环形缓冲区的实现原理(ring buffer)
就好比两个人围着一张圆形的桌子在追逐,跑的人被网络IO线程所控制,当写入数据时,这个人就往前跑;追的人就是逻辑线程,会一直往前追直到追上跑的人。如果追上了怎么办?那就是没有数据可读了,先等会儿呗,等跑的人向前跑几步了再追,总不能让游戏没得玩了吧。那要是追的人跑的太慢,跑的人转了一圈过来反追上追的人了呢?那您也先歇会儿吧。要是一直这么反着追,估计您就只能换一个跑的更快的追逐者了,要不这游戏还真没法玩下去。
前面我们特别强调了,按照严格的先进先出顺序进行处理,这是环形缓冲区的使用必须遵守的一项要求。也就是,大家都得遵守规定,追的人不能从桌子上跨过去,跑的人当然也不允许反过来跑。至于为什么,不需要多做解释了吧。
环形缓冲区是一项很好的技术,不用频繁的分配内存,而且在大多数情况下,内存的反复使用也使得我们能用更少的内存块做更多的事。
在网络IO线程中,我们会为每一个连接都准备一个环形缓冲区,用于临时存放接收到的数据,以应付半包及粘包的情况。在解包及解密完成后,我们会将这个数据包复制到逻辑线程消息队列中,如果我们只使用一个队列,那这里也将会是个环形缓冲区,IO线程往里写,逻辑线程在后面读,互相追逐。可要是我们使用了前面介绍的优化方案后,可能这里便不再需要环形缓冲区了,至少我们并不再需要他们是环形的了。因为我们对同一个队列不再会出现同时读和写的情况,每个队列在写满后交给逻辑线程去读,逻辑线程读完后清空队列再交给IO线程去写,一段固定大小的缓冲区即可。没关系,这么好的技术,在别的地方一定也会用到的。
在通信程序中,经常使用环形缓冲区作为数据结构来存放通信中发送和接收的数据。环形缓冲区是一个先进先出的循环缓冲区,可以向通信程序提供对缓冲区的互斥访问。
1、环形缓冲区的实现原理
环形缓冲区通常有一个读指针和一个写指针。读指针指向环形缓冲区中可读的数据,写指针指向环形缓冲区中可写的缓冲区。通过移动读指针和写指针就可以实现缓冲区的数据读取和写入。在通常情况下,环形缓冲区的读用户仅仅会影响读指针,而写用户仅仅会影响写指针。如果仅仅有一个读用户和一个写用户,那么不需要添加互斥保护机制就可以保证数据的正确性。如果有多个读写用户访问环形缓冲区,那么必须添加互斥保护机制来确保多个用户互斥访问环形缓冲区。
图1、图2和图3是一个环形缓冲区的运行示意图。图1是环形缓冲区的初始状态,可以看到读指针和写指针都指向第一个缓冲区处;图2是向环形缓冲区中添加了一个数据后的情况,可以看到写指针已经移动到数据块2的位置,而读指针没有移动;图3是环形缓冲区进行了读取和添加后的状态,可以看到环形缓冲区中已经添加了两个数据,已经读取了一个数据。
个数据。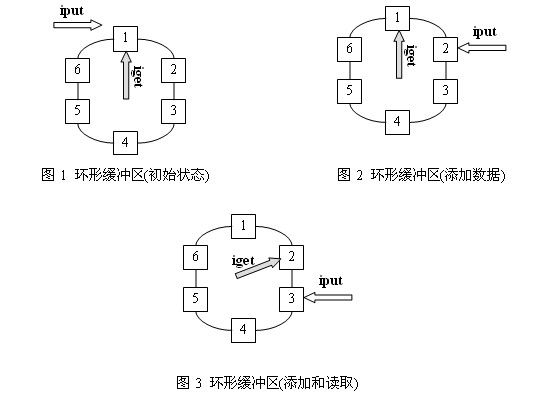
2、实例:环形缓冲区的实现
环形缓冲区是数据通信程序中使用最为广泛的数据结构之一,下面的代码,实现了一个环形缓冲区:
/*ringbuf .c*/
#include
#include
#define NMAX 8
int iput = 0; /* 环形缓冲区的当前放入位置 */
int iget = 0; /* 缓冲区的当前取出位置 */
int n = 0; /* 环形缓冲区中的元素总数量 */
double buffer[NMAX];
/* 环形缓冲区的地址编号计算函数,如果到达唤醒缓冲区的尾部,将绕回到头部。
环形缓冲区的有效地址编号为:0到(NMAX-1)
*/
int addring (int i)
{
return (i+1) == NMAX ? 0 : i+1;
}
/* 从环形缓冲区中取一个元素 */
double get(void)
{
int pos;
if (n>0){
Pos = iget;
iget = addring(iget);
n--;
return buffer[pos];
}
else {
printf(“Buffer is empty\n”);
