Oracle数据库重点笔记
1.与ORACLE相关的数据库
MySql 小型数据库 (免费,开源)
Sqlserver 中大型数据库
Oracle 大型数据库
Db2(IBM公司)
2.开启Oracle服务
数据库的启动3个状态:
1:NOMOUNT 只打开数据库实例
2:MOUNT 打开实例并读取控制文件
3:OPEN 打开数据库
按123顺序启动
数据库的关闭3个状态:
1:CLOSE 关闭数据库
2:DISMOUNT
3:SHUTDOWN 关闭数据库实例
进入SQL Plus进入Oracle的cmd界面
数据库实例的开启:启动实例,加载数据库,打开数据库
数据库实例的启动与关闭 只有sys用户才有权限
3.Oracle默认账户
准备工作:学习Oracle首先就是安装环境。我装的是oracle11g
安装完成之后在dos窗口中,输入 sqlplus 再输入用户名和密码即可登录
Sys/change_on_install 系统管理员 拥有最高权限(相当于root)
System/manager本地管理员,次高权限
Scott/tiger普通用户,用于学习,默认未解锁
1)普通用户切换:
conn 用户名/密码;
2)sys用户切换:
conn 用户名/密码 as sysdba;
3)显示当前用户:
show user;
4.SQL分类
DDL :数据库定义语言 create alter drop rename truncate
DML:数据库操作语言:select insert update delete
DCL:数据库控制语言:grant revoke
TCL事务控制语言:commit rollback savepoint 等。
5.Oracle常用命令
---------------------------------SQL语句--------------------------------------------------------
1.Oracle查询语句和MYSQL语句是几乎一样的:
注:1.字符串连接使用 ||
2.distinct 消除重复那内容
3.表内容区分大小写
4.order by desc 降序(默认为升序:asc )
2.SQL常用运算符:(优先级由高到地)
算数运算符:+ - * /
连接运算符:||
比较运算符:= != 或(<>) < > <+ >+ ANY ALL
逻辑运算符:and or not
3.SQL操作符:
1.in(值1,值2)
2.like : % _
3.between 值1 and 值 2
4.is null (判断是否为null时,不能用=来判断)
5.is NAN (NAN表示非数字)
注:这些操作符都可以和not 搭配
----------------------------------------SQL示例-----------------------------------------------------------------------
1. Scott用户表的说明

2.最基本的一些操作:
查询员工表
select * from scott.emp;(注意分号)
查询名字为SCOTT的员工信息
select * from scott.emp where ename = 'SCOTT';
查询员工scott创建的表
select * from scott.dept;
在员工表插入一个员工数据
insert into scott.emp(empno,ename) values(800,'OCEANMIX');
删除某个员工信息
delete from scott.emp where ename = 'OCEANMIX';
创建一个表(Oracle中没有自增列)
create table UserInfo(
id int primary key,
ename nvarchar2(64)
);
//向表中添加数据
insert into userinfo values(1,'oceanmix');
//删除表
drop table userinfo;
//修改员工某项数据
update scott.emp set sal ='5000' where ename = 'OCEANMIX';
//输入ed;创建表(decimal(3,2)表示总共3位,小数占据2位)
create table emp
(
id int primary key,
ename nvarchar2(64) default 'test',
money decimal(3,2)
)3. 查询的语法
语法说明:
<> :表示必须的
[]:表示可选。
select [distinct] *| <字段名> [as 别名] from <表名> [别名] [where <条件>]
示例:
--查询所有的员工信息
select * from emp;
--需求:查询员工的姓名,去重复
select distinct ename from emp;
--需求:查询员工的姓名,返回的字段名使用表的别名指定
select distinct a.ename from emp a;
--需求:查询员工的姓名,返回的字段名使用表的别名指定.将返回的字段修改为‘c’
select distinct a.ename as 员工姓名 from emp a;
二、条件查询
1、对比运算符
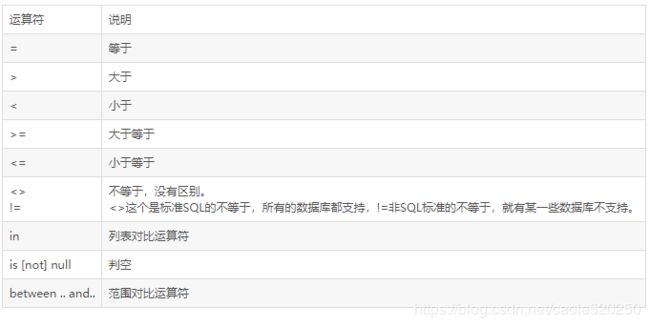
示例:
--需求:查询员工部门编号为10,或者20的员工。
select * from dept where deptno in (10,20);
--需求:查询员工的奖金不为null的员工。
select * from emp where COMM is not null;
--需求:查询员工的工资在1600和3000 之间的员工。包括上下限。
select * from emp where sal between 1600 and 3000;
select * from emp where sal>= 1600 and sal<=3000;
--需求:查询员工的入职时间在1981-9-28至1982-1-23的员工,包括上下限。
select * from emp where hiredate between to_date('1981-09-28','yyyy-mm-dd') and to_date('1982-01-23','yyyy-mm-dd');在该示例中涉及时间的转换,在后面会总结到.
