基于深度学习神经网络等机器学习技术实现一个医学辅助诊断的专家系统原型
3.运行环境搭建
操作系统:Ubantu
(1)安装python模块
sudo apt-get install python-pip
(2)安装numpy
sudo apt-get install python-numpy
(3)安装opencv
sudo apt-get install python-opencv
(4)安装OCR和预处理相关依赖
sudo apt-get install tesseract-ocr
sudo pip install pytesseract
sudo apt-get install pyton-tk
sudo pip install pillow
(5)安装Flask框架、mongo
sudo pip install Flask
sudo apt-get install mongodb
sudo service mongodb started
sudo pip install pymongo
(6)安装tensorflow
pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.0rc0-cp27-none-linux_x86_64.whl
4.Demo
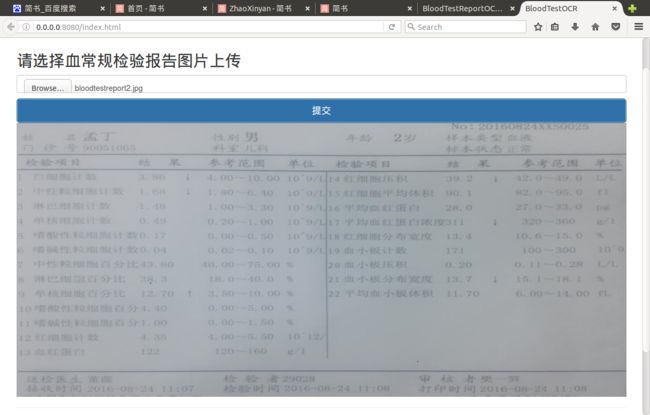
(1)定位到BloodTestReportOCR文件夹,输入python view.py

(2)打开浏览器,输入localhost:8080

(3)选择样本图片上传后得到矫正后的图片

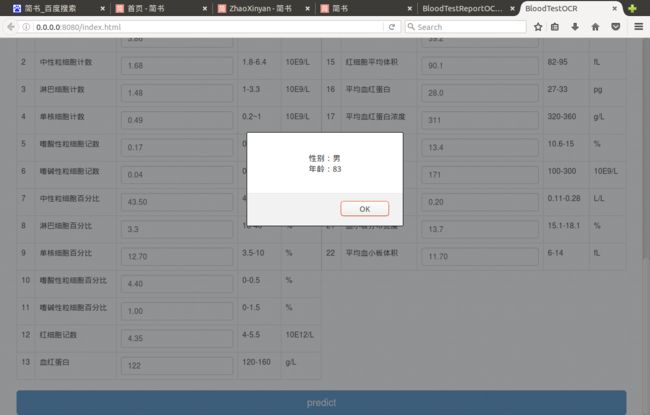
(4)点击“生成报告”,得到OCR的结果

(5)点击“predict”,得到预测结果

- 代码分析
1.相关文件介绍
view.py
Web端上传图片到服务器,存入mongodb并获取oid,稍作修整,希望能往REST架构设计,目前还不完善
imageFilter.py
对图形透视裁剪和OCR进行了简单的封装,以便于模块间的交互,规定适当的接口
imageFilter = ImageFilter()#可以传入一个opencv格式打开的图片
num = 22
print imageFilter.ocr(num)
OCR函数-模块主函数返回识别数据
用于对img进行ocr识别,它会先进行剪切,之后进一步做ocr识别,返回一个json对象,如果剪切失败,则返回None @num规定剪切项目数
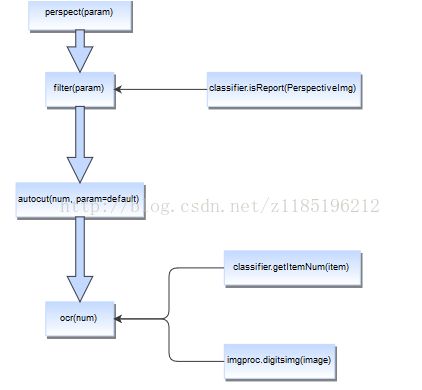
perspect函数-做初步的矫正图片
用于透视image,它会缓存一个透视后的opencv numpy矩阵,并返回该矩阵。透视失败,则会返回None,并打印不是报告@param透视参数
关于param
参数的形式为[p1,p2,p3,p4,p5]。p1,p2,p3,p4,p5都是整型,其中p1必须是奇数。
p1是高斯模糊的参数,p2和p3是canny边缘检测的高低阀值,p4和p5是和刷选有关的乘数。
如果化验报告单放在桌子上时,有的边缘会稍微翘起,产生比较明显的阴影,这种阴影有可能被识别出来,导致定位失败。解决的方法是调整p2和p3,来将阴影线筛选掉。但是如果将P2和P3调的比较高,就会导致其他图里的黑线也被筛选掉了。参数的选择是一个问题。前列们在getinfo.default中设置的是一个较低的阀值,p2=70,p3=30,这个阀值不会屏蔽阴影线。如果改为p2=70,p3=50则可以屏蔽,但是会导致其他图片识别困难。
就现在来看,得到较好结果的前提主要有三个
- 代码分析
(1)化验单尽量平整
(2)图片中应该包含全部的三条黑线
(3)图片尽量不要包含化验单的边缘,如果有的话,请尽量避开有阴影的边缘。
filter函数-过滤掉不合格的或非报告图片
返回img经过透视过后的PIL格式的Image对象,如果缓存中游PerspectivImg则直接使用,没有先进行透视过滤,失败则返回None @param filter参数
autocut函数-将图片中性别、年龄、日期和各项目名称数据分别剪切出来
用于剪切ImageFilter中的img成员,剪切之后临时图片保存在out_path,如果剪切失败,返回-1,成功返回0
@num 剪切项目数 @param 剪切参数
剪切出来的图片在BloodTestReportOCR/temp_pics/文件夹下
