YOLOv2 论文学习
YOLO9000: Better, Faster, Stronger
- Abstract
- 1. Introduction
- 2. Better
- 1) Batch Normalization
- 2) High Resolution Classifier
- 3) Convolutional With Anchor Boxes
- 4) Dimension Clusters
- 5) Direct location prediction
- 6) Fine-Grained Features
- 7) Multi-scale training
- 3. Faster
- 1) Darknet-19
- 2) Training for classification
- 3) Training for detection
- 4. Stronger
- 1) Hierarchical classification
- 2) Dataset combination with WordTree
- 3) Joint classification and detection
- 5. Conclusion
论文地址: https://arxiv.org/abs/1612.08242
代码地址: http://pjreddie.com/yolo9000/
YOLO9000是CVPR2017的最佳论文提名。首先讲一下这篇文章一共介绍了YOLO v2和YOLO9000两个模型,二者略有不同。前者主要是YOLO的升级版,后者的主要检测网络也是YOLOv2,同时对数据集做了融合,使得模型可以检测9000多类物体。而提出YOLO9000的原因主要是目前检测的数据集数据量较小,因此利用数量较大的分类数据集来帮助训练检测模型。
接下来基本上按照文章的顺序来解读一下算法,这样读起来也比较清晰。主要包括三个部分:Better,Faster,Stronger,其中前面两部分基本上讲的是YOLO v2,最后一部分讲的是YOLO9000。
Abstract
YOLO9000是一个全新的实时目标检测系统,可以识别超过9000个物体种类。首先,作者对YOLO检测方法做了多方面的改进,得到了YOLOv2。利用新颖的,多尺度训练方法,同样的YOLOv2模型可以运行在不同大小的输入图片上,在速度和精度之间容易权衡。在67帧每秒时,YOLOv2在VOC2007上的精度是76.8。在40帧每秒时,YOLOv2的精度是78.6,超过了主流的方法如Faster R-CNN和SSD,而且速度更快。最后,作者提出了结合地训练目标检测和分类的方法。使用此方法,作者在COCO检测数据集和ImageNet分类数据集上同步训练YOLO9000。这种结合的训练允许YOLO9000去预测那些没有标注检测数据的类别。作者在ImageNet检测任务上进行了验证。YOLO9000 在ImageNet检测验证集上得到了19.7的mAP,尽管只有200个类别中44个类的数据。在不属于COCO的156个类别上,YOLO9000得到的mAP是16.0。YOLO9000可以预测超过9000个不同类别的物体,而且是实时的。
1. Introduction
目标检测的通用目标是快速,准确,能够识别各种类的物体。自从神经网络的进入,检测框架变得越来越精准而迅速。但是,绝大多数的检测方法仍然受限于有限集合内的物体。
当前的目标检测数据集与分类和标注任务的数据集相比,仍很有限。最常用的检测数据集包含几千到几十万张图像,有几十到上百个标签。分类数据集有几百万的图片,以及几十个或几百上千个的类别。
我们想把检测任务放大到物体分类的程度。但是,检测任务的数据与分类或标注任务相比,成本要高很多。因此在近期,检测数据集与分类数据集不太可能达到规模一样。

作者提出一个新的方法来驾驭已有的大量的分类数据,然后把它扩展到现在的目标检测系统中去。此方法使用了目标分类的层次视角,允许我们结合不同的数据集。
作者同样提出了**共同训练(jointly training)**的算法,允许我们在检测和分类数据上训练目标检测器。此方法利用标注好的检测图像来学习精准定位物体,同时它利用分类图片来增加它的鲁棒性和“词汇量”。
作者使用此方法来训练YOLO9000。首先,作者在base YOLO检测系统基础上做改进,有了YOLOv2。然后使用数据集结合方法和共同训练算法,在ImageNet超过9000个类别以及COCO检测数据上训练模型。
2. Better
YOLO和当前主流的检测系统比较,有一些缺陷。(1)与Fast R-CNN比,YOLO犯了大量定位的错误。而且,(2)YOLO的recall与region proposal-based 方法相比较低。因此,此论文聚焦于如何在保持分类准确率的同时,提升recall和定位准确度上。
