ORACLE公司自86年推出版本5开始,系统具有分布数据库处理功能.88年推出版本6,ORACLE RDBMS(V6.0)可带事务处理选项(TPO),提高了事务处理的速度.1992年推出了版本7,在ORACLE RDBMS中可带过程数据库选项(procedural database option)和并行服务器选项(parallel server option),称为ORACLE7数据库管理系统,它释放了开放的关系型系统的真正潜力。ORACLE7的协同开发环境提供了新一代集成的软件生命周期开发环境,可用以实现高生产率、大型事务处理及客户/服务器结构的应用系统。协同开发环境具有可移植性,支持多种数据来源、多种图形用户界面及多媒体、多民族语言、CASE等协同应用系统。 一. ORACLE系统 1. ORACLE产品结构及组成
ORACLE系统是由以RDBMS为核心的一批软件产品构成,其产品结构轮廓下图所示: 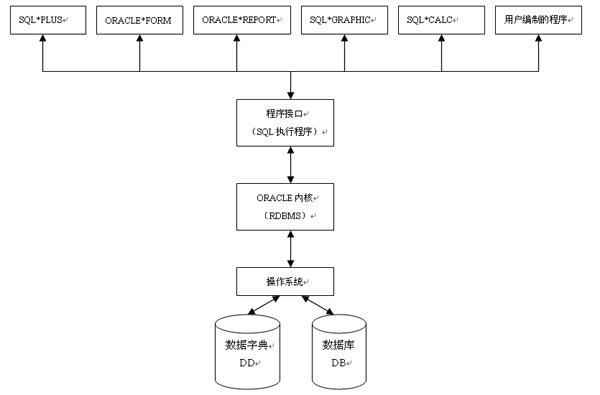
2. ORACLE系统特点
ORACLE公司于1979年,首先推出基于SQL标准的关系数据库产品,可在100多种硬件平台上运行(所括微机、工作站、小型机、中型机和大型机),支持很多种操作系统。用户的ORACLE应用可方便地从一种计算机配置移至另一种计算机配置上。ORACLE的分布式结构可将数据和应用驻留在多台计算机上,而相互间的通信是透明的。1992年6月ORACLE公司推出的ORACLE7协同服务器数据库,使关系数据库技术迈上了新台阶。根据IDG(国际数据集团)1992年全球UNIX数据库市场报告,ORACLE占市场销售量50%。它之所以倍受用户喜爱是因为它有以下突出的特点:
● 支持大数据库、多用户的高性能的事务处理。ORACLE支持最大数据库,其大小可到几百千兆,可充分利用硬件设备。支持大量用户同时在同一数据上执行各种数据应用,并使数据争用最小,保证数据一致性。系统维护具有高的性能,ORACLE每天可连续24小时工作,正常的系统操作(后备或个别计算机系统故障)不会中断数据库的使用。可控制数据库数据的可用性,可在数据库级或在子数据库级上控制。
● ORACLE遵守数据存取语言、操作系统、用户接口和网络通信协议的工业标准。所以它是一个开放系统,保护了用户的投资。美国标准化和技术研究所(NIST)对ORACLE7 SERVER进行检验,100%地与ANSI/ISO SQL89标准的二级相兼容。
● 实施安全性控制和完整性控制。ORACLE为限制各监控数据存取提供系统可靠的安全性。ORACLE实施数据完整性,为可接受的数据指定标准。
● 支持分布式数据库和分布处理。ORACLE为了充分利用计算机系统和网络,允许将处理分为数据库服务器和客户应用程序,所有共享的数据管理由数据库管理系统的计算机处理,而运行数据库应用的工作站集中于解释和显示数据。通过网络连接的计算机环境,ORACLE将存放在多台计算机上的数据组合成一个逻辑数据库,可被全部网络用户存取。分布式系统像集中式数据库一样具有透明性和数据一致性。
● 具有可移植性、可兼容性和可连接性。由于ORACLE软件可在许多不同的操作系统上运行,以致ORACLE上所开发的应用可移植到任何操作系统,只需很少修改或不需修改。ORACLE软件同工业标准相兼容,包括许多工业标准的操作系统,所开发应用系统可在任何操作系统上运行。可连接性是指ORALCE允许不同类型的计算机和操作系统通过网络可共享信息。 二. ORACLE数据库系统的体系结构 ORACLE数据库系统为具有管理ORACLE数据库功能的计算机系统。每一个运行的ORACLE数据库与一个ORACLE实例(INSTANCE)相联系。一个ORACLE实例为存取和控制一数据库的软件机制。每一次在数据库服务器上启动一数据库时,称为系统全局区(SYSTEM GLOBAL AREA)的一内存区(简称SGA)被分配,有一个或多个ORACLE进程被启动。该SGA 和 ORACLE进程的结合称为一个ORACLE数据库实例。一个实例的SGA和进程为管理数据库数据、为该数据库一个或多个用户服务而工作。
在ORACLE系统中,首先是实例启动,然后由实例装配(MOUNT)一数据库。在松耦合系统中,在具有ORACLE PARALLEL SERVER 选项时,单个数据库可被多个实例装配,即多个实例共享同一物理数据库。 1. ORACLE实例的进程结构和内存结构
1) 进程结构
进程是操作系统中的一种机制,它可执行一系列的操作步。在有些操作系统中使用作业(JOB)或任务(TASK)的术语。一个进程通常有它自己的专用存储区。ORACLE进程的体系结构设计使性能最大。
ORACLE实例有两种类型:单进程实例和多进程实例。
单进程ORACLE(又称单用户ORACLE)是一种数据库系统,一个进程执行全部ORACLE代码。由于ORACLE部分和客户应用程序不能分别以进程执行,所以ORACLE的代码和用户的数据库应用是单个进程执行。
在单进程环境下的ORACLE 实例,仅允许一个用户可存取。例如在MS-DOS上运行ORACLE 。
多进程ORACLE实例(又称多用户ORACLE)使用多个进程来执行ORACLE的不同部分,对于每一个连接的用户都有一个进程。
在多进程系统中,进程分为两类:用户进程和ORACLE进程。当一用户运行一应用程序,如PRO*C程序或一个ORACLE工具(如SQL*PLUS),为用户运行的应用建立一个用户进程。ORACLE进程又分为两类:服务器进程和后台进程服务器进程用于处理连接到该实例的用户进程的请求。当应用和ORACELE是在同一台机器上运行,而不再通过网络,一般将用户进程和它相应的服务器进程组合成单个的进程,可降低系统开销。然而,当应用和ORACLE运行在不同的机器上时,用户进程经过一个分离服务器进程与ORACLE通信。它可执行下列任务:
●对应用所发出的SQL语句进行语法分析和执行。
●从磁盘(数据文件)中读入必要的数据块到SGA的共享数据库缓冲区(该块不在缓冲区时)。
●将结果返回给应用程序处理。
系统为了使性能最好和协调多个用户,在多进程系统中使用一些附加进程,称为后台进程。在许多操作系统中,后台进程是在实例启动时自动地建立。一个ORACLE实例可以有许多后台进程,但它们不是一直存在。后台进程的名字为:
DBWR 数据库写入程序
LGWR 日志写入程序
CKPT 检查点
SMON 系统监控
PMON 进程监控
ARCH 归档
RECO 恢复
LCKn 封锁
Dnnn 调度进程
Snnn 服务器
每个后台进程与ORACLE数据库的不同部分交互。
下面对后台进程的功能作简单介绍:
DBWR进程:该进程执行将缓冲区写入数据文件,是负责缓冲存储区管理的一个ORACLE后台进程。当缓冲区中的一缓冲区被修改,它被标志为“弄脏”,DBWR的主要任务是将“弄脏”的缓冲区写入磁盘,使缓冲区保持“干净”。由于缓冲存储区的缓冲区填入数据库或被用户进程弄脏,未用的缓冲区的数目减少。当未用的缓冲区下降到很少,以致用户进程要从磁盘读入块到内存存储区时无法找到未用的缓冲区时,DBWR将管理缓冲存储区,使用户进程总可得到未用的缓冲区。
ORACLE采用LRU(LEAST RECENTLY USED)算法(最近最少使用算法)保持内存中的数据块是最近使用的,使I/O最小。在下列情况预示DBWR 要将弄脏的缓冲区写入磁盘:
● 当一个服务器进程将一缓冲区移入“弄脏”表,该弄脏表达到临界长度时,该服务进程将通知DBWR进行写。该临界长度是为参数DB-BLOCK-WRITE-BATCH的值的一半。
● 当一个服务器进程在LRU表中查找DB-BLOCK-MAX-SCAN-CNT缓冲区时,没有查到未用的缓冲区,它停止查找并通知DBWR进行写。
● 出现超时(每次3秒),DBWR 将通知本身。
● 当出现检查点时,LGWR将通知DBWR
在前两种情况下,DBWR将弄脏表中的块写入磁盘,每次可写的块数由初始化参数DB-BLOCK-WRITE-BATCH所指定。如果弄脏表中没有该参数指定块数的缓冲区,DBWR从LUR表中查找另外一个弄脏缓冲区。
如果DBWR在三秒内未活动,则出现超时。在这种情况下DBWR对LRU表查找指定数目的缓冲区,将所找到任何弄脏缓冲区写入磁盘。每当出现超时,DBWR查找一个新的缓冲区组。每次由DBWR查找的缓冲区的数目是为寝化参数DB-BLOCK-WRITE-BATCH的值的二倍。如果数据库空运转,DBWR最终将全部缓冲区存储区写入磁盘。
在出现检查点时,LGWR指定一修改缓冲区表必须写入到磁盘。DBWR将指定的缓冲区写入磁盘。
在有些平台上,一个实例可有多个DBWR。在这样的实例中,一些块可写入一磁盘,另一些块可写入其它磁盘。参数DB-WRITERS控制DBWR进程个数。
LGWR进程:该进程将日志缓冲区写入磁盘上的一个日志文件,它是负责管理日志缓冲区的一个ORACLE后台进程。LGWR进程将自上次写入磁盘以来的全部日志项输出,LGWR输出:
●当用户进程提交一事务时写入一个提交记录。
● 每三秒将日志缓冲区输出。
● 当日志缓冲区的1/3已满时将日志缓冲区输出。
●当DBWR将修改缓冲区写入磁盘时则将日志缓冲区输出。
LGWR进程同步地写入到活动的镜象在线日志文件组。如果组中一个文件被删除或不可用,LGWR 可继续地写入该组的其它文件。
日志缓冲区是一个循环缓冲区。当LGWR将日志缓冲区的日志项写入日志文件后,服务器进程可将新的日志项写入到该日志缓冲区。LGWR 通常写得很快,可确保日志缓冲区总有空间可写入新的日志项。
注意:有时候当需要更多的日志缓冲区时,LWGR在一个事务提交前就将日志项写出,而这些日志项仅当在以后事务提交后才永久化。
ORACLE使用快速提交机制,当用户发出COMMIT语句时,一个COMMIT记录立即放入日志缓冲区,但相应的数据缓冲区改变是被延迟,直到在更有效时才将它们写入数据文件。当一事务提交时,被赋给一个系统修改号(SCN),它同事务日志项一起记录在日志中。由于SCN记录在日志中,以致在并行服务器选项配置情况下,恢复操作可以同步。 CKPT进程:该进程在检查点出现时,对全部数据文件的标题进行修改,指示该检查点。在通常的情况下,该任务由LGWR执行。然而,如果检查点明显地降低系统性能时,可使CKPT进程运行,将原来由LGWR进程执行的检查点的工作分离出来,由CKPT进程实现。对于许多应用情况,CKPT进程是不必要的。只有当数据库有许多数据文件,LGWR在检查点时明显地降低性能才使CKPT运行。CKPT进程不将块写入磁盘,该工作是由DBWR完成的。
初始化参数CHECKPOINT-PROCESS控制CKPT进程的使能或使不能。缺省时为FALSE,即为使不能。 SMON进程:该进程实例启动时执行实例恢复,还负责清理不再使用的临时段。在具有并行服务器选项的环境下,SMON对有故障CPU或实例进行实例恢复。SMON进程有规律地被呼醒,检查是否需要,或者其它进程发现需要时可以被调用。 PMON进程:该进程在用户进程出现故障时执行进程恢复,负责清理内存储区和释放该进程所使用的资源。例:它要重置活动事务表的状态,释放封锁,将该故障的进程的ID从活动进程表中移去。PMON还周期地检查调度进程(DISPATCHER)和服务器进程的状态,如果已死,则重新启动(不包括有意删除的进程)。
PMON有规律地被呼醒,检查是否需要,或者其它进程发现需要时可以被调用。 RECO进程:该进程是在具有分布式选项时所使用的一个进程,自动地解决在分布式事务中的故障。一个结点RECO后台进程自动地连接到包含有悬而未决的分布式事务的其它数据库中,RECO自动地解决所有的悬而不决的事务。任何相应于已处理的悬而不决的事务的行将从每一个数据库的悬挂事务表中删去。
当一数据库服务器的RECO后台进程试图建立同一远程服务器的通信,如果远程服务器是不可用或者网络连接不能建立时,RECO自动地在一个时间间隔之后再次连接。
RECO后台进程仅当在允许分布式事务的系统中出现,而且DISTRIBUTED – TRANSACTIONS参数是大于0。 ARCH进程:该进程将已填满的在线日志文件拷贝到指定的存储设备。当日志是为ARCHIVELOG使用方式、并可自动地归档时ARCH进程才存在。 LCKn进程:是在具有并行服务器选件环境下使用,可多至10个进程(LCK0,LCK1……,LCK9),用于实例间的封锁 Dnnn进程(调度进程):该进程允许用户进程共享有限的服务器进程(SERVER PROCESS)。没有调度进程时,每个用户进程需要一个专用服务进程(DEDICATEDSERVER PROCESS)。对于多线索服务器(MULTI-THREADED SERVER)可支持多个用户进程。如果在系统中具有大量用户,多线索服务器可支持大量用户,尤其在客户_服务器环境中。
在一个数据库实例中可建立多个调度进程。对每种网络协议至少建立一个调度进程。数据库管理员根据操作系统中每个进程可连接数目的限制决定启动的调度程序的最优数,在实例运行时可增加或删除调度进程。多线索服务器需要SQL*NET版本2或更后的版本。在多线索服务器的配置下,一个网络接收器进程等待客户应用连接请求,并将每一个发送到一个调度进程。如果不能将客户应用连接到一调度进程时,网络接收器进程将启动一个专用服务器进程。该网络接收器进程不是ORACLE实例的组成部分,它是处理与ORACLE有关的网络进程的组成部分。在实例启动时,该网络接收器被打开,为用户连接到ORACLE建立一通信路径,然后每一个调度进程把连接请求的调度进程的地址给予于它的接收器。当一个用户进程作连接请求时,网络接收器进程分析请求并决定该用户是否可使用一调度进程。如果是,该网络接收器进程返回该调度进程的地址,之后用户进程直接连接到该调度进程。有些用户进程不能调度进程通信(如果使用SQL*NET以前的版本的用户),网络接收器进程不能将如此用户连接到一调度进程。在这种情况下,网络接收器建立一个专用服务器进程,建立一种合适的连接。 2)、ORACLE内存结构
ORACLE在内存存储下列信息:
●执行的程序代码。
●连接的会话信息
●程序执行期间所需数据和共享的信息
●存储在外存储上的缓冲信息。
ORACLE具有下列基本的内存结构:
●软件代码区
●系统全局区,包括数据库缓冲存储区、日志缓冲区和共享池.
●程序全局区,包括栈区和数据区.
