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia') #request.get()用于请求目标网站
print(response.status_code) # 打印状态码
try:
url_text = response.content.decode() #更推荐使用response.content.deocde()的方式获取响应的html页面
#print(url_text)
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch', #re.search():扫描字符串以查找正则表达式模式产生匹配项的第一个位置 ,然后返回相应的match对象。
url_text, re.S) #在字符串a中,包含换行符\n,在这种情况下:如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始;
#而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
texts = url_content.group() #获取匹配正则表达式的整体结果
content = texts.replace('window.getAreaStat = ', '').replace('}catch', '') #去除多余的字符
json_data = json.loads(content)
with open('data/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
except:
print('' % response.status_code)
def crawl_statistics_data():
"""
获取各个省份历史统计数据,保存到data目录下,存JSON文件
"""
with open('data/'+ today + '.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
statistics_data = {}
for province in json_array:
response = requests.get(province['statisticsData'])
try:
statistics_data[province['provinceShortName']] = json.loads(response.content.decode())['data']
except:
print(' for url: [%s]' % (response.status_code, province['statisticsData']))
with open("data/statistics_data.json", "w", encoding='UTF-8') as f:
json.dump(statistics_data, f, ensure_ascii=False)
if __name__ == '__main__':
crawl_dxy_data()
crawl_statistics_data() '''
安装第三方库pyecharts ,如果下载时出现断线和速度过慢的问题导致下载失败,可以尝试使用清华镜像
'''
#!pip install pyecharts
!pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyecharts
二、疫情地图
Echarts 是一个由百度开源的数据可视化工具,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 诞生了。pyecharts api可以参考:https://pyecharts.org/#/zh-cn/chart_api
使用 options 配置项,在 pyecharts 中,一切皆 Options。
主要分为全局配置组件和系列配置组件。
(1)系列配置项 set_series_opts(),可配置图元样式、文字样式、标签样式、点线样式等;
(2)全局配置项 set_global_opts(),可配置标题、动画、坐标轴、图例等;
2.1全国疫情地图
import json
import datetime
from pyecharts.charts import Map
from pyecharts import options as opts
# 读原始数据文件
today = datetime.date.today().strftime('%Y%m%d') #20200315
datafile = 'data/'+ today + '.json'
with open(datafile, 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
# 分析全国实时确诊数据:'confirmedCount'字段
china_data = []
for province in json_array:
china_data.append((province['provinceShortName'], province['confirmedCount']))
china_data = sorted(china_data, key=lambda x: x[1], reverse=True) #reverse=True,表示降序,反之升序
print(china_data)
# 全国疫情地图
# 自定义的每一段的范围,以及每一段的特别的样式。
pieces = [
{'min': 10000, 'color': '#540d0d'},
{'max': 9999, 'min': 1000, 'color': '#9c1414'},
{'max': 999, 'min': 500, 'color': '#d92727'},
{'max': 499, 'min': 100, 'color': '#ed3232'},
{'max': 99, 'min': 10, 'color': '#f27777'},
{'max': 9, 'min': 1, 'color': '#f7adad'},
{'max': 0, 'color': '#f7e4e4'},
]
labels = [data[0] for data in china_data]
counts = [data[1] for data in china_data]
m = Map()
m.add("累计确诊", [list(z) for z in zip(labels, counts)], 'china')
#系列配置项,可配置图元样式、文字样式、标签样式、点线样式等
m.set_series_opts(label_opts=opts.LabelOpts(font_size=12),
is_show=False)
#全局配置项,可配置标题、动画、坐标轴、图例等
m.set_global_opts(title_opts=opts.TitleOpts(title='全国实时确诊数据',
subtitle='数据来源:丁香园'),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(pieces=pieces,
is_piecewise=True, #是否为分段型
is_show=True)) #是否显示视觉映射配置