函数输出为data0.jpg,data1.jpg......等一系列图片,分别是白细胞计数,中性粒细胞记数等的数值的图片。
classifier.py
用于判定裁剪矫正后的报告和裁剪出检测项目的编号
imgproc.py
将识别的图像进行处理二值化等操作,提高识别率,包括对中文和数字的处理
digits
将该文件替换Tesseract-OCR\tessdata\configs中的digits
b)腐蚀、膨胀
c)求最小外接矩形
将轮廓变成线:比较最小外接矩形相邻两条边的长短,以两条短边的中点作为线的两端;
若线数量大于三则根据线长短继续筛选长线。根据三条线间的距离确定表格头部和内容的位置;
利用向量叉乘不可变性确定起始点(若方向相反,结果为负),将表格内容往上包含头部的一些年龄性别信息。
a)透射变换
b)截图
c)对每份数据调用pytesserac的OCR库进行识别
'''
围不同,因此有必要将他们都归一化到一个固定的范围,一般情况下是归一化到[0 1]或者[-1 1]。同样在TensorFlow的MNIST源码中可以看到,去均值后,会将每点的像素值除以128,进行了归一化操作。
下边是本门课程中写的去均值与归一化代码,a是训练集,b是需要预测的一组样本。返回结果是去均值与归一化之后的样本b。
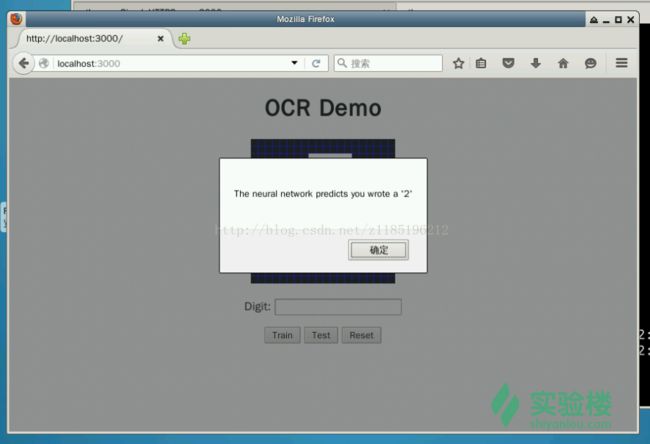
A1:神经网络实现手写识别系统
这个项目可以说是深度学习的hello world。可以通过这个项目来入门机器学习。但是在跑的过程中还是遇到了一些麻烦。因为原来我的电脑中装的是python3.5,和pyhton2.7中的有些包是不兼容的。所以后来又重新装了pyhton2.7总算跑起来了。
当然跑不是最重要的,重要的是理解算法。这是一个最简单的神经网络,只有一层输入层,一层隐藏层,一个输出层。输入是20乘20,也就是400个像素点,400行一列的矩阵。着色的部分为1,否则为0。输出是一个10行一列的one-hot矩阵代表是哪个数字。采用反向传播算法,它通过计算误差率然后系统根据误差改变网络的权值矩阵和偏置向量来进行训练。
初次之外,我还对一个完整的项目的运作有了了解。数据怎样从前端流向后端,再调用算法进行计算,最后显示在网页上。
用户接口(ocr.html)--html网页
客户端(ocr.js)--处理在客户端接收到的响应、传递服务器的响应
服务器(server.py)--由Python标准库BaseHTTPServer实现,接收从客户端发来的训练或是预测请求,使用POST报文
神经网络(ocr.py) --实现具体算法
神经网络设计脚本(neural_network_design.py)--测试用
2 调用CV2模块的findContours提取矩形轮廓,筛选对角线大于阈值的轮廓
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
def getbox(i):
rect = cv2.minAreaRect(contours[i])
box = cv2.cv.BoxPoints(rect)
box = np.int0(box)
return box
def distance(box):
delta1 = box[0]-box[2]
delta2 = box[1]-box[3]
distance1 = np.dot(delta1,delta1)
distance2 = np.dot(delta2,delta2)
distance_avg = (distance1 + distance2) / 2
return distance_avg
# 筛选出对角线足够大的几个轮廓
found = []
for i in range(len(contours)):
box = getbox(i)
distance_arr = distance(box)
if distance_arr > ref_lenth:
found.append([i, box])
def getline(box):
if np.dot(box[1]-box[2],box[1]-box[2]) < np.dot(box[0]-box[1],box[0]-box[1]):
point1 = (box[1] + box[2]) / 2
point2 = (box[3] + box[0]) / 2
lenth = np.dot(point1-point2, point1-point2)
return point1, point2, lenth
else:
point1 = (box[0] + box[1]) / 2
point2 = (box[2] + box[3]) / 2
lenth = np.dot(point1-point2, point1-point2)
return point1, point2, lenth
def cmp(p1, p2):
delta = p1 - p2
distance = np.dot(delta, delta)
if distance < img_sp[0] * img_sp[1] * ref_close_multiplier:
return 1
else:
return 0
def linecmp(l1, l2):
f_point1 = l1[0]
f_point2 = l1[1]
f_lenth = l1[2]
b_point1 = l2[0]
b_point2 = l2[1]
b_lenth = l2[2]
if cmp(f_point1,b_point1) or cmp(f_point1,b_point2) or cmp(f_point2,b_point1) or cmp(f_point2,b_point2):
if f_lenth > b_lenth:
return 1
else:
return -1
else:
return 0
def deleteline(line, j):
lenth = len(line)
for i in range(lenth):
if line[i] is j:
del line[i]
return 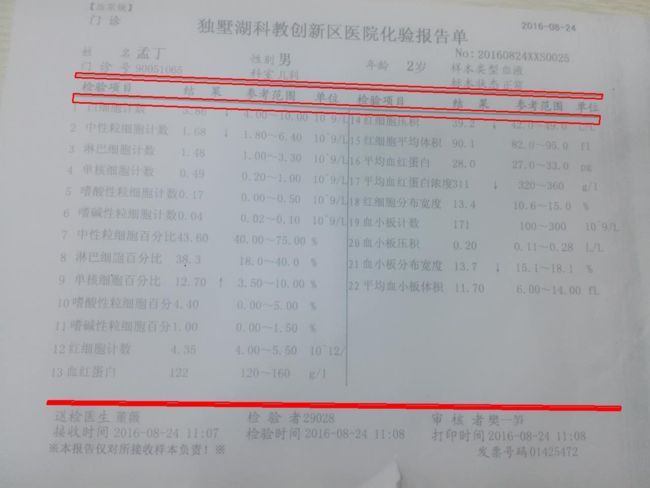
4 使用透视变换将表格区域转换为一个1000*760的图,得到可用于ocr剪切的照片
5 autocut(self, num, param=default)函数用于剪切ImageFilter中的img成员,剪切之前调用filter(param)判断是否为可识别的图像,剪切之后临时图片保存在out_path,如果剪切失败,返回-1,成功返回0
6 ocr(self, num)函数用于对img进行ocr识别,返回一个json格式数据。
A3:根据血常规检验的各项数据预测年龄和性别
下面我们要做的就是构建机器学习模型了。我们使用了2000多份血常规报告,90%用于训练,10%用于检验。我使用的是基于tensorflow实现的神经网络
神经网络原理
神经网络由能够互相通信的节点构成,赫布理论解释了人体的神经网络是如何通过改变自身的结构和神经连接的强度来记忆某种模式的。而人工智能中的神经网络与此类似。请看下图,最左一列蓝色节点是输入节点,最右列节点是输出节点,中间节点是隐藏节点。该图结构是分层的,隐藏的部分有时候也会分为多个隐藏层。如果使用的层数非常多就会变成我们平常说的深度学习了。
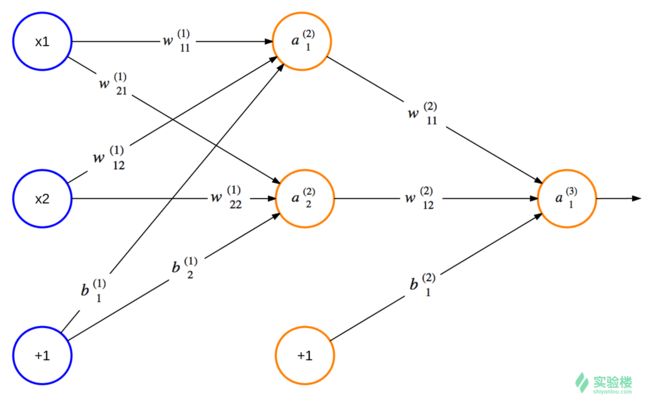
神经网络属于监督学习,那么多半就三件事,决定模型参数,通过数据集训练学习,训练好后就能到分类工具/识别系统用了。数据集可以分为2部分(训练集,验证集),也可以分为3部分(训练集,验证集,测试集),训练集可以看作平时做的习题集(可反复做)。通过不断的训练减少损失,我们就可以得到最优的参数,即偏置向量和权重。
调参经验
在总结点数量差不多的情况下,深层但每层的隐藏节点数较少的网络较之浅层但每层节点数的网络效果要好。其它参数,近两年论文基本都用同样的参数设定:迭代几十到几百epoch。sgd,mini batch size从几十到几百皆可。步长0.1,可手动收缩,weight decay取0.005,momentum取0.9。dropout加relu。weight用高斯分布初始化,bias全初始化为0。输入特征和预测目标都做好归一化也有助于提高准确率。
在A2中,因为我写的神经网络和版本库上的类似,所以就没有上传,下面讲讲我的贡献,数据封装和可视化
数据封装
因为看到minist手写识别的代码中把数据集封装成了对象,用起来很方便,所以就做了这个。
train = Traindata() #初始化
gender = train.gender #性别的one-hot矩阵
age = train.age #年龄
para = train.parameter #26项指标矩阵
train.next_batch_gender(n) #随机抽取n项数据对应的指标及其性别
train.next_batch_age(n) #同上TensorBoard:可视化学习