● 排序区 软件代码区
用于存储正在执行的或可以执行的程序代码。
软件区是只读,可安装成共享或非共享。ORACLE系统程序是可共享的,以致多个ORACLE用户可存取它,而不需要在内存有多个副本。用户程序可以共享也可以不共享。 系统全局区
为一组由ORACLE分配的共享的内存结构,可包含一个数据库实例的数据或控制信息。如果多个用户同时连接到同一实例时,在实例的SGA中数据可为多个用户所共享,所以又称为共享全局区。当实例起动时,SGA的存储自动地被分配;当实例关闭时,该存储被回收。所有连接到多进程数据库实例的全部用户可自动地被分配;当实例关闭时,该存储被回收。所有连接到多进程数据库实例的全部用户可使用其SGA中的信息,但仅仅有几个进程可写入信息。在SGA中存储信息将内存划分成几个区:数据库缓冲存储区、日志缓冲区、共享池、请求和响应队列、数据字典存储区和其它各种信息。 程序全局区
PGA是一个内存区,包含单个进程的数据和控制信息,所以又称为进程全局区(PROCESS GLOBAL AREA)。 排序区
排序需要内存空间,ORACLE利用该内存排序数据,这部分空间称为排序区。排序区存在于请求排序的用户进程的内存中,该空间的大小为适就排序数据量的大小,可增长,但受初始化参数SORT-AREA-SIZER所限制。 2. ORACLE的配置方案
所有连接到ORACLE的用户必须执行两个代码模块可存取一个ORACLE数据库实例:
● 应用或ORACLE工具:一数据库用户执行一数据库应用或一个ORACLE工具,可向ORACLE数据库发出SQL语句。
●ORACLE服务器程序:负责解释和处理应用中的SQL语句。
在多进程实例中,连接用户的代码可按下列三种方案之一配置:
● 对于每一个用户,其数据库应用程序和服务器程序组合成单个用户进程
● 对于每一个用户,其数据库应用是由用户进程所运行,并有一个专用服务器进程。执行ORACLE服务器的代码。这样的配置称为专用服务器体系结构
●执行数据库应用的进程不同于执行ORACLE服务器代码的进程,而且每一个服务器进程(执行ORACLE服务器代码)可服务于多个用户进程,这样的配置称为多线索服务器体系结构。 1) USER/SERVER进程相结合的结构
在这种配置下,数据库应用和ORACLE服务器程序是在同一个进程中运行,该进程称为用户进程。
这种ORACLE配置有时称为单任务ORACLE(single_task ORACLE),该配置适用于这样的操作系统,它可在同一进程中的数据库应用和ORACLE代码之间维护一个隔离,该隔离是为数据安全性和完整性所需。其中程序接口(program interface)是负责ORACLE服务器代码的隔离和保护,在数据库应用和ORACLE用户程序之间传送数据。 2) 使用专用服务器进程的系统结构
使用专用服务器进程的ORACLE系统在两台计算机上运行。在这种系统中,在一计算机上用户进程执行数据库应用,而在另一台计算机上的服务器进程执行相应的ORACLE服务器代码,这两个进程是分离的。为每个用户进程建立的不同的服务器进程称为专用服务器进程,因为该服务器进程仅对相连的用户进程起作用。这种配置又称为两任务ORACLE。每一个连接到ORACLE的用户进程有一个相应的专用服务进程。这种系统结构允许客户应用是有工作站上执行,通过网络与运行ORACLE的计算机通信。当客户应用和ORACLE服务器代码是在同一台计算机上执行时,这种结构也可用。 3) 多线索服务器的系统结构
多线索服务器配置允许许多用户进程共享很少服务器进程。在没有多线索服务器的配置中,每一个用户进程需要自己的专用服务器进程。在具有多线索服务器的配置中,许多用户进程连接到调度进程,由调度进程将客户请求发送到一个共享服务器进程。多线索服务器配置的优点是降低系统开销,增加用户个数。 该系统中需要下列类型的进程:
● 网络接收器进程,将用户进程连接到调度进程和专用服务器进程。
●一个或多个调度进程
●一个或多个共享服务器进程
其中网络接收器进程等待新来的连接请求,决定每一用户进程能否用共享服务器进程。如果可以使用,接收器进程将一调度进程的地址返回给用户进程。如果用户进程请求一专用服务器,该接收器进程将建立一个专用服务器进程,将用户进程连接到该专用服务器进程。对于数据库客户机所使用的每种网络协议至少配置一个调度进程,并启动它。
当用户作一次调用时,调度进程将请求放置在SGA的请求队列中,由可用的共享服务器进程获取。共享服务器进程为完成每一个用户进程的请求作所有必要的数据库调用。当服务器完成请求时,将结果返回到调度进程的队列,然后由调度进程将完成的请求返回给用户进程。
共享服务器进程:除共享服务器进程不是连接指定的用户进程外,共享服务器进程和专用服务器进程提供相同的功能,一个共享服务器进程在多线索服务器的配置中可为任何客户请求服务。一个共享服务器进程的SGA不包含有与用户相关的数据,其信息可为所有共享服务器进程存取,它仅包含栈空间、进程指定变量。所有与会话有关的信息是包含有SGA中。每一个共享服务器进程可存取全部会话的数据空间,以致任何服务进程可处理任何会话的请求。对于每一个会话的数据空间是在SGA中分配空间。
ORACLE根据请求队列的长度可动态地调整共享服务器进程。可建立的共享服务器进程将请求放到请求队列。一个用户请求是对数据库的一次程序接口调用,为SQL语句。在SGA中请求队列对实例的全部调度进程是公用的。服务器进程为新请求检查公用请求队列,按先进先出的原则从队列检出一个请求,然后为完成该请求对数据库作必要的调用。共享服务器进程将响应放在调度进程的响应队列。每一个调度进程在SGA中有自己的响应队列,每个调度进程负责将完成的请求回送给相应的用户进程。 3.ORACLE运行
1) 使用专用服务进程的ORACLE的运行
在这种配置下,ORACLE运行过程如下:
(1) 数据库服务器计算机当前正在运行ORACLE(后台进程)。
(2) 在一客户工作站运行一个数据库应用(为用户进程),如SQL*PLUS。客户应用使用SQL*NET DRIVER建立对服务器的连接。
(3) 数据库服务器计算机当前正运行合适的SQL*NET DRIVER,该机上接收器进程检出客户数据库应用的连接请求,并在该机上为用户进程建立专用服务器进程。
(4) 用户发出单个SQL语句。
(5) 专用服务器进程接收该语句,在此处有两种方法处理SQL语句:
●如果在共享池一共享SQL区中包含有相同SQL语句时,该服务器进程可利用已存在的共享SQL区执行客户的SQL语句。
●如果在共享池中没有一个SQL区包含有相同的SQL语句时,在共享池中为该语句分配一新的共享SQL区。
在每一种情况,在会话的PGA中建立一个专用SQL区,专用服务器进程检查用户对查询数据的存取权限。
(6) 如果需要,服务器进程从数据文件中检索数据块,或者可使用已存储在实例SGA中的缓冲存储区的数据块。
(7) 服务器进程执行存储在共享SQL区中的SQL语句。数据首先在SGA中修改,由DBWR进程在最有效时将它写入磁盘。LGWR进程在在线日志文件中记录用户提交请求的事务。
(8)如果请求成功,服务器将通过网络发送一信息。如果请求不成功,将发送相应的错误信息。
(9)在整个过程中,其它的后台进程是运行的,同时注意需要干预的条件。另外,ORACLE管理其它事务,防止不同事务之间请求同一数据的竞争。
2) 使用多线索服务器的ORACLE的运行
在这种配置下,ORACLE运行过程如下:
(1) 一数据库服务器计算机运行使用多线索服务器配置的ORACLE。
(2) 在一客户工作站运行一数据库应用(在一用户进程中)。客户应用合适的SQL*NET驱动器试图建立到数据库服务器计算机的连接。
(3) 数据库服务器计算机当前运行合适的SQL*NET驱动器,它的网络接收器进程检出用户进程的连接请求,并决定用户进程如何连接。如果用户是使用SQL*NET版本2,该网络接收器通知用户进程使用一个可用的调度进程的地址重新连接。
(4) 用户发出单个SQL语句
(5) 调度进程将用户进程的请求放入请求队列,该队列位于SGA中,可为所有调度进程共享。
(6) 一个可用共享服务器检验公用调度进程请求队列,并从队列中检出下一个SQL语句。然后处理该SQL语句,同前一(5),(6)和(7)。注意:会话的专用SQL区是建立在SGA中。
(7) 一当共享服务器进程完成SQL处理,该进程将结果放置发入该请求的调度进程的响应队列。
(8) 调度进程检查它的响应队列,并将完成的请求送回请求的用户进程。
4.数据库结构和空间管理
一个ORACLE数据库是数据的集合,被处理成一个单位。一个ORACLE数据库有一个物理结构和一个逻辑结构。
物理数据库结构(physical database structure)是由构成数据库的操作系统文件所决定。每一个ORACLE数据库是由三种类型的文件组成:数据文件、日志文件和控制文件。数据库的文件为数据库信息提供真正的物理存储。
逻辑数据库结构是用户所涉及的数据库结构。一个ORACLE数据库的逻辑结构由下列因素决定:
● 一个或多个表空间
●数据库模式对象(即表、视图、索引、聚集、序列、存储过程)
逻辑存储结构如表空间(dataspace)、段(segment)和范围将支配一个数据库的物理空间如何使用。模式对象(schema object)用它们之间的联系组成了一个数据库的关系设计。 1) 物理结构 (1) 数据文件
每一个ORACLE数据库有一个或多个物理的数据文件(data file)。一个数据库的数据文件包含全部数据库数据。逻辑数据库结构(如表、索引)的数据物理地存储在数据库的数据文件中。数据文件有下列特征:
●一个数据文件仅与一个数据库联系。
●一旦建立,数据文件不能改变大小
● 一个表空间(数据库存储的逻辑单位)由一个或多个数据文件组成。
数据文件中的数据在需要时可以读取并存储在ORACLE内存储区中。例如:用户要存取数据库一表的某些数据,如果请求信息不在数据库的内存存储区内,则从相应的数据文件中读取并存储在内存。当修改和插入新数据时,不必立刻写入数据文件。为了减少磁盘输出的总数,提高性能,数据存储在内存,然后由ORACLE后台进程DBWR决定如何将其写入到相应的数据文件。 (2) 日志文件
每一个数据库有两个或多个日志文件(redo log file)的组,每一个日志文件组用于收集数据库日志。日志的主要功能是记录对数据所作的修改,所以对数据库作的全部修改是记录在日志中。在出现故障时,如果不能将修改数据永久地写入数据文件,则可利用日志得到该修改,所以从不会丢失已有操作成果。
日志文件主要是保护数据库以防止故障。为了防止日志文件本身的故障,ORACLE允许镜象日志(mirrored redo log),以致可在不同磁盘上维护两个或多个日志副本。
日志文件中的信息仅在系统故障或介质故障恢复数据库时使用,这些故障阻止将数据库数据写入到数据库的数据文件。然而任何丢失的数据在下一次数据库打开时,ORACLE自动地应用日志文件中的信息来恢复数据库数据文件。 (3) 控制文件
每一ORACLE数据库有一个控制文件(control file),它记录数据库的物理结构,包含下列信息类型:
● 数据库名;
● 数据库数据文件和日志文件的名字和位置;
● 数据库建立日期。
为了安全起见,允许控制文件被镜象。
每一次ORACLE数据库的实例启动时,它的控制文件用于标识数据库和日志文件,当着手数据库操作时它们必须被打开。当数据库的物理组成更改时,ORACLE自动更改该数据库的控制文件。数据恢复时,也要使用控制文件。 2) 逻辑结构
数据库逻辑结构包含表空间、段、范围(extent)、数据块和模式对象。
(1) 表空间
一个数据库划分为一个或多个逻辑单位,该逻辑单位称为表空间(TABLESPACE)。一个表空间可将相关的逻辑结构组合在一起。DBA可利用表空间作下列工作:
●控制数据库数据的磁盘分配。
● 将确定的空间份额分配给数据库用户。
●通过使单个表空间在线或离线,控制数据的可用性。
●执行部分数据库后备或恢复操作。
●为提高性能,跨越设备分配数据存储。
数据库、表空间和数据文件之间的关系如下图所示:
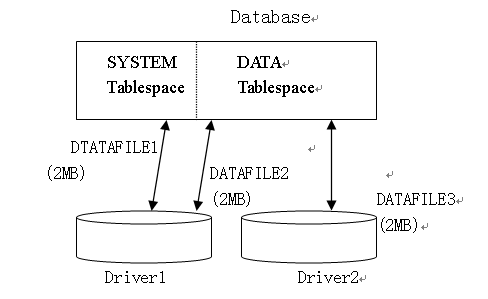
每个数据库可逻辑划分为一个或多个表空间。
每一个表空间是由一个或多个数据文件组成,该表空间物理地存储表空间中全部逻辑结构的数据。DBA可以建立新的表空间,可为表空间增加数据文件或可删除数据文件,设置或更改缺省的段存储位置。 每一个ORACLE数据库包含有一个名为SYSTEM的表空间,在数据库建立是自动建立。在该表空间中总包含有整个数据库的数据字典表。最小的数据库可只需要SYSTEM表空间。该表空间必须总是在线。表和存储的PL/SQL程序单元(过程函数、包和触发器)的全部存储数据是存储在SYSTEM表空间中。如果这些PL/SQL对象是为数据库建的,DBA在SYSTEM表空间中需要规划这些对象所需要的空间。
表空间利用增加数据文件扩大表空间,表空间的大小为组成该表空间的数据文件大小的和。
DBA可以使ORACLE数据库中任何表空间(除SYSTEM表空间外)在线(ONLINE)或离线(OFFLINE)。表空间通常是在线以致它所包含的数据对数据库用户是可用的。当表空间为离线时,其数据不可使用。在下列情况下,DBA可以使其离线。
使部分数据不可用,而剩余的部分允许正常存取
执行离线的表空间后备
。为了修改或维护一应用,使它和它的一组表临时不可用。
包含有正在活动的回滚段的表空间不能被离线,仅当回滚段不正在使用时,该表空间才可离线。
在数据字典中记录表空间的状态,在线还是离线。如果在数据库关闭时一表空间为离线,那么在下次数据库装配和重新打开后,它仍然保持离线。
当出现某些错误时,一个表空间可自动地由在线改变为离线。通过使用多个表空间,将不同类型的数据分开,更方便DBA来管理数据库。
ORACLE数据库中一表空间是由一个或多个物理数据文件组成,一个数据文件只可与一个表空间想联系。当为一表空间建立一数据文件时,ORACLE建立该文件,分配指定的磁盘空间容量。在数据文件初时建立后,所分配的磁盘不包含任何数据。表空间可以在线或离线。在ORACLE中还允许单独数据文件在线或离线。 (2) 段、范围和数据块
ORACLE通过段、范围和数据块逻辑数据结构可更细地控制磁盘空间的使用。 段
段(SEGMENT)包含表空间中一种指定类型的逻辑存储结构,是由一组范围组成。在ORACLE数据库中有几种类型的段:数据段、牵引段、回滚段和临时段。
数据段:对于每一个非聚集的表有一数据段,表的所有数据存放在该段。每一聚集有一个数据段,聚集中每一个表的数据存储在该段中。
索引段:每一个索引有一索引段,存储索引数据。
回滚段:是由DBA建立,用于临时存储要撤消的信息,这些信息用于生成读一致性数据库信息、在数据库恢复时使用、回滚未提交的事务。
临时段:当一个SQL语句需要临时工作区时,由ORACLE建立。当语句执行完毕,临时段的范围退回给系统。
ORACLE对所有段的空间分配,以范围为单位。 范围
一个范围(EXTENT)是数据库存储空间分配的一个逻辑单位,它由连续数据块所组成。每一个段是由一个或多个范围组成。当一段中间所有空间已完全使用时,ORACLE为该段分配一个新的范围。
为了维护的目的,在数据库的每一段含有段标题块(segment header block)说明段的特征以及该段中的范围目录。 数据块
数据块(data block)是ORACLE管理数据文件中存储空间的单位,为数据库使用的I/O的最小单位,其大小可不同于操作系统的标准I/O块大小。
数据块的格式:
(3) 模式和模式对象
一个模式(schema)为模式对象(scehma object)的一个集合,每一个数据库用户对应一个模式。模式对象为直接引用数据库数据的逻辑结构,模式对象包含如表、视图、索引、聚集、序列、同义词、数据库链、过程和包等结构。模式对象是逻辑数据存储结构,每一种模式对象在磁盘上没有一个相应文件存储其信息。一个模式对象逻辑地存储在数据库的一个表空间中,每一个对象的数据物理地包含在表空间的一个或多个数据文件中。 表
表(table)为数据库中数据存储的基本单位,其数据按行、列存储。每个表具有一表名和列的集合。每一列有一个列名、数据类型、宽度或精度、比例。一行是对应单个记录的列信息的集合。 视图
一个视图(view)是由一个或多个表(或其他视图)中的数据的一种定制的表示,是用一个查询定义,所以可认为是一个存储的查询(stored query)或是一个虚表(virtual table)。视图可在使用表的许多地方使用。
由于视图是由表导出的,视图和表存在许多类似,视图象表最多可定义254列。视图可以被查询,而在修改、插入或删除时具有一定的限制,在视图上执行的全部操作真正地影响视图的基本表中的数据,受到基本表的完整性约束和触发器的限制。
视图与表不同,一个视图不分配任何存储空间,视图不真正地包含数据。由查询定义的视图相应于视图引用表中的数据。视图只在数据字典中存储其定义。
引入视图有下列好处:
。通过限制对表的行预定义集合的存取,为表提供附加的安全性
。隐藏数据复杂性。
。为用户简化命令
。为基本表的数据提供另一种观点。
。可将应用隔离基本表定义的修改
。用于不用视图无法表示的查询。
。可用于保存复杂查询。 聚集
