Chapter 6 决策树
OReilly.Hands-On Machine Learning with Scikit-Learn and TensorFlow读书笔记
Chapter 6 Decision Trees
Like SVMs, Decision Trees are versatile ML algorithms that can perform both classification and regression tasks, and even multioutput tasks.
Decision Trees are also fundamental components of Random Forest, which are among the most powerful ML algorithms.
6.1 Training and Visualizing a Decision Tree
Training a DecisionTreeClassifier \verb+DecisionTreeClassifier+ DecisionTreeClassifier on the iris dataset.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris=load_iris()
#receive different results, why?
#X=iris['data'][:,2:] #petal length and width
#y=iris['target']
X=iris.data[:,2:]
y=iris.target
tree_clf=DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X,y)
In your working directory, manually create directories of the following structure: ./images/decision_trees
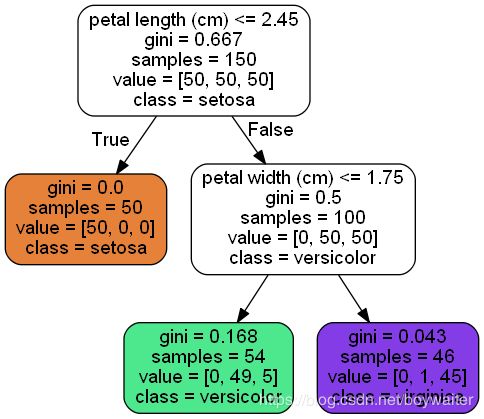
You can visualize the trained decision tree by using the export_graphviz() \verb+export_graphviz()+ export_graphviz() method to output a graph definition file called iris_tree.dot.
from sklearn.tree import export_graphviz
import os
# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "decision_trees"
def image_path(fig_id):
return os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id)
export_graphviz(
tree_clf,
out_file=image_path("iris_tree.dot"),
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
Then you can convert this .dot file to a variety formats such as PDF or PNG using the dot command-line tool from the graphviz package.
$dot -Tpng iris_tree.dot -o iris_tree.png
6.2 Making Predictions
One of the many qualities of Decision Trees is that they require very little data preparation. In particular, they don’t require feature scaling or centering at all.
A node’s samples \verb+samples+ samples attribute counts how many training instances it applies to.
A node’s value \verb+value+ value attribute tells you how many training instances of each class this node contains.
A node’s gini \verb+gini+ gini attribute measures its impurity: a node is “pure” ( gini=0 \verb+gini=0+ gini=0) if all training instances it applies to belong to the same class.
Equation 6-1. Gini impurity
G i = 1 − ∑ k = 1 n p i , k 2 G_i=1-\sum_{k=1}^n p_{i,k}^2 Gi=1−k=1∑npi,k2
- p i , k p_{i,k} pi,k is the ratio of class k k k instances among the training instances in the i i i-th node.
For example, the depth-2 left node has a gini \verb+gini+ gini score equal to 1 – ( 0 / 54 ) 2 – ( 49 / 54 ) 2 – ( 5 / 54 ) 2 ≈ 0.168 1 – (0/54)^2 – (49/54)^2 – (5/54)^2 \approx 0.168 1–(0/54)2–(49/54)2–(5/54)2≈0.168.
Scikit-Learn uses the CART algorithm, which produces only binary trees. Other algorithms such as ID3 can produce Decision Trees with nodes that have more than two children.
Model Interpretation: White Box Versus Black Box
White Box Models are fairly intuitive and their decisions are easy to interpret, such as Decision Trees.
Black box models are usually hard to explain in simple terms why the predictions were made, such as Random Forest and Neural Networks.
6.3 Estimating Class Probabilities
tree_clf.predict_proba([[5,1.5]])
#array([[0. , 0.90740741, 0.09259259]])
tree_clf.predict([[5,1.5]])#array([1])
6.4 The CART Training Algorithm
Scikit-Learn use CART (Classification And Regression Tree) algorithm to train Decision Trees (this process is also called “growing” trees). The idea is: the algorithm first splits the training set in two subsets using a single feature k k k and a threshold t k t_k tk (e.g., “petal length ≤ \le ≤ 2.45 cm”).
