利用矩阵奇异值分解(SVD)进行降维
一、SVD的优缺点及应用场合
- 1.优点:简化数据,去除噪声,提高算法的结果
- 2.缺点:数据的转换可能难以理解
- 3.适用场合:数值型数据
二、SVD算法主要用途
- SVD是矩阵分解的一种类型,而矩阵分解是将数据矩阵分解成多个独立部分的过程。
- 1.隐性语义分析LSA
- 最早的SVD应用之一是信息检索,称为利用SVD的方法为隐性语义分析。在LSA中,一个矩阵是由文档和词语组成的。当在此矩阵上应用SVD时,就会构建出多个奇异值,这些奇异值表示的是文档中的概念或主题,这一特点可以应用在更高的文档搜索中。
- 2.推荐系统
- SVD的另一个应用就是推荐系统。利用SVD从数据中构建一个主题空间,然后在该空间下计算其相似度。考虑下图中给出的矩阵,它是由菜品(列)和品菜师对这些菜的意见构成的(列)。品菜师可以采用1到5之间的任意一个整数对菜进行评价;如果品菜师没有尝过该菜,则评分为0。可以利用SVD将原先的5维/7维的矩阵降低到只有2维。
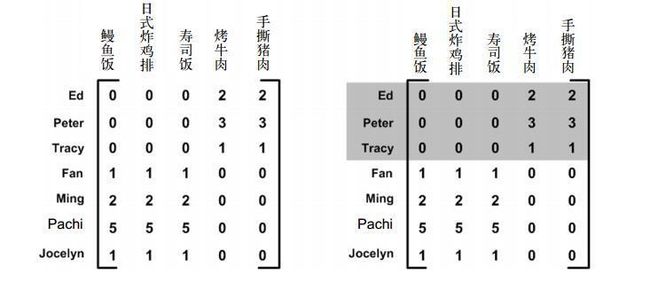
- SVD的另一个应用就是推荐系统。利用SVD从数据中构建一个主题空间,然后在该空间下计算其相似度。考虑下图中给出的矩阵,它是由菜品(列)和品菜师对这些菜的意见构成的(列)。品菜师可以采用1到5之间的任意一个整数对菜进行评价;如果品菜师没有尝过该菜,则评分为0。可以利用SVD将原先的5维/7维的矩阵降低到只有2维。
三、矩阵分解
- 矩阵分解就是将原始矩阵表示成新的易于处理的形式,这种新式是两个或多个矩阵的乘积。不同的矩阵分解技术具有不同的性质,其中有些更适合于某个应用,有些则更适合于其他的应用,最常见的矩阵分解技术是SVD,SVD将原始的数据集矩阵Data分解成三个矩阵U,Sigma,V.T。如果原始矩阵