聚集(cluster)是存储表数据的可选择的方法。一个聚集是一组表,将具有同一公共列值的行存储在一起,并且它们经常一起使用。这些公共列构成聚集码。例如:EMP表各DEPT表共享DEPTNO列,所以EMP表和DEPT表可聚集在一起,聚集码的列为DEPTNO列,该聚集将每个部门的全部职工行各该部门的行物理地存储在同一数据块中。 索引
索引(index)是与表和聚集相关的一种选择结构。索引是为提高数据检索的性能而建立,利用它可快速地确定指定的信息。ORACLE索引为表数据提供快速存取路径。索引适用于一范围的行查询或指定行的查询。
索引可建立在一表的一列或多列上,一旦建立,由ORACLE自动维护和使用,对用户是完全透明的。索引是逻辑地和物理地独立于数据,它们的建立或删除对表没有影响,应用可继续处理。索引数据的检索性能几乎保持常数,而当一表上存在许多索引时,修改、删除和插入操作的性能会下降。
索引有唯一索引各非唯一索引。唯一索引保证表中没有两行在定义索引的列上具有重复值。ORACLE在唯一码上自动地定义唯一索引实施UNIQUE完整性约束。
组合索引是在表的某个列上所建立的一索引。组全索引可加快SELECT语句的检索速度,在其WHERE子句中可引用组合索引的全部或主要部分 。所以在定义中给出列的次序,将经常存取的或选择最多的列放在首位。
在建立索引时,将在表空间自动地建立一索引段,索引段空间分配和保留空间的使用受下列方式控制:
索引段范围的分配常驻该索引段的存储参数控制。
其数据块中未用空间可受该段的PCTFREE参数设置所控制。 序列生成器
序列生成器(sequence generator)产生序列号。在多用户环境下该序列生成器特别有用,可生成各返回序列号而不需要磁盘I/O或事务封锁。
序列号为ORACLE整数,最多可有38个数字。一个序列定义指出一般信息:序列的名字、上升或下降、序列号之间间距和其它信息。对所有序列的确的定义以行存储在SYSTEM表空间中的数据字典表中,所以所有序列定义总是可用。由引用序列号的SQL语句使用序列号,可生成一个新的序列号或使用当前序列号。一旦在用户会话中的SQL语句生成一序列号,该序列号仅为该会话可用。序列号生成是独立于表,所以同一序列生成器可用于一个和多个表。所生成序列号可用于生成唯一的主码。 同义词
一个同义词(synonym)为任何表、视图、快照、序列、过程、函数或包的别名,其定义存储在数据字典中。同义词因安全性和方便原因而经常使用,可用于:
●可屏蔽对象的名字及其持有者。
●为分布式数据库的远程对象提供位置透明性。
●为用户简化SQL语句。
有两种同义词:公用和专用。一个公用同义词为命名为PUBLIC特殊用户组所持有,可为数据库中每一个用户所存取。一个专用同义词是包含在指定用户的模式中,仅为该用户和授权的用户所使用。 杂凑
杂凑(hashing)是存储表数据一种可选择的方法,用以改进数据检索的性能。要使用杂凑,就要建立杂凑聚集,将表装入到该聚集。在骠凑聚集中的表行根据杂凑函数的结果进行物理学存储和检索。杂凑函数用于生成一个数值的分布,该数值称为杂凑值,它是基于指定的聚集码值。 程序单元
程序单元(program unit)是指存储过程、函数和包(PACKAGE)。一个过程和函数,是由SQL语句和PL/SQL语句组合在一起,为执行某一个任务的一个可执行单位。一个过程或函数可被建立,在数据库中存储其编译形式,可由用户或数据库应用所执行。过程和函数差别在函数总返回单个值给调用者,而过程没有值返回给调用者。
包提供相关的过程、函数、变量和其它包结构封装起来并存贮在一起的一种方法,允许管理者和应用开发者利用该方法组织如此的程序(routine),来提供更多的功能和提高性能。 数据库链
数据库链是一个命名的对象,说明从一数据库到另一数据库的一路径(PATH)。在分布式数据库中,对全局对象名引用时,数据库链隐式地使用。 三. 数据库和实例的启动和关闭
一个ORACLE数据库没有必要对所有用户总是可用,数据库管理员可启动数据库,以致它被打开。在数据库打开情况下,用户可存取数据库中的信息。当数据库不使用时,DBA可关闭它,关闭后的数据库,用户不能存取其信息。
数据库的启动和关闭是非常重要的管理功能,通过以INTERNAL连接到ORACLE的能力来保护。以INTERNAL 连接到ORACLE需要有下列先决条件:
该用户的操作系统账号具有使用INTERNAL连接的操作系统特权。
对INTERNAL数据库有一口令,该用户知道其口令。
另外:当用户以INTERNAL连接时,可连接到专用服务器,而且是安全连接。
1. 数据库启动
启动数据库并使它可用有三步操作:
●启动一个实例;
●装配数据库
●打开数据库 1) 启动一个实例
启动一实例的处理包含分配一个SGA(数据库信息使用的内存共享区)和后台进程的建立。实例起动的执行先于该实例装配一数据库。如果仅启动实例,则没有数据库与内存储结构和进程相联系 2) 装配一数据库
装配数据库是将一数据库与已启动的实例相联。当实例安装一数据库之后,该数据库保持关闭,仅DBA可存取。 3) 打开一数据库
打开一数据库是使数据库可以进行正常数据库操作的处理。当一数据库打开所有用户可连接到该数据库用存取其信息。在数据库打开时,在线数据文件和在线日志文件也被打开。如果一表空间在上一次数据库关闭时为离线,在数据库再次打开时,该表空间与它所相联的数据文件还是离线的。 2. 数据库和实例的关闭 关闭一实例以及它所连接的数据库也有三步操作: 1) 关闭数据库
数据库停止的第一步是关闭数据库。当数据库关闭后,所有在SGA中的数据库数据和恢复数据相应地写入到数据文和日志文件。在这操作之后,所有联机数据文件和联机的日志文件也被关闭,任何离线表空间中数据文件夹是已关闭的。在数据库关闭后但还安装时,控制文件仍保持打开。 2) 卸下数据库
停止数据库的第二步是从实例卸下数据库。在数据库卸下后,在计算机内存中仅保留实例。在数据库卸下后,数据库的控制文件也被关闭。 3) 停止实例
停止数据库的最后一步是停止实例。当实例停止后,SAG是从内存中撤消,后台进程被中止。 3. 初始化参数文件
在启动一个实例时,ORACLE必须读入一初始化参数文件(initialization parameter file),该参数文件是一个文本文件,包含有实例配置参数。这些参数置成特殊值,用于初始ORACLE实例的许多内存和进程设置,该参数文件包:
●一个实例所启动的数据库名字
● 在SGA中存储结构使用多少内存;
● 在填满在线日志文件后作什么;
● 数据库控制文件的名字和位置;
●在数据库中专用回滚段的名字。
四. 数据字典的使用
数据字典是ORACLE数据库的最重要的部分之一,是由一组只读的表及其视图所组成。它提供有关该数据库的信息,可提供的信息如下:
● ORACLE用户的名字;
● 每一个用户所授的特权和角色;
●模式对象的名字(表、视图、快照、索引、聚集、同义词、序列、过程、函数、包及触发器等);
● 关于完整性约束的信息;
● 列的缺省值;
● 有关数据库中对象的空间分布及当前使用情况;
● 审计信息(如谁存取或修改各种对象);
●其它一般的数据库信息。
可用SQL存取数据字典,由于数据字典为只读,允许查询。
1. 数据字典的结构
数据库数据字典是由基本表和用户可存取的视图组成。
基本表:数据字典的基础是一组基本表组成,存储相关的数据库的信息。这些信息仅由ORACLE读和写,它们很少被ORACLE用户直接存取。
用户可存取视图:数据字典包含用户可存取视图,可概括地方便地显示数据字典的基本表的信息。视图将基本表中信息解码成可用信息。 2. 数据字典的使用
当数据库打开时,数据字典总是可用,它驻留在SYSTEM表空间中。数据字典包含视图集,在许多情况下,每一视图集有三种视图包含有类似信息,彼此以 前缀 相区别,前缀 USER、ALL和DBA。
● 前缀为USER的视图,为用 视图,是在用户的模式内。
●前缀为ALL的视图,为扩展的用户视图(为用户可存取的视图)。
●前缀为DBA的视图为DBA的视图(为全部用户可存取的视图)。
在数据库中ORACLE还维护了一组虚表记录当前数据库的活动,这些表称为动态性能表。动态性能表不是真正的表,许多用户不能存取,DBA可查询这些表,可以建立视图,给其它用户授予存取视图权。 五. 事务管理
1. 事务
一个事务为工作的一个逻辑单位,由一个或多个SQL语句组成。一个事务是一个原子单位,构成事务的全部SQL语句的结果可被全部提交或者全部回滚。一个事务由第一个可执行SQL语句开始,以提交或回滚结束,可以是显式的,也可是隐式的(执行DDL语句)。
在执行一个SQL语句出现错误时,该语句所有影响被回滚,好像该语句没有被执行一样,但它不会引起当前事务先前的工作的丢失。 2. ORACLE的事务管理
在ORACLE中一个事务是由一个可执行的SQL语句开始,一个可执行SQL语句产生对实例的调用。在事务开始时,被赋给一个可用回滚段,记录该事务的回滚项。一个事务以下列任何一个出现而结束。
●当COMMIT或ROLLBACK(没有SAVEPOINT子句)语句发出。
●一个DDL语句被执行。在DDL语句执行前、后都隐式地提交。
● 用户撤消对ORACLE的连接(当前事务提交)。
●用户进程异常中止(当前事务回滚)。 1) 提交事务
提交一事务,即将在事务中由SQL语句所执行的改变永久化。在提交前,ORACLE已有下列情况:
●在SGA的回滚段缓冲区已生成回滚段记录,回滚信息包含有所修改值的老值。
●在SGA的日志缓冲区已生成日志项。这些改变在事务提交前可进入磁盘。
●对SGA的数据库缓冲区已作修改,这些修改在事务真正提交之前可进入磁盘。
在事务提交之后,有下列情况:
●对于与回滚段相关的内部事务表记录提交事务,并赋给一个相应的唯一系统修改号(SCN),记录在表中。
● 在SGA的日志缓冲区中日志项由LGWR进程写入到在线日志文件, 这是构成提交事务的原子事务。
●在行上和表上的封锁被释放。
●该事务标志为完成 。
注意:对于提交事务的数据修改不必由DBWR后台进程立即写入数据文件,可继续存储在SGA的数据库缓冲区中,在最有效时将其写入数据文件。 2) 回滚事务
回滚事务的含义是撤消未提交事务中的SQL语句所作的对数据修改。ORALCE允许撤消未提交的整个事务,也允许撤消部分。
在回滚整个事务(没有引用保留点)时,有下列情况:
●在事务中所有SQL语句作的全部修改,利用相应的回滚段被撤消。
● 所有数据的事务封锁被释放。
●事务结束。
当事务回滚到一保留点(具有SAVEPOINT)时,有下列情况:
● 仅在该保留点之后执行的语句被撤消。
● 该指定的保留点仍然被保留,该保留点之后所建立的保留点被删除。
●自该保留点之后所获取的全部表封锁和行封锁被释放,但指定的保留点以前所获取的全部数据封锁继续保持。
●该事务仍可继续。 3) 保留点
保留点(savepoint)是在一事务范围内的中间标志,经常用于将一个长的事务划分为小的部分。保留点可标志长事务中的任何点,允许可回滚该点之后的工作。在应用程序中经常使用保留点;例如一过程包含几个函数,在每个函数前可建立一个保留点,如果函数失败,很容易返回到每一个函数开始的情况。在回滚到一个保留点之后,该保持点之后所获得的数据封锁被释放。 六. 数据库触发器
1. 触发器介绍
数据库触发器(database trigger)是存储在数据库中的过程,当表被修改时它隐式地被激发(执行)。在ORACLE中允许在对表发出INSERT、UPDATE或DELETE语句时隐式地执行所定义的过程,这些过程称为数据库触发器。触发器存储在数据库中,并与所相关表分别存储。触发器仅可在表上定义。在许多情况中触发器用于提供很高级的专用数据库管理系统,来补充ORACLE的标准功能。触发器一般用于:
● 自动地生成导出的列值;
● 防止无效的事务;
●实施更复杂的安全性检查
●在分布式数据库中实施跨越结点的引用完整性;
●实施复杂的事务规则;
● 提供透明事件日志;
●提供高级的审计;
●维护同步表复制;
●收集关于存取表的统计。
注意:数据库触发器与SQL*FORMS触发器之间的差别。数据库触发器是定义在表上,存储在数据库中,当对表执行INSERT、UPDATE或DELETE语句时被激发,不管是谁或哪一应用发出。而SQL*FORMS触发器是SQL*FORM应用的部分,仅当在指定SQL*FORMS应用中执行一个指定触发器点时才被激发。
触发器和说明性完整性约束都可用于约束数据的输入,但它们之间有一定区别:
说明性完整性约束是关于数据库总是为“真”的语句。一个完整性约束应用于表中已有数据和操纵表的任何语句。
而触发器约束事务不可应用于在定义触发器前已装入的数据,所以它不能保证表中全部数据服从该触发器的规则。触发器实施瞬时约束,即在数据改变时实施一约束。 2. 触发器的组成:
一个触发器有三个基本部件:触发事件或语句、触发器的限制、触发器动作。
触发事件或语句:为引起触发器激发的SQL语句,是对指定表INSERT、UPDATE或DELETE语句。 触发器限制:为一布尔表达式,当触发器激发时该条件必须为TRUE。触发器的限制是用WHEN子句来指定。 触发器的动作:为一个PL/SQL块(过程),由SQL语句和PL/SQL语句组成。当触发语句发出,触发器的限制计算得TRUE时,它被执行。在触发器动作的语句中,可使用触发器的处理的当前行的列值(新值、老值),使用形式为:
NEW.列名 引用新值
OLE.列名 引用老值
在定义触发器时可指定触发器动作执行次数:受触发语句影响每一行执行一次或是对触发语句执行一次。
对每一触发语句可有四种类型触发器:
行触发器:对受触发语句所影响的每一行,行触发器激发一次。
语句触发器:该类型触发器对触发语句执行一次,不管其受影响行数。
定义触发器可以指定触发时间,指定激发器动作的执行相对于触发语句执行之后或之前。
BEFORE触发器:该触发器执行触发器动作是在触发语句执行之前。
AFTER触发器:该触发器执行触发器动作是在触发语句执行之后。
一个触发器可处于两种不同的方式:使能触发器和使不能触发器。
使能触发器:只要当触发语句发出,触发器限制计算为TRUE,这种类型的触发器执行其触发动作。
使不能触发器:这种触发器即使其触发语句被发出,触发器限制计算为TRUE,也不执行触发器动作。
触发器的源代码存储在数据库中,在第一次执行时,触发器的源代码被编译,存储在共享池中。如果触发器从共享池中挤了,再使用时必须再重新编译。 七. 分布处理和分布式数据库
1. 简介
一个分布式数据库在用户面前为单个逻辑数据库,但实际上是由存储在多台计算机上的一组数据库组成。在几台计算机 上的数据库通过网络可同时修改和存取,每一数据库受它的局部的DBMS控制。分布式数据库中每一个数据库服务器合作地维护全局数据库的一致性。
在系统中的每一台计算机称为结点。如果一结点具有管理数据库 软件,该结点称为数据库服务器。如果一个结点为请求服务器的信息的一应用,该结点称为客户。在ORACLE客户,执行数据库应用,可存取数据信息和与用户交互。在服务器,执行ORACLE软件,处理对ORACLE数据库并发、共享数据存取。ORACLE允许上述两部分在同一台计算机上,但当客户部分和服务器部分是由网连接的不同计算机上时,更有效。
分布处理是由多台处理机分担单个任务的处理。在ORACLE数据库系统中分布处理的例子如:
客户和服务器是位于网络连接的不同计算机上。
单台计算机上有多个处理器,不同处理器分别执行客户应用。
SQL*NET是ORACLE网络接口,允许运行在网络工作站的ORACLE工具和服务器上,可存取、修改、共享和存储在其它服务器上的数据。SAQL*NET可被认为是网络通信的程序接口。SQL*NET利用通信协议和应用程序接口(API)为OARCLE提供一个分布式数据库和分布处理。
SQL*NET驱动器为在数据库服务器上运行的ORACLE进程与ORACLE工具的用户进程之间提供一个接口。
参与分布式数据库的每一服务器是分别地独立地管理数据库,好 像每一数据库不是网络化的数据库。每一个数据库独立地被管理,称为场地自治性。场地自治性有下列好处:
●系统的结点可反映公司的逻辑组织。
● 由局部数据库管理员控制局部数据,这样每一个数据库管理员责任域要小一些,可更
好管理。
●只要一个数据库和网络是可用,那么全局数据库可部分可用。不会因一个数据库的故
障而停止全部操作或引起性能瓶颈。
● 故障恢复通常在单个结点上进行。
●每个局部数据库存在一个数据字典。
●结点可独立地升级软件。
可从分布式数据库的所有结点存取模式对象,因此正像非分布的局部的DBMS,必须提供一种机制,可在局部数据库中引用一个对象。分布式DBMS必须提供一种命名模式,以致分布式数据库中一个对象可在应用中唯一标识和引用。一般彩在层次结构的每一层实施唯一性。分布式DVMS简单地扩充层次命名模型,实施在网络上唯一数据库命名。因此一个对象的全局对象名保证在分布式数据库内是唯一。
ORACLE允许在SQL语句中使用佤对象名引用分布式数据库中的模式对象(表、视图和过程)。在ORACLE中,一个模式对象的全局名由三部分组成:包含对象的模式名、对象名、数据库名、其形式如:
[email protected]
其中SCOTT为模式名,EMP为表名,@符号之后为数据库名.