计算机视觉通常倾向于使用更大,更深的网络。更好的性能一般依赖于训练更大的网络,或者将若干个模型集成训练。但是,作者希望YOLOv2精度更高,也能速度更快。作者不是增大网络结构,而是简化网络,让特征更容易学习。
1) Batch Normalization
BN能有效地提升收敛,而不需要其他形式的正则化。在YOLO所有的卷积层后增加一个BN,可以提升 2 % 2\% 2%的mAP。有了BN,我们能去除模型中的dropout操作,而不需担心过拟合问题。
2) High Resolution Classifier
所有主流的检测方法都有用在ImageNet上预训练的分类器。从AlexNet上开始,绝大多数的分类器都操作在小于 256 × 256 256\times 256 256×256的图像上。原生YOLO在 224 × 224 224\times 224 224×224的图像上训练分类器网络,检测时增加到 448 448 448分辨率。网络需要同时转换至学习目标检测,以及调整至新的输入分辨率。
对于YOLOv2,首先在 448 × 448 448\times 448 448×448分辨率的ImageNet上微调分类网络,10个epochs。这给了网络时间来调整它的滤波器,以在更高分辨率的输入上运行。然后在检测数据上微调此输出网络。这个高分辨率的分类网络能提升mAP有 4 % 4\% 4%mAP。
3) Convolutional With Anchor Boxes
YOLO直接使用全连接层来预测边框的位置。Faster R-CNN中的RPN(region proposal networks)只使用了卷积层来预测anchor box的位置偏移和置信度。因为预测层是卷积的,RPN就可以在特征图的每个位置上预测偏移。预测偏移而非坐标位置简化了问题,让模型学习起来变得容易。
作者移除了YOLO中的全连接层,使用anchor boxes来预测边框。首先,去除池化层,让网络卷积层的输出分辨率更高。作者也将输入图像的大小由 448 × 448 448\times 448 448×448收缩为 416 416 416。这样做,因为作者希望在特征图上有奇数个位置,这样就只有一个中心cell。为什么要奇数个位置呢?因为物体(尤其是大的物体)倾向于占据图像的中心位置,所以最好有一个单独的正中心位置来预测这些物体,而不是其相邻的四个位置。YOLO的卷积层对图片通过大小是32的系数来进行下采样。因此,416的输入图片会输出一个 13 × 13 13\times 13 13×13的特征图。
选择了anchor boxes,我们也要从空间位置中解耦出类别预测机制(class prediction mechanism),对每个anchor box预测类别和是否包含物体(objectness)。Objectness预测和YOLO一样,预测候选框和真实边框的IOU;类别预测假定物体存在,它属于哪一类别的条件概率。
使用anchor boxes,精度上有些许下降。YOLO在每张图片上只预测98个边框,但是对于anchor boxes,我们的模型要预测上千个。如果没有anchor boxes,模型的精度有69.5,recall是 88 % 88\% 88%。加进了anchor boxes,模型的mAP是69.2,recall是 88 % 88\% 88%。
4) Dimension Clusters
在YOLO上使用anchor boxes作者遇到了2个问题。第一个是box维度是按经验选择的。网络能够自己学习boxes的尺寸,但是如果我们能提前找到一个适合的尺寸,模型就能学习预测出更好的结果。所以作者采用k-means的方式对训练集的bounding boxes做聚类,试图找到合适的anchor box。
与按经验选择box的尺寸不同,作者在训练集上通过k-means clustering 来自动找到适合的尺寸。如果我们使用标准的欧氏距离的k-means,较大的box会比较小的box产生更多的错误。通过IOU定义了如下的距离函数,使得误差和box的大小无关:
d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) d(box, centroid) = 1- IOU(box, centroid) d(box,centroid)=1−IOU(box,centroid)
如下图2,左边是聚类的clusters个数和IOU的关系,两条曲线分别代表两个不同的数据集。在分析了聚类的结果并平衡了模型复杂度与recall值,作者选择了 k = 5 k=5 k=5,这也就是图2中右边的示意图是选出来的5个box的大小,这里紫色和黑色也是分别表示两个不同的数据集,可以看出其基本形状是类似的。

