Flume架构及应用
@Author : Spinach | GHB
@Link : http://blog.csdn.net/bocai8058-
-
- Flume简介
- Flume基本概念
- Flume架构
- Flume广义用法
- Flume应用配置
-
- an agent flow配置
- multi-agent flow配置
- fan out flow配置
- 通用配置
- 运行命令(flume-ng)
-
- 关于Flume核心组件的几个问题
-
- Source
- Channel
- Sink
-
- Flume适用场景
- 总结
-
Flume简介
Flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。后于2009年被捐赠了apache软件基金会,为hadoop相关组件之一。尤其近几年随着flume的不断被完善以及升级版本的逐一推出,特别是Flume NG(next generation);同时Flume内部的各种组件不断丰富,用户在开发的过程中使用的便利性得到很大的改善,现已成为apache top项目之一。
apache Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力。
Flume基本概念
- Flume:是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方。
- Even:包括event headers、event body、event信息(即文本文件中的单行记录),其中event信息就是flume收集到的日记记录。
在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?
1. event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。
2. event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。
3. event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。 
Flume架构
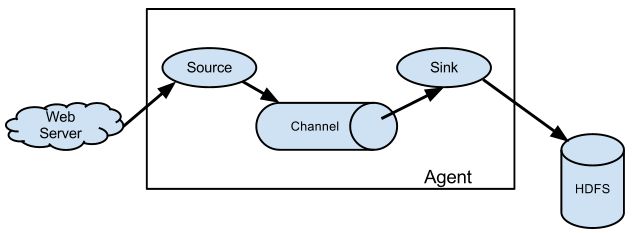
Flume的核心是agent,把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume再删除自己缓存的数据。
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件,分别是source、 channel、 sink。
- sources 数据源:数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入一个或多个Channel中。Flume提供了很多内置的Source,如下表。
- channels 数据通道:一种短暂的存储容器,负责数据的存储持久化,可以持久化到jdbc,file,memory。Flume提供了很多内置的Channels,如下表。
- 将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,
- 可以把channel看成是一个队列,队列的优点是先进先出,放好后尾部一个个event出来,Flume比较看重数据的传输,因此几乎没有数据的解析预处理。
- 仅仅是数据的产生,封装成event然后传输。
- 数据只有存储在下一个存储位置(可能是最终的存储位置,如HDFS;也可能是下一个Flume节点的channel),数据才会从当前的channel中删除。
- 这个过程是通过事务来控制的,这样就保证了数据的可靠性。
备注:不过flume的持久化也是有容量限制的,比如内存如果超过一定的量,不够分配,也一样会爆掉。
- sinks 数据目的槽:Sink负责数据的转发,将数据存储到集中存储器,比如Hbase和HDFS,它从channel消费数据(events)并将其传递给目标地,目的地也可以是其他agent的Source。Flume提供了很多内置的Sinks,如下表。
| sources类型 | 描述 | channels类型 | 描述 | sinks类型 | 描述 |
|---|---|---|---|---|---|
| avro | 监听Avro端口并接收Avro Client的流数据 | memory | Event数据存储在内存中 | avor | 数据被转换成Avro Event,然后发送到配置的RPC端口上 |
| thrift | 监听Thrift端口并接收Thrift Client的流数据 | jdbc | Event数据存储在持久化存储中,当前Flume Channel内置支持Derby | thrift | 数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
| exec | 基于Unix的command在标准输出上生产数据 | file | Event数据存储在磁盘文件中 | hive | 数据导入到HIVE中 |
| jms | 从JMS(Java消息服务)采集数据 | SPILLABLEMEMORY | Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) | logger | 数据写入日志文件 |
| spooldir | 监听指定目录 | PseudoTxnMemoryChannel | 测试用途 | hdfs | 数据写入HDFS |
| KafkaSource | 采集Kafka topic中的message | KafkaChannel | Event存储在kafka集群 | KafkaSink | 数据写到Kafka Topic |
| netcat | 监听端口(要求所提供的数据是换行符分隔的文本) | Custom | 自定义Channel实现 | hbase | 数据写入HBase数据库 |
| seq | 序列产生器,连续不断产生event,用于测试 | null | 丢弃到所有数据 | ||
| syslogtcp、syslogudp、multiport_syslogtcp | 采集syslog日志消息,支持单端口TCP、多端口TCP和UDP日志采集 | DatasetSink | 写数据到Kite Dataset,试验性质的 | ||
| http | 接收HTTP POST和GET数据 | Custom | 自定义Sink实现 | ||
| 其他 | 其他 |
- channel selectors 通道选择器:设置从source到多个channel的过滤数据,默认是replicating。
| sources类型 | 描述 |
|---|---|
| replicating | 默认管道选择器: 每一个管道传递的都是相同的events |
| multiplexing | 多路复用通道选择器: 依据每一个event的头部header的地址选择管道 |
| Custom | 自定义selector实现 |

Flume广义用法
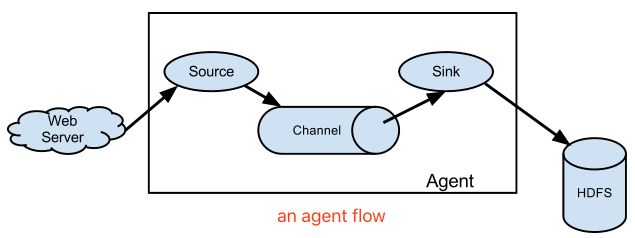
- an agent flow:简单一个agent流程。
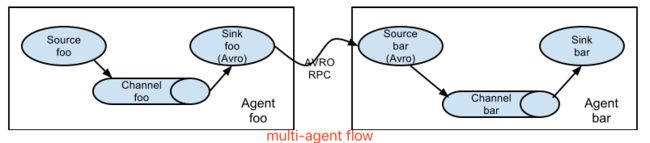
- multi-agent flow:多个agent顺序连接。
