日志分析系列之平台实现
本系列故事纯属虚构,如有雷同实属巧合
平台实现前的说明
小B在给老板汇报了"统一日志分析平台"项目后,老板拍板立即开始做,争取下一次能及时发现攻击并且追踪攻击者。于是小B开始分析了市面上商业与开源的日志分析平台架构,大家都神似如下图:
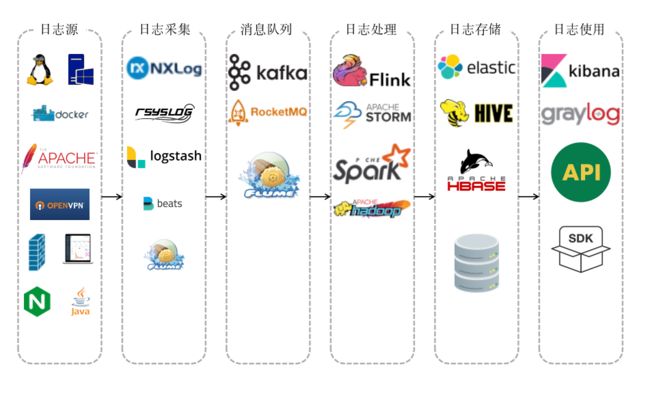
知道了架构如何,接下来的关键就是每层之间选择什么样的产品了。关于如何选择,小B推荐了几个方面:
- 已有架构:避免基础能力的重复,使用目前IT基础框架中已有的东西。假设运维已经有一套ELK,就没有必要重复搭建,只需要与之结合优化数据源与增加安全分析场景即可。
- 技术实力:负责统一日志分析平台人员的技能栈。
- 产品自身优劣:不同产品有各自最适用的场景,所以选择合理产品是核心依据。
小B在选择产品时,参考了一些些资料(见参考资料)。
在经过一番对比之后,小B最终选择了以下产品来实现统一日志分析平台:
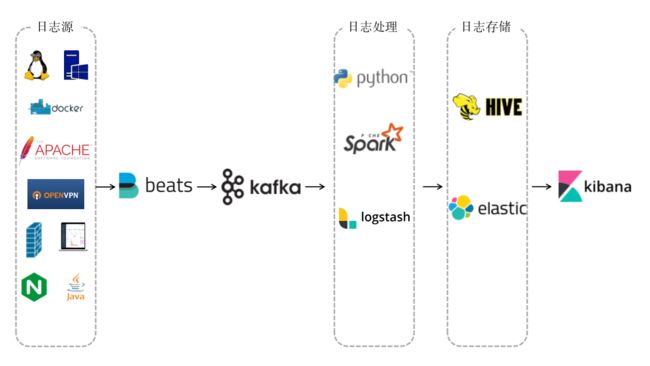
下面就容小B细细道来实现统一日志分析平台的那些心酸历程:(如果大家尝试复现小B的统一日志分析平台,请优先阅读踩坑记录,在文章末尾)
小B的统一日志分析平台结构(简易版,实际要复杂的多,这里只是一个Demo环境):
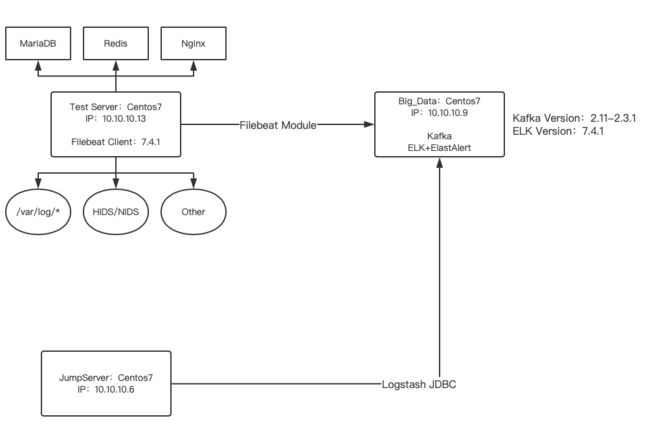
搭建过程,我就不一一描述了,搭建自己可以查询相关产品的安装文档或者:https://bloodzer0.github.io/ossa
实现日志采集处理与展示
服务器日志
首先关注的是服务器上的日志,Q公司所有的服务器都是Linux(Centos7.x),极大的减少了小B的工作:
服务器日志采集
/var/log/audit/audit.log:审计日志,跟用户相关的日志。/var/log/cron:记录与系统定时任务相关的日志。/var/log/messages:记录系统中主要信息的日志。/var/log/secure:记录验证和授权方面信息的日志,如:ssh登录、su切换用户、sudo授权等。/var/log/yum.log:记录yum安装软件信息。
关于服务器日志采集filebeat提供了两种采集方法:
- 方法一:直接写配置文件采集:
vim /etc/filebeat/filebeat.yml。 - 方法二:使用filebeat模块来收集,使用模块收集也是我们本次采用的方法。因为使用模块内置了pipeline可以解析服务器日志,并且在Kibana中提供了很多图表,减少我们的工作时间。备注:这里有坑,详情请看踩坑0x02
# 首先在我们的测试服务器上安装filebeat
rpm -ivh filebeat-7.4.1-x86_64.rpm
# 修改filebeat配置文件中的ES和Kibana地址,并初始化filebeat
vim /etc/filebeat/filebeat.yml
setup.kibana:
host: "10.10.10.9:5601"
output.elasticsearch:
hosts: ["10.10.10.9:9200"]
# 初始化filebeat
filebeat setup
# 启动filebeat模块
filebeat modules enable system
filebeat modules enable auditd
# 初始化filebeat模块的pipelines
filebeat setup --pipelines --modules system
filebeat setup --pipelines --modules auditd
# 修改system模块中日志文件路径
vim /etc/filebeat/modules.d/system.yml
- module: system
syslog:
enabled: true
var.paths: ["/var/log/messages"]
auth:
enabled: true
var.paths: ["/var/log/secure"]
# 修改audit模块中日志文件路径
vim /etc/filebeat/modules.d/auditd.yml