表1中作者采用的5种anchor(Cluster IOU)的Avg IOU是61,而采用9种Anchor Boxes的 Faster R-CNN 的Avg IOU是60.9,也就是说本文仅选取5种box就能达到Faster R-CNN的9种box的效果。

5) Direct location prediction
在YOLO中使用anchor boxes,会遇到第二个问题:模型不稳定性,尤其是在训练早期时。绝大多数的不稳定性来自于预测边框的位置 ( x , y ) (x,y) (x,y)。在RPN(region proposal network)中,网络预测 t x t_x tx的值和 t y t_y ty的值, ( x , y ) (x,y) (x,y)中心位置计算如下:
x = ( t x × w a ) − x a x=(t_x \times w_a)-x_a x=(tx×wa)−xa
y = ( t y × h a ) − y a y=(t_y \times h_a)-y_a y=(ty×ha)−ya
这里 x a x_a xa和 y a y_a ya是anchor的坐标, w a w_a wa和 h a h_a ha是anchor的size, x x x和 y y y是坐标的预测值, t x t_x tx和 t y t_y ty是偏移量。例如,当 t x = 1 t_x=1 tx=1,会把box向右移anchor box的宽度距离, t x = − 1 t_x=-1 tx=−1会把box向左移anchor box的宽度距离。
这个公式不受约束,所以任意的anchor box可以移动到图像中的任何位置。由于随机初始化,模型需要很长的时间来稳定下来,预测出有效的偏移。
作者延续YOLO的方法,相对于网格的坐标来预测box的位置。作者使用了Sigmoid 激活函数将网络的预测值落在0和1之间,这样的归一化处理也使得模型训练更加稳定。
网络在特征图的每个网格上预测5个boxes。网络对每个边框预测5个坐标, t x , t y , t w , t h , t o t_x,t_y,t_w,t_h,t_o tx,ty,tw,th,to。如果网格相对于图片的左上角坐标是 ( c x , c y ) (c_x, c_y) (cx,cy),边框的宽度和高度是 p w , p h p_w,p_h pw,ph, σ ( x ) \sigma(x) σ(x)是Sigmoid激活函数,则预测的box如下:
b x = σ ( t x ) + c x b_x = \sigma(t_x) + c_x bx=σ(tx)+cx
b y = σ ( t y ) + c y b_y = \sigma(t_y) + c_y by=σ(ty)+cy
b w = p w e t w b_w = p_w e^{t_w} bw=pwetw
b h = p h e t h b_h = p_h e^{t_h} bh=pheth
P r ( o b j e c t ) × I O U ( b , o b j e c t ) = σ ( t o ) Pr(object) \times IOU(b, object) = \sigma(t_o) Pr(object)×IOU(b,object)=σ(to)
如果对上面的公式不理解,可以看图3,首先是 c x c_x cx和 c y c_y cy,表示网格与图像左上角的横纵坐标距离,黑色虚线框是边界框,蓝色矩形框就是预测的结果。

我们限制了位置预测的值,参数学习起来更简单,网络也就更稳定。相较于使用anchor boxes的版本,使用维度聚类和预测边框的中心位置的方法可以提升YOLO的mAP 5 % 5\% 5%。
6) Fine-Grained Features
这个层的作用就是将前面一层的 26 × 26 26\times 26 26×26的feature map和本层的 13 × 13 13\times 13 13×13的特征图进行连接,有点像ResNet。这样做的原因在于虽然 13 × 13 13\times 13 13×13的特征图对于预测大的物体已经足够了,但是对于预测小的物体就不一定有效。也容易理解,越小的物体,经过层层的卷积和池化,可能到最后都不见了,所以通过合并前一层的size大一点的特征图,可以有效检测小的物体。
Passthrough层将较高分辨率的特征与较低分辨率的特征连接(concatenate)起来,通过在不同的通道内把毗邻的特征摞起来(stack),这与ResNet中的identity mapping一样。它将 26 × 26 × 512 26\times 26\times 512 26×26×512的特征图变为 13 × 13 × 2048 13\times 13\times 2048 13×13×2048的特征图,它就能和原始输入图像concatenate起来。检测器就在这个特征图上运行,它就能获取高质量的特征。这能提升 1 % 1\% 1%的性能。