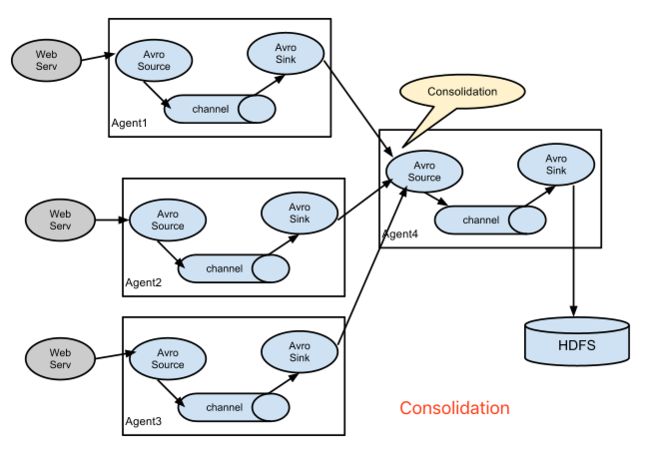
- Consolidation:多个agent的数据汇聚到同一个agent。
- Multiplexing flow:多级流。

Flume应用配置
an agent flow配置
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/ghb/HadoopCluster/Call
a1.sources.r1.fileHeader = true
#a1.sources.r1.type = exec
#a1.sources.r1.command = tail -F /home/ghb/HadoopCluster/Call/CallLog.log
#a1.sources.r1.fileHeader = true
#a1.sources.r1.deserializer.outputCharset=UTF-8
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = CallLog
a1.sinks.k1.kafka.bootstrap.servers =127.0.0.1:6667
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks=1
#a1.sinks.k1.type = hdfs
#a1.sinks.k1.hdfs.path = hdfs://hadoop0:9000/CallLog
#a1.sinks.k1.hdfs.filePrefix = log_%Y%m%d_%H
#a1.sinks.k1.hdfs.writeFormat= Text
#a1.sinks.k1.hdfs.fileType = CompressedStream
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1multi-agent flow配置
# Weblog.conf: A agent configuration
# list sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source
agent_foo.sinks = avro-forward-sink
agent_foo.channels = file-channel
# define the flow
agent_foo.sources.avro-AppSrv-source.channels = file-channel
agent_foo.sinks.avro-forward-sink.channel = file-channel
# avro sink properties
agent_foo.sources.avro-forward-sink.type = avro
agent_foo.sources.avro-forward-sink.hostname = 10.1.1.100
agent_foo.sources.avro-forward-sink.port = 10000
# configure other pieces
#...# HDFS.conf: other agent configuration
# list sources, sinks and channels in the agent
agent_foo.sources = avro-collection-source
agent_foo.sinks = hdfs-sink
agent_foo.channels = mem-channel
# define the flow
agent_foo.sources.avro-collection-source.channels = mem-channel
agent_foo.sinks.hdfs-sink.channel = mem-channel
# avro sink properties
agent_foo.sources.avro-collection-source.type = avro
agent_foo.sources.avro-collection-source.bind = 10.1.1.100
agent_foo.sources.avro-collection-source.port = 10000
# configure other pieces
#...fan out flow配置
# fan_out_flow.conf: an agent configuration
# list the sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source1
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2
# set channels for source
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 file-channel-2
# set channel for sinks
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
# channel selector configuration
agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing
agent_foo.sources.avro-AppSrv-source1.selector.header = State
agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
# configure other pieces
#...通用配置
# example1.conf: This is a generic configuration for the configuration file
# list the sources, sinks and channels for the agent
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# properties for sources
<Agent>.sources.<Source>.<someProperty> = <someValue>
# properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>
# channel selector configuration
# ...
# Bind the source and sink to the channel
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
<Agent>.sinks.<Sink>.channel = <Channel1>运行命令(flume-ng)
$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.conf -Dflume.root.logger=INFO,console# $flume-ng --help
Usage: /home/ghb/HadoopCluster/flume-1.7.0/bin/flume-ng [options]...