return 0.0;
}
/* 向环形缓冲区中放入一个元素*/
void put(double z)
{
if (n buffer[iput]=z; iput = addring(iput); n++; } else printf(“Buffer is full\n”); } int main{void) { chat opera[5]; double z; do { printf(“Please input p|g|e?”); scanf(“%s”, &opera); switch(tolower(opera[0])){ case ‘p’: /* put */ printf(“Please input a float number?”); scanf(“%lf”, &z); put(z); break; case ‘g’: /* get */ z = get(); printf(“%8.2f from Buffer\n”, z); break; case ‘e’: printf(“End\n”); break; default: printf(“%s - Operation command error! \n”, opera); }/* end switch */ }while(opera[0] != ’e’); return 0; } 在CAN通信卡设备驱动程序中,为了增强CAN通信卡的通信能力、提高通信效率,根据CAN的特点,使用两级缓冲区结构,即直接面向CAN通信卡的收发缓 冲区和直接面向系统调用的接收帧缓冲区。 通讯中的收发缓冲区一般采用环形队列(或称为FIFO队列),使用环形的缓冲区可以使得读写并发执行,读进程和写进程可以采用“生产者和消费者”的模型来 访问缓冲区,从而方便了缓存的使用和管理。然而,环形缓冲区的执行效率并不高,每读一个字节之前,需要判断缓冲区是否为空,并且移动尾指针时需要进行“折行处理”(即当指针指到缓冲区内存的末尾时,需要新将其定向到缓冲区的首地址);每写一个字节之前,需要判断缓区是否为,并且移动尾指针时同样需要进行“ 折行处理”。程序大部分的执行过程都是在处理个别极端的情况。只有小部分在进行实际有效的操作。这就是软件工程中所谓的“8比2”关系。结合CAN通讯实际情况,在本设计中对环形队列进行了改进,可以较大地提高数据的收发效率。 由于CAN通信卡上接收和发送缓冲器每次只接收一帧CAN数据,而且根据CAN的通讯协议,CAN控制器的发送数据由1个字节的标识符、一个字节的RTR 和DLC位及8个字节的数据区组成,共10个字节;接收缓冲器与之类似,也有10个字节的寄存器。所以CAN控制器收的数据是短小的定长帧(数据可以不满 8字节)。 于是,采用度为10字节的数据块业分配内存比较方便,即每次需要内存缓冲区时,直接分配10个字节,由于这10个字节的地址是线性的,故不需要进行“折行”处理。更重要的是,在向缓冲区中写数据时,只需要判断一次是否有空闲块并获取其块首指针就可以了,从而减少了重复性的条件判断,大大提高了程序的执行效率;同样在从缓冲队列中读取数据时,也是一次读取10字节的数据块,同样减少了重复性的条件判断。 在CAN卡驱动程序中采用如下所示的称为“Block_Ring_t”的数据结构作为收发数据的缓冲区: typedef struct { long signature; unsigned char *head_p; unsigned char *tail_p; unsigned char *begin_p; unsigned char *end_p; unsigned char buffer [BLOCK_RING_BUFFER_SIZE]; int usedbytes; }Block_Ring_t; 该数据结构在通用的环形队列上增加了一个数据成员usedbytes,它表示当前缓冲区中有多少字节的空间被占用了。使用usedbytes,可以比较方 便地进行缓冲区满或空的判断。