How does it choose k k k and t k t_k tk?
It searches for the pair ( k , t k ) (k, t_k) (k,tk) that produces the purest subsets (weighted by their size). The cost function that the algorithm tries to minimize is given by Equation 6-2.
Equation 6-2. CART cost function for classification
J ( k , t k ) = m left m G left + m right m G right where { G left/right measures the impurity of the left/right subsets, m left/right is the number of instances in the left/right subsets, J(k,t_k)= \frac{m_{\textrm{left}}}{m}G_{\textrm{left}}+\frac{m_{\textrm{right}}}{m}G_{\textrm{right}}\\ \textrm{where } \begin{cases} G_\textrm{left/right} \textrm{ measures the impurity of the left/right subsets,}\\ m_\textrm{left/right} \textrm{ is the number of instances in the left/right subsets,} \end{cases} J(k,tk)=mmleftGleft+mmrightGrightwhere {Gleft/right measures the impurity of the left/right subsets,mleft/right is the number of instances in the left/right subsets,
Termination conditions: It stops recursing once it reaches the maximum depth (defined by the max_depth \verb+max_depth+ max_depth hyperparameter), or if it cannot find a split that will reduce impurity. A few other hyperparameters control additional stopping conditions ( min_samples_split \verb+min_samples_split+ min_samples_split, min_samples_leaf \verb+min_samples_leaf+ min_samples_leaf, min_weight_fraction_leaf \verb+min_weight_fraction_leaf+ min_weight_fraction_leaf, and max_leaf_nodes \verb+max_leaf_nodes+ max_leaf_nodes).
The CART algorithm is a greedy algorithm: it greedily searches for an optimum split at the top level, then repeat the process at each level. It does not check whether or not the split will lead to the lowest possible impurity several levels down. A greedy algorithm often produces a reasonably good solution, but it is not guaranteed to be the optimal solution.
Finding the optimal tree is known to be an NP-Complete problem.
6.5 Computational Complexity
Traversing the Decision Tree requires going through roughly O ( log 2 ( m ) ) O(\log_2(m)) O(log2(m)) nodes. Since each node requires checking the value of one feature, the overall prediction complexity is just O ( log 2 ( m ) ) O(\log_2(m)) O(log2(m)), independent of the number of features.
However, the training algorithm compares all features (or less if max_features \verb+max_features+ max_features is set) on all samples at each node. This results in a training complexity of O ( n × m log 2 ( m ) ) O(n \times m \log_2(m)) O(n×mlog2(m)).
For small training sets (less than a few thousand instances), Scikit-Learn can speed up
training by presorting the data (set presort=True \verb+presort=True+ presort=True), but this slows down training considerably for larger training sets.
6.6 Gini Impurity or Entropy?
Gini impurity measure is the default measurement, but you can use entropy impurity measure instead by setting the criterion \verb+criterion+ criterion hyperparameter to “ entropy \verb+entropy+ entropy”.
Equation 6-3. Entropy
H i = − ∑ k = 1 n P i , k ≠ 0 P i , k log P i , k H_i=-\mathop{\sum_{k=1}^n}\limits_{P_{i,k}\neq 0}P_{i,k}\log P_{i,k} Hi=−Pi,k̸=0k=1∑nPi,klogPi,k
So should you use Gini impurity or entropy? The truth is, most of the time it does not
make a big difference: they lead to similar trees. Gini impurity is slightly faster to compute, so it is a good default. However, when they differ, Gini impurity tends to isolate the most frequent class in its own branch of the tree, while entropy tends to produce slightly more balanced trees.
6.7 Regularization Hyperparameters
Decision Trees make very few assumptions about the training data (as opposed to lin‐
ear models, which obviously assume that the data is linear, for example).
nonparametric model: the number of parameters is not determined prior to training, so the model structure is free to stick closely to the data.
parametric model: has a predetermined number of parameters, so its degree of freedom is limited, reducing the risk of overfitting (but increasing the risk of underfitting).