一个远程查询为一查询,是从一个或多个远程表中选择信息,这些表驻留在同一个远程结点.
一个分布式查询可从两个或多个结点检索数据.一个分布式更新可修改两个或两个以上结点的数据.
一个远程事务为一个事务,包含一人或多个远程语句,它所引用的全部是在同一个远程结点上.一个分布式事务中一个事务,包含一个或多个语句修改分布式数据库的两个或多个不同结点的数据.
在分布式数据库中,事务控制必须在网络上直辖市,保证数据一致性.两阶段提交机制保证参与分布式事务的全部数据库服务器是全部提交或全部回滚事务中的语句.
ORACLE分布式数据库系统结构可由ORACLE数据库管理员为终端用户和应用提供位置透明性,利用视图、同义词、过程可提供ORACLE分布式数据库系统中的位置透明性.
ORACLE允许在SELECT(查询)、INSERT、UPDATE、DELETE、SELECT…FOR UPDATE和LOCK TABLE语句中引用远程数据。对于查询,包含有连接、聚合、子查询和SELECT …FOR UPDATE,可引用本地的、远程的表和视图。对于UPDATE、INSERT、DELETE和LOCK TABLE语句可引用本地的和远程的表。注意在引用LONG和LONG RAW列、序列、修改表和封锁表时,必须位于同一个结点。ORACLE不允许作远程DDL语句。
在单场地或分布式数据库中,所有事务都是用COMMIT或ROLLBACK语句中止。ORACLE提供两种机制实现分布式数据库中表重复的透明性:表快照提供异步的表重复;触发器实现同步的表的重复。在两种情况下,都实现了对表重复的透明性。 2. 分布式数据库全局名与数据库链
1) 分布式数据库全局名:每一个数据库有一个唯一的全局名,由两部分组成:数据库名(小于等于8字符)和网络域。全局数据库名的网络域成分必须服从标准互联网规范。域名中的层次 由符号“.”分开,域名的次序由叶至根,从左至右。
2) 数据库链:为对过程数据库定义的一路径。数据库链对分布式数据库的用户是透明的,数据库链的名字与链所指向的数据库的全局名相同。其由二部分组成:远程账号和数据库串。例建立数据库链的形式:
CREAT PUBLIC DATEBASE LINK sale。Division3。acme。com
CONNECT TO guest IDENTIFIED BY password
USING‘DB串’;
其中:sales。Divisin3。acme。com为定义的链名;guest/password 为远程数据库的用户账号和口令;DB串用于远程连接。由账号和DB串构成完全路径。如果只有一个则为部分路径。
有三种数据库链可用于决定用户对全部对象名的引用:
专用数据库链:为一指定用户建立。专用数据库链仅链的主人可使用。在SQL语句中用于指定一全局对象名或者在持有者的视图过程定义中使用。
公用数据库链:为特殊的用户组PUBLIC建立。公用数据库链可为任何用户使用,在SQL语句中用于指定一个全局对象名或对象定义。
网络数据链:由网络域服务器建立和管理,可为网络中的任何数据库的任何用户使用,可在SQL语句中指定全局对象名或对象定义中使用。注意:当前网络域服务器对ORACLE不能用,所以网络数据库链不可用。 3. 表快照
ORACLE的表快照特征允许一个主表在分布式数据库的其它结点进行复制。只允许修改主表,而复制只可读。主表达式每一个复制称为一个快照。快照异步的刷新,反映主表的一个最近事务一致状态。
一个快照可为表的完全拷贝或者为表的一个子集,由引用一个或多个主表、视图或其它快照的分布式查询所定义。包含主表的数据库称为主数据库。
快照有简单快照和复杂快照。简单快照的每行是基于单个远程表中的一行。所以定义简单快照的查询中不能有GROUB BY或CONNECT BY子句,或子查询、连接或集合操作。如果在快照定义的查询中包含有上述子句或操作,这种快照称为复杂快照。
在快照建立时,ORACLE在快照的模式中建立几种内部对象:
在快照结点,ORACLE建立一基表用于存储由快照定义的查询所检索的行,然后为该表建立一个只读的视图,并为远程主表建立一视图,该视图用于新快照。
一个快照周期地被刷新,反映它的主表的当前情况。为了刷新一快照,快照定义查询是被发出,其查询结果想在存储在快照中,代替以前的快照数据。
当快照为简单快照时,可以由快照日志来刷新,这样可加快刷新处理。快照日志是在主表数据库中的一表,与主表相关。ORACLE使用快照日志跟踪主表中已修改的行。当基于主表的简单快照刷新时,仅需要快照日志的相应行来刷新快照,这种刷新称为快速刷新。
数据库的安全性、完整性、并发控制和恢复
为了保证数据库数据的安全可靠性和正确有效,DBMS必须提供统一的数据保护功能。数据保护也为数据控制,主要包括数据库的安全性、完整性、并发控制和恢复。 一. 数据库的安全性
数据库的安全性是指保护数据库以防止不合法的使用所造成的数据泄露、更改或破坏。计算机系统都有这个问题,在数据库系统中大量数据集中存放,为许多用户共享,使安全问题更为突出。
在一般的计算机系统中,安全措施是一级一级设置的。
在DB存储这一级可采用密码技术,当物理存储设备失窃后,它起到保密作用。在数据库系统这一级中提供两种控制:用户标识和鉴定,数据存取控制。
在ORACLE多用户数据库系统中,安全机制作下列工作:
● 防止非授权的数据库存取;
● 防止非授权的对模式对象的存取;
● 控制磁盘使用;
●控制系统资源使用;
● 审计用户动作。 数据库安全可分为二类:系统安全性和数据安全性。
系统安全性是指在系统级控制数据库的存取和使用的机制,包含:
● 有效的用户名/口令的组合;
● 一个用户是否授权可连接数据库;
● 用户对象可用的磁盘空间的数量;
● 用户的资源限制;
● 数据库审计是否是有效的;
● 用户可执行哪些系统操作。 数据安全性是指在对象级控制数据库的存取和使用的机制,包含:
●哪些用户可存取一指定的模式对象及在对象上允许作哪些操作类型。
在ORACLE服务器上提供了一种任意存取控制,是一种基于特权限制信息存取的方法。用户要存取一对象必须有相应的特权授给该用户。已授权的用户可任意地可将它授权给其它用户,由于这个原因,这种安全性类型叫做任意型。 ORACLE利用下列机制管理数据库安全性:
● 数据库用户和模式;
● 特权;
●角色;
●存储设置和空间份额;
●资源限制;
●审计。 1. 数据库的存取控制
ORACLE保护信息的方法采用任意存取控制来控制全部用户对命名对象的存取。用户对对象的存取受特权控制。一种特权是存取一命名对象的许可,为一种规定格式。
ORACLE使用多种不同的机制管理数据库安全性,其中有两种机制:模式和用户。模式为模式对象的集合,模式对象如表、视图、过程和包等。第一数据库有一组模式。
每一ORACLE数据库有一组合法的用户,可存取一数据库,可运行一数据库应用和使用该用户各连接到定义该用户的数据库。当建立一数据库用户时,对该用户建立一个相应的模式,模式名与用户名相同。一旦用户连接一数据库,该用户就可存取相应模式中的全部对象,一个用户仅与同名的模式相联系,所以用户和模式是类似的。 用户的存取权利受用户安全域的设置所控制,在建立一个数据库的新用户或更改一已有用户时,安全管理员对用户安全域有下列决策:
●是由数据库系统还是由操作系统维护用户授权信息。
●设置用户的缺省表空间和临时表空间。
●列出用户可存的表空间和在表空间中可使用空间份额。
●设置用户资源限制的环境文件,该限制规定了用户可用的系统资源的总量。
●规定用户具有的特权和角色,可存取相应的对象。 每一个用户有一个安全域,它是一组特性,可决定下列内容:
●用户可用的特权和角色;
●用户可用的表空间的份额;
●用户的系统资源限制。 1) 用户鉴别:
为了防止非授权的数据库用户的使用,ORACLE提供二种确认方法
操作系统确认和相应的ORACLE数据库确认。
如果操作系统允许,ORACLE可使用操作系统所维护的信息来鉴定用户。由操作系统鉴定用户的优点是:
●用户可更方便地连接到ORACLE,不需要指定用户名和口令。
●对用户授权的控制集中在操作系统,ORACLE不需要存储和管理用户口令。然而用户名在数据库中仍然要维护。
●在数据库中的用户名项和操作系统审计跟踪相对应。 ORACLE数据库方式的用户确认:ORACLE利用存储在数据库中的信息可鉴定试图接到数据库的一用户,这种鉴别方法仅当操作系统不能用于数据库用户鉴别时才使用。当用户使用一ORACLE数据库时执行用户鉴别。每个用户在建立时有一个口令,用户口令在建立对数据库连接时使用,以防止对数据库非授权的使用。用户的口令以密码的格式存储在数据库数据字典中,用户可随时修改其口令。 2) 用户的表空间设置和定额
关于表空间的使用有几种设置选择:
●用户的缺省表空间;
●用户的临时表空间;
●数据库表空间的空间使用定额。 3) 用户资源限制和环境文件
用户可用的各种系统资源总量的限制是用户安全域的部分。利用显式地设置资源限制;安全管理员可防止用户无控制地消耗宝贵的系统资源。资源限制是由环境文件管理。一个环境文件是命名的一组赋给用户的资源限制。另外ORACLE为安全管理员在数据库级提供使能或使不能实施环境文件资源限制的选择。
ORACLE可限制几种类型的系统资源的使用,每种资源可在会话级、调用级或两者上控制。在会话级:每一次用户连接到一数据库,建立一会话。每一个会话在执行SQL语句的计算机上耗费CPU时间和内存量进行限制。对ORACLE的几种资源限制可在会话级上设置。如果会话级资源限制被超过,当前语句被中止(回滚),并返回指明会话限制已达到的信息。此时,当前事务中所有之前执行的语句不受影响,此时仅可作COMMIT、ROLLBACK或删除对数据库的连接等操作,进行其它操作都将出错。
在调用级:在SQL语句执行时,处理该语句有好几步,为了防止过多地调用系统,ORACLE在调用级可设置几种资源限制。如果调用级的资源限制被超过,语句处理被停止,该 语句被回滚,并返回一错误。然而当前事务的已执行所用语句不受影响,用户会话继续连接。 有下列资源限制:
●为了防止无控制地使用CPU时间,ORACLE可限制每次ORACLE调用的CPU时间和在一次会话期间ORACLE调用所使用的CPU的时间,以0.01秒为单位。
●为了防止过多的I/O,ORACLE可限制每次调用和每次会话的逻辑数据块读的数目。
●ORACLE在会话级还提供其它几种资源限制。 每个用户的并行会话数的限制;
会话空闲时间的限制,如果一次会话的ORACLE调用之间时间达到该空闲时间,当前事务被回滚,会话被中止,会话资源返回给系统;
每次会话可消逝时间的限制,如果一次会话期间超过可消逝时间的限制,当前事务被回滚,会话被删除,该会话的资源被释放;
每次会话的专用SGA空间量的限制。
用户环境文件:
用户环境文件是指定资源限制的命名集,可赋给ORACLE数据库的有效的用户。利用用户环境文件可容易地管理资源限制。要使用用户环境文件,首先应将数据库中的用户分类,决定在数据库中全部用户类型需要多少种用户环境文件。在建立环境文件之前,要决定每一种资源限制的值。例如一类用户通常不执行大量逻辑数据块读,那就可将LOGICAL-READS-PER-SESSION和LOGICAL-READS-PER-CALL设置相应的值。在许多情况中决定一用户的环境文件的合适资源限制的最好的方法是收集每种资源使用的历史信息。 2. 特权和角色
1) 特权:特权是执行一种特殊类型的SQL语句或存取另一用户的对象的权力。有两类特权:系统特权和对象特权。
系统特权:是执行一处特殊动作或者在对象类型上执行一种特殊动作的权利。ORACLE有60多种不同系统特权,每一种系统允许用户执行一种特殊的数据库操作或一类数据库操作.
系统特权可授权给用户或角色,一般,系统特权全管理人员和应用开发人员,终端用户不需要这些相关功能.授权给一用户的系统特权并具有该 系统特权授权给其他用户或角色.反之,可从那些被授权的用户或角色回收系统特权.