当usedbytes=0时,缓冲区空;当usedbytes=BLOCK_RING_BUFFER_SIZE时,缓冲区 满。 本驱动程序除了收发缓冲区外,还有一个接收帧缓冲区,接收帧队列负责管理经Hilon A协议解包后得到的数据帧。由于有可能要同接收多个数据帧,而根据CAN总线遥通信协议,高优先级的报文将抢占总线,则有可能在接收一个低优先级且被分为 好几段发送的数据帧时,被一个优先级高的数据帧打断。这样会出现同时接收到多个数据帧中的数据包,因而需要有个接收队列对同时接收的数据帧进行管理。 当有新的数据包到来时,应根据addr(通讯地址),mode(通讯方式),index(数据包的序号)来判断是否是新的数据帧。如果是,则开辟新的 frame_node;否则如果已有相应的帧节点存地,则将数据附加到该帧的末尾;在插入数据的同时,应该检查接收包的序号是否正确,如不正确将丢弃这包 数据。 每次建立新的frame_node时,需要向frame_queue申请内存空间;当frame_queue已满时,释放掉队首的节点(最早接收的但未完 成的帧)并返回该节点的指针。 当系统调用读取了接收帧后,释放该节点空间,使设备驱动程序可以重新使用该节点。 形缓冲区:环形缓冲队列学习 来源: 发布时间:星期四, 2008年9月25日 浏览:117次 评论:0 项目中需要线程之间共享一个缓冲FIFO队列,一个线程往队列中添数据,另一个线程取数据(经典的生产者-消费者问题)。开始考虑用STL的vector 容器, 但不需要随机访问,频繁的删除最前的元素引起内存移动,降低了效率。使用LinkList做队列的话,也需要频繁分配和释放结点内存。于是自己实现一个有 限大小的FIFO队列,直接采用数组进行环形读取。 队列的读写需要在外部进程线程同步(另外写了一个RWGuard类, 见另一文) 到项目的针对性简单性,实现了一个简单的环形缓冲队列,比STL的vector简单 PS: 第一次使用模板,原来类模板的定义要放在.h 文件中, 不然会出现连接错误。 template _Type pop_front(); bool IsEmpty() { template template template //前面弹出一个元素 } //从尾部加入队列 http://hi.baidu.com/zkheartboy/blog/item/f162b20fdbf250eeab6457be.html 实现环形缓冲区的通用类: http://hi.baidu.com/broland/blog/item/6a6ddf813f3425c69123d956.html http://hi.baidu.com/uc100200/blog/item/c6d670543df4544fd00906ac.html http://hi.baidu.com/282280072/blog/item/9927685090cbb9928d543075.html ★环形缓冲区介绍 环形缓冲区是生产者和消费者模型中常用的数据结构。生产者将数据放入数组的尾端,而消费者从数组的另一端移走数据,当达到数组的尾部时,生产者绕回到数组的头部。 如果只有一个生产者和一个消费者,那么就可以做到免锁访问环形缓冲区(Ring Buffer)。写入索引只允许生产者访问并修改,只要写入者在更新索引之前将新的值保存到缓冲区中,则读者将始终看到一致的数据结构。同理,读取索引也只允许消费者访问并修改。 环形缓冲区实现原理图 如图所示,当读者和写者指针相等时,表明缓冲区是空的,而只要写入指针在读取指针后面时,表明缓冲区已满。 ★环形缓冲区内部结构
class CShareQueue
{
public:
CShareQueue();
CShareQueue(unsigned int bufsize);
virtual ~CShareQueue();
bool push_back( _Type item);
//返回容量
unsigned int capacity() { //warning:需要外部数据一致性