2、逻辑运算符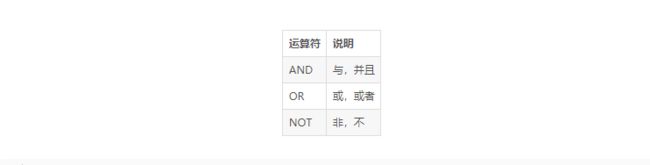
示例:
--逻辑运算符
--AND
--需求:查询员工的工资在1600和3000 之间的员工。不包括上下限。
select * from emp where sal > 1600 and sal<3000;
--OR
--需求:查询员工部门编号为10,或者20的员工。
select * from emp where deptno =10 or deptno=20;
--NOT
--需求:查询员工的工资不在1600和3000 之间的员工。包括上下限。
--1600以下
--3000以上
select * from emp where sal not between 1600 and 3000;
3、模糊查询
1、特殊字符
如果遇到,匹配的字符就是一个特殊字符,那么需要转义。
定义一个转义字符来实现,定义的转义符可以是任何字符,只是我们习惯使用\
_代表是匹配一个字符
%代表是匹配任何的字符
--模糊查询
--like
--需求:查询第三个字母为A,的员工
select * from emp where ename like '__A%';
--需求:查询名字有_的员工
select * from emp where ename like '%\_%' escape '\';
4、排序
关键字:desc 和 asc
--需求:根据工资的从高到低排序
select * from emp order by sal desc;
--需求:根据部门编号从低到高排序
select * from dept order by deptno asc;
--需求,按部门编号升序排序,然后每个部门按工资从高到低排序。
select * from emp order by deptno asc,sal desc;
三、函数
1、数值函数
数值函数,就是处理数值。
1)四舍五入函数round(p,s)
p:原值
s:精度,如果是正数,表示小数点后的位数,如果是0,表示忽略小数点后的位数,如果是负数,即使从右到左,精确正数部分。
--需求:统计所有员工的平均工资,保留四位小数,四舍五入
select round(avg(sal),4) from emp;
--需求:统计所有员工的平均工资,保留三位小数,四舍五入
select round(avg(sal),3) from emp;
--需求:统计所有员工的平均工资,保留到个位
select round(avg(sal),0) from emp;
--需求:统计所有员工的平均工资,保留到十位
select round(avg(sal),-1) from emp;
2)数值截取函数 trunc(p,s)
p:原值
s:精度,如果是正数,表示小数点后的位数,如果是0,表示忽略小数点后的位数,如果是负数,即使从右到左,精确正数部分。
--需求:统计所有员工的平均工资,保留四位小数
select trunc(avg(sal),4),avg(sal) from emp;
--需求:统计所有员工的平均工资,保留到十位
select round(avg(sal),-1) from emp;
2、字符函数
字符函数:就是处理字符
1)字符函数 length(p)
字符长度计算函数,p:表示原值
--需求:统计所有员工的平均工资,保留四位小数
select trunc(avg(sal),4),avg(sal) from emp;
--需求:统计所有员工的平均工资,保留到十位
select round(avg(sal),-1) from emp;p:原值
c1:需要替换的值(旧值)
c2:替换后的值(新值)
--需求:my name is itcast 修改 my 为 your
select replace('my name is liwei','my','your') from dual;
--如果c2没有值,表示直接删除c1的值
select replace('my name is liwei','my') from dual;
3)伪表:dual
在Oracle里面,查询都是使用select关键字的。而select关键字语法为:select 返回结果 from <表名>。
但是在查询一些情况是没有表的,查询函数,查询运算的结果,查询关键字。Oracle在查询这些没有表的数据时,使用一个临时表来存储。这个临时表就是伪表dual;
dual的作用就是查询没有表的数据时,用于维持select的语法的需要。
反正,没有表的数据查询时,统一使用dual
--如:查询7+8的结果
select 7+8 from dual;
--如:查询当前用户
select user from dual;
--如:查询当前的日期
select sysdate from dual;
3、日期时间函数
日期时间函数:就是处理日期时间的
1)日期函数
--如:查询当前的日期
select sysdate from dual;
2)月份增加函数 add_months(p,m)
p:原值
m:增加的月份数,如果是正数就是加,如果是负数就是减
--需求:计算当前日期的5个月后的日期
select add_months(sysdate,5) from dual;
--需求:计算当前日期的5个月前的日期
select add_months(sysdate,-5) from dual;
3)日期月份对比函数 months_between(d1,d2)
日期月份对比函数,返回两个日期的月份间隔
作用:
用于计算两个日期的月份区间 1)字符串转成日期 to_date(p,f) 将其他类型的值转成字符串 将当前日期转成字符串 p:原值 1)空处理函数 四、聚合函数 max() 五、分组查询 1、分组查询时什么 2、分组的作用 3.事务 事务的概念:事务是一组逻辑工作单元,它由一条或多条SQL语句组成。 事务的4个特性:原子性,一致性,隔离性和持久性 事务控制:commit,rollback