对象特权:在指定的表、视图、序列、过程、函数或包上执行特殊动作的权利。对于不同类型的对象,有不同类型的对象特权。对于有些模式对象,如聚集、索引、触发器、数据库链没有相关的对象特权,它们由系统特权控制。
对于包含在某用户名的模式中的对象,该用户对这些对象自动地具有全部对象特权,即模式的持有者对模式中的对象具有全部对象特权。这些对象的持有者可将这些对象上的任何对象特权可授权给其他用户。如果被授者包含有GRANT OPTION 授权,那么该被授者也可将其权利再授权给其他用户。 2) 角色:为相关特权的命名组,可授权给用户和角色。ORACEL利用角色更容易地进行特权管理。有下列优点:
●减少特权管理,不要显式地将同一特权组授权给几个用户,只需将这特权组授给角色,然后将角色授权给每一用户。
● 动态特权管理,如果一组特权需要改变,只需修改角色的特权,所有授给该角色的全部用户的安全域将自动地反映对角色所作的修改。
● 特权的选择可用性,授权给用户的角色可选择地使其使能(可用)或使不能(不可用)。
● 应用可知性,当一用户经一用户名执行应用时,该数据库应用可查询字典,将自动地选择使角色使能或不能。
●专门的应用安全性,角色使用可由口令保护,应用可提供正确的口令使用权角色使能,达到专用的应用安全性。因用户不知其口令,不能使角色使能。
一般,建立角色服务于两个目的:为数据库应用管理特权和为用户组管理特权。相应的角色称为应用角色和用户角色。
应用角色是授予的运行一数据库应用所需的全部特权。一个应用角色可授给其它角色或指定用户。一个应用可有几种不同角色,具有不同特权组的每一个角色在使用应用时可进行不同的数据存取。
用户角色是为具有公开特权需求的一组数据库用户而建立的。用户特权管理是受应用角色或特权授权给用户角色所控制,然后将用户角色授权给相应的用户。
数据库角色包含下列功能:
● 一个角色可授予系统特权或对象特权。
●一个角色可授权给其它角色,但不能循环授权。
● 任何角色可授权给任何数据库用户。
●授权给一用户的每一角色可以是使能的或者使不能的。一个用户的安全域仅包含当前对该用户使能的全部角色的特权。
● 一个间接授权角色(授权给另一角色的角色)对一用户可显式地使其能或使不能。
在一个数据库中,每一个角色名必须唯一。角色名与用户不同,角色不包含在任何模式中,所以建立一角色的用户被删除时不影响该角色。
ORACLE为了提供与以前版本的兼容性,预定义下列角色:CONNENT、RESOURCE、DBA、EXP-FULL-DATABASE和IMP-FULL-DATABASE。 3. 审计
审计是对选定的用户动作的监控和记录,通常用于:
●审查可疑的活动。例如:数据被非授权用户所删除,此时安全管理员可决定对该 数据库的所有连接进行审计,以及对数据库的所有表的成功地或不成功地删除进行审计。
● 监视和收集关于指定数据库活动的数据。例如:DBA可收集哪些被修改、执行了多少次逻辑的I/O等统计数据。
ORACLE支持三种审计类型:
●语句审计,对某种类型的SQL语句审计,不指定结构或对象。
● 特权审计,对执行相应动作的系统特权的使用审计。
●对象审计,对一特殊模式对象上的指定语句的审计。
ORACLE所允许的审计选择限于下列方面:
● 审计语句的成功执行、不成功执行,或者其两者。
● 对每一用户会话审计语句执行一次或者对语句每次执行审计一次。
●对全部用户或指定用户的活动的审计。
当数据库的审计是使能的,在语句执行阶段产生审计记录。审计记录包含有审计的操作、用户执行的操作、操作的日期和时间等信息。审计记录可存在数据字典表(称为审计记录)或操作系统审计记录中。数据库审计记录是在SYS模式的AUD$表中。
二. 数据完整性
它是指数据的正确性和相容性。数据的完整性是为了防止数据库存在不符合主义的数据,防止错误信息输入和输出,即数据要遵守由DBA或应用开发者所决定的一组预定义的规则。ORACLE应用于关系数据库的表的数据完整性有下列类型:
● 在插入或修改表的行时允许不允许包含有空值的列,称为空与非空规则。
● 唯一列值规则,允许插入或修改的表行在该列上的值唯一。
●引用完整性规则,同关系模型定义
● 用户对定义的规则,为复杂性完整性检查。
ORACLE允许定义和实施上述每一种类型的数据完整性规则,这些规则可用完整性约束和数据库触发器定义。
完整性约束,是对表的列定义一规则的说明性方法。
数据库触发器,是使用非说明方法实施完整性规则,利用数据库触发器(存储的数据库过程)可定义和实施任何类型的完整性规则。
1. 完整性约束
ORACLE利用完整性约束机制防止无效的数据进入数据库的基表,如果任何DML执行结果破坏完整性约束,该语句被回滚并返回一上个错误。ORACLE实现的完整性约束完全遵守ANSI X3。135-1989和ISO9075-1989标准。
利用完整性约束实施数据完整性规则有下列优点:
●定义或更改表时,不需要程序设计,便很容易地编写程序并可消除程序性错误,其功能是由ORACLE控制。所以说明性完整性约束优于应用代码和数据库触发器。
● 对表所定义的完整性约束是存储在数据字典中,所以由任何应用进入的数据都必须遵守与表相关联的完整性约束。
●具有最大的开发能力。当由完整性约束所实施的事务规则改变时,管理员只需改变完整性约束的定义,所有应用自动地遵守所修改的约束。
●由于完整性约束存储在数据字典中,数据库应用可利用这些信息,在SQL语句执行之前或由ORACLE检查之前,就可立即反馈信息。
●由于完整性约束说明的语义是清楚地定义,对于每一指定说明规则可实现性能优化。
●由于完整性约束可临时地使不能,以致在装入大量数据时可避免约束检索的开销。当数据库装入完成时,完整性约束可容易地使其能,任何破坏完整性约束的任何新行在例外表中列出。
ORACLE的DBA和应用开始者对列的值输入可使用的完整性约束有下列类型:
● NOT NULL约束:如果在表的一列的值不允许为空,则需在该列指定NOT NULL约束。
●UNIQUE码约束:在表指定的列或组列上不允许两行是具有重复值时,则需要该列或组列上指定UNIQUE码完整性约束。在UNIQUE码约束定义中的列或组列称为唯一码。所有唯一完整性约束是用索引方法实施。
●PRIMARY KEY约束:在数据库中每一个表可有一个PRIMARY KEY约束。包含在PRIMARY KEY完整性约束的列或组列称为主码,每个表可有一个主码。ORACLE使用索引实施PRIMARY KEY约束。
● FOREIGN KEY约束(可称引用约束):在关系数据库中表可通过公共列相关联,该 规则控制必须维护的列之间的关系。包含在引用完整性约束定义的列或组列称为外来码。由外来码所引用的表中的唯一码或方码,称为引用码。包含有外来码的表称为子表或从属表。由子表的外来码所引用的表称为双亲表或引用表。如果对表的每一行,其外来码的值必须与主码中一值相匹配,则需指定引用完整性约束。
● CHECK约束:表的每行对一指定的条件必须是TRUE或未知,则需在一列或列组上指定CHECK完整性约束。如果在发出一个DML语句时,CHECK约束的条件计算得FALSE时,该语句被回滚。 2. 数据库触发器
ORACLE允许定义过程,当对相关的表作INSERT、UPDATE或DELETE语句时,这些过程被隐式地执行。这些过程称为数据库触发器。触发器类似于存储的过程,可包含SQL语句和PL/SQL语句,可调用其它的存储过程。过程与触发器差别在于调用方法:过程由用户或应用显式执行;而触发器是为一激发语句 (INSERT、UPDATE、DELETE)发出进由ORACLE隐式地触发。一个数据库应用可隐式地触发存储在数据库中多个触发器。
在许多情况中触发器补充ORACLE的标准功能,提供高度专用的数据库管理系统。一般触发器用于:
●自动地生成导出列值。
●防止无效事务。
● 实施复杂的安全审核。
●在分布式数据库中实施跨结点的引用完整性。
● 实施复杂的事务规则。
●提供透明的事件记录。
● 提供高级的审计。
●维护同步的表副本。
● 收集表存取的统计信息。
注意:在ORACLE环境中利用ORACLE工具SQL*FORMS也可定义、存储和执行触发器,它作为由SQL*FORMS所开发有应用的一部分,它与在表上定义的数据库触发器有差别。数据库触发器在表上定义,存储在相关的数据库中,在对该表发出IMSERT、UPDATE、DELETE语句时将引起数据库触发器的执行,不管是哪些用户或应用发出这些语句。而SQL*FORMS的触发器是SQL*FORMS应用的组成,仅当在指定SQL*FORMS应用中执行指定触发器点时才激发该触发器。
一个触发器由三部分组成:触发事件或语句、触发限制和触发器动作。触发事件或语句是指引起激发触发器的SQL语句,可为对一指定表的INSERT、UNPDATE或DELETE语句。触发限制是指定一个布尔表达式,当触发器激以时该布尔表达式是必须为真。触发器作为过程,是PL/SQL块,当触发语句发出、触发限制计算为真时该过程被执行。 3. 并发控制
数据库是一个共享资源,可为多个应用程序所共享。这些程序可串行运行,但在许多情况下,由于应用程序涉及的数据量可能很大,常常会涉及输入/输出的交换。为了有效地利用数据库资源,可能多个程序或一个程序的多个进程并行地运行,这就是数据库的并行操作。在多用户数据库环境中,多个用户程序可并行地存取数据库,如果不对并发操作进行控制,会存取不正确的数据,或破坏数据库数据的一致性。
例:在飞机票售票中,有两个订票员(T1,T2)对某航线(A)的机动性票作事务处理,操作过程如图所示:
数据库中的A 1 1 1 1 0 0
T1 READ A A:=A-1 WRITE A
T2 READ A A:=A-1 WRITE A
T1工作区中的A 1 1 0 0 0 0
T2工作区中的A 1 1 0 0 0
首先T1读A,接着T2也读A。然后T1将其工作区中的A减1,T2也采取同样动作,它们都得0值,最后分别将0值写回数据库。在这过程中没有任何非法操作,但实际上多出一张机票。这种情况称为数据库的不一致性,这种不一致性是由于并行操作而产生的。所谓不一致,实际上是由于处理程序工作区中的数据与数据库中的数据不一致所造成的。如果处理程序不对数据库中的数据进行修改,则决不会造成任何不一致。另一方面,如果没有并行操作发生,则这种临时的不一致也不会造成什么问题。数据不一致总是是由两个因素造成:一是对数据的修改,二是并行操作的发生。因此为了保持数据库的一致性,必须对并行操作进行控制。最常用的措施是对数据进行封锁。 1) 数据库不一致的类型
●不一致性
在一事务期间,其它提交的或未提交事务的修改是显然的,以致由查询所返回的数据集不与任何点相一致。
●不可重复读
在一个事务范围内,两个相同查询将返回不同数据,由于查询注意到其它提交事务的修改而引起。
● 读脏数据
如果事务T1将一值(A)修改,然后事务T2读该值,在这之后T1由于某种原因撤销对该值的修改,这样造成T2读取的值是脏的。
● 丢失更改
在一事务中一修改重写另一事务的修改,如上述飞机票售票例子。
● 破坏性的DDL操作
在一用户修改一表的数据时,另一用户同时更改或删除该表。 2) 封锁
在多用户数据库中一般采用某些数据封锁来解决并发操作中的数据一致性和完整性问题。封锁是防止存取同一资源的用户之间破坏性的干扰的机制,该干扰是指不正确地修改数据或不正确地更改数据结构。
在多用户数据库中使用两种封锁:排它(专用)封锁和共享封锁。排它封锁禁止相关资源的共享,如果一事务以排它方式封锁一资源,仅仅该事务可更改该资源,直至释放排它封锁。共享封锁允许相关资源可以共享,几个用户可同时读同一数据,几个事务可在同一资源上获取共享封锁。共享封锁比排它封锁具有更高的数据并行性。
在多用户系统中使用封锁后会出现死锁,引起一些事务不能继续工作。当两个或多个用户彼此等待所封锁数据时可发生死锁。 3) ORACLE多种一致性模型。
ORACLE利用事务和封锁机制提供数据并发存取和数据完整性。在一事务内由语句获取的全部封锁在事务期间被保持,防止其它并行事务的破坏性干扰。一个事务的SQL语句所作的修改在它提交之后所启动的事务中才是可见的。在一事务中由语句所获取的全部封锁在该事务提交或回滚时被释放。
ORACLE在两个不同级上提供读一致性:语句级读一致性和事务级一致性。ORCLE总是实施语句级读一致性,保证单个查询所返回的数据与该查询开始时刻相一致。所以一个查询从不会看到在查询执行过程中提交的其它事务所作的任何修改。为了实现语句级读一致性,在查询进入执行阶段时,在注视SCN的时候为止所提交的数据是有效的,而在语句执行开始之后其它事务提交的任何修改,查询将是看不到的。
ORACLE允许选择实施事务级读一致性,它保证在同一事务内所有查询的数据 4) 封锁机制
ORACLE自动地使用不同封锁类型来控制数据的并行存取,防止用户之间的破坏性干扰。ORACLE为一事务自动地封锁一资源以防止其它事务对同一资源的排它封锁。在某种事件出现或事务不再需要该资源时自动地释放。
ORACLE将封锁分为下列类:
●数据封锁:数据封锁保护表数据,在多个用户并行存取数据时保证数据的完整性。数据封锁防止相冲突的DML和DDL操作的破坏性干扰。DML操作可在两个级获取数据封锁:指定行封锁和整个表封锁,在防止冲突的DDL操作时也需表封锁。当行要被修改时,事务在该行获取排它数据封锁。表封锁可以有下列方式:行共享、行排它、共享封锁、共享行排它和排它封锁。
●DDL封锁(字典封锁)
DDL封锁保护模式对象(如表)的定义,DDL操作将影响对象,一个DDL语句隐式地提交一个事务。当任何DDL事务需要时由ORACLE自动获取字典封锁,用户不能显式地请求DDL封锁。在DDL操作期间,被修改或引用的模式对象被封锁。
● 内部封锁:保护内部数据库和内存结构,这些结构对用户是不可见的。
5) 手工的数据封锁
下列情况允许使用选择代替ORACLE缺省的封锁机制:
● 应用需要事务级读一致或可重复读。
●应用需要一事务对一资源可排它存取,为了继续它的语句,具有对资源排它存取的事务不必等待其它事务完成。
ORACLE自动封锁可在二级被替代:事务级各系统级。
●事务级:包含下列SQL语句的事务替代ORACLE缺省封锁:LOCK TABLE命令、SELECT…FOR UPDATE命令、具有READ ONLY选项的SET TRANSACTIN命令。由这些语句所获得的封锁在事务提交或回滚后所释放。
●系统级:通过调整初始化参数SERIALIZABLE和REO-LOCKING,实例可用非缺省封锁启动。该两参数据的缺省值为:
SERIALIZABLE=FALSE
ORW-LOCKING=ALWAYS 4. 数据库后备和恢复
当我们使用一个数据库时,总希望数据库的内容是可靠的、正确的,但由于计算机系统的故障(硬件故障、软件故障、网络故障、进程故障和系统故障)影响数据库系统的操作,影响数据库中数据的正确性,甚至破坏数据库,使数据库中全部或部分数据丢失。因此当发生上述故障后,希望能重新建立一个完整的数据库,该处理称为数据库恢复。恢复子系统是数据库管理系统的一个重要组成部分。恢复处理随所发生的故障类型所影响的结构而变化。 1) 恢复数据库所使用的结构
ORACLE数据库使用几种结构对可能故障来保护数据:数据库后备、日志、回滚段和控制文件。
数据库后备是由构成ORACLE数据库的物理文件的操作系统后备所组成。当介质故障时进行数据库恢复,利用后备文件恢复毁坏的数据文件或控制文件。
日志,每一个ORACLE数据库实例都提供,记录数据库中所作的全部修改。一个实例的日志至少由两个日志文件组成,当实例故障或介质故障时进行数据库部分恢复,利用数据库日志中的改变应用于数据文件,修改数据库数据到故障出现的时刻。数据库日志由两部分组成:在线日志和归档日志。
每一个运行的ORACLE数据库实例相应地有一个在线日志,它与ORACLE后台进程LGWR一起工作,立即记录该实例所作的全部修改。在线日志由两个或多个预期分配的文件组成,以循环方式使用。
归档日志是可选择的,一个ORACLE数据库实例一旦在线日志填满后,可形成在线日志的归档文件。归档的在线日志文件被唯一标识并合成归档日志。
回滚段用于存储正在进行的事务(为未提交的事务)所修改值的老值,该信息在数据库恢复过程中用于撤消任何非提交的修改。
控制文件,一般用于存储数据库的物理结构的状态。控制文件中某些状态信息在实例恢复和介质恢复期间用于引导ORACLE。 2) 在线日志
一个ORACLE数据库的每一实例有一个相关联的在线日志。一个在线日志由多个在线日志文件组成。在线日志文件填入日志项,日志项记录的数据用于重构对数据库所作的全部修改。后台进程LGWR以循环方式写入在线日志文件。当当前的在线日志文件写满后,LGWR写入到下一可用在线日志文件当最后一个可用的在线日志文件的检查点已完成时即可使用。如果归档不实施,一个已填满的在线日志文件一当包含该在线日志文件的检查点完成,该文件已被归档后即可使用。在任何时候,仅有一个在线日志文件被写入存储日志项,它被称为活动的或当前在线日志文件,其它的在线日志文件为不活动的在线日志文件。