return m_capacity;
}
//返回当前个数
unsigned int size() { //warning:需要外部数据一致性
return m_size;
}
//是否满//warning: 需要外部控制数据一致性
bool IsFull() {
return (m_size >= m_capacity);
}
return (m_size == 0);
}
protected:
UINT m_head;
UINT m_tail;
UINT m_size;
UINT m_capacity;
_Type *pBuf;
};
CShareQueue<_Type>::CShareQueue() : m_head(0), m_tail(0), m_size(0)
{
pBuf = new _Type[512];//默认512
m_capacity = 512;
}
CShareQueue<_Type>::CShareQueue(unsigned int bufsize) : m_head(0), m_tail(0)
{
if( bufsize > 512 || bufsize < 1)
{
pBuf = new _Type[512];
m_capacity = 512;
}
else
{
pBuf = new _Type[bufsize];
m_capacity = bufsize;
}
}
CShareQueue<_Type>::~CShareQueue()
{
delete[] pBuf;
pBuf = NULL;
m_head = m_tail = m_size = m_capacity = 0;
}
template
_Type CShareQueue<_Type>::pop_front()
{
if( IsEmpty() )
{
return NULL;
}
_Type itemtmp;
itemtmp = pBuf[m_head];
m_head = (m_head + 1) % m_capacity;
--m_size;
return itemtmp;
template
bool CShareQueue<_Type>::push_back( _Type item)
{
if ( IsFull() )
{
return FALSE;
}
pBuf[m_tail] = item;
m_tail = (m_tail + 1) % m_capacity;
++m_size;
return TRUE;
}
#endif
◇外部接口相似
在介绍环形缓冲区之前,咱们先来回顾一下普通的队列。普通的队列有一个写入端和一个读出端。队列为空的时候,读出端无法读取数据;当队列满(达到最大尺寸)时,写入端无法写入数据。
对于使用者来讲,环形缓冲区和队列缓冲区是一样的。它也有一个写入端(用于push)和一个读出端(用于pop),也有缓冲区“满”和“空”的状态。所以,从队列缓冲区切换到环形缓冲区,对于使用者来说能比较平滑地过渡。
◇内部结构迥异
虽然两者的对外接口差不多,但是内部结构和运作机制有很大差别。队列的内部结构此处就不多啰嗦了。重点介绍一下环形缓冲区的内部结构。
大伙儿可以把环形缓冲区的读出端(以下简称R)和写入端(以下简称W)想象成是两个人在体育场跑道上追逐(R追W)。当R追上W的时候,就是缓冲区为空;当W追上R的时候(W比R多跑一圈),就是缓冲区满。
为了形象起见,去找来一张图并略作修改,如下:
从上图可以看出,环形缓冲区所有的push和pop操作都是在一个固定 的存储空间内进行。而队列缓冲区在push的时候,可能会分配存储空间用于存储新元素;在pop时,可能会释放废弃元素的存储空间。所以环形方式相比队列方式,少掉了对于缓冲区元素所用存储空间的分配、释放。这是环形缓冲区的一个主要优势。
★环形缓冲区的实现
如果你手头已经有现成的环形缓冲区可供使用,并且你对环形缓冲区的内部实现不感兴趣,可以跳过这段。
