【CenterNet】《Objects as Points》

arXiv-2019
Code:https://github.com/xingyizhou/CenterNet
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
- 4.1 2D Objects as Points
- 4.2 Human pose estimation
- 5 Experiments
- 5.1 Datasets
- 5.2 Implementation details
- 5.3 Object detection
- 5.3.1 Experiments on MS COCO
- 5.3.2 Additional experiments
- 5.3.3 Error Analysis
- 5.3.4 Experiments on Pascal VOC
- 5.3.5 3D detection
- 5.4 Pose estimation
- 6 Conclusion(own)
1 Background and Motivation
监控、自动驾驶、visual question answering 等领域都涉及到目标检测,其发展推动着实例分割(instance segmentation)、姿态检测(pose estimation)、物体追踪(tracking)、动作识别(action recognition)等视觉任务的发展!
当前的 object detectors 通过一个轴向对齐的框(axis-aligned boxes)来表示每个 object,可分为 one-stage 方法(直接对 anchor 进行分类和回归,来确定最终的边界框) 和 two-stage 方法(对 anchor 先二分类+回归筛选出前景背景,然后 pooling 成固定尺寸进行分类+回归确定最终的边界框) !由于候选区域较多(备胎),需要经过 NMS 算法筛选剔除(留下真爱),不过 NMS 方法往往难以 end-to-end 训练,所以大多数目标检测器不是 end-to-end trainable 的方法!
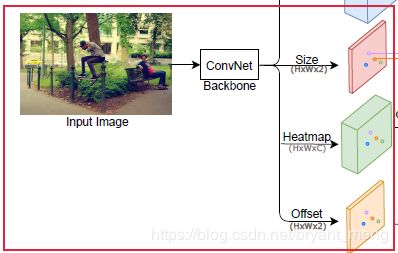
本文,作者用边界框的中心点来表示目标,目标的 size 用中心处的特征回归出来!这样目标检测的问题就转化为了关键点评估(keypoint estimation)问题!也即对每一类预测出一个 heatmap,heatmap 中响应值较高的点为中心点,配合中心点特征回归出来的 h h h 和 w w w 就能锁定边界框,从而实现目标检测的定位和分类!

作者也摒弃了 NMS 后处理操作(only have one positive “anchor” per object,没有备胎)!

最骚的是,基于点的特征可以回归出其他值,进而运用到其他的任务上(eg:3D object detection 和 pose keypoint estimation)


速度和精度的 trade-off 如下

左上角最猛
2 Related Work
-
Object detection by region classification
R-CNN、Fast RCNN -
Object detection with implicit anchors
- one-stage:SSD、YOLO-v1、YOLO-v2、Focal Loss
- two-stage:Faster R-CNN
-
Object detection by keypoint estimation
CornerNet、ExtremeNet,点检测完了之后需要 grouping 在一起形成框,这样比较慢, -
Monocular 3D object detection
3D 领域没接触过过,这个就“略”了
3 Advantages / Contributions
- 提出 CenterNet,可以同时实现目标检测,人体关键点检测和 3D bounding box(uses keypoint estimation to find center points and regresses to all other object properties, such as size, 3D location, orientation, and even pose. )
- 在 COCO 目标检测数据上,实现了不错的速度和精度 trade-off(效果一般哈)
4 Method
【CenterMask】《CenterMask:Single Shot Instance segmentation with Point Representation》 文章中,就是基于 CenterNet 改进的,关于检测的部分细节完全一样

C = 80 for COCO(类别数)
也即如下的形式
 【CenterMask】《CenterMask:Single Shot Instance segmentation with Point Representation》
【CenterMask】《CenterMask:Single Shot Instance segmentation with Point Representation》
4.1 2D Objects as Points
1)中心点 Loss
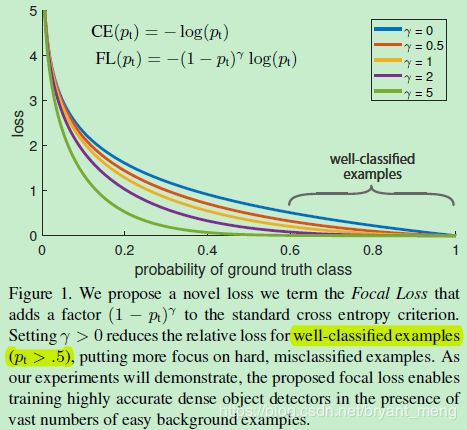
预测中心点的损失,公式如下,是基于 focal loss 的修改版(a pixel-wise logistic regression modified by the focal loss)