ORCLE结束写入一在线日志文件并开始写入到另一个在线日志文件的点称为日志开关。日志开关在当前在线日志文件完全填满,必须继续写入到下一个在线日志文件时总出现,也可由DBA强制日志开关。每一日志开关出现时,每一在线日志文件赋给一个新的日志序列号。如果在线日志文件被归档,在归档日志文件中包含有它的日志序列号。
ORACLE后台进程DBWR(数据库写)将SGA中所有被修改的数据库缓冲区(包含提交和未提交的)写入到数据文件,这样的事件称为出现一个检查点。因下列原因实现检查点:
● 检查点确保将内存中经常改变的数据段块每隔一定时间写入到数据文件。由于DBWR使用最近最少使用算法,经常修改的数据段块从不会作为最近最少使用块,如果检查点不出现,它从不会写入磁盘。
●由于直至检查点时所有的数据库修改已记录到数据文件,先于检查点的日志项在实例恢复时不再需要应用于数据文件,所以检查点可加快实例恢复。
虽然检查点有一些开销,但ORACLE既不停止活动又不影响当前事务。由于DBWR不断地将数据库缓冲区写入到磁盘,所以一个检查点一次不必写许多数据块。一个检查点保证自前一个检查点以来的全部修改数据块写入到磁盘。检查点不管填满的在线日志文件是否正在归档,它总是出现。如果实施归档,在LGWR重用在线日志文件之前,检查点必须完成并且所填满的在线日志文件必须被归档。
检查点可对数据库的全部数据文件出现(称为数据库检查点),也可对指定的数据文件出现。下面说明一下什么时候出现检查点及出现什么情况:
●在每一个日志开关处自动地出现一数据库检查点。如果前一个数据库检查点正在处理,由日志开关实施的检查点优于当前检查点。
● 初始化参数据LOG-CHECKPOINT-INTERVAL设置所实施的数据库检查点,当预定的日志块数被填满后(自最后一个数据库检查点以来),实施一数据库检查点。另一个参数LOG-CHECKPOINT-TIMEOUT可设置自上一个数据库检查点开始之后指定秒数后实施一数据库检查点。这种选择对使用非常大的日志文件时有用,它在日志开头之间增加检查点。由初始化参数所启动的数据库检查点只有在前一个检查点完成后才能启动。
●当一在线表空间开始后备时,仅对构成该空间的数据文件实施一检查点,该检查点压倒仍在进行中的任何检查点。
● 当DBA使一表空间离线时,仅对构成该表空间的在线文件实施一检查点。
●当DBA以正常或立即方式关闭一实例时,ORACLE在实例关闭之前实施一数据库检查点,该检查点压倒任何运行检查点。
● DBA可要求实施一数据库检查点,该检查点压倒任何运行检查点。 检查点机制:当检查点出现时,检查点后台进程记住写入在线文件的下一日志行的位置,并通知数据库写后台进程将SGA中修改的数据库缓冲区写入到磁盘上的数据文件。然后由CKPT修改全部控制文件和数据文件的标头,反映该最后检查点。当检查点不发生,DBWR当需要时仅将最近最少使用的数据库缓冲区写入磁盘,为新数据准备缓冲区。
镜象在线日志文件:为了安全将实例的在线日志文件镜象到它的在线日志文件ORACLE提供镜象功能。当具有镜象在线日志文件时,LGWR同时将同一日志信息写入到多个同样的在线日志文件。日志文件分成组,每个组中的日志文件称为成员,每个组中的全部成员同时活动,由LGWR赋给相同的日志序列号。如果使用镜象在线日志,则可建立在线日志文件组,在组中的每一成员要求是同一大小。
镜象在线日志的机制:LGWR总是寻找组的全部成员,对一组的全部成员并行地写,然后转换到下一组的全部成员,并行地写。
每个数据库实例有自己的在线日志组,这些在线日志组可以是镜象的或不是,称为实例的在线日志线索。在典型配置中,一个数据库实例存取一个ORACLE数据库,于是仅一个线索存在。然而在运行ORACLE并行服务器中,两个或多个实例并行地存取单个数据库,在这种情况下,每个实例有自己的线索。 3) 归档日志
ORACLE要将填满的在线日志文件组归档时,则要建立归档日志,或称离线日志。其对数据库后备和恢复有下列用处:
● 数据库后备以及在线和归档日志文件,在操作系统或磁盘故障中可保证全部提交的事务可被恢复。
●在数据库打开时和正常系统使用下,如果归档日志是永久保持,在线后备可以进行和使用。
如果用户数据库要求在任何磁盘故障的事件中不丢失任何数据,那么归档日志必须要存在。归档已填满的在线日志文件可能需要DBA执行额外的管理操作。
归档机制:决定于归档设置,归档已填满的在线日志组的机制可由ORACLE后台进程ARCH自动归档或由用户进程发出语句手工地归档。当日志组变为不活动、日志开关指向下一组已完成时,ARCH可归档一组,可存取该组的任何或全部成员,完成归档组。在线日志文件归档之后才可为LGWR重用。当使用归档时,必须指定归档目标指向一存储设备,它不同于个有数据文件、在线日志文件和控制文件的设备,理想的是将归档日志文件永久地移到离线存储设备、如磁带。
数据库可运行在两种不同方式下:NOARCHIVELOG方式或ARCHIVELOG方式。数据库在NOARCHIVELOG方式下使用时,不能进行在线日志的归档。在该数据库控制文件指明填满的组不需要归档,所以一当填满的组成为活动,在日志开关的检查点完成,该组即可被LGWR重用。在该方式下仅能保护数据库实例故障,不能保护介质(磁盘)故障。利用存储在在线日志中的信息,可实现实例故障恢复。
如果数据库在ARCHIVELOG方式下,可实施在线日志的归档。在控制文件中指明填满的日志文件组在归档之前不能重用。一旦组成为不活动,执行归档的进程立即可使用该组。
在实例起动时,通过参数LOG-ARCHIVE-START设置,可启动ARCH进程,否则ARCH进程在实例启动时不能被启动。然而DBA在凭借时候可交互地启动或停止自动归档。 一旦在线日志文件组变为不活动时,ARCH进程自动对它归档。
如果数据库在ARCHIVELOG方式下运行,DBA可手工归档填满的不活动的日志文件组,不管自动归档是可以还是不可以。 4) 数据库后备
不管为ORACLE数据库设计成什么样的后备或恢复模式,数据库数据文件、日志文件和控制文件的操作系统后备是绝对需要的,它是保护介质故障的策略部分。操作系统后备有完全后备和部分后备
●完全后备:一个完全后备将构成ORACLE数据库的全部数据库文件、在线日志文件和控制文件的一个操作系统后备。一个完全后备在数据库正常关闭之后进行,不能在实例故障后进行。在此时,所有构成数据库的全部文件是关闭的,并与当前点相一致。在数据库打开时不能进行完全后备。由完全后备得到的数据文件在任何类型的介质恢复模式中是有用的。
● 部分后备
部分后备为除完全后备外的任何操作系统后备,可在数据库打开或关闭下进行。如单个表空间中全部数据文件后备、单个数据文件后备和控制文件后备。部分后备仅对在ARCHIVELOG方式下运行数据库有用,因为存在的归档日志,数据文件可由部分后备恢复。在恢复过程中与数据库其它部分一致。 5) 数据库恢复
●实例故障的恢复
当实例意外地(如掉电、后台进程故障等)或预料地(发出SHUTDOUM ABORT语句)中止时出现实例故障,此时需要实例恢复。实例恢复将数据库恢复一故障之前的事务一致状态。如果在在线后备发现实例故障,则需介质恢复。在其它情况ORACLE在下次数据库起动时(对新实例装配和打开),自动地执行实例恢复。如果需要,从装配状态变为打开状态,自动地激发实例恢复,由下列处理:
(1) 为了解恢复数据文件中没有记录的数据,进行向前滚。该数据记录在在线日志,包括对回滚段的内容恢复。
(2) 回滚未提交的事务,按步1重新生成回滚段所指定的操作。
(3) 释放在故障时正在处理事务所持有的资源。
(4) 解决在故障时正经历一阶段提交的任何悬而未决的分布事务。
●介质故障的恢复
介质故障是当一个文件、一个文件的部分或一磁盘不能读或不能写时出现的故障。介质故障的恢复有两种形式,决定于数据库运行的归档方式。
●如果数据库是可运行的,以致它的在线日志仅可重用但不能归档,此时介质恢复为使用最新的完全后备的简单恢复。在完全后备执行的工作必须手工地重作。
●如果数据库可运行,其在线日志是被归档的,该介质故障的恢复是一个实际恢复过程,重构受损的数据库恢复到介质故障前的一个指定事务一致状态。
不管哪种形式,介质故障的恢复总是将整个数据库恢复到故障之前的一个事务一致状态。如果数据库是在ARCHIVELOG方式运行,可有不同类型的介质恢复:完全介质恢复和不完全介质恢复。
完全介质恢复可恢复全部丢失的修改。仅当所有必要的日志可用时才可能。有不同类型的完全介质恢复可使用,其决定于毁坏文件和数据库的可用性。例:
● 关闭数据库的恢复。当数据库可被装配却是关闭的,完全不能正常使用,此时可进行全部的或单个毁坏数据文件的完全介质恢复。
●打开数据库的离线表空间的恢复。当数据库是打开的,完全介质恢复可以处理。未损的数据库表空间是在线的可以使用,而受损耗捕空间是离线的,其所有数据文件作为恢复的单位。
● 打开数据库的离线表间的单个数据文件的恢复。当数据库是打开的,完全介质恢复可以处理。未损的数据库表空间是在线的可以使用,而所损的表空间是离线的,该表空间的指定所损的数据文件可被恢复。
●使用后备的控制文件的完全介质恢复。当控制文件所有拷贝由于磁盘故障而受损时,可进行介质恢复而不丢失数据。
不完全介质恢复是在完全介质恢复不可能或不要求时进行的介质恢复。重构受损的数据库,使其恢复介质故障前或用户出错之前的一个事务一致性状态。不完全介质恢复有不同类型的使用,决定于需要不完全介质恢复的情况,有下列类型:基于撤消、基于时间和基于修改的不完全恢复。
基于撤消恢复:在某种情况,不完全介质恢复必须被控制,DBA可撤消在指定点的操作。基于撤消的恢复地在一个或多个日志组(在线的或归档的)已被介质故障所破坏,不能用于恢复过程时使用,所以介质恢复必须控制,以致在使用最近的、未损的日志组于数据文件后中止恢复操作。
基于时间和基于修改的恢复:如果DBA希望恢复到过去的某个指定点,不完全介质恢复地理想的。可在下列情况下使用:
●当用户意外地删除一表,并注意到错误提交的估计时间,DBA可立即关闭数据库,恢复它到用户错误之前时刻。
●由于系统故障,一个在线日志文件的部分被破坏,所以活动的日志文件突然不可使用,实例被中止,此时需要介质恢复。在恢复中可使用当前在线日志文件的未损部分,DBA利用基于时间的恢复,一旦有将效的在线日志已应用于数据文件后停止恢复过程。
在这两种情况下,不完全介质恢复的终点可由时间点或系统修改号(SCN)来指定。
Pro * C 的使用
一. Pro*C 程序概述:
1.什么是Pro*C程序
在ORACLE数据库管理和系统中, 有三种访问数据库的方法;
(1) 用SQL*Plus, 它有SQL命令以交互的应用程序访问数据库;
(2) 用第四代语言应用开发工具开发的应用程序访问数据库,这些工具有SQL*Froms,QL*Reportwriter,SQL*Menu等;
(3) 利用在第三代语言内嵌入的SQL语言或ORACLE库函数调用来访问。
Pro*C就属于第三种开发工具之一, 它把过程化语言C和非过程化语言SQL最完善地结合起来, 具有完备的过程处理能力,又能完成任何数据库的处理品任务,使用户可以通过编程完成各种类型的报表。在Pro*C程序中可以嵌入SQL语言, 利用这些SQL语言可以完成动态地建立、修改和删除数据库中的表,也可以查询、插入、修改和删除数据库表中的行, 还可以实现事务的提交和回滚。
在Pro*C程序中还可以嵌入PL/SQL块, 以改进应用程序的性能, 特别是在网络环境下,可以减少网络传输和处理的总开销。
2.Pro*C的程序结构图
通俗来说,Pro*C程序实际是内嵌有SQL语句或PL/SQL块的C程序, 因此它的组成很类似C程序。 但因为它内嵌有SQL语句或PL/SQL块, 所以它还含有与之不同的成份。为了让大家对Pro*C有个感性的认识, 特将二者差别比较如下:
C的全程变量说明
C源程序 函数1:同函数K。
函数2:同函数K。
C的局部变量说明
函数K
可执行语句
应用程序首部 C的外部变量说明
外部说明段(ORACLE变量说明)
通讯区说明 Pro*C源程序 函数1:同函数K。
函数2:同函数K。
C局部变量说明
程序体 内部说明部分 内部说明段
通讯区说明
函数K C的可执行语句
可执行语句 SQL的可执行语句
或PL/SQL块 二. Pro*C程序的组成结构 每一个Pro*C程序都包括两部分:(1)应用程序首部;(2)应用程序体
应用程序首部定义了ORACLE数据库的有关变量, 为在C语言中操纵ORACLE数据库做好了准备。应用程序体基本上由Pro*C的SQL语句调用组成。主要指查询SELECT、INSERT、UPDATE、DELETE等语句。
应用程序的组成结构如图所示:
EXEC SQL BEGIN DECLARE SECTION
(SQL变量的定义)
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLLA;EXEC SQL CONNECT:< 用户名>
IDENTIFIED BY: < 口令 >
SQL 语句及游标的使用 1. 应用程序首部
应用程序的首部就是Pro*C的开始部分。它包括以下三部分:
● C变量描述部分;
●SQL变量描述部分(DECLARE部分);
●SQL通信区。 (1) .DECLARE部分(描述部分)
描述部分说明程序的SQL变量, 定义部分以EXEC SQL BEGIN DECLARE SECTION ;开始和以 EXEC SQL END DECLARE SECTION ;结束的。它可以出现在程序的主部,也可出现在局部
SQL变量的说明和使用
在说明段能为SQL变量指定的数据类型如表所示:
数据类型 描述
CHAR
CHAR(n)
INT
SHORT
LONG
FLOAT
DOUBLE
VARCHAR 单字符
n个字符数组
整数
短整数
单精度浮点数
双精度浮点数
变长字符串
这些数据类型实际上就是C语言的数据类型, 其中VARCHAR中视为C数据类型的扩充。这在以后会谈到。
SQL变量的使用应注意以下几点:
必须在描述部分明确定义
必须使用与其定义相同的大小写格式
在SQL语句中使用时,必须在其之前加一个“:”(冒号),但在C语句中引用时不需加冒号。
不能是SQL命令中的保留字。
可以带指示变量。
例如:EXEC SQL BEGIN DECLARE SECTIONS;
VARCHAR programe[30];
Int porgsal, pempno;
EXEC SQL END DECLARE SECTION;
EXEC SQL SELECT ENAME , SAL
INTO: programe, : progsal
FROM EMP
WHERE EMPNO = : pempno;
(2). 指示器变量的说明和引用
指示变量实际上也是一类SQL变量,它被用来管理与其相关联的宿主变量(即在SQL语句中充 当输入或输出的变量)。每一个宿主变量都可定义一个指示器变量,主要用于处理空值(NULL)
指示器变量的说明基本同一般SQL变量一样, 但必须定义成2字节的整型,如SHORT、INT。在SQL语句中引用时, 其前也应加“:”(冒号),而且必须附在其相关联的宿主变量之后,在C语句中,可独立使用。当指示器变量为-1时,表示空值。例如:
EXEC SQL BEGIN DECLARE SECTION ;
INT dept- number;
SHORT ind – num;
CHAR emp –name;
EXEC SQL END DECLARE SECTION ;
Scanf(“90d %s”, & dept- number , dept – name );
If (dept – number ==0)
Ind – num = -1;
Else
Ind – num = 0;
EXEC SQL INSERT INTO DEPT (DEPTNO, DNAME)
VALUES(:dept – number : ind- num , :dept – name);
其中ind – num是dept – number 的指示器变量。当输入的dept – number 值是0时, 则向DEPT 表的DEPTNO列插入空值。
(3).指针SQL变量的说明和使用
指针SQL变量在引用前也必须在DECLARE 部分先说明。其说明格式同C语言。在SQL语句中引用时,指针名字前要加前缀“:”(冒号)而不加“*”(星号)。在C语句中用法如同C语言的指针变量。
(4).数组SQL变更的说明和引用
在SQL语句中引用数组时,只需写数组名(名字前加冒号), 不需写下标,在C语句中用法如同C语言的数组变量。
使用数组可大大降低网络传输开销。如要向一表插入100行数据,如果没有数组,就要重复100次, 而引用后,只须执行一次insert语句、便可一次性插入。例如:
EXEC SQL BEGIN DECLARE SECTION;
Int emp_number[100];
Char emp_name[100][15];
Float salary[100],commission[100];
Int dept_number;
EXEC SQL END DECLARE SECTION;
….