7) Multi-scale training
原来的YOLO输入大小是 448 × 448. 448\times 448. 448×448. 增加了anchor boxes后,分辨率改为 416 × 416 416\times 416 416×416。但是,因为模型中有卷积核池化层,它能很快地重新设定大小。我们希望YOLOv2在不同大小的图片上运行具有鲁棒性,因此也在YOLOv2中加入了这个特性。
作者每隔几个迭代就会变动图像的输入大小。每10个batches,网络随机选择新的图片维度。因为模型以factor 32来进行下采样,我们从32的倍数中作选择: 320 , 352 , ⋯ , 608 {320,352,\cdots,608} 320,352,⋯,608。因此最小的输入尺寸是 320 × 320 320\times 320 320×320,最大的输入尺寸是 608 × 608 608\times 608 608×608。重新调整网络的维度,然后继续训练。
这种策略使得网络能在不同的分辨率的图像上做出detection。同一个网络能预测不同分辨率上的物体。它在较小的输入上运行的更快,因此YOLOv2很容易地权衡了速度和精度。
在低分辨率图像上,YOLOv2操作一个成本低,相对准确的检测器。在 228 × 228 228\times 228 228×228的图像上,它运行的速度是90帧每秒,精度可以与Fast R-CNN媲美。所以它对小型GPU和高帧速率的视频很完美。
在高分辨率图像上,YOLOv2在VOC2007上的mAP有78.6,达到实时的速度。



Further experiments 作者在VOC2012上训练YOLOv2检测。YOLOv2的mAP是73.4,而且跑的比其它模型更快。

总的看下这些技巧对mAP的贡献:

3. Faster
大多数的检测应用,如机器人或自动驾驶汽车,依赖于低延迟预测。为了最大化性能,作者设计了YOLOv2。大多数的检测框架依赖于VGG16作为基础的特征提取器。VGG16在分类任务上很强大且准确,但是太复杂。对于一张大小是 224 × 224 224\times 224 224×224的图片,单次通过VGG16中的卷积层需要306.9亿个浮点计算。
YOLO框架基于GoogLeNet使用了一个传统的网络。此网络比VGG16更快,对于单次前向传播只用85.2亿次的浮点计算。但是,精度比起VGG16要差一些。在 224 × 224 224\times 224 224×224的图片上,YOLO的top-5准确率为 88 % 88\% 88%,而VGG16为 90 % 90\% 90%。
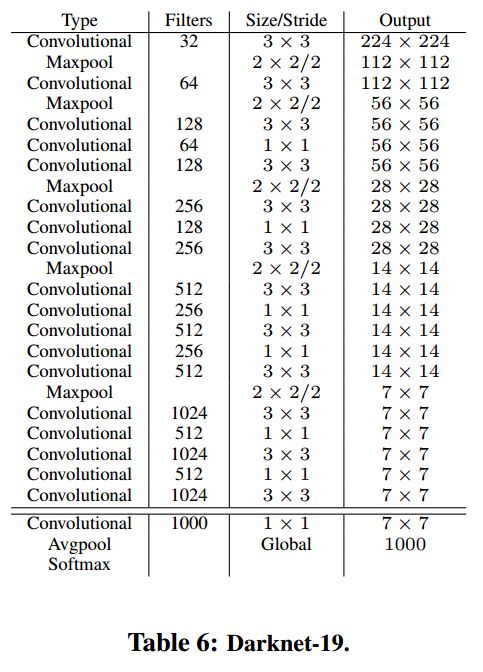
1) Darknet-19
作者提出了一个新的分类模型用于YOLOv2。与VGG类似,作者使用 3 × 3 3\times 3 3×3的滤波器,在每个池化操作后将通道数加一倍。使用全局average pooling做预测,在 3 × 3 3\times 3 3×3的卷积中间使用 1 × 1 1\times 1 1×1的滤波器来压缩特征图。作者也使用了batch normalization来稳住训练,加速收敛,以及正则化模型。
最后这个模型称作Darknet-19,它有19个卷积层,5个 maxpooling层。它对于一张图片输入,只有55.8亿次浮点计算,在ImageNet上它的top-1准确率达到 72.9 % 72.9\% 72.9%,top-5准确率有 91.2 % 91.2\% 91.2%。
2) Training for classification
这里的training for classification都是在ImageNet上进行预训练,主要分两步:
-
从头开始训练Darknet-19,数据集是ImageNet,训练160个epoch,输入图像的大小是224*224,初始学习率为0.1。另外在训练的时候采用了标准的数据增加方式比如随机裁剪,旋转以及色度,亮度的调整等。
-
在一个更大的图像尺寸 448 × 448 448\times 448 448×448上进行微调。它只跑了10个epochs,初始学习率设为 1 0 − 3 10^{-3} 10−3。由此获得的top-1精度是 76.5 % 76.5\% 76.5%,top-5准确率为 93.3 % 93.3\% 93.3%。
3) Training for detection
在前面第2步之后,就开始把网络移植到detection,并开始基于检测的数据再进行fine-tuning。