其中
- Y ^ x y c ∈ R H R × W R × C \hat{Y}_{xyc} \in \mathbb{R}^{\frac{H}{R} × \frac{W}{R} × C} Y^xyc∈RRH×RW×C 表示是第 c c c 类 heatmap 中,位置 ( x , y ) (x,y) (x,y) 处预测出来的 score,也即 detection confidence
- Y x y c Y_{xyc} Yxyc 是对应的 GT
- N N N 是图片中的中心点个数
- α = 2 \alpha = 2 α=2、 β = 4 \beta = 4 β=4 是超参数
仔细推导,就是把 logistic regression Loss 中的 cross entopy 换成了 focal loss 的形式!仅仅多了一个超参数 β \beta β 而已!( y = 1 y = 1 y=1 的时候,在 focal 代入 y y y 和 y ^ \hat{y} y^, y y y 不等于 1 的时候,在 focal loss 中代入 1 − y 1-y 1−y 和 1 − y ^ 1-\hat{y} 1−y^)
logistic regression 的 binary cross entropy 如下:

Focal Loss 如下:
关于 Focal Loss 的解析可以参考 【Focal Loss】《Focal Loss for Dense Object Detection》
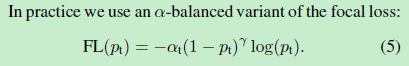
公式中 Y x y c Y_{xyc} Yxyc 的定义同 Hourglass Network (参考 【Stacked Hourglass】《Stacked Hourglass Networks for Human Pose Estimation》),也即标签采用的是中心点的高斯分布,而不是仅有一个像素
GT 的高斯分布表达如下
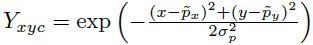
2)偏置 Loss
L1 Loss,来 recover the discretization error caused by the output stride
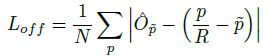
其中
- O ^ ∈ R H R × W R × 2 \hat{O} \in \mathbb{R}^{\frac{H}{R} × \frac{W}{R} × 2} O^∈RRH×RW×2 为预测的 offset
- p p p 是 GT
- R R R 是 output stride,也就是 heatmap 大小与原图大小的比例关系,为 4
- 特征图的中心点和原图中心点的映射关系为
p ~ = ⌊ p R ⌋ \widetilde{p} = \left \lfloor \frac{p}{R} \right \rfloor p =⌊Rp⌋
比如中心点在原图(15,15)处,R=4,那么精确地映射到特征图上对应着应该是 (3.75,3.75)处,但特征图最小的分辨率是 1 像素嘛,所以预测的中心点最准的地方只能为(3,3)!(3,3)还原到原始图处为(12,12),与(15,15)有了 3 个像素的偏差嘛,为了弥补这个偏差,我们需要在特征图(3,3)的基础上,学出一个(0.75,0.75)的偏置,这样的话恢复到原始图片大小,就能逼近(15,15)了
3)边界框大小 Loss
目标 k k k 的边界框表示为 ( x 1 ( k ) , y 1 ( k ) , x 2 ( k ) , y 2 ( k ) ) (x_1^{(k)},y_1^{(k)},x_2^{(k)},y_2^{(k)}) (x1(k),y1(k),x2(k),y2(k)),对应的类别用 c k c_k ck 表示!
中心点坐标为
![]()
边界框的大小为
![]()
边界框的损失为

其中
- S ^ ∈ R H R × W R × 2 \hat{S}\in \mathbb{R}^{\frac{H}{R} × \frac{W}{R} × 2} S^∈RRH×RW×2 表示预测出来的边界框大小
- S k = ( h , w ) {S}_k = (h,w) Sk=(h,w) 是 GT object size
CenterNet 做 2D 目标检测的整体流程如下
【CenterMask】《CenterMask:Single Shot Instance segmentation with Point Representation》
整体 Loss 为
![]()
其中, λ s i z e 和 λ o f f \lambda_{size} 和 \lambda_{off} λsize和λoff 分别被设置为了 0.1 和 1
测试的时候,一张热力图中,如果该点为 8 邻域响应最高的点,就为中心点(实现的时候采用 3x3 max-pooling 操作即可,感觉如果 max-pooling 的结果如果和自己相同,就保留),输出 top-100 的 center point,预测出来的边界框为

其中
![]()
是预测出的第 i i i 个中心点
![]()
是预测出的偏置
![]()
是预测出的边界框大小
4.2 Human pose estimation