EXEC SQL SELECT EMPNO,ENAME,SAL,COMM
INTO :emp_number,:emp_name,:salary,:commission
FROM EMP
WHERE DEPTNO=:dept_number;
在使用数组时,应注意以下几点;
不支持指针数组
只支持一维数组, 而 emp-name [100][15]视为一维字符串
数组最大维数为32767
在一条SQL语句中引用多个数组时,这些数组维数应相同
在VALUES , SET, INTO 或WHERE子名中, 不允许把简单SQL变量与数组SQL变量混用
不能在DELARE部分初始化数组
例如:下面的引用是非法的
EXEC SQL BEGIN DECLARE SECTION;
Int dept – num [3] = {10,20,30};
EXEC SQL END DECLARE SECTION ;
EXEC SQL SELECT EMPNO, ENAME , SAL
INTO : emp – num [ i ], : emp – name [ i ], : salarg [ i ]
FROM EMP
(5) 伪类型VARCHAR的说明和引用
VARCHAR变量在引用之前也必须在说明段说明, 说明时必须指出串的最大
长度,如:
EXEC SQL BEGIN DECLARE SECTION;
Int book – number;
VARCHAR book – name [ 50 ];
EXEC SQL END DECLARE SECTION ;
在预编绎时, book – name 被翻译成C语言中的一个结构变量;
Struct { unsigned short len ;
Unsigned chart arr [ 20 ] ;
} boo – name
由此看出, VARCHAR变量实际上是含长度成员和数组成员的结构变量。在SQL语句中引用时,应引用以冒号为前缀的结构名, 而不加下标,在C语句 中引用结构成员。
VARCHAR变量在作输出变量时,由ORACLE自动设置, 在作为输入变量时,程序应先把字符串存入数组成员中, 其长度存入长度成员中,然后再在SQL语句中引用。例如:
Main( )
{ .......
scanf(“90s, 90d’, book – name .arr, & book – number );
book – name .len = strlen (book – name .arr);
EXEC SQL UPDATE BOOK
SET BNAME = : book – name ;
BDESC = : book – number ;
}
SQL通信区
SQL 通信区是用下列语句描述的:
EXEC SQL INCLUDE SQLCA;
此部分提供了用户运行程序的成败记录和错误处理。 SQLCA的组成
SQLCA是一个结构类型的变量,它是ORACLE 和应用程序的一个接口。在执行 Pro*C程序时, ORACLE 把每一个嵌入SQL语句执行的状态信息存入SQLCA中, 根据这些信息,可判断SQL语句的执行是否成功,处理的行数,错误信息等,其组成如表所示:
Struct sqlca
{ char sqlcaid [ 8 ] ; ----?标识通讯区
long sqlabc; ---? 通讯区的长度
long sqlcode; ---?保留最近执行的SQL语句的状态码
struct { unsigned short sqlerrml; -----?信息文本长度
}sqlerrm;
char sqlerrp [ 8 ];
long sqlerrd [ 6 ];
char sqlwarn [ 8 ];
char sqlext [ 8 ];
}
struct sqlca sqlca;
其中, sqlcode在程序中最常用到,它保留了最近执行的SQL语句的状态码。程序员根据这些状态码做出相应的处理。这些状态码值如下:
0: 表示该SQL语句被正确执行,没有发生错误和例外。
>0:ORACLE执行了该语句,但遇到一个例外(如没找到任何数据)。
<0:表示由于数据库、系统、网络或应用程序的错误,ORACLE未执行该SQL语句。
当出现此类错误时,当前事务一般应回滚。 2.应用程序体
在Pro*C程序中, 能把SQL语句和C语句自由地混合书写,并能在SQL语句中使用SQL变量,嵌入式SQL语句的书写文法是:
以关键字EXEC SQL开始
以C语言的语句终结符(分号)终结
SQL语句的作用主要用于同数据库打交道。C语言程序用于控制,输入,输出和数据处理等。
连接到ORACLE数据库
在对数据库存取之前,必须先把程序与ORACLE数据库连接起来。即登录到ORACLE上。所连接命令应该是应用程序的第一个可执行命令。连接命令格式如下:
EXEC SQL CONNECT:< 用户名 > IDENTIFIED BY : < 口令 >
或EXEC SQL CONNECT: < 用户名 > / < 口令 >
在使用上述两种格式进行登入时, 应当首先在说明段定义包含用户名和口令的
SQL 变量,并在执行CONNECT之前设置它们,否则会造成登录失败。例如:
EXEC SQL BEGIN DECLARE SECTION ;
VARCHAR usename [20];
VARCHAR password[20];
EXEC SQL END DECLARE
..........
strcpy ( usename.arr, “CSOTT’);
usename.len = strlen (username.arr);
strcpy (password.arr , “TIGER’);
password .len = strlen( password .arr);
EXEC SQL WHENEVER SQLERROR GOTO SQLERR;
EXEC SQL CONNECT :username INDNTIFIED BY : password;
注意: 不能把用户名和口令直接编写到CONNECT语句中,或者把用引号(’)括起来的字母串在CONNECT 语句中, 如下面的语句是无效的。
EXEC SQL CONNECT SCOTT INENTIFIED BY TIGER;
EXEC SQL CONNECT ‘SCOTT’ IDENTIFIED BY ‘TIGER’;
(2). 插入、更新和删除
在讲述SQL语言时已详细讲过, 这里就不举例说明了。
(3). 数据库查询及游标的使用
在PRO*C中, 查询可分为两种类型:
返回单行或定行数的查询;
返回多行的查询.此种查询要求使用游标来控制每一行或每一组(主变量用数组).
返回单行或定行数的查询
在PRO*C中的查询SQL SELECT语句由以下几个子句组成:
SELECT
INTO
FROM
WHERE
CONNECT BY
UNION
INTERSECT
MINUS
GROUP BY
HAVING
ORDER BY
其中WHERE子句中的查询条件可以是一个属性或多个属性的集合,在执行是赋值的主变量也可放在WHERE子句中.WHERE子句中所用的主变量称为输入主变量。如:
SELECT EMPNO, JOB, SAL
INTO:PNAME, :PJOB, :PSAL
FROM EMP
WHERE EMPNO=:PEMPNO;
若没有找到限定的行, 则SQLCA.SQLCODE返回”+1403”, 表明”没有找到”。
INTO从句中的主变量叫输出主变量,它提供了查询时所需要的信息。
在任何项送给主变量之前,都要求ORACLE把这些项转换成主变量的数据类型。对于数字是通过截断来完成的(如:9.23转换为9)。
如果已确定查询只返回一行,那么就不必使用游标,只给SELECT语句增加一个INTO子句即可。在语义上INTO语句在FROM之前的查询中有多少个选择项就有多少个输出主变量。若在SELECT项中表达式的数目不等于INTO子句中主变量的数目,就把SQLCA.SQLWARN[3]置为”W”。 2)多行查询及游标的使用
如果查询返回多行或不知道返回多少行,使用带有ORACLE游标(CURSOR)的SELECT语句。
游标是ORACLE和PRO*C存放查询结果的工作区域。一个游标(已命名的)与一条SELECT语句相关联。操作游标有由4条命令:(1)DECLARE CURSOR;(2)OPEN CURSOR;(3)FETCH;(4)CLOSE CURSOR。 定义游标
一个游标必须首先定义, 才能使用它。语法为:
EXEC SQL DECLARE 〈游标名〉CORSOR FOR
SELECT 〈列〉
FROM 〈表〉
例如:
EXEC SQL DECLARE CSOR, CURSOR FOR
SELECT ENAME , JOB, SAL
FROM EMP
WHERE DEPTNO=:DEPTNO;
当赋给一个与查询相关联的游标CURSOR之后, 当SELECT查询EMP时可从数据库中返回多行,这些行就是CURSOR的一个活动区域。
注意:
定义游标必须在对游标操作之前完成;
PRO*C不能引用没有定义的游标;
游标定义后,其作用范围是整个程序。所以对一个程序来讲, 同时定义两个相同的游标是错误的。 B. 打开游标
打开游标的OPEN语句主要用来输入主变量的内容,这些主要是WHERE中使用的主变量。打开游标的语句是:EXEC SQL OPEN 〈游标名〉
当打开游标后,可以从相关的查询中取出多于一行的结果。所有满足查询标准的行组成一集合,叫做“游标活动集”。通过取操作,活动集中的每一行或每一组是一个一个返回的,查询完成后, 游标就可关闭了。如图所示:
定义游标:DECLARE 开始查询:SELECT打开游标:OPEN 从活动集取数据:FETCH
查询完成
关闭游标:CLOSE
注意:1)游标处于活动集的第一行前面;
2)若改变了输入主变量就必须重新打开游标。 C. 取数据
从活动集中取出一行或一组把结果送到输出主变量中的过程叫取数据。输出主变量的定义在取数据语句中。取数据的语句如下:
EXEC SQL FETCH〈游标名〉INTO:主变量1,主变量2,……
FETCH的工作过程如图所示: 查询结果查询结果 …… 如图所示的查询结果指满足查询条件的查询结果。使用FETCH应注意以下几点:
游标必须先定义再打开。
只有在游标打开之后才能取数据,即执行FETCH语句。
FETCH语句每执行一次,从当前行或当前组取数据一次,下一行或下一组向上移一次。游标每次所指的行或组都为当前行或当前组,而FETCH每次都是取游标所指定的行或组的数据。
当游标活动集空之后,ORCLE返回一个SQLCA。SQLCA(=1403)。
若希望此游标再操作, 必须先关闭再打开它。
在C程序中可以开辟一个内存空间,来存放操作结果,这样就能利用开辟的空间来灵活操纵查询的结果。 D.关闭游标
取完活动集中所有行后,必须关闭游标,以释放与该游标有关的资源。
关闭游标的格式为:
EXEC SQL CLOSE 游标名;
例如:
EXEC SQL CLOSE C1;
ORACLE V5.0版支持SQL格式“CURRENT OF CURSOR”。这条语句将指向一个游标中最新取出的行, 以用于修改和删除操作。该语句必须有取操作之后使用,它等同存储一个ROWID,并使用它。 (4).举例
EXEC SQL DECLARE SALESPEOPLE CURSOR FOR
SELECT SSNO, NAME, SALARY
FROM EMPLOYEE
WHERE DNAME=‘Sales’;
EXEC SQL OPEN SALESPEOPLE;
EXEC SQL FETCH SALESPEOPLE
INTO :SS,:NAME,:SAL;
EXEC SQL CLOSE SALESPEOPLE; (5)SQL嵌套的方法及应用
嵌入SQL与交互式SQL在形式上有如下差别:
在SQL语句前增加前缀“EXEC SQL”, 这一小小的差别其目的是在于预编译时容易识别出来, 以便把每一条SQL作为一条高级语言来处理。
每一SQL语句分为说明性语句和可执行语句两大类。可执行语句又分为数据定义、数据控制、数据操纵、数据检索四大类。
可执行性SQL语句写在高级语言的可执行处;说明性SQL语句写在高级语言的说明性的地方。
例如:在PRO*C程序中建立一个名为BOOK的表结构,过程如下:
#include〈stdio.h〉
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20], pwd[20];
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
Main()
{
/*login database*/
strcpy(uid.arr,’wu’);
uid.len=strlen(uid,arr);
strcpy(pwd.arr,’wu’);
pwd.len=strlen(pwd.arr);
EXEC SQL CONNECT:uid IDENTIFEED BY:pwd;
EXEC SQL CREATE TABLE book
( acqnum number, copies number , price number);
EXEC SQL COMMIT WORK RELEASE;
EXIT;
PRO*C可非常简便灵活地访问ORCLE数据库中的数据,同时又具有C语言高速的特点,因而可完成一些ORACLE产品不能完成的任务,例如以下一个固定的特殊格式输出结果。
SQL嵌套源程序示例
#unclude
typedef char asciz[20];
EXEC SQL BEGIN DECLARE SECTION;
EXEC SQL TYPE asciz IS STRING (20) REFERENCE;
asciz username;
asciz password;
asciz emp_name(5);
int emp_number(5a);
float salary[5];
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE sqlca;
Void print_rows();
Void sqlerror();
Main()
{
int num_ret;
strcpy(username,”SCOTT’);
strcpy(password, “TYGER”);
EXEC SQL WHENEVER SQLERROR DO sqlerror();
EXEC SQL CONNECT:username IDENTIFIED BY:password;
Print (“/nConnected to ORACLE as user:%s/n”, username);
EXEC SQL DECLARE c1 CURSOR FOR
SELECT EMPNO , ENAME , SAL FROM EMP;
EXEC SQL OPEN c1;
Num_ret = 0;
For(;;)
{
EXEC SQL WHENEVER NOT FOUND DO break;
EXEC SQL FETCH c1 INTO : emp_number , :emp_name , :salary;
Print_rows (sqlca.sqlerrd[2] – num_ret);
Num_ret=sqlca.sqlerrd[2];
}
if ((sqlca.sqlerrd[2] – num_ret)>0);
print _rows(sqlca.sqlerrd[2] –num_ret);
EXEC SQL CLOSE c1;
Printf(“/Have a good day./n”);
EXEC SQL COMMIT WORK RELEASE;
} void print_rows(n);
int n;
{
int i;
printf(“/nNumber Employee Salary/n”);
printf(“------------------------------/n”);
for (i=0;iprintf(“% - 9d%- 8s%9.2f/n”,emp-number[i], emp---name[i],salary[i];
}
void sqlerror()
{
EXEC SQL WHENEVER SQLERROR CONTINUE;
Printf(“/noracle error detected:/n”);
Printf(‘/n%.70s/n”, sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
Exit(1);
}
(6) 错误检测和恢复
在使用SQL语句和PRO*C对数据库进行操作时,常常有字段空值,无条件删除,无行返回,数据溢出和截断等现象发生,这种现象可以用SQLCA和指示器变量来检测。
1 SQLCA的结构
在PRO*C程序中SQLCA结构如下:
STRUCT SQLCA{
Char sqlcaid[8];
Long sqlabc;
Long sqlcode;
STRUCT{
Unsigned sqlerrm1;
Char sqlerrmc[10];
}sqlerrm;
Char sqlerrp[8];
Long sqlerrd[6];
Char sqlwarn[8];
Char sqlext[8];
}
其中:
SQLCA.sqlerrm.sqlerrmc:带有SQLCA。SQLCODE的错误正文。
SQLCA.sqlerrd:当前ORACLE的状态,只有SQLCA.SQLERRD[2]有意义,表示DML语句处理的行数。
SQLCA.sqlwarn:提供可能遇到的条件信息。 在每执行一个SQL语句后,ORACLE就把返回结果放入SQLCA中,但说明语句除外。
用SQLCA可以查看SQL语句的执行结果。往往有三种结果:
=0:执行成功;
SQLCA.SQLCODE= >0:执行成功的状态值;
<0:失败,不允许继续执行。 2 指示器变量
指示器变量有时也称指示变量.指示变量与一个主变量相关联,指出主变量的返回情况.