◇数组方式 vs 链表方式
环形缓冲区的内部实现,即可基于数组(此处的数组,泛指连续存储空间)实现,也可基于链表实现。
数组在物理存储上是一维的连续线性结构,可以在初始化时,把存储空间一次性 分配好,这是数组方式的优点。但是要使用数组来模拟环,你必须在逻辑上把数组的头和尾相连。在顺序遍历数组时,对尾部元素(最后一个元素)要作一下特殊处理。访问尾部元素的下一个元素时,要重新回到头部元素(第0个元素)。如下图所示:
使用链表的方式,正好和数组相反。链表省去了头尾相连的特殊处理。但是链表在初始化的时候比较繁琐,而且在有些场合(比如后面提到的跨进程的IPC)不太方便使用。
◇读写操作
环形缓冲区要维护两个索引,分别对应写入端(W)和读取端(R)。写入(push)的时候,先确保环没满,然后把数据复制到W所对应的元素,最后W指向下一个元素;读取(pop)的时候,先确保环没空,然后返回R对应的元素,最后R指向下一个元素。
◇判断“空”和“满”
上述的操作并不复杂,不过有一个小小的麻烦:空环和满环的时候,R和W都指向同一个位置!这样就无法判断到底是“空”还是“满”。大体上有两种方法可以解决该问题。
办法1:始终保持一个元素不用
当空环的时候,R和W重叠。当W比R跑得快,追到距离R还有一个元素间隔的时候,就认为环已经满。当环内元素占用的存储空间较大的时候,这种办法显得很土(浪费空间)。
办法2:维护额外变量
如果不喜欢上述办法,还可以采用额外的变量来解决。比如可以用一个整数记录当前环中已经保存的元素个数(该整数>=0)。当R和W重叠的时候,通过该变量就可以知道是“空”还是“满”。
◇元素的存储
由于环形缓冲区本身就是要降低存储空间分配的开销,因此缓冲区中元素的类型要选好。尽量存储值 类型的数据,而不要存储指针(引用) 类型的数据。因为指针类型的数据又会引起存储空间(比如堆内存)的分配和释放,使得环形缓冲区的效果打折扣。
★应用场合
刚才介绍了环形缓冲区内部的实现机制。按照前一个帖子 的惯例,我们来介绍一下在线程和进程方式下的使用。
如果你所使用的编程语言和开发库中带有现成的、成熟的 环形缓冲区,强烈建议使用现成的库,不要重新制造轮子;确实找不到现成的,才考虑自己实现。如果你纯粹是业余时间练练手,那另当别论。
◇用于并发线程
和线程中的队列缓冲区类似,线程中的环形缓冲区也要考虑线程安全的问题。除非你使用的环形缓冲区的库已经帮你实现了线程安全,否则你还是得自己动手搞定。线程方式下的环形缓冲区用得比较多,相关的网上资料也多,下面就大致介绍几个。
对于C++的程序员,强烈推荐使用boost 提供的circular_buffer 模板,该模板最开始是在boost 1.35版本中引入的。鉴于boost在C++社区中的地位,大伙儿应该可以放心使用该模板。
对于C程序员,可以去看看开源项目circbuf ,不过该项目是GPL协议的,不太爽;而且活跃度不太高;而且只有一个开发人员。大伙儿慎用!建议只拿它当参考。
对于C#程序员,可以参考CodeProject上的一个示例 。
◇用于并发进程
进程间的环形缓冲区,似乎少有现成的库可用。大伙儿只好自己动手、丰衣足食了。
适用于进程间环形缓冲的IPC类型,常见的有共享内存 和文件。在这两种方式上进行环形缓冲,通常都采用数组的方式实现。程序事先分配好一个固定长度的存储空间,然后具体的读写操作、判断“空”和“满”、元素存储等细节就可参照前面所说的来进行。
共享内存方式的性能很好,适用于数据流量很大的场景。但是有些语言(比如Java)对于共享内存不支持。因此,该方式在多语言协同开发的系统中,会有一定的局限性。
而文件方式在编程语言方面支持很好,几乎所有编程语言都支持操作文件。但它可能会受限于磁盘读写(Disk I/O)的性能。所以文件方式不太适合于快速数据传输;但是对于某些“数据单元 ”很大的场合,文件方式是值得考虑的。
对于进程间的环形缓冲区,同样要考虑好进程间的同步、互斥等问题。