首先,去除了最后一个卷积层,增加3个 3 × 3 3\times 3 3×3卷积层,每个卷积层有1024个filters,每个卷积层后又跟着1个 1 × 1 1\times 1 1×1的卷积层。对于VOC,预测5个boxes,每个box有5个坐标和20个类别,所以一共需要125个filter。(与YOLOv1不同,在YOLOv1中每个grid cell有30个filters,还记得那个 7 × 7 × 30 7\times 7\times 30 7×7×30的矩阵吗,而且在YOLOv1中,类别概率是由grid cell来预测的,也就是说一个grid cell对应的两个boxes的类别概率是一样的,但是在YOLOv2中,类别概率是属于box的,每个box对应一个类别概率,而不是由grid cell决定,因此这边每个box对应25个预测值(5个坐标加20个类别值),而在YOLOv1中一个grid cell的两个box的20个类别值是一样的)。
作者同样在最后一个 3 × 3 × 512 3\times 3\times 512 3×3×512层和倒数第二个卷积层中间增加了一个passthrough层,这样我们的模型就可以使用高质量的特征。作者训练这个模型160个epochs,初始学习率是 1 0 − 3 10^{-3} 10−3,在第60和第90个epoch时学习率除以10。Weight decay设为0.0005,momentum设为0.9。使用了与YOLO和SSD类似的数据增强方法,以及与COCO和VOC一样的训练策略。
4. Stronger
作者提出了在分类和检测数据上共同训练(jointly training)的机制。此方法使用标注检测的数据来学习检测相关的信息,如边框位置预测和objectness。使用标注类别的数据来扩展它可以检测的类别数量。
在训练中,作者将检测和分类数据集混合使用。当网络得到一个标注检测的图像时,使用完整的YOLOv2损失函数来反向传播。当它得到一个分类图像时,就只使用损失函数中与类别相关的部分来反向传播。
这个方法有一些挑战。检测数据集只有一般的物体和类别,如狗和船等。分类数据集的类别则更广一些,ImageNet有超过100种的狗,包括“Norfolk terrier”, “Yorkshireterrier”, 和 “Bedlington terrier”。所以我们需要一个连贯的方法来结合这些标签。
大多数的分类方法都使用跨所有类别的softmax层来计算最后的概率分布。使用softmax的前提是这些类别都是互斥的。这就给结合数据集带来了麻烦,因为"Norfolk terrier"和狗是不互斥的。
作者因此使用了一个multi-label的模型来结合这些并不互斥的数据集。
1) Hierarchical classification
ImageNet标签是从WordNet中提取的(一个结构化概念和关系的语言数据集。)在WordNet中,"Norfolk terrier"和"Yorkshire terrier"都是"terrier"的下义词(hyponym),是猎犬的一种,也是狗的一种,也是犬类的一种。大多数的分类方法都假设标签是flat的结构,但是为了结合不同的数据集,我们需要一种结构化。
WordNet是有向图的结构,不是树,因为语言是复杂的。例如狗既是一种犬,也是一种家养动物,都是WordNet的同义词集合。作者通过构建一个层级树(hierarchical tree)来简化问题。
为了构建这个tree,作者检查了ImageNet中的视觉名词,观察它们在WordNet图中通往root node (physical object)的路径。许多同义词集合在图中只有一条路径,所以作者把这些路径加入到tree中。然后迭代式地检查剩下的concepts,添加路径,逐渐让tree变大。如果一个concept有两个路径去往root node,我们选择较短的那条路径。
最终的结果就是WordTree,它是一个视觉concepts的层级模型(hierarchical model)。为了在WordTree中分类,在每个node中预测同义词集合内的每个下义词的条件概率。例如,在"terrier" node处,预测:
P r ( N o r f o l k t e r r i e r ∣ t e r r i e r ) Pr(Norfolk terrier | terrier) Pr(Norfolkterrier∣terrier)
P r ( Y o r k s h i r e t e r r i e r ∣ t e r r i e r ) Pr(Yorkshire terrier | terrier) Pr(Yorkshireterrier∣terrier)
