RBM and NADE TO Collaborative Filtering
RBM and NADE TO Collaborative Filtering
最近在看深度学习在推荐算法上应用,本篇是hulu公司同事的ICML的文章A Neural Autoregressive Approach to Collaborative Filtering,介绍了利用NADE进行电影推荐的方法,在NETFX的数据集上取得了不错的结果,本文主要是学习和记录笔记,学习NADE-CF,并记录所涉及的一些算法,供后续查看方便。
RBM
RBM主要参考受限波尔兹曼机简介-张春霞,同时也参考核复制了博客的很多内容 深度学习读书笔记之RBM(限制波尔兹曼机)。在这里主要简介RBM涉及的几个计算公式,方便后边实现的理解。
能量函数
能量函数。随机神经网络是根植于统计力学的。受统计力学中能量泛函的启发,引入了能量函数。能量函数是描述整个系统状态的一种测度。系统越有序或者概率分布越集中,系统的能量越小。反之,系统越无序或者概率分布越趋于均匀分布,则系统的能量越大。能量函数的最小值,对应于系统的最稳定状态。
其中, ai 和 bj 为偏置, vi 为可见层, hj 为隐藏层。
似然函数
有了能量函数,定义可视节点和隐藏层的联合概率分布。
由联合概率可以得到观测数据 v 的概率分布 p(v|θ) ,也成为似然函数
同理,可以获得每个节点的激发函数,RBN层内节点不连接,同一层各节点独立分布。
对比散度RBM参数训练
学习RBM的任务是求出参数 θ 的值, 以拟合给定的训练数据。 参数 θ 可以通过最大
化RBM在训练集昨假设包含T个样本昩上的对数似然函数学习得到, 即
Hiton提出了RBM的一个快速学习算法, 即对比散度(Contrastive Divergence)。与吉布斯采样不同, CD指出当使用训练数据初始化 v0 时, 我们仅需要使用k步吉布斯采样便可以得到足够好的近似。在CD算法一开始, 可见单元的状态被设置成一个训练样本,并利用式 p(h|v,θ) 计算所有隐层单元的二值状态。在所有隐层单元的状态确定之后,来确定第i个可见单元 vi 取值为1的概率,进而产生可见层的一个重构。
- 输入:一个训练样本 m0 ,隐层单元个数 m ,学习率$$,最大训练周期$T$.
- 输出:连接权重矩阵W、可见层的偏置向量a、隐层的偏置向量b.
- 训练阶段:
- 初始化可见层单元的初始状态 v1=x0;Wa 和b为随机的较小数值。
- For t=1,2…T
- For j=1,2..m(对所有隐层单元)
- 计算隐层节点分布 p(h1j=1|v1) , p(h1j=1|v1)=σ(bj+∑iv1iWij)
- 计算隐层节点 h1j ,从条件 p(h1j=1|v1) 中抽样 h1j=0,1 ,具体 h1j=p(h1j=1|v1)>Rand(numHidden+1)?1:0
- EndFor
- For i=1,2,….,n(对所有可见层单元)
- 计算 p(v2i=1|h1) , p(v2i=1|h1)=σ(ai+∑jhjWij)
- 计算节点 v1i ,从条件 p(v1j=1|h1) 中抽样 v1i=0,1 ,具体 v1i=p(v1i=1|h1) (参考下文中代码实现)
- EndFor
- For 1,2,…,m(对所有隐层单元)
- 计算隐层节点分布 p(h2j=1|v2) , p(h2j=1|v2)=σ(bj+∑iv2iWij)
- EndFor
- 参数更新(根据上文的导数可以求得)
- W=W+(p(h1=1|v1)vT1−p(h2=1|v2))vT2
- a=a+(v1−v2)
- b=b+(p(h1=1|v1)−p(h2=1|v2))
python code 参考训练过程
def train(self, data, max_epochs = 1000):
"""
Train the machine.
Parameters
----------
data: A matrix where each row is a training example consisting of the states of visible units.
"""
num_examples = data.shape[0]
# Insert bias units of 1 into the first column.
data = np.insert(data, 0, 1, axis = 1)
for epoch in range(max_epochs):
# Clamp to the data and sample from the hidden units.
# (This is the "positive CD phase", aka the reality phase.)
pos_hidden_activations = np.dot(data, self.weights)
pos_hidden_probs = self._logistic(pos_hidden_activations)
pos_hidden_states = pos_hidden_probs > np.random.rand(num_examples, self.num_hidden + 1)
# Note that we're using the activation *probabilities* of the hidden states, not the hidden states
# themselves, when computing associations. We could also use the states; see section 3 of Hinton's
# "A Practical Guide to Training Restricted Boltzmann Machines" for more.
pos_associations = np.dot(data.T, pos_hidden_probs)
# Reconstruct the visible units and sample again from the hidden units.
# (This is the "negative CD phase", aka the daydreaming phase.)
neg_visible_activations = np.dot(pos_hidden_states, self.weights.T)
neg_visible_probs = self._logistic(neg_visible_activations)
neg_visible_probs[:,0] = 1 # Fix the bias unit.
neg_hidden_activations = np.dot(neg_visible_probs, self.weights)
neg_hidden_probs = self._logistic(neg_hidden_activations)
# Note, again, that we're using the activation *probabilities* when computing associations, not the states
# themselves.
neg_associations = np.dot(neg_visible_probs.T, neg_hidden_probs)
# Update weights.
self.weights += self.learning_rate * ((pos_associations - neg_associations) / num_examples)
error = np.sum((data - neg_visible_probs) ** 2)
print("Epoch %s: error is %s" % (epoch, error))如果详细的了解过程,可以看一下github上代码Restricted Boltzmann Machines in Python
RBM-CF
有了以上对RBM的介绍和认识,接下来的RBM-CF的原理就很好理解了。Restricted Boltzmann Machines in Python是Hinton大牛在2007ICML上提出的,在netfext上也取得了不错的效果。下面就详细的介绍一下算法。