官方文档中的介绍是这样的:
TensorBoard 涉及到的运算,通常是在训练庞大的深度神经网络中出现的复杂而又难以理解的运算。
为了更方便 TensorFlow 程序的理解、调试与优化,我们发布了一套叫做 TensorBoard 的可视化工具。你可以用 TensorBoard 来展现你的 TensorFlow 图像,绘制图像生成的定量指标图以及附加数据。
想要可视化,首先要定义图层和对节点命名:
使用with tf.name_scope('inputs')将xs和ys包含进来,形成一个大的图层,图层的名字就是with tf.name_scope()方法里的参数。
with tf.name_scope('inputs'):
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1]) 然后再次对ys指定名称y_in,xs同理:
ys= tf.placeholder(tf.loat32, [None, 1],name='y_in') 在定义完大的框架layer之后,也可以定义每一个’框架‘里面的小部件:(Weights biases 和 activation function)。如对 Weights 定义: 定义的方法同上,可以使用tf.name.scope()方法,同时也可以在Weights中指定名称W。 即为:
def add_layer(inputs, in_size, out_size, activation_function=None):
#define layer name
with tf.name_scope('layer'):
#define weights name
with tf.name_scope('weights'):
Weights= tf.Variable(tf.random_normal([in_size, out_size]),name='W')
#and so on...... 接下来,我们为层中的Weights设置变化图, tensorflow中提供了tf.histogram_summary()方法,用来绘制图片, 第一个参数是图表的名称, 第二个参数是图表要记录的变量
tf.histogram_summary(layer_name+'/weights',Weights) Loss 的变化图和之前设置的方法略有不同. loss是在tesnorBorad 的event下面的, 这是由于我们使用的是tf.scalar_summary() 方法
with tf.name_scope('loss'):
loss= tf.reduce_mean(tf.reduce_sum( tf.square(ys- prediction), reduction_indices=[1]))
tf.scalar_summary('loss',loss) 接下来, 开始合并打包,tf.merge_all_summaries() 方法会对我们所有的 summaries合并到一起. 因此在原有代码片段中添加:
sess= tf.Session()
merged= tf.merge_all_summaries()
# tf.train.SummaryWriter soon be deprecated, use following
writer = tf.summary.FileWriter("logs/", sess.graph)
sess.run(tf.initialize_all_variables()) 程序运行完毕之后, 会产生logs目录 , 使用命令 tesnsorboard --logdir='logs/',打开终端中输出的URL地址即可。
代码
以年龄预测为例:
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import csv
import math
label_orign2 = []
data_orign2 = []
sex_orign2 = []
age_orign2 = []
#读预测数据
with open('predict.csv','rb') as precsv2:
reader2 = csv.reader(precsv2)
for line2 in reader2:
if reader2.line_num == 1:
continue
label_origntemp2 = [0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0] #升维度