#render()会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件,也可以传入路径参数,如 m.render("mycharts.html")
m.render(path='/home/aistudio/data/全国实时确诊数据.html')
[('湖北', 67801), ('广东', 1494), ('河南', 1276), ('浙江', 1257), ('湖南', 1018), ('安徽', 990), ('江西', 937), ('山东', 774), ('香港', 714), ('江苏', 646), ('北京运行结果
 全国实时疫情地图
全国实时疫情地图
2.2 全国疫情扇形图
import json
import datetime
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
# 读原始数据文件
today = datetime.date.today().strftime('%Y%m%d') #20200315
datafile = 'data/'+ today + '.json'
with open(datafile, 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
# 分析全国实时确诊数据:'confirmedCount'字段
china_data = []
for province in json_array:
china_data.append((province['provinceShortName'], province['confirmedCount']))
china_data = sorted(china_data, key=lambda x: x[1], reverse=True) #reverse=True,表示降序,反之升序
print(china_data)
# 全国疫情地图
# 自定义的每一段的范围,以及每一段的特别的样式。
pieces = [
{'min': 10000, 'color': '#540d0d'},
{'max': 9999, 'min': 1000, 'color': '#9c1414'},
{'max': 999, 'min': 500, 'color': '#d92727'},
{'max': 499, 'min': 100, 'color': '#ed3232'},
{'max': 99, 'min': 10, 'color': '#f27777'},
{'max': 9, 'min': 1, 'color': '#f7adad'},
{'max': 0, 'color': '#f7e4e4'},
]
labels = [data[0] for data in china_data]
counts = [data[1] for data in china_data]
c = (
Pie()
.add("累计确诊", [list(z) for z in zip(labels, counts)],center=["35%", "65%"],radius=["20%", "50%"])
.set_global_opts(title_opts=opts.TitleOpts(title="全国实时确诊数据",subtitle='数据来源:丁香园'),
legend_opts=opts.LegendOpts(pos_left="60%"),)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render("data/全国确诊数据.html")
)
[('湖北', 67801), ('广东', 1494), ('河南', 1276), ('浙江', 1257), ('湖南', 1018), ('安徽', 990), ('江西', 937), ('山东', 774), ('香港', 714), ('江苏', 646), ('运行结果
 全国实时确诊
全国实时确诊
DAY 2 手势识别
手势识别是一个分类任务,采用了AlexNet为basebone进行手势识别,检测0-9共10个手势类别。
AlexNet:Alex Krizhevsky等人在2012年提出了AlexNet, 并应用在大尺寸图片数据集ImageNet上,获得了2012年ImageNet比赛冠军(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。
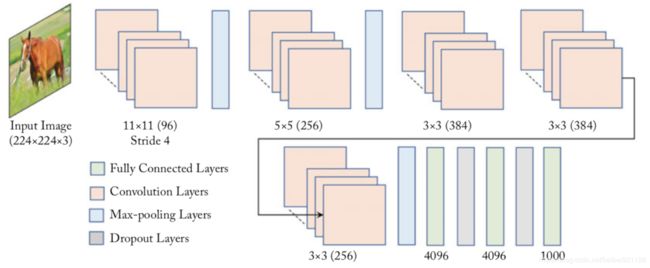 AlexNet模型网络结构示意图
AlexNet模型网络结构示意图
class AlexNet(fluid.dygraph.Layer):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
self.conv1 = Conv2D(num_channels=3, num_filters=96, filter_size=11, stride=4, padding=5, act='relu')
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(num_channels=96, num_filters=256, filter_size=5, stride=1, padding=2, act='relu')
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv3 = Conv2D(num_channels=256, num_filters=384, filter_size=3, stride=1, padding=1, act='relu')
self.conv4 = Conv2D(num_channels=384, num_filters=384, filter_size=3, stride=1, padding=1, act='relu')
self.conv5 = Conv2D(num_channels=384, num_filters=256, filter_size=3, stride=1, padding=1, act='relu')
self.pool5 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.fc1 = Linear(input_dim=12544, output_dim=4096, act='relu')
self.drop_ratio1 = 0.5
self.fc2 = Linear(input_dim=4096, output_dim=4096, act='relu')
self.drop_ratio2 = 0.5
self.fc3 = Linear(input_dim=4096, output_dim=num_classes, act='softmax')
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.pool5(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
# 在全连接之后使用dropout抑制过拟合
x= fluid.layers.dropout(x, self.drop_ratio1)
x = self.fc2(x)
# 在全连接之后使用dropout抑制过拟合
x = fluid.layers.dropout(x, self.drop_ratio2)