- module: auditd
log:
enabled: true
var.paths: ["/var/log/audit/audit.log"]
# 修改filebeat配置文件中输出 为Kafka
vim /etc/filebeat/filebeat.yml
# output.elasticsearch:
# hosts: ["10.10.10.9:9200"]
output.kafka:
hosts: ["10.10.10.9:9092"]
topics:
# 这里的含义:当存在@metadata.pipeline字段时(这个字段是使用module默认生成的字段),topic命名为%{[service.type]}-%{[fileset.name]}
# 在这里推荐大家,如果不想使用我这种命名方式,可以使用kafka消费者查看详细信息,从信息中获取字段来命名
- topic: '%{[service.type]}-%{[fileset.name]}'
when.has_fields: ["@metadata.pipeline"]
# 测试配置文件
filebeat test config -c /etc/filebeat/filebeat.yml
# 启动filebeat
filebeat -e
一旦filebeat开始工作,我们就可以看到在kafka服务器上新增了三个topic:
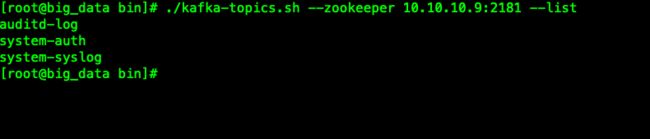
这里我使用kafka消费topic查看日志消息内容,大家使用不同命名格式时也可以从这里获取。甚至可以在每一个topic的名称中包含客户端信息。

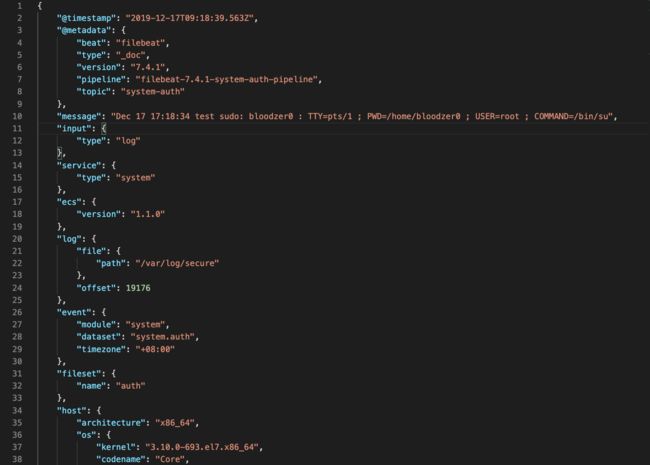
接下来我们需要使用logstash接受kafka的消息,并输出到ES中。需要注意的是,由于我们使用的是filebeat采集并且在ES与Kibana的配置中也是使用filebeat开头的template信息,所以我们输出的index前缀不要轻易修改,可以在中间添加我们需要的信息。
# 创建Logstash配置文件
vim /etc/logstash/conf.d/system.conf
input {
kafka {
bootstrap_servers => "10.10.10.9:9092"
topics => ["system-auth","system-syslog","auditd-log"]
codec => json
}
}
output {
if [@metadata][pipeline] and [@metadata][topic] == "auditd-log" {
elasticsearch {
hosts => ["10.10.10.9:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-audit-log-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
}
}
else if [@metadata][pipeline] and [@metadata][topic] == "system-syslog" {
elasticsearch {
hosts => ["10.10.10.9:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-system-syslog-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
}
}
# **********
}
# 启动Logstash
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d
# 查看Kibana中的索引信息
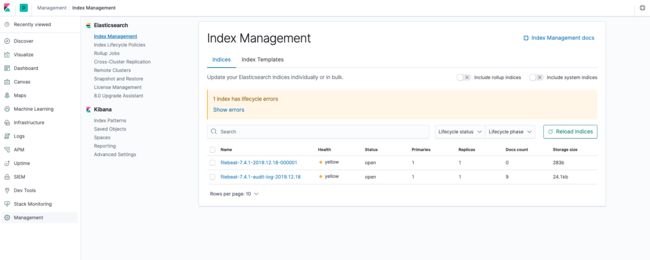
服务器日志展示
当一切完成后,我们可以在Kibana的Dashboard中查看默认配置好的图表:
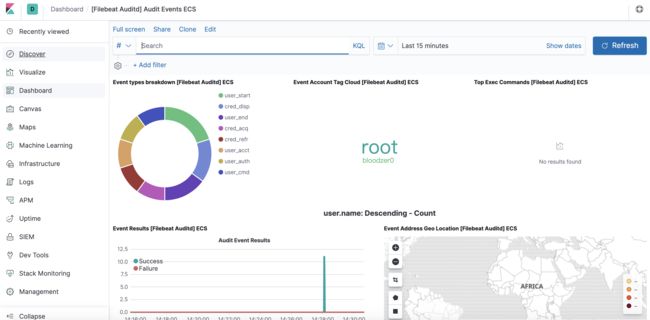