P r ( B e d l i n g t o n t e r r i e r ∣ t e r r i e r ) Pr(Bedlington terrier | terrier) Pr(Bedlingtonterrier∣terrier)
⋯ \cdots ⋯
如果我们想计算某node种的绝对概率值,我们只需要沿着通向root node的路径,然后将各条件概率乘起来。如果我们想知道是否一个图片是Norfolk terrier,计算:
P r ( N o r f o l k t e r r i e r ) = P r ( N o r f o l k t e r r i e r ∣ t e r r i e r ) Pr(Norfolk terrier) = Pr(Norfolk terrier | terrier) Pr(Norfolkterrier)=Pr(Norfolkterrier∣terrier)
× P r ( t e r r i e r ∣ h u n t i n g d o g ) \times Pr(terrier | hunting dog) ×Pr(terrier∣huntingdog)
× ⋯ × \times \cdots \times ×⋯×
× P r ( m a m m a l ∣ P r ( a n i m a l ) × P r ( a n i m a l ∣ p h y s i c a l o b j e c t ) ) \times Pr(mammal | Pr(animal) \times Pr(animal | physical object)) ×Pr(mammal∣Pr(animal)×Pr(animal∣physicalobject))
对于分类目的,我们假设图像包含一个物体: P r ( p h y s i c a l o b j e c t ) = 1 Pr(physical object) = 1 Pr(physicalobject)=1。
为了验证此方法,作者在WordTree上训练了Darknet-19模型,WordTree使用了ImageNet中1000各类别来构建。为了构建WordTree1k,作者把所有的intermediate nodes都加进去,把label space从1000扩展到了1369。这样,如果一张图片标注了"Norfolk terrier",则它也被标注为狗和哺乳动物等。为了计算条件概率,计算所有同义词集合的softmax。

使用同样的训练参数,Hierarchical Darknet-19获得的top-1准确率为 71.9 % 71.9\% 71.9%,top-5准确率为 90.4 % 90.4\% 90.4%。遇见新的类别或没见过的物体种类时,模型的表现会下降一些。比如,网络得到了一张狗的图片,但是不知道它是哪种狗,它仍然会预测出狗的种类,但是预测出狗具体类别的置信度会降低。
这个方法对检测同样适用。我们可以用YOLOv2的objectness检测器来预测 P r ( p h y s i c a l o b j e c t ) Pr(physical object) Pr(physicalobject)。检测器预测一个边框和概率tree。我们遍历这个tree,在每个split采用最高置信度的路径,直到达到了某个阈值。
2) Dataset combination with WordTree
我们可以用WordTree来结合多个数据集。只需要将数据集的类别映射到tree的同义词集合中去。WordNet非常多样化,可以用于大多数数据集。

3) Joint classification and detection
我们想要在一个特别大规模的检测器,所以作者把COCO检测数据集和ImageNet中前9000个类别的数据结合起来,得到了一个新的数据集。这个数据集的WordTree有9418个类别。ImageNet特别大,所以作者平衡了数据集,所以ImageNet和COCO的数量比是4:1。
利用这个数据集训练YOLO9000。基础的YOLOv2结构只用了3个clusters,而不是5个,这可以限制输出的大小。如果网络得到了一个检测图像,正常地进行反向传播。对于分类损失部分,只反向传播损失部分给对应的标签层级。
当它得到一个分类图像时,只反向传播分类损失部分。我们只需找到对该类别预测概率最高的边框,只需在预测的tree上计算损失就行了。作者同样假设,预测框与真实框重叠部分至少等于0.3 IOU,基于此假设进行objectness的反向传播。
利用Joint training,YOLO9000使用COCO中的检测数据来学习找到图像中的物体,使用ImageNet中的数据来学习分类图像中的物体。
5. Conclusion
Pls read paper for more details.