k = 17 k = 17 k=17 for COCO
1)直接回归偏置
l j = ( x ^ , y ^ ) + J ^ x ^ y ^ j l_j = (\hat{x},\hat{y}) + \hat{J}_{\hat{x}\hat{y}j} lj=(x^,y^)+J^x^y^j
其中,
- j ∈ 1... k j \in 1...k j∈1...k,表示关键点的类型
- ( x ^ , y ^ ) (\hat{x},\hat{y}) (x^,y^) 是关键点坐标
- J ^ ∈ R H R × W R × k × 2 \hat{J} \in \mathbb{R}^{\frac{H}{R} × \frac{W}{R} × k ×2} J^∈RRH×RW×k×2 是用 L1 Loss 来优化的 offset
Here, our center offset acts as a grouping cue, to assign individual keypoint detections to their closest person instance.
2)与此同时,预测热力图 Φ ∈ R H R × W R × k \Phi \in \mathbb{R}^{\frac{H}{R}× \frac{W}{R} × k} Φ∈RRH×RW×k,配合 focal loss 来 refine 关键点
L j = { l ~ i j } i = 1 n j L_j = \{\widetilde{l}_{ij}\}_{i=1}^{n_j} Lj={l ij}i=1nj
这个 n n n 是什么意思?
保留 confidence > 0.1 的 keypoints
3)最后让两者逼近?
![]()
由于背景知识较少,这部分不知道自己理解错了没,感觉以预测1)偏置为主,热力图 2)只是精修下回归出的关键点的位置!
注意,上面操作 considering only joint detections within the bounding box of the detected object.(还是依托在目标检测任务之上)
5 Experiments
5.1 Datasets
- MS COCO
- 118k training images (train2017)
- 5k validation images (val2017)
- 20k hold-out testing images (test-dev)
- Pascal VOC
- MS COCO keypoint dataset
- KITTI benchmark
5.2 Implementation details
采用了 ResNet、DLA、Hourglass 三种主干网络(【Stacked Hourglass】《Stacked Hourglass Networks for Human Pose Estimation》)


作者在 ResNet 和 DLA 的 3 次上采样之前(32 倍变成 4 倍),用了 3×3 的 deformable Conv,上采样采用的是 bilinear interpolation
输入的分辨率都是 512×512
data augmentation
- random flip,
- random scaling (between 0.6 to 1.3)
- cropping
- color jittering
inference 的时候有如下三种策略
- no augmentation,
- flip augmentation,
- flip and multi-scale (0.5, 0.75, 1, 1.25, 1.5)——multi-scale时,用 NMS 来合并结果
5.3 Object detection
5.3.1 Experiments on MS COCO
速度和精度的 trade-off
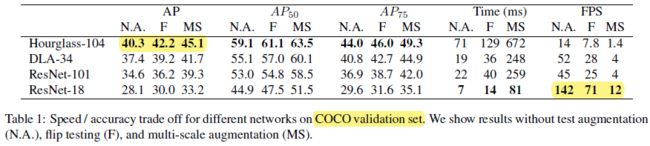
四种方法的 AP 对应着 Fig.1 的部分点

最高的精度(42:2% AP in 7:8 FPS)比 CornerNet(40:6% AP in 4:1 FPS) 和 ExtremeNet(40:3% AP in 3:1 FPS) 效果好,Better accuracy indicates that center points are easier to detect than corners or extreme points
和 State-of-the-art comparison 比较

实话说,还是二阶段的猛
5.3.2 Additional experiments
1)Center point collision
如果两个同类物体,在热力图上中心点是一样的,CenterNet 只能预测出其中第一个,作者统计了 COCO 数据集,共 860001 objects 中,有 614 pairs of objects(< 0.1%) 在步长为 4 的特征图上出现了 Center point collision!
SS 方法,会有 ~2% 的这种情况(imperfect region proposals)
Faster R-CNN 方法,会有 ~20.0% 的重叠(可能是在步长为 16 或者 32 的条件下吧 insufficient anchor placement)
2)NMS
For DLA-34 (flip-test),用和不用效果为 39.2% to 39.7%
For Hourglass-104,用和不用效果都为 42.2%
所以 CenterNet 可以砍掉 NMS 这种后处理操作
3)Training and Testing resolution

这里应该指的是不用 padding 和用 padding 的区别的吧
4)Regression loss

size regression 时,L1 比 Smooth L1 效果更好
5)Bounding box size weight

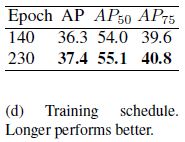
6)Training schedule
5.3.3 Error Analysis

用 GT 来替换相应的检测部位,可以看到,上限能高达 99.5!
5.3.4 Experiments on Pascal VOC

5.3.5 3D detection
没接触过,这里就省略了
5.4 Pose estimation

效果一般般啦,用热力图 refine 比直接回归的效果要好(reg vs jd)
最后感受下 CenterNet 在三个任务上的结果


6 Conclusion(own)
- anchor 少,每个目标 只对应一个 positive,不用 NMS,易于 end-to-end train,且最小的 feature map 分辨率仅为原图的 ( 1 4 , 1 4 \frac{1}{4},\frac{1}{4} 41,41)
- Detector 效果没有二阶段的猛,keypoint estimation 效果一般般,3D 没接触过,不好评估,存在少量实例中心点重叠的情况!keypoint estimation 还是要基于 detectors 的框框里面的,来区分实例
- 错误分析实验很有启发,上限有 99.5,西天取经路漫漫矣