总结一下: 对于服务器日志的收集处理小B觉得,如果你后续还考虑接入入侵检测与防护系统的日志的话,对于服务器日志这块相对可以忽略部分,因为这里能够分析处理的日志内容在入侵检测与防护日志中也能体现。
Web日志
Q公司使用的Web服务器是Nginx,所以只需要对日志统一化,就很好处理
Web日志采集
- 方式一:使用Filebeat Module,但是如果自定义了日志格式,需要修改Filebeat的pipeline规则:
vim /usr/share/filebeat/module/nginx/access/ingest/default.json - 方式二:自己写Pattern解析,我们这里使用此种方法。
# 首先修改采集端filebeat的配置
vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
paths:
- /opt/nginx/logs/access.log
fields:
nginx: access
json.keys_under_root: true
json.overwrite_keys: true
output.kafka:
hosts: ["10.10.10.9:9092"]
topics:
- topic: '%{[service.type]}-%{[fileset.name]}'
when.has_fields: ["@metadata.pipeline"]
- topic: 'nginx-access'
when.has_fields: ["fields.nginx"]
# 修改Logstash配置
vim /etc/logstash/conf.d/nginx.conf
input {
kafka {
bootstrap_servers => "10.10.10.9:9092"
topics => ["nginx-access"]
codec => json
}
}
output {
if [fields][nginx] == "access" {
elasticsearch {
hosts => ["10.10.10.9:9200"]
index => "nginx-access-%{+YYYY.MM.dd}"
}
}
}
Web日志展示
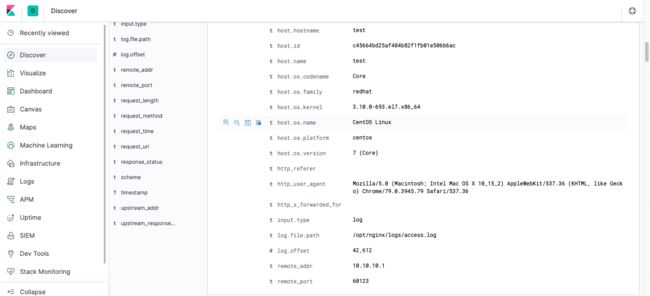
总结一下: Web服务的日志很多时候是我们关注的重点,这里只是展示了采集与简单处理,在后续的分析篇中会提到更多关于Web日志的分析技巧。
堡垒机日志
堡垒机日志采集
Q公司使用的堡垒机是开源JumpServer,版本信息是:1.5.4-2,JumpServer的相关信息在MySQL中,需要分析可以将结果从MySQL中获取,对于JumpServer日志分析也有两种方法:
- 写定时SQL将结果导出到文件中,在使用filebeat从文件中读取。
- 直接使用logstash jdbc input plugin,远程获取,我们这里使用此种方法(此种方法是没有使用到filebeat的)。
# 配置jumpserver Logstash采集
vim /etc/logstash/conf.d/jumpserver.conf
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-5.1.36.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_connection_string => "jdbc:mysql://10.10.10.6:3306/jumpserver"
jdbc_user => "root"
jdbc_password => "root"
schedule => "*/1 * * * *"
statement => "select * from terminal_session where date_start >= SUBDATE(now(),interval 481 minute)"
type => "terminal_session"
}
jdbc {