Regularization:
- max_depth \verb+max_depth+ max_depth
- min_samples_split \verb+min_samples_split+ min_samples_split (the minimum number of samples a node must have before it can be split)
- min_samples_leaf \verb+min_samples_leaf+ min_samples_leaf (the minimum number of samples a leaf node must have)
- min_weight_fraction_leaf \verb+min_weight_fraction_leaf+ min_weight_fraction_leaf (same as min_samples_leaf \verb+min_samples_leaf+ min_samples_leaf but expressed as a fraction of the total number of weighted instances)
- max_leaf_nodes \verb+max_leaf_nodes+ max_leaf_nodes (maximum number of leaf nodes)
- max_features \verb+max_features+ max_features (maximum number of features that are evaluated for splitting at each node).
Increasing min_* \verb+min_*+ min_* hyperparameters or reducing max_* \verb+max_*+ max_* hyperparameters will regularize the
model (i.e., not making the model too complex).
Other algorithms work by first training the Decision Tree without restrictions, then pruning (deleting) unnecessary nodes. The necessity of pruning a node is evaluates by standard statistical tests, such as the χ 2 \chi ^2 χ2 test.
6.8 Regression
# Quadratic training set + noise
import numpy as np
np.random.seed(42)
m = 200
X = np.random.rand(m, 1)
y = 4 * (X - 0.5) ** 2
y = y + np.random.randn(m, 1) / 10
from sklearn.tree import DecisionTreeRegressor
tree_reg=DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X,y)
export_graphviz(
tree_reg,
out_file=image_path("reg_tree.dot"),
feature_names=['x1'],
rounded=True,
filled=True
)
$dot -Tpng reg_tree.dot -o reg_tree.png
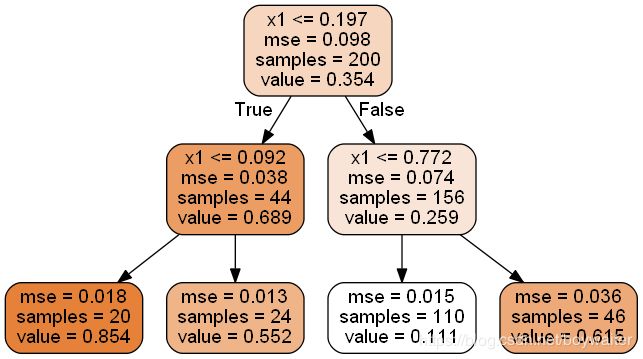
The main difference is that, given a x 1 x_1 x1 value, instead of predicting a class in each node, it predicts a value. For example, the prediction of a new instance with x 1 = 0.6 x_1=0.6 x1=0.6, the algorithm traverses the decision tree above, reaches the second to right leaf node, and obtain the value 0.111 finally. This prediction is simply the average target value of the 110 training instances associated to this leaf node. This prediction results in a mse (Mean Squared Error) equal to 0.015 over these 110 instances.
The CART algorithm works mostly the same way as earlier, except that instead of try‐
ing to split the training set in a way that minimizes impurity, it now tries to split the
training set in a way that minimizes the MSE.
Equation 6-4. CART cost function for regression
J ( k , t k ) = m left m MSE left + m right m MSE right where { MSE node = ∑ i ∈ node ( y ^ node − y ( i ) ) 2 y ^ node = 1 m node ∑ i ∈ node y ( i ) J(k,t_k)= \frac{m_{\textrm{left}}}{m}\textrm{MSE}_{\textrm{left}}+\frac{m_{\textrm{right}}}{m}\textrm{MSE}_{\textrm{right}} \textrm{where } \begin{cases} \textrm{MSE}_\textrm{node}=\sum_{i\in \textrm{node}}\left(\hat y_\textrm{node}-y^{(i)}\right)^2\\ \hat y_\textrm{node}=\frac{1}{m_\textrm{node}}\sum_{i\in \textrm{node}}y^{(i)} \end{cases} J(k,tk)=mmleftMSEleft+mmrightMSErightwhere {MSEnode=∑i∈node(y^node−y(i))2y^node=mnode1∑i∈nodey(i)
6.9 Instability
limitations:
- orthogonal decision boundaries (all splits are perpendicular to an axis), which makes them sensitive to training set rotation. One way to limit this is PCA.
- very sensitive to small variations in the training data