commands:
help display this help text
agent run a Flume agent
avro-client run an avro Flume client
version show Flume version info
global options:
--conf,-c use configs in directory
--classpath,-C append to the classpath
--dryrun,-d do not actually start Flume, just print the command
--plugins-path colon-separated list of plugins.d directories. See the
plugins.d section in the user guide for more details.
Default: $FLUME_HOME/plugins.d
-Dproperty=value sets a Java system property value
-Xproperty=value sets a Java -X option
agent options:
--name,-n the name of this agent (required)
--conf-file,-f specify a config file (required if -z missing)
--zkConnString,-z specify the ZooKeeper connection to use (required if -f missing)
--zkBasePath,-p specify the base path in ZooKeeper for agent configs
--no-reload-conf do not reload config file if changed
--help,-h display help text
avro-client options:
--rpcProps,-P RPC client properties file with server connection params
--host,-H hostname to which events will be sent
--port,-p port of the avro source
--dirname directory to stream to avro source
--filename,-F text file to stream to avro source (default: std input)
--headerFile,-R File containing event headers as key/value pairs on each new line
--help,-h display help text
Either --rpcProps or both --host and --port must be specified.
Note that if directory is specified, then it is always included first
in the classpath. 关于Flume核心组件的几个问题
Flume主要由3个重要的组件构成:
1. Source: 完成对日志数据的收集,分成transtion 和 event 打入到channel之中。
2. Channel: Flume Channel主要提供一个队列的功能,对source提供中的数据进行简单的缓存。
3. Sink: Flume Sink取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Source
- Spool Source 如何使用?
在实际使用的过程中,可以结合log4j使用,使用log4j的时候,将log4j的文件分割机制设为1分钟一次,将文件拷贝到spool的监控目录。
1) log4j有一个TimeRolling的插件,可以把log4j分割的文件到spool目录。
2) 基本实现了实时的监控。
3) Flume在传完文件之后,将会修改文件的后缀,变为.COMPLETED(后缀也可以在配置文件中灵活指定)- Exec Source和Spool Source比较
1) ExecSource可以实现对日志的实时收集,但是存在Flume不运行或者指令执行出错时,将无法收集到日志数据,无法何证日志数据的完整性。
2) SpoolSource虽然无法实现实时的收集数据,但是可以使用以分钟的方式分割文件,趋近于实时。
3) 总结:如果应用无法实现以分钟切割日志文件的话,可以两种收集方式结合使用。Channel
- MemoryChannel可以实现高速的吞吐, 但是无法保证数据完整性
- MemoryRecoverChannel在官方文档的建议上已经建义使用FileChannel来替换。FileChannel保证数据的完整性与一致性。在具体配置不现的FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。
Sink
Flume Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
Flume适用场景
如果你想把可文本化的日志数据提取到HDFS,那么Flume是非常适合的。
对于其他场景,有些东西是需要考量的:Flume被设计用来传输、提取定期生成的数据的,这些数据是传输在相对稳定的、可能是复杂的拓扑结构上的。每个数据就是一个event。“event data”的概念是非常广泛的。对于Flume而言,一个event就是一个blob字节数据。这个event的大小是有限制的,例如,不能大于内存或硬盘或单机可以存储的大小。事实上,flume的event可以是任何东西,从日志文本到图片文件。Event的关键点是不断生成、流式的。如果你的数据不是的定期生成的(比如一次性的向Hadoop集群导入数据),Flume可以工作,但是有点杀鸡用牛刀了。Flume喜欢相对稳定的拓扑结构。你的拓扑结构不必是不可改变的,因为Flume可以在不丢失数据的前提下处理拓扑结构的改变,并且能容忍由于故障转移导致的周期性的重新配置。但如果你每天都要改变拓扑结构,那么Flume将不能很好的工作,因为重新配置会产生开销。
简而言之,有两点:
1. 数据。数据是定期生成的。
2. 网络拓扑相对稳定。
总结
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。