label_origntemp2.insert(int(math.floor(float(line2[2])/10)),float(math.floor(float(line2[2])/10)))
label_orign2.append(label_origntemp2)
data_orign2.append(line2[3:])
label_np_arr2 = np.array(label_orign2)
data_np_arr2 = np.array(data_orign2)
sex_np_arr2 = np.array(sex_orign2)
data_len2 = data_np_arr2.shape[1]
data_num2 = data_np_arr2.shape[0]
label_orign = []
data_orign = []
sex_orign = []
age_orign = []
#读训练数据
with open('train.csv','rb') as precsv:
reader = csv.reader(precsv)
for line in reader:
if reader.line_num == 1:
continue
label_origntemp = [0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0] #升维度
label_origntemp.insert(int(math.floor(float(line[2])/10)),float(math.floor(float(line[2])/10)))
label_orign.append(label_origntemp)
data_orign.append(line[3:])
label_np_arr = np.array(label_orign)
data_np_arr = np.array(data_orign)
#sex_np_arr = np.array(sex_orign)
data_len = data_np_arr.shape[1]
data_num = data_np_arr.shape[0]
#添加层函数
def add_layer(inputs,in_size,out_size,n_layer,activation_function=None):
layer_name='layer%s'%n_layer
with tf.name_scope('layer'):
with tf.name_scope('weights'):
Ws = tf.Variable(tf.random_normal([in_size,out_size]))
tf.histogram_summary(layer_name+'/weights',Ws)
with tf.name_scope('baises'):
bs = tf.Variable(tf.zeros([1,out_size])+0.5)
tf.histogram_summary(layer_name+'/baises',bs)
with tf.name_scope('Wx_plus_b'):
Wxpb = tf.matmul(inputs,Ws) + bs
if activation_function is None:
outputs = Wxpb
else:
outputs = activation_function(Wxpb)
tf.histogram_summary(layer_name+'/outputs',outputs)
return outputs
#比较函数
def compute_accuracy(v_xs,v_ys):
global prediction
y_pre = sess.run(prediction,feed_dict={xs:v_xs})
correct_prediction = tf.equal(tf.argmax(y_pre,1),tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
result = sess.run(accuracy,feed_dict={xs:v_xs,ys:v_ys})
return result
# define placeholder for inputs to network
with tf.name_scope('inputs'):
