数据挖掘常见面试题(持续更新中)
1、你理解什么是数据挖掘?
数据挖掘就是由数据准备,数据挖掘和对结果的解释评估三部分组成。数据准备包括数据选取,数据预处理和数据变化。数据挖掘部分包括确定挖掘的任务或目的,选择挖掘算法。最后将结果可视化或者转化为易于理解的形式。
2、为什么会产生过拟合,有哪些方法可以预防或克服过拟合?(常问问题)
所谓过拟合(Overfit),是这样一种现象:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外的数据集上却不能很好的拟合数据。
过拟合产生的原因:出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少。
解决方法:
1、 增大数据量
2、 减少feature个数(人工定义留多少个feature或者算法选取这些feature)
3、 正则化(留下所有的feature,但对于部分feature定义其parameter非常小)
4、 交叉验证,重采样评价模型效能,K折交叉验证
5、 保留一个验证数据集检验
几乎所有集成模型都是为了防止过拟合的。
3、样本不平衡处理方法?(好多次)
a、负样本少,就复制到一定比例
b、或者把正样本删除一部分
c、分段逐一训练(举例:正样本10000,负样本1000,将正样本随机分成10份,每份1000,然后拿着负样本的1000与正样本的每一份进行训练,最后进行融合选择)
d、模型参数调权重(模型里面有个参数可以调整样本权重)
e、交叉验证

f、根据样本随机构造新的样本
4、高维海量数据搜索
KNN(维度20以下)
欧式距离就是指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离,所以它实现的是绝对距离。
余弦相似度是通过计算两个向量的夹角余弦值来评估他们的相似度。
Jaccard相似度是用于比较有限样本集之间的相似性与差异性,其中Jaccard系数值越大,样本相似度越高。
Pearson相似度是余弦相似度的升级版,它把每个向量都中心化了,即每个向量会减去所有向量的平均数,来实现数据更好的平衡,所以它实现的是相对距离。
ANN(维度20以上):
- LSH(Local Sensitive Hash / 局部敏感度哈希)
- K-Means Tree
- K-D Tree
https://zhuanlan.zhihu.com/p/58130758
5、逻辑回归于SVM的区别
1. 损失函数不同
逻辑回归的损失函数:Loss(z)=log( 1+exp(-z))
SVM的损失函数:
损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。SVM的处理方法是考虑支持向量(距离超平面最近的这几个满足 的样本点),逻辑回归通过非线性映射,减小了离分类平面较远的点的权重,相对增加与分类最相关的数据点的权重。两者目的一样。SVM考虑局部(支持向量),而logistic回归考虑全局。
6、索引为什么能加快查询速度?
索引的原理:通过不断的缩小想要获得数据的范围来筛选最终想要的结果,同时把随机的事件变成顺序事件,也就是我们总是通过同一种查找方式来锁定数据。
索引的数据结构:B+树
目前大部分数据库系统及文件系统都采用B-Tree和B+Tree作为索引结构。B+树提高了磁盘IO性能和遍历元素的效率
7、连续值转换为离散值,有什么办法,比如年龄?(好多次)
根据业务知识区分
根据pandas下面qcut和cut方法进行等频或等宽处理
风控中 可以根据woe和iv 或者卡方检验
用聚类来做最优化尺度
8、你在建模过程中遇到过什么困难?(很多次)
样本不平衡问题(然后回答解决办法),样本过拟合问题(然后回答解决办法),准确率不高(结合更换特征,模型调参,换模型等思路回答)
9、Dropout 调参
我的经验是决定dropout之前,需要先判断是否模型过拟合
先dropout=0, 训练后得到模型的一些指标(比如: F1, Accuracy, AP)。比较train数据集和test数据集的指标。
- 过拟合:尝试下面的步骤。
- 欠拟合:尝试调整模型的结构,暂时忽略下面步骤。
dropout设置成0.4-0.6之间, 再次训练得到模型的一些指标。
- 如果过拟合明显好转,但指标也下降明显,可以尝试减少dropout(0.2)
- 如果过拟合还是严重,增加dropout(0.2)
重复上面的步骤多次,就可以找到理想的dropout值了
10、VGG优缺点
- VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- 几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:
- 验证了通过不断加深网络结构可以提升性能。
VGG缺点
- VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
PS:有的文章称:发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。
注:很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相对其他的方法,参数空间很大,最终的model有500多m,AlexNet只有200m,GoogLeNet更少,所以train一个vgg模型通常要花费更长的时间,所幸有公开的pretrained model让我们很方便的使用。
11、抽样的分类
随机抽样,分层抽样(分块)每一层进行随机抽样,系统抽样(固定规则),整群抽样(先聚类,再抽样)
12、决策树
ID3.5 -> 熵(entropy),information gain(信息增益),选择增益最大的属性,
C4.5
ID3有一些缺陷,就是选择的时候容易选择一些比较容易分纯净的属性,尤其在具有像ID值这样的属性,因为每个ID都对应一个类别,所以分的很纯净,ID3比较倾向找到这样的属性做分裂。
C4.5算法定义了分裂信息,表示为:split_infoA(D)=−∑j=1v|Dj||D|log2(|Dj||D|)
split_infoA(D)=−∑j=1v|Dj||D|log2(|Dj||D|)
很容易理解,这个也是一个熵的定义,pi=|Dj||D|pi=|Dj||D|,可以看做是属性分裂的熵,分的越多就越混乱,熵越大。
gain_ratio(A)=gain(A)/split_info(A)
CART分类树:
CART分类树预测分类离散型数据,采用基尼指数选择最优特征,同时决定该特征的最优二值切分点。分类过程中,假设有K个类,样本点属于第k个类的概率为Pk,则概率分布的基尼指数定义为