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-5.1.36.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_connection_string => "jdbc:mysql://10.10.10.6:3306/jumpserver"
jdbc_user => "root"
jdbc_password => "root"
schedule => "*/1 * * * *"
statement => "select id,user,asset,system_user,input,session,timestamp,org_id from terminal_command where FROM_UNIXTIME(timestamp) >= SUBDATE(now(),interval 1 minute);"
type => "terminal_command"
}
}
output {
if [type] == "terminal_session" {
elasticsearch {
hosts => ["10.10.10.9:9200"]
index => "jumpserver-session-%{+YYYY.MM.dd}"
}
}
else if [type] == "terminal_command" {
elasticsearch {
hosts => ["10.10.10.9:9200"]
index => "jumpserver-command-%{+YYYY.MM.dd}"
}
}
}
堡垒机日志展示

总结一下: 对于堡垒机或者其他网络运维设备的日志,我们更多时候是将日志统一到日志平台中,然后进行展开的深入分析,包括:
- 异常的登录时间、地址位置、用户信息;
- 异常的操作行为等等;
这些都将在后续的分析中慢慢放出来。
入侵检测系统日志
对于入侵检测系统,这里介绍两种开源的系统:Bro(Zeek)与Wazuh,前者在Elastic 7.x版本之后以SIEM形式提供支持,Wazuh自身可以与Elastic集成。所以这里也介绍两种入侵检测系统的日志收集处理展示方式:
使用Elastic SIEM
- 安装Bro网络入侵检测系统
# 安装依赖
yum install cmake.x86_64 gcc.x86_64 gcc-c++.x86_64 flex.x86_64 bison.x86_64 libpcap.x86_64 libpcap-devel.x86_64 openssl-devel.x86_64 python-devel.x86_64 swig.x86_64 zlib-devel.x86_64 -y
# 配置yum源
wget http://download.opensuse.org/repositories/network:bro/CentOS_7/network:bro.repo -O /etc/yum.repos.d/network:bro.repo
yum install bro.x86_64 -y
# 配置环境变量
echo 'export PATH=/opt/bro/bin:$PATH' >> /etc/profile
source /etc/profile
- 修改Bro的日志格式
vim /opt/bro/share/bro/site/local.bro
# 在文件末尾添加
@load tuning/json-logs
redef LogAscii::json_timestamps = JSON::TS_ISO8601;
redef LogAscii::use_json = T;
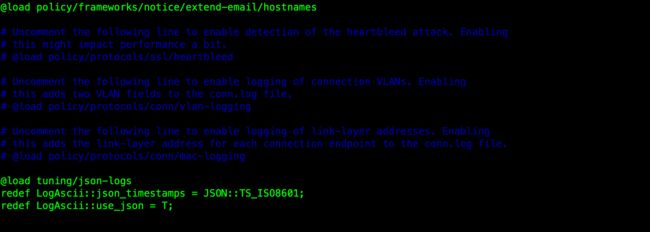
- 启动bro进行监控,启动前请修改配置文件(百度获取)
- 收集Bro日志到Elastic SIEM
# 启动zeek模块,执行这里时需要将output.kafka注释,还原output.elasticsearch
filebeat setup --pipelines --modules zeek
