最小二乘GAN:比常规GAN更稳定,比WGAN收敛更迅速
LSGANs基本思想
LSGANs的英文全称是Least Squares GANs。这篇文章针对的是标准GAN生成的图片质量不高以及训练过程不稳定这两个缺陷进行改进。改进方法就是将GAN的目标函数由交叉熵损失换成最小二乘损失,而且这一个改变同时解决了两个缺陷。
为什么最小二乘损失可以提高生成图片质量?
我们知道,GANs包含两个部分:判别器和生成器。判别器用于判断一张图片是来自真实数据还是生成器,要尽可能地给出准确判断;生成器用于生成图片,并且生成的图片要尽可能地混淆判别器。
本文作者认为以交叉熵作为损失,会使得生成器不会再优化那些被判别器识别为真实图片的生成图片,即使这些生成图片距离判别器的决策边界仍然很远,也就是距真实数据比较远。这意味着生成器的生成图片质量并不高。为什么生成器不再优化优化生成图片呢?是因为生成器已经完成我们为它设定的目标——尽可能地混淆判别器,所以交叉熵损失已经很小了。而最小二乘就不一样了,要想最小二乘损失比较小,在混淆判别器的前提下还得让生成器把距离决策边界比较远的生成图片拉向决策边界。这一段总结起来就是图1: 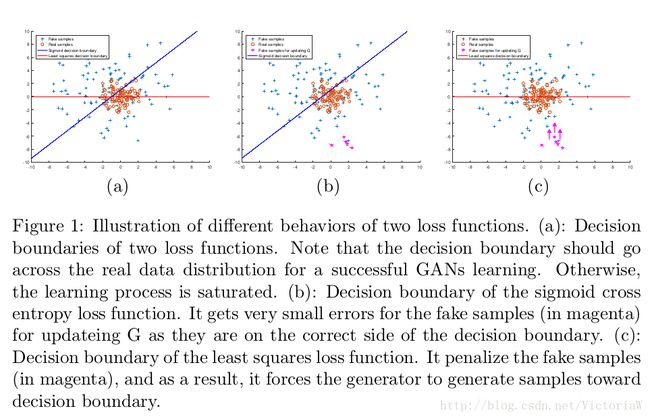
补充:作者是把决策边界作为中介,认为生成图片和真实数据之间的距离可以由生成图片和决策边界之间的距离来反映。这是因为学到的决策边界必须穿过真实数据点,否则就是学习过程饱和了。在未来工作中作者也提到可以改进的一点就是直接把生成图片拉向真实数据,而不是拉向决策边界。
为什么最小二乘损失可以使得GAN的训练更稳定呢?作者对这一点介绍的并不是很详细,只是说sigmoid交叉熵损失很容易就达到饱和状态(饱和是指梯度为0),而最小二乘损失只在一点达到饱和,如图2所示: 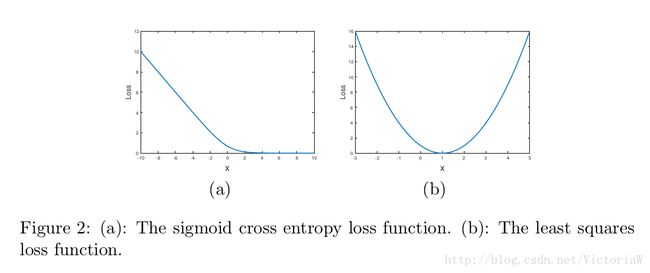
sigmoid损失处于饱和状态应该是和WGANs中提到的JS散度为常数一致,此时生成网络的梯度为0。
LSGANs的损失函数表达式
最小二乘损失函数:
其中, D(x;θD) 表示判别器, G(z;θG) 表示生成器,随机变量 z 服从标准正态分布。常数a、b分别表示真实图片和生成图片的标记;c是生成器为了让判别器认为生成图片是真实数据而定的值。
作者证明了上述优化目标函数在 a−c=1 、 a−b=2 的情况下等价于最小化 pr+pg 和 2pg 之间的Pearson卡方散度。
作者设置a=c=1,b=0。
近来 GAN 证明是十分强大的。因为当真实数据的概率分布不可算时,传统生成模型无法直接应用,而 GAN 能以对抗的性质逼近概率分布。但其也有很大的限制,因为函数饱和过快,当判别器越好时,生成器的消失也就越严重。所以不论是 WGAN 还是本文中的 LSGAN 都是试图使用不同的距离度量,从而构建一个不仅稳定,同时还收敛迅速的生成对抗网络。
项目地址:http://wiseodd.github.io/techblog/2017/03/02/least-squares-gan/
由于生成对抗网络训练的一般框架 F-GAN 已经构建了起来,最近我们可以看到一些并不像常规 GAN 的修订版生成对抗网络,它们会学习使用其它度量方法,而不只是 Jensen-Shannon 散度 (Jensen-Shannon divergence/JSD)。
其中一个修订版就是 Wasserstein 生成对抗网络(WGAN),该生成网络使用 Wasserstein 距离度量而不是 JSD。Wasserstein GAN 运行十分流畅,甚至其作者都声称该系统已经克服了模型崩溃难题并给生成对抗提供了十分强大的损失函数。尽管 Wasserstein GAN 的实现是很直接的,但在 WGAN 背后的理论是十分困难并需要一些如权重剪枝(weight clipping)等「hack」知识。另外 WGAN 的训练过程和收敛都要比常规 GAN 要慢一点。
现在,问题是:我们能设计一个比 WGAN 运行得更稳定、收敛更快速、流程更简单更直接的生成对抗网络吗?我们的答案是肯定的!