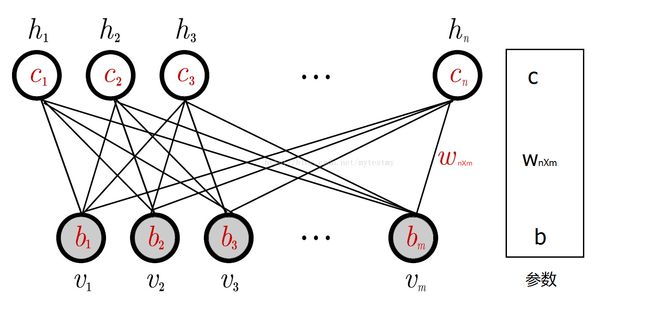
如图所示,RBM-CF是一个标准的RBM。其中V是用户对电影的评分(如图是5个级别).可见层为用户对电影的评分向量,隐层为隐向量。
能量函数和似然函数
其中, Zi=∑kl=1exp(bli+∑jhjWwij)
对应的似然函数:
有了以上的定义,可以获得隐层和可见层的分布:
Conditional RBM’s
其实在NetFlix的数据中,用户对电影的评分是比较稀疏。有大量的用户观看了电影没有评分,因此作者为了将此类信息加入到模型中,增加模型对用户评分的准确性。如图,将用户的观看列表信息加入到隐层中。

原先每个隐层的分布变为:
由于参数D与可见层无关,可以作为和b偏置一样的功能,参数更新也一样。
NADE
NADE是Hugo Larochelle在2011年提出,论文The Neural Autoregressive Distribution Estimator。具体引入NADE的原因还不是特别懂,看论文
We describe a new approach for modeling the distribution of high-dimensional vectors of discrete variables. This model is inspired by the restricted Boltzmann machine (RBM), which has been shown to be a powerful model of such distributions. However, an RBM typically does not provide a tractable distribution estimator, since evaluating the probability it assigns to some given observation requires the computation of the so-called partition function, which itself is intractable for RBMs of even moderate size.
可见层分布
将RBM贝叶斯网络化,v为可见层节点, vparent(i) 可以理解为 vi 的网络中的隐层节点。那么可见层的分布为:
现在有两种表征 p(vi|vparents(i)) 的方式,分别为FVSBM和NADE.

FVSBM
NADE
以上是NADE的可见层的分布公式,下面是求解流程:
- #计算p(v)
- a=c
- p(v)=0
- For i=1,2,…,D:
- hi=sigm(a)
- p(vi=1|v<i)=simg(bi+Vi.hi)
- p(v)=p(v)(p(vi=1|v<i)vi+(1−p(vi=1|v<i)1−vi))
- a=a+W.,ivi
- EndFor
- 计算梯度-log(p(v))
- δa=0
- δc=0
- For i,2,…,D:
- δbi=p(vi=1|v<i)−vi
- δVi=(p(vi=1|v<i)−vi)hTi
- δhi=(p(vi=1|v<i)−vi)VTi
- δc=δc+(δhi)hi(1−hi)
- δW,i=(δa)vi
- δa=δa+(δhi)hi(1−hi)
- EndFor
- 参数更新
NADE-CF
在以上铺垫后,就是讲应用加入到模型就行了。先定义一些参数 ru=rumo1,rumo2,..,rumoD 为用户的评分序列, rumoi 为用户的评分,在1-k之间。
另外,若写成每个用户对每个电影在评分K上的分布:
目标函数
参数共享