=0:返回值不为空, 未被截断,值放在主变量中;
返回值= >0:返回值为空, 忽略主变量的值;
<0:主变量长度不够就被截断。
使用指示变量要注意:
在WHERE子句中不能用指示变量。用NULL属性来测试空值。
例如下列子句:
SELECT…
FROM…
WHERE ENAME IS NULL;
是正确的,而
WHERE ENAME=:PEME:PEME1
是错误的。
指示变量在插入空值之前为—1
可输出空值。 3 WHENEVER语句
WHENEVER是说明语句,不返回SQLCODE, 只是根据SQLCA中的返回码指定相关的措施。格式为
EXEC SQL WHENEVER [SQLERROR|SQLWARNING|NOTFORUND]
[STOP|CONTINUE|GOTO<标号>];
其中
(1)[STOP|CONTINUE|GOT<标号>]的缺省值为CONTINUE。
(2)SQLERROR:SQLCA.SQLCODE<0;
(3)SQLWARNIGN:SQLCA.SQLWARN[0]=“W”;
(4)NOTFOUND:SQLCA.SQLCODE=1403;
下面给出一段程序来说明WHENEVER的用法:
EXEC SQL BEGIN DEELARE SECTION;
VARCHAR UID[20];
VARCHAR PASW[20];
……
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
Main()
{
……
EXEC SQL WHENEVER SQLERROR GOTO ERR;
EXEC SQL CONNECT:UID/:PWD;
……
EXEC SQL DECLARE CSOR1 CURSOR FOR
SELECT 〈字段〉
FORM〈表〉
EXEC SQL OPEN CSOR1;
SQL
……
EXEC SQL WHENEVER NOT FOUND GOTO good;
For(;;)
EXEC SQL FETCH CSOR, INTO……
Good:
……
printf(“/n查询结束/n”);
EXEC SQL CLOSE C1;
EXEC SQL WHENEVER SQLERROR CONTINUE.
EXEC SQL COMMIT WORK RELEASE:
Exit();
Printf(“/n%70s|n”, sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE:
Exit(1);
} (7) 动态定义语句
SQL语句分动态定义语句和静态定义语句两种:
静态定义语句:SQL语句事先编入PRO*C中,在经过预编译器编译之后形成目标程序*。BOJ,然后执行目标程序预即可。
动态定义语句:有些语句不能事先嵌入到PRO*C程序中,要根据程序运行情况,用户自己从输入设备上(如终端上)实时输入即将执行的SQL语句。
动态定义语句有:
EXECUTE IMMEDIATE;
PREPARE 与EXECUTE;
PREPARE与FETCH 和 OPEN ;
BIND与DEFINE DESCRIPTOR。 EXECUTE IMMEDIATE语句
此语句表示立即执行, 并且只向SQLCA返回执行结果,无其它信息。例如:
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR abcd[89];
VARCHAR deay[20];
EXEC SQL END DECLARE SECTION;
/** 输出字符串到abcd **/
EXEC SQL EXECUTE IMMEDIATE :abcd;
注意:
EXECUTE IMMEDIATE只能运行带一个参数的动态语句。其中,abcd是参数,不是关键字。
EXECUTE IMMEDIATE使用的先决条件是:SQL语句不能包含主变量;SQL语句不能是查询语句。
可用任何主变量作为EXECUTE IMMEDIATE的参数;也可用字符串作为主变量。 PREPARE与EXECUTE语句
此语句表示“预编译/执行”。此语句能够预编译一次而执行多次。语法为:
EXEC SQL PREPARE 〈语句名〉FROM:主变量;
EXEC SQL EXECUTE〈语句名〉[USING:替换主变量];
PREPARE语句做两件事:
预编译SQL语句;
给出SQL语句的语句名。
注意:
SQL语句不能是查询语句;
PREPARE和EXECUTE可包含主变量;
PREPARE不能多次执行。
例如:
#define USERNAME “SCOTT”
#define PASSWORD “TIGER”
#include
EXEC SQL INCLUDE sqlca;
EXEC SQL BEGIN DECLARE SECTION;
Char * username=USERNAME;
Char * password=PASSWORD;
VARCHAR sqlstmt[80];
Int emp_number;
VARCHAR emp_name[15];
VARCHAR job[50];
EXEC SQL END DECLARE SECTION;
Main()
{
EXEC SQL WHENEVER SQLERROR GOTO :sqlerror;
EXEC SQL CONNECT :username IDENTIFIED BY :password;
Sqlstmt.len=sprintf(sqlstmt.arr,”INSERT INTO EMP (EMPNO,ENAME,JOB,SAL)
VALUES(:V1,:V2,:V3,:V4)”);
Puts(sqlstmt.arr);
EXEC SQL PREPARE S FROM :sqlstmt;
For(;;)
{
printf(“/nenter employee number:”);
scanf(“%d”,&emp_number);
if (emp_number==0) break;
printf(“/nenter employee name:”);
scanf(“%s”,&emp_name.arr);
emp_name.len=strlen(emp_name.arr);
printf(“/nenter employee job:”);
scanf(“%s”,job.arr);
job.len=strlen(job.arr);
printf(“/nenter employee salary:”);
scanf(“%f”,&salary);
}
EXEC SQL EXECUTE S USING :emp_number,:emp_name,:job,:salary;
}
FETCH语句和OPEN语句
FETCH语句和OPEN语句这组动态语句是对游标进行操作的,其执行过程如下:
PREPARE〈语句名〉FROM 〈主变量字符串〉;
DECLARE〈游标名〉FOR〈语句名〉;
OPEN 〈游标名〉[USING:替换变量1[,:替换变量变…]]
FETCH〈游标名〉INTO: 主变量1[,:主变量2…]
CLOSE〈游标名〉
注意:
SQL语句允许使用查询语句;
SELECT子句中的列名不能动态改变,只能预置;
WHERE和ORDER BY 子句可以动态改变条件。 Pro*C的编译和运行 先用ORACLE预编译器PROC对PRO*C程序进行预处理,该编译器将源程序中嵌入的SQL语言翻译成C语言,产生一个C语言编译器能直接编译的文件。生成文件的扩展名为 .C
用C语言编译器CC 对扩展名为 .c的文件编译,产生目标码文件,其扩展名为 .o
使用MAKE命令,连接目标码文件,生成可运行文件
例如: 对上面的example.pc进行编译运行
PROC iname=example.pc
CC example.c
MAKE EXE=example OBJS=”example.o”
example
SQL语言简介
一. SQL概述
SQL是一种面向数据库的通用数据处理语言规范,能完成以下几类功能:提取查询数据,插入修改删除数据,生成修改和删除数据库对象,数据库安全控制,数据库完整性及数据保护控制。
数据库对象包括表、视图、索引、同义词、簇、触发器、函数、过程、包、数据库链、快照等(表空间、回滚段、角色、用户)。数据库通过对表的操作来管理存储在其中的数据。
1) SQL*PLUS界面:
登录:输入SQLPLUS回车;输入正确的ORACLE用户名并回车;输入用户口令并回车,显示提示符:SQL>
退出:输入EXIT即可。
2)命令的编辑与运行:
? 在命令提示符后输入SQL命令并运行,以分号结束输入;以斜杠结束输入;以空行结束输入;
? 利用SQL缓冲区进行PL/SQL块的编辑和运行;
? 利用命令文件进行PL/SQL块的编辑和运行。 1、 数据库查询
1) 用SELECT语句从表中提取查询数据。语法为
SELECT [DISTINCT] {column1,column2,…} FROM tablename WHERE {conditions} GROUP BY {conditions} ORDER BY {expressions} [ASC/DESC];
说明:SELECT子句用于指定检索数据库的中哪些列,FROM子句用于指定从哪一个表或视图中检索数据。
2) SELECT中的操作符及多表查询WHERE子句。(LIKE,IS,…)
WHERE子句中的条件可以是一个包含等号或不等号的条件表达式,也可以是一个含有IN、NOT IN、BETWEEN、LIKE、IS NOT NULL等比较运算符的条件式,还可以是由单一的条件表达通过逻辑运算符组合成复合条件。
3) ORDER BY 子句
ORDER BY 子句使得SQL在显示查询结果时将各返回行按顺序排列,返回行的排列顺序由ORDER BY 子句指定的表达式的值确定。
4) 连接查询
利用SELECT语句进行数据库查询时,可以把多个表、视图的数据结合起来,使得查询结果的每一行中包含来自多个表达式或视图的数据,这种操作被称为连接查询。
连接查询的方法是在SELECT命令的FROM子句中指定两个或多个将被连接查询的表或视图,并且在WHERE子句告诉ORACLE如何把多个表的数据进行合并。根据WHERE子句中的条件表达式是等还是不等式,可以把连接查询分为等式连接和不等式连接。
5) 子查询
如果某一个SELECT命令(查询1)出现在另一个SQL命令(查询2)的一个子句中,则称查询1是查询2的子查询。 2、 基本数据类型(NUMBER,VARCHAR2,DATE) O
RACEL支持下列内部数据类型:
●VARCHAR2 变长字符串,最长为2000字符。
●NUMBER 数值型。
●LONG 变长字符数据,最长为2G字节。
●DATE 日期型。
●RAW 二进制数据,最长为255字节。
● LONG RAW 变长二进制数据,最长为2G字节。
●ROWID 二六进制串,表示表的行的唯一地址。
●CHAR 定长字符数据,最长为255。 3、 常用函数用法:
一个函数类似于一个算符,它操作数据项,返回一个结果。函数在格式上不同于算符,它个具有变元,可操作0个、一个、二个或多个变元,形式为:
函数名(变元,变元,…)
函数具有下列一般类形:
● 单行函数
●分组函数
1) 单行函数对查询的表或视图的每一行返回一个结果行。它有数值函数,字符函数,日期函数,转换函数等。
2) 分组函数返回的结果是基于行组而不是单行,所以分组函数不同于单行函数。在许多分组函数中可有下列选项:
● DISTRNCT 该选项使分组函数只考虑变元表达式中的不同值。
● ALL该选项使分组函数考虑全部值,包含全部重复。
全部分组函数(除COUNT(*)外)忽略空值。如果具有分组函数的查询,没有返回行或只有空值(分组函数的变元取值的行),则分组函数返回空值。
5、 数据操纵语言命令:
数据库操纵语言(DML)命令用于查询和操纵模式对象中的数据,它不隐式地提交当前事务。它包含UPDATE、INSERT、DELETE、EXPLAIN PLAN、SELECT和LOCK TABLE 等命令。下面简单介绍一下:
1) UPDATE tablename SET {column1=expression1,column2=expression2,…} WHERE {conditions};
例如:S QL>UPDATE EMP
SET JOB =’MANAGER’
WHERE ENAME=’MAPTIN’;
SQL >SELECT * FROM EMP;
UPDATE子句指明了要修改的数据库是EMP,并用WHERE子句限制了只对名字(ENAME)为’MARTIN’的职工的数据进行修改,SET子句则说明修改的方式,即把’MARTION’的工作名称(JOB)改为’MARAGER’.
2) INSERT INTO tablename {column1,column2,…} VALUES {expression1,expression2,…};
例如:SQL>SELECT INTO DEPT(DNAME, DEPTNO)
VALUES (‘ACCOUNTING’,10) 3) DELETE FROM tablename WHERE {conditions};
例如:SQL>DELETE FROM EMP
WHERE EMPNO = 7654;
DELETE命令删除一条记录,而且DELETE命令只能删除整行,而不能删除某行中的部分数据.
4) 事务控制命令
提交命令(COMMIT):可以使数据库的修改永久化.设置AUTOCOMMIT为允许状态:SQL >SET AUTOCOMMIT ON;
回滚命令(ROLLBACK):消除上一个COMMIT命令后的所做的全部修改,使得数据库的内容恢复到上一个COMMIT执行后的状态.使用方法是:
SQL>ROLLBACK;
4、 创建表、视图、索引、同义词、用户。
1) 、表是存储用户数据的基本结构。
建立表主要指定义下列信息:
●列定义
●完整性约束
●表所在表空间
●存储特性
●可选择的聚集
●从一查询获得数据
语法如下:CREATE TABLE tablename
(column1 datatype [DEFAULT expression] [constraint],
column1 datatype [DEFAULT expression] [constraint],
……)
[STORAGE子句]
[其他子句…];
例如:
SQL>CREATE TABLE NEW_DEPT
(DPTNO NUMBER(2),
DNAME CHAR(6),
LOC CHAR(13);
更改表作用:
● 增加列
●增加完整性约束
●重新定义列(数据类型、长度、缺省值)
●修改存储参数或其它参数
●使能、使不能或删除一完整性约束或触发器
●显式地分配一个范围
2)、视图
视图是一个逻辑表,它允许操作者从其它表或视图存取数据,视图本身不包含数据。视图所基于的表称为基表。
引入视图有下列作用:
●提供附加的表安全级,限制存取基表的行或/和列集合。
● 隐藏数据复杂性。
●为数据提供另一种观点。
●促使ORACLE的某些操作在包含视图的数据库上执行,而不在另一个数据库上执行。
3)、索引
索引是种数据库对象。对于在表或聚集的索引列上的每一值将包含一项,为行提供直接的快速存取。在下列情况ORACLE可利用索引改进性能:
●按指定的索引列的值查找行。
●按索引列的顺序存取表。
建立索引: CREATE [UNIQUE] INDEX indexname ON tablename(column ,。。。);
例如:SQL>CREAT INDEX IC_EMP
ON CLUSTER EMPLOYEE
4)、同义词
同义词:为表、视图、序列、存储函数、包、快照或其它同义词的另一个名字。使用同义词为了安全和方便。对一对象建立同义词可有下列好处:
●引用对象不需指出对象的持有者。
●引用对象不需指出它所位于的数据库。
●为对象提供另一个名字。
建立同义词:
CREATE SYNONYM symnon_name FOR [username.]tablename;
例如:CREAT PUBLIC SYNONYM EMP
FOR SCOTT.EMP @SALES 5)、用户
CREATE USER username IDENTIFIED BY password;
例如:SQL>CREATE USER SIDNEY
IDENTIFIED BY CARTON ;
二. Oracle扩展PL/SQL简介
1、 PL/SQL概述。
PL/SQL是Oracle对SQL规范的扩展,是一种块结构语言,即构成一个PL/SQL程序的基本单位(过程、函数和无名块)是逻辑块,可包含任何数目的嵌套了快。这种程序结构支持逐步求精方法解决问题。一个块(或子块)将逻辑上相关的说明和语句组合在一起,其形式为:
DECLARE
---说明
BEGIN
---语句序列
EXCEPTION
---例外处理程序
END;
它有以下优点:
●支持SQL;
●生产率高;
●性能好;
●可称植性;
●与ORACLE集成. 2、 PL/SQL体系结构
PL/SQL运行系统是种技术,不是一种独立产品,可认为这种技术是PL/SQL块和子程序的一种机,它可接收任何有效的PL/SQL块或子程序。如图所示: PL/SQL机可执行过程性语句,而将SQL语句发送到ORACLE服务器上的SQL语句执行器。在ORACLE预编译程序或OCI程序中可嵌入无名的PL/SQL块。如果ORACLE具有PROCEDURAL选件,有名的PL/SQL块(子程序)可单独编译,永久地存储在数据库中,准备执行。
3、 PL/SQL基础:
PL/SQL有一字符集、保留字、标点、数据类型、严密语法等,它与SQL有相同表示,现重点介绍。
1)、数据类型:如下表所示
数据类型 子类型
纯量类型 数值 BINARY_INTEGER NATURAL,POSITIVE
NUMBER DEC,DECIMAL,DOUBLE PRECISION,PLOAT,INTEGER,INT,NUMERIC,REAL,SMALLINT
字符 CHAR CHARACTER,STRING
VARCHAR2 VARCHAR
LONG
LONG RAW
RAW
RAWID
逻辑 BOOLEAN
日期 DATE
组合
类型 记录 RECORD
表 TABLE
2)、变量和常量
在PL/SQL程序中可将值存储在变量和常量中,当程序执行时,变量的值可以改变,而常量的值不能改变。 3)、程序块式结构:
DECLARE
变量说明部分;
BEGIN
执行语句部分;
[EXCEPTION
例外处理部分;]
END; 4、 控制语句:
分支语句:
IF condition THEN
Sequence_of_statements;
END IF; IF condition THEN
Sequence_of_statement1;
ELSE
Sequence_of_statement2;
END IF; IF condition1 THEN
Sequence_of_statement1;
ELSIF condition2 THEN
Sequence_of_statement2;
ELSIF condition3 THEN
Sequence_of_statement3;
END IF;
5、 循环语句:
LOOP
Sequence_of_statements;
IF condition THEN
EXIT;
END IF;
END LOOP;
WHILE condition LOOP
Sequence_of_statements;
END LOOP;
FOR counter IN lower_bound..higher_bound LOOP
Sequence_of_statements;
END LOOP; 6、 子程序:
存储过程:
CREATE PROCEDURE 过程名 (参数说明1,参数说明2, 。。。) IS
[局部说明]
BEGIN
执行语句;
END 过程名; 存储函数:
CREATE FUNCTION 函数名 (参数说明1,参数说明2, 。。。)
RETURN 类型 IS
[局部说明]
BEGIN
执行语句;
END 函数名; |