最小二乘生成对抗网络
LSGAN 的主要思想就是在辨别器 D 中使用更加平滑和非饱和(non-saturating)梯度的损失函数。我们想要辨别器(discriminator)D 将生成器(generator)G 所生成的数据「拖」到真实数据流形(data manifold)Pdata(X),从而使得生成器 G 生成类似 Pdata(X) 的数据。
我们知道在常规 GAN 中,辨别器使用的是对数损失(log loss.)。而对数损失的决策边界就如下图所示:
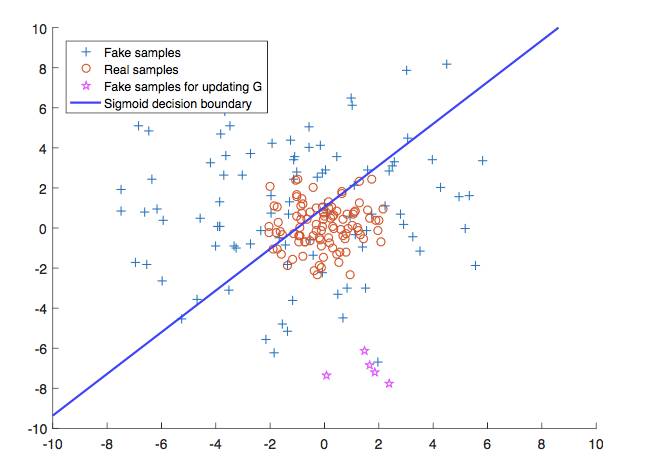
因为辨别器 D 使用的是 sigmoid 函数,并且由于 sigmoid 函数饱和得十分迅速,所以即使是十分小的数据点 x,该函数也会迅速忽略 x 到决策边界 w 的距离。这也就意味着 sigmoid 函数本质上不会惩罚远离 w 的 x。这也就说明我们满足于将 x 标注正确,因此随着 x 变得越来越大,辨别器 D 的梯度就会很快地下降到 0。因此对数损失并不关心距离,它仅仅关注于是否正确分类。
为了学习 Pdata(X) 的流形(manifold),对数损失(log loss)就不再有效了。由于生成器 G 是使用辨别器 D 的梯度进行训练的,那么如果辨别器的梯度很快就饱和到 0,生成器 G 就不能获取足够学习 Pdata(X) 所需要的信息。
输入 L2 损失(L2 loss):

在 L2 损失(L2 loss)中,与 w(即上例图中 Pdata(X) 的回归线)相当远的数据将会获得与距离成比例的惩罚。因此梯度就只有在 w 完全拟合所有数据 x 的情况下才为 0。如果生成器 G 没有没有捕获数据流形(data manifold),那么这将能确保辨别器 D 服从多信息梯度(informative gradients)。
在优化过程中,辨别器 D 的 L2 损失想要减小的唯一方法就是使得生成器 G 生成的 x 尽可能地接近 w。只有这样,生成器 G 才能学会匹配 Pdata(X)。
最小二乘生成对抗网络(LSGAN)的整体训练目标可以用以下方程式表达:
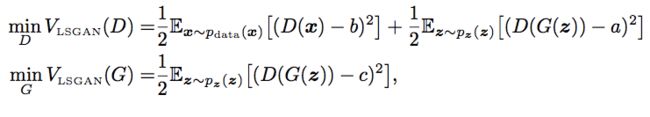
在上面方程式中,我们选择 b=1 表明它为真实的数据,a=0 表明其为伪造数据。最后 c=1 表明我们想欺骗辨别器 D。
但是这些值并不是唯一有效的值。LSGAN 作者提供了一些优化上述损失的理论,即如果 b-c=1 并且 b-a=2,那么优化上述损失就等同于最小化 Pearson χ^2 散度(Pearson χ^2 divergence)。因此,选择 a=-1、b=1 和 c=0 也是同样有效的。
我们最终的训练目标就是以下方程式所表达的:
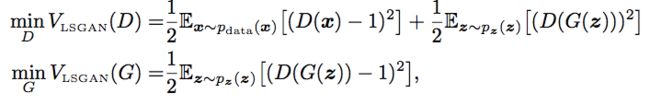
在 Pytorch 中 LSGAN 的实现
先将我们对常规生成对抗网络的修订给写出来:
1. 从辨别器 D 中移除对数损失
2. 使用 L2 损失代替对数损失
所以现在先让我们从第一个检查表(checklist)开始
G = torch.nn.Sequential(
torch.nn.Linear(z_dim, h_dim),
torch.nn.ReLU(),
torch.nn.Linear(h_dim, X_dim),
torch.nn.Sigmoid()
)
D = torch.nn.Sequential(
torch.nn.Linear(X_dim, h_dim),
torch.nn.ReLU(),
# No sigmoid
torch.nn.Linear(h_dim, 1),
)
