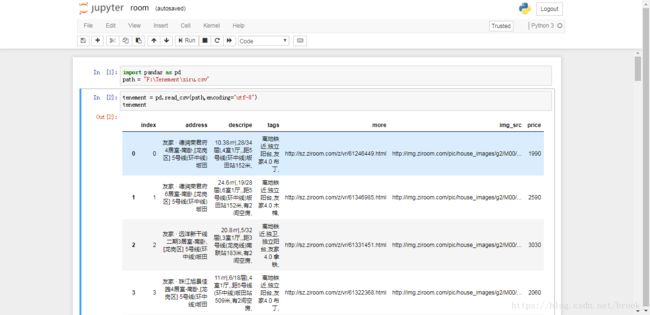
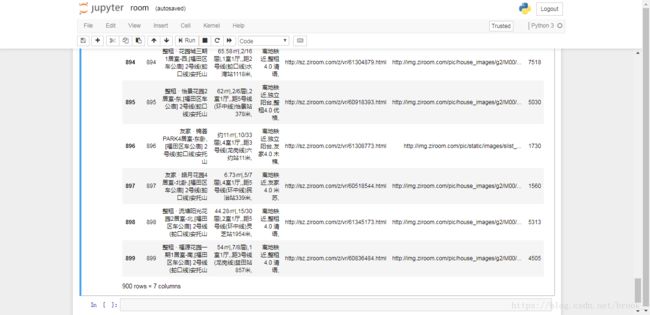
python爬虫——抓取自如网房源,导出为csv
1.抓取自如网房源,其实为了后面一个小项目做数据采集工作
2.为什么选择自如,是因为我做租房的同学说,自如网的房源质量比较高
3.因为博主是暂居深圳,就先以深圳市的房源为示例
base_url = "http://sz.ziroom.com/z/nl/z3.html"起始地址,全是get请求,就可以拿到数据,那么,十分的简单,
1.构造网址
base_url = "http://sz.ziroom.com/z/nl/z3.html"
class Get_one_page:
def __init__(self,page):
self.page = page
self.parmas = {"p": page}
self.appartments = []2.getpage页面,拿出房源信息
def getpage(self):
try:
time.sleep(random.randint(1,2))
response = requests.get(url=base_url,params=self.parmas,headers=my_headers)
except Exception as e:
print("get方法失败"+self.page)
print(e)
return
if response.status_code == 200:
soup = BeautifulSoup(response.text,"lxml")
ul = soup.select("ul[id='houseList']")
li_list = ul[0].select("li")
else:
print("状态码不为200------"+self.page)
return
for li in li_list:
address = li.select("h3")[0].text + "," + soup.select("h4")[0].text # 获取房源地址
descripe = li.select(".detail")[0].text.replace(" " , "").replace("\n" , ",")[2:] # 获取房源描述信息
tags = li.select(".room_tags")[0].text.replace("\n" , ",")[1:] # 获取房源标签
more_href = "http:" + li.select('.more a')[0].attrs["href"] # 详情链接
img_src = "http:" + li.select("img")[0].attrs["_src"] # 图片链接
price = self.get_price(more_href)
room = {"address": address,
"descripe": descripe,
"tags": tags,
"more": more_href,
"img_src": img_src,
"price": price}
self.appartments.append(room)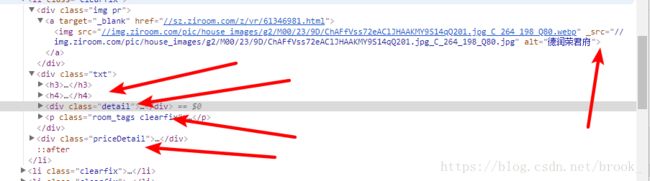
房源最重要的信息-价格,在http://sz.ziroom.com/z/nl/z3.html这个地址中是以图片拼出来的,我们只有进入每个房源的详情页,才能以足够简单的方法获取价格,所以再定义一个get_price方法,参数是房源详情页的地址
3.get_price获取房源价格
def get_price(self, href):
"""返回的是季付每月租金, 从更多页面中获取"""
try:
time.sleep(random.randint(1 , 2))
response = requests.get(url=href, headers=my_headers)
except Exception as e:
print("get方法失败" + href)
print(e)
price = "0"
if response.status_code == 200:
soup = BeautifulSoup(response.text , "lxml")
try:
price =soup.select("#room_price")[0].text
except:
print(href)
price = "0"
else:
print("状态码不为200------" + href)
price = "0"
regex = "\d+"
if price == None:
print(href)
price = "0"
return re.findall(regex, price)[0]
4.导出为scv格式文件
def writedata(self):
def write_csv_file(path , head , data):
try:
with open(path , 'w' , newline='' , encoding="utf-8") as csv_file:
writer = csv.writer(csv_file , dialect='excel')
if head is not None:
writer.writerow(head)
for row in data:
row_data = []
for k in head:
row_data.append(row[k])
row_data = tuple(row_data)
# print(row_data)
writer.writerow(row_data)
print("Write a CSV file to path %s Successful." % path)
except Exception as e:
print("Write an CSV file to path: %s, Case: %s" % (path , e))
head = ("address" , "descripe" , "tags" , "more" , "img_src" , "price")
write_csv_file(self.path , head , self.appartments)5.循环抓取50页房源并写入本地
if __name__ == '__main__':
for i in range(1,51):
Get_one_page(i)慢慢写是为了方便哪页出错好排查,重爬数据代价小
6.合并50页房源


import pandas as pd
dfs = []
for i in range(1,51):
path = "ziru/page_%d.csv"%i
# 导入数据
df = pd.read_csv(path,encoding="utf-8")
dfs.append(df)
# 合并数据
ziru = pd.concat(dfs,ignore_index=True)
# 导出数据
ziru.to_csv("ziru.csv")7.房源信息展示