# 如果你已经执行初始化就不用重复执行了
filebeat -e
# Filebeat的配置文件与收集系统日志一致,只需要修改logstash的配置文件的input中的topic内容
input {
kafka {
bootstrap_servers => "10.10.10.9:9092"
topics => ["system-auth","system-syslog","auditd-log","zeek-connection","zeek-dns","zeek-http","zeek-files"]
codec => json
}
}
# output内容不用变换,只需要替换条件即可
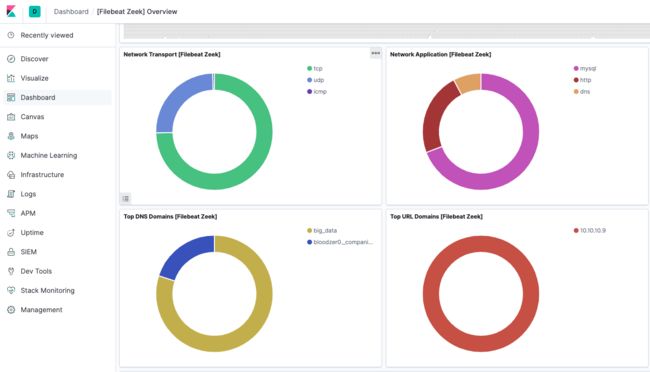
使用Wazuh+Elastic
关于Wazuh安装过程,我这里就不重复补充了,唯一说明一下是:在Filebeat的新版本中(没有具体测试从哪个版本开始)不支持多个output,所以我们这里还是output到kafka再到ES中。
- 修改filebeat的配置文件:
vim /etc/filebeat/filebeat.yml
filebeat.modules:
- module: wazuh
alerts:
enabled: true
archives:
enabled: false
setup.template.json.enabled: true
setup.template.json.path: '/etc/filebeat/wazuh-template.json'
setup.template.json.name: 'wazuh'
setup.template.overwrite: true
setup.ilm.enabled: false
output.kafka:
hosts: ["10.10.10.9:9092"]
topics:
- topic: '%{[service.type]}-%{[fileset.name]}'
when.has_fields: ["@metadata.pipeline"]
- 修改logstash配置文件:
vim /etc/logstash/conf.d/wazuh.conf
input {
kafka {
bootstrap_servers => "10.10.10.9:9092"
topics => ["wazuh-alert"]
codec => json
}
}
output {
if [@metadata][pipeline] and [@metadata][topic] == "auditd-log" {
elasticsearch {
hosts => ["10.10.10.9:9200"]
index => "wazuh-alerts-3.x-%{+YYYY.MM.dd}"
}
}
}
总结一下: 对于入侵检测与防护系统、WAF、防火墙等安全设备的日志,我们更多是收集日志做展示,需要基础的分析,因为日志自身本就是经过分析的,我们需要做的是对这些日志进行深入挖掘。
在本篇的平台实现就先到这里了,大致体现了几种不同类型的:收集方式 --> 存储 --> 展示 。因为篇幅原因不想写的太冗长影响阅读。后续还会有一些番外传:
- 利用大数据处理日志信息;
- 基于Elastic的监控报警系统;
- 统一日志分析平台的安全性;
- …………
踩坑记录
对于踩坑,最好的帮助就是多搜索,多看看官方的说明文档,所有的问题都会迎刃而解。
0x01 Filebeat output.kafka无法输出数据
必须在filebeat的客户端机器上配置域名解析:vim /etc/hosts
10.10.10.9 big_data
0x02 Logstash解析系统日志失败
如果大家使用Logstash自带的解析规则,在某些情况下会出现解析系统日志失败的情况,原因是因为:系统主机名包含下划线时会解析失败,我们来看一下Logstash中关于主机名部分的解析规则:vim /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns

此时的配置在出现下划线时就不能被正确解析