G_solver = optim.Adam(G.parameters(), lr=lr)
D_solver = optim.Adam(D.parameters(), lr=lr)
剩下的就十分简单直接了,跟着上面的损失函数做就行。
for it in range(1000000):
# Sample data
z = Variable(torch.randn(mb_size, z_dim))
X, _ = mnist.train.next_batch(mb_size)
X = Variable(torch.from_numpy(X))
# Dicriminator
G_sample = G(z)
D_real = D(X)
D_fake = D(G_sample)
# Discriminator loss
D_loss = 0.5 * (torch.mean((D_real - 1)**2) + torch.mean(D_fake**2))
D_loss.backward()
D_solver.step()
reset_grad()
# Generator
G_sample = G(z)
D_fake = D(G_sample)
# Generator loss
G_loss = 0.5 * torch.mean((D_fake - 1)**2)
G_loss.backward()
G_solver.step()
reset_grad()
完整的代码可以在此获得:https://github.com/wiseodd/generative-models
结语
在这篇文章中,我们了解到通过使用 L2 损失(L2 loss)而不是对数损失(log loss)修订常规生成对抗网络而构造成新型生成对抗网络 LSGAN。我们不仅直观地了解到为什么 L2 损失将能帮助 GAN 学习数据流形(data manifold),同时还直观地理解了为什么 GAN 使用对数损失是不能进行有效地学习。
最后,我们还在 Pytorch 上对 LSGAN 做了一个实现。我们发现 LSGAN 的实现非常简单,基本上只有两段代码需要改变。
-
论文:Least Squares Generative Adversarial Networks
论文地址:https://arxiv.org/abs/1611.04076
摘要:最近应用生成对抗网络(generative adversarial networks/GAN)的无监督学习被证明是十分成功且有效的。常规生成对抗网络假定作为分类器的辨别器是使用 sigmoid 交叉熵损失函数(sigmoid cross entropy loss function)。然而这种损失函数可能在学习过程中导致导致梯度消失(vanishing gradient)问题。为了克服这一困难,我们提出了最小二乘生成对抗网络(Least Squares Generative Adversarial Networks/LSGANs),该生成对抗网络的辨别器(discriminator)采用最小平方损失函数(least squares loss function)。我们也表明 LSGAN 的最小化目标函数(bjective function)服从最小化 Pearson X^2 divergence。LSGAN 比常规生成对抗网络有两个好处。首先 LSGAN 能够比常规生成对抗网络生成更加高质量的图片。其次 LSGAN 在学习过程中更加地稳定。我们在五个事件数据集(scene datasets)和实验结果上进行评估,结果证明由 LSGAN 生成的图像看起来比由常规 GAN 生成的图像更加真实一些。我们还对 LSGAN 和常规 GAN 进行了两个比较实验,其证明了 LSGAN 的稳定性。