xs = tf.placeholder(tf.float32,[None,data_len])
ys = tf.placeholder(tf.float32,[None,10])
#3个隐藏层
l1 = add_layer(xs,data_len,19,n_layer=1,activation_function=tf.nn.sigmoid)
l2 = add_layer(l1,19,19,n_layer=2,activation_function=tf.nn.sigmoid)
l3 = add_layer(l2,19,19,n_layer=3,activation_function=tf.nn.sigmoid)
# add output layer
prediction = add_layer(l3,19,10,n_layer=4,activation_function=tf.nn.softmax)
with tf.name_scope('loss'):
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))
tf.scalar_summary('loss',cross_entropy) #show in evernt
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(cross_entropy)
init = tf.initialize_all_variables()
saver = tf.train.Saver()
sess = tf.Session()
merged = tf.merge_all_summaries()
writer = tf.train.SummaryWriter("logs/", sess.graph)
sess.run(init)
for i in range(10000):
_, cost = sess.run([train_step, cross_entropy], feed_dict={xs:data_np_arr,
ys:label_np_arr.reshape((data_num,10))})
#sess.run(train_step,feed_dict={xs:data_np_arr,ys:label_np_arr.reshape((data_num,10))})
if i%50 == 0:
print("Epoch:", '%04d' % (i), "cost=", \
"{:.9f}".format(cost),"Accuracy:",compute_accuracy(data_np_arr2,label_np_arr2.reshape((data_num2,10))))
result = sess.run(merged,feed_dict={xs:data_np_arr,
ys:label_np_arr.reshape((data_num,10))})
writer.add_summary(result,i)
print("Optimization Finished!") 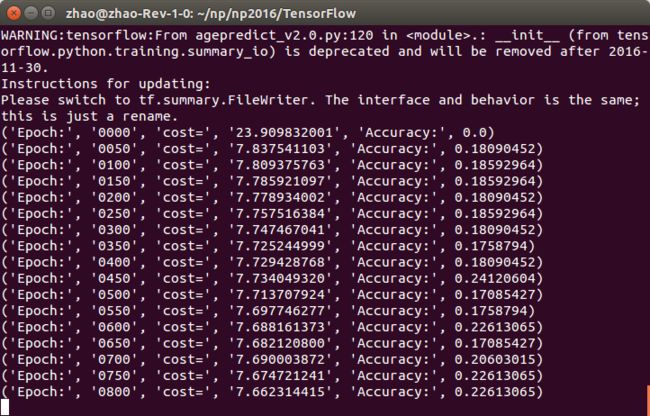
写在最后
陆放翁有诗云:
古人学问无遗力,少壮工夫老始成。纸上得来终觉浅,绝知此事要躬行。
此话倒是一点不假,经过这个项目我真的明显的感觉到了我的代码能力的提升。。。
首先在A1我就困难重重,虽然代码都是现成的(晕。。。),我的电脑中原先装的是python3.x,与python2.x各种不兼容。所以卸了重装才跑起来。
A2的时候我装的是openCV3,版本库上用的是CV2。。。再加上我刚开学时年少无知,居然装了Ubuntu kylin!各种环境问题,解决一个又来一个,果断重装系统后才终于没有环境问题了。果然Ubuntu14还是比较好的。
A3开始就需要学习机器学习算法了,因为我之前了解了一些机器学习的相关内容,所以这部分相对轻松了一些。加上我们又站在了巨人的肩膀上,我感觉对于程序员来讲,当了解算法的具体细节遇到困难时,了解已有库的封装和使用方式就变得尤其重要了。我学习的是谷歌的Tensorflow,它在实现神经网络上还是很给力的。对于这个库来说,主要需要了解的是节点、数据流、图等相关概念。想要弄的漂亮的话还可以做一些可视化处理。TensorFlow相对来说还是比较底层的一个库,比如Keras就是一个高层神经网络库,Keras由纯Python编写而成并基于Tensorflow或Theano。