对比两个日期的大小
如果d1>d2,返回正数,如果 d1--需求:计算当前日期,和2017-01-14.的月份间隔
select months_between(sysdate,to_date('2017-01-14','YYYY-MM-DD') ) from dual;
4)日期时间提前函数
extract(year|month|day|hour|minute|seconnd from <日期>|<时间>)--需求:提前当前日期的年月日
--提取年
select extract(year from sysdate) from dual;
--提取月
select extract(month from sysdate) from dual;
--提取日
select extract(day from sysdate) from dual;
--提取时
--12小时制
select extract(hour from to_timestamp('2017-08-14 11:48:20','yyyy-mm-dd hh:mi:ss')) from dual;
--24小时制
select extract(hour from to_timestamp('2017-08-14 13:48:20','yyyy-mm-dd hh24:mi:ss')) from dual;
--提取分
select extract(minute from to_timestamp('2017-08-14 13:48:20','yyyy-mm-dd hh24:mi:ss')) from dual;
--提取秒
select extract(second from to_timestamp('2017-08-14 13:48:20','yyyy-mm-dd hh24:mi:ss')) from dual;
--oracle支持另种写法,不用to_timestamp函数,使用timestamp关键字
--提取秒
select extract(second from timestamp '2017-08-14 13:48:20') from dual;
4、转换函数
转换函数:就是实现类型的转成
p:原值
f:格式,年YYYY,月MM,日DD,时HH24,分MI,秒SSselect to_date('2017-08-14','YYYY-MM-DD') from dual;
2)字符串转时间 to_timestamp(p,f)
p:原值
f:格式,年YYYY,月MM,日DD,时HH24,分MI,秒SSselect to_timestamp('2017-08-14 13:11:30','YYYY-MM-DD HH24:MI:SS') from dual;
3)将其他类型的值转成字符串
to_char(p,f)
f:格式,年YYYY,月MM,日DD,时HH24,分MI,秒SS
select to_char(sysdate,'yyyy-mm-dd') from dual;
select to_char(sysdate,'yyyy/mm/dd') from dual;
4)将数值类型转成字符串 to_char(p,f)
p:原值
f:数值的占位符是9--需求:将8978767976,转为$8,978,767,976
select to_char(8978767976,'$9,999,999,999') from dual;
5、通用函数
通用函数:一些帮助函数,空处理
nvl(p,v1):如果p的值为null,就返回v1.
nvl2(p,v1,v2):如果p的值不为null,返回v1,为null返回v2;--需求:查询有奖金员工
--nvl
select comm,nvl(comm,0) from emp;
select * from emp where nvl(comm,0)<>0;
--nvl2
select comm,nvl2(comm,comm,0) from emp;
select * from emp where nvl2(comm,comm,0)<>0;
聚合函数:就是用于统计
min()
count()
sum()
avg()
所谓的多行函数就是聚合函数,非聚合函数的其他函数就是单行函数。
数据库是支持统计数据功能,统计包括了最大值,最小值,平均值,总数,总记录数
如果我们需要按某种字段分类后再统计呢?
我们将按某个字段分类称为分组。
分组的作用实现将某种字段分类,再统计这个类型的统计数据。--需求:统计员工工资的最大值,最小值,平均值,总数
select max(sal),min(sal),avg(sal),sum(sal) from emp;
--需求:按部门分组,求每个部门的最大工资和平均工资
select deptno,max(sal),avg(sal) from emp group by deptno;
--需求:按部门分组,求每个部门的最大工资和平均工资,平均工资在2000以上
--问题:使用where,还是having?
--答:因为平均工资是在分组后才可以获得,所以使用优先级别在group by后面的having来判断
--查询语句的关键字是有优先级别的
--from > where > group by >having > select > order by
select deptno,max(sal),avg(sal) from emp group by deptno having avg(sal)>2000;
--问题:如果判断的条件不需要分组就可以获得,使用where.
--为什么:如果在分组前就可以过滤掉这些数据,就可以查询时的效率。