y = self.fc3(x)
return y 检测结果
检测结果
DAY 3 车牌检测
采用与DAY2相同的AlexNet进行检测。
DAY 4 口罩检测
口罩识别,是指可以有效检测在密集人流区域中携带和未携戴口罩的所有人脸,同时判断该者是否佩戴口罩。通常由两个功能单元组成,可以分别完成口罩人脸的检测和口罩人脸的分类。
采用了VGG-16网络进行检测,输出结果中,0代表佩戴口罩,1代表未佩戴口罩。
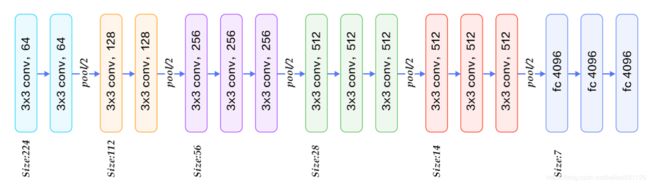 VGG
VGG
VGG的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,上图展示一个16层的网络结构。
class ConvPool(fluid.dygraph.Layer):
'''卷积+池化'''
def __init__(self,
num_channels,
num_filters,
filter_size,
pool_size,
pool_stride,
groups,
pool_padding=0,
pool_type='max',
conv_stride=1,
conv_padding=0,
act=None):
super(ConvPool, self).__init__()
self._conv2d_list = []
for i in range(groups):
conv2d = self.add_sublayer( #返回一个由所有子层组成的列表。
'bb_%d' % i,
fluid.dygraph.Conv2D(
num_channels=num_channels, #通道数
num_filters=num_filters, #卷积核个数
filter_size=filter_size, #卷积核大小
stride=conv_stride, #步长
padding=conv_padding, #padding大小,默认为0
act=act)
)
self._conv2d_list.append(conv2d)
self._pool2d = fluid.dygraph.Pool2D(
pool_size=pool_size, #池化核大小
pool_type=pool_type, #池化类型,默认是最大池化
pool_stride=pool_stride, #池化步长
pool_padding=pool_padding #填充大小
)
def forward(self, inputs):
x = inputs
for conv in self._conv2d_list:
x = conv(x)
x = self._pool2d(x)
return xclass VGGNet(fluid.dygraph.Layer):
'''
VGG网络
'''
def __init__(self):
super(VGGNet, self).__init__()
self.convpool1=ConvPool(3,64,3,2,2,2, act='relu')
self.convpool2=ConvPool(64,128,3,2,2,2, act='relu')
self.convpool3=ConvPool(128,256,3,2,2,3, act='relu')
self.convpool4=ConvPool(256,512,3,2,2,3, act='relu')
self.convpool5=ConvPool(512,512,3,2,2,3, act='relu')
self.fc1=fluid.dygraph.Linear(12800,4096,act='relu')
self.drop1_ratio = 0.5
self.fc2=fluid.dygraph.Linear(4096,4096,act='relu')
self.drop2_ratio = 0.5
self.fc3=fluid.dygraph.Linear(4096,2,act='softmax')
def forward(self, inputs, label=None):
"""前向计算"""
x = self.convpool1(inputs)
x = self.convpool2(x)
x = self.convpool3(x)
x = self.convpool4(x)
x = self.convpool5(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = fluid.layers.dropout(self.fc1(x), self.drop1_ratio)
x = fluid.layers.dropout(self.fc2(x), self.drop2_ratio)
y = self.fc3(x)
if label is None:
return y
else:
#pred = fluid.layers.softmax(x)
#pred2 = pred*(-1.0)+1.0
# pred = fluid.layers.concat([pred2,pred],axis= 1)
acc = fluid.layers.accuracy(input=y,label=label)
return y, acc检测结果
 口罩检测结果
口罩检测结果
DAY 5 人流密度比赛
采用了密度图方式检测,效果不理想。
DAY 6 PaddleSlim模型压缩
按照配置在train_program和val_program中加入量化和反量化op.
#剪裁训练网络
pruner = slim.prune.Pruner()
print("FLOPs before pruning: {}".format(slim.analysis.flops(train_program)))
pruned_program, _, _ = pruner.prune(
train_program,
fluid.global_scope(),
params=["conv2_1_sep_weights", "conv2_2_sep_weights"],
ratios=[0.33] * 2,
place=place)
print("FLOPs after pruning: {}".format(slim.analysis.flops(pruned_program)))FLOPs before pruning: 10896832.0 FLOPs after pruning: 10253707.0
#剪裁测试网络
pruner = slim.prune.Pruner()
print("FLOPs before pruning: {}".format(slim.analysis.flops(val_program)))
pruned_val_program, _, _ = pruner.prune(
val_program,
fluid.global_scope(),
params=["conv2_1_sep_weights", "conv2_2_sep_weights"],
ratios=[0.33] * 2,
place=place,
only_graph=True)
print("FLOPs after pruning: {}".format(slim.analysis.flops(pruned_val_program)))FLOPs before pruning: 10896832.0 FLOPs after pruning: 10253707.0