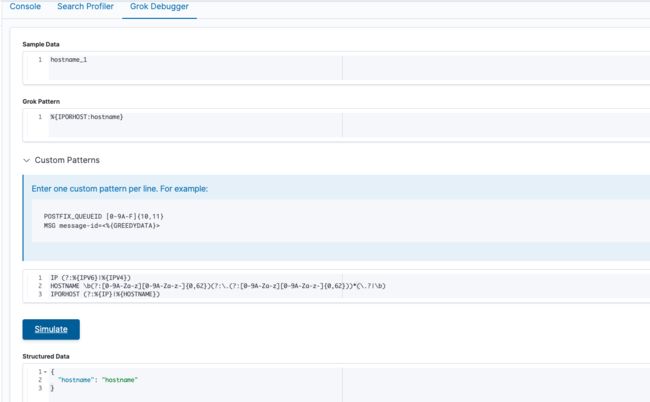
所以如果我们要使用,需要修改成如下图所示
# 将 HOSTNAME \b(?:[0-9A-Za-z][0-9A-Za-z-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z-]{0,62}))*(\.?|\b) 修改为
HOSTNAME \b(?:[0-9A-Za-z][0-9A-Za-z_-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z_-]{0,62}))*(\.?|\b) # 注意看两者多了两个下划线
如果使用Filebeat的模块,也会出现这个问题。
0x03 Logstash使用jdbc input
/usr/share/logstash/bin/logstash-plugin install logstash-input-jdbc
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.36/mysql-connector-java-5.1.36.jar -O /usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-5.1.36.jar
chown logstash:logstash /usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-5.1.36.jar
chmod 644 /usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-5.1.36.jar
0x04 Kibana无法加载Wazuh-API配置页面
错误图:
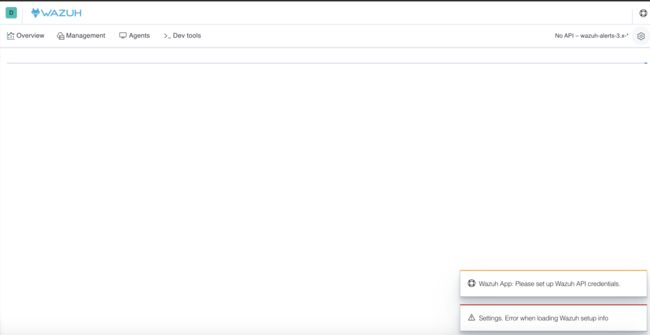
原因分析:对比了官方的安装文档,如果在安装Kibana的插件时,使用root用户,那么就会报错。是因为使用root用户安装插件导致插件中的版本文件丢失。
解决方案:
sudo -u kibana /usr/share/kibana/bin/kibana-plugin install https://packages.wazuh.com/wazuhapp/wazuhapp-3.10.2_7.4.1.zip
参考资料
- Apache流框架Flink、Spark Streaming、Storm对比分析:https://bigdata.163yun.com/product/article/5
- Difference Between Apache Kafka and Flume:https://www.educba.com/apache-kafka-vs-flume/
- Flume、Logstash、Filebeat调研报告:https://www.twblogs.net/a/5d24244bbd9eee1ede06988b/zh-cn
- Log Monitoring and Analysis: Comparing ELK, Splunk and Graylog:https://devops.com/log-monitoring-and-analysis-comparing-elk-splunk-and-graylog/
- System Properties Comparison ElasticSearch vs. HBase vs. Hive:https://db-engines.com/en/system/Elasticsearch%3BHBase%3BHive
- 多种日志收集工具比较:https://www.cnblogs.com/wzj4858/p/8252730.html
- 详解日志采集工具–Logstash、Filebeat、Fluentd、Logagent对比:https://juejin.im/post/5cc121abf265da036b4a683f
History
日志分析系列(一):方法论
日志分析系列(外传一):Nginx透过代理获取真实客户端IP
日志分析系列(外传二):Nginx日志统一化