根据基尼指数定义,可以得到样本集合D的基尼指数,其中Ck表示数据集D中属于第k类的样本子集。

如果数据集D根据特征A在某一取值a上进行分割,得到D1,D2两部分后,那么在特征A下集合D的基尼系数如下所示。其中基尼系数Gini(D)表示集合D的不确定性,基尼系数Gini(D,A)表示A=a分割后集合D的不确定性。基尼指数越大,样本集合的不确定性越大。
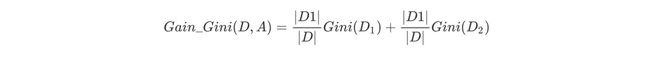
对于属性A,分别计算任意属性值将数据集划分为两部分之后的Gain_Gini,选取其中的最小值,作为属性A得到的最优二分方案。然后对于训练集S,计算所有属性的最优二分方案,选取其中的最小值,作为样本及S的最优二分方案。

实现trick
决策树的构建过程是一个递归的过程,所以需要确定停止条件,否则过程将不会结束。一种最直观的方式是当每个子节点只有一种类型的记录时停止,但是这样往往会使得树的节点过多,导致过拟合问题(Overfitting)。另一种可行的方法是当前节点中的记录数低于一个最小的阀值,那么就停止分割,将max(P(i))对应的分类作为当前叶节点的分类。
过拟合
优化方案1:修剪枝叶
决策树过渡拟合往往是因为太过“茂盛”,也就是节点过多,所以需要裁剪(Prune Tree)枝叶。裁剪枝叶的策略对决策树正确率的影响很大。主要有两种裁剪策略。
前置裁剪 在构建决策树的过程时,提前停止。那么,会将切分节点的条件设置的很苛刻,导致决策树很短小。结果就是决策树无法达到最优。实践证明这中策略无法得到较好的结果。
后置裁剪 决策树构建好后,然后才开始裁剪。采用两种方法:
1)用单一叶节点代替整个子树,叶节点的分类采用子树中最主要的分类;
2)将一个子树完全替代另外一颗子树。后置裁剪有个问题就是计算效率,有些节点计算后就被裁剪了,导致有点浪费。
优化方案2:K-Fold Cross Validation
首先计算出整体的决策树T,叶节点个数记作N,设i属于[1,N]。对每个i,使用K-Fold Validataion方法计算决策树,并裁剪到i个节点,计算错误率,最后求出平均错误率。(意思是说对每一个可能的i,都做K次,然后取K次的平均错误率。)这样可以用具有最小错误率对应的i作为最终决策树的大小,对原始决策树进行裁剪,得到最优决策树。
优化方案3:Random Forest
Random Forest是用训练数据随机的计算出许多决策树,形成了一个森林。然后用这个森林对未知数据进行预测,选取投票最多的分类。实践证明,此算法的错误率得到了经一步的降低。这种方法背后的原理可以用“三个臭皮匠定一个诸葛亮”这句谚语来概括。一颗树预测正确的概率可能不高,但是集体预测正确的概率却很高。RF是非常常用的分类算法,效果一般都很好。
13、梯度消失与爆炸
概念:在深度神经网络中的梯度是不稳定的,在靠近输入层的隐藏层中或会消失,或会爆炸。这种不稳定性才是深度神经网络中基于梯度学习的根本问题。
产生梯度不稳定的根本原因:前面层上的梯度是来自后面层上梯度的乘积。当存在过多的层时,就会出现梯度不稳定场景,比如梯度消失和梯度爆炸。
梯度消失:在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫梯度消失。
梯度爆炸:在神经网络中,当前面隐藏层的学习速率高于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫梯度爆炸。
其实梯度消失和梯度爆炸是一回事,只是表现的形式,以及产生的原因不一样。
14.梯度消失与梯度爆炸的产生原因
根本原因是反向传播算法
梯度消失:(1)隐藏层的层数过多;(2)采用了不合适的激活函数sigmoid(更容易产生梯度消失,但是也有可能产生梯度爆炸)
梯度爆炸:(1)隐藏层的层数过多;(2)权重的初始化值过大

15.梯度消失与梯度爆炸的解决方案
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑一下三种方案解决:
(1)用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。(几种激活函数的比较见我的博客)
(2)用Batch Normalization。(对于Batch Normalization的理解可以见我的博客)
(3)LSTM的结构设计也可以改善RNN中的梯度消失问题。

16、准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F值(F-Measure)、AUC、ROC的理解
https://blog.csdn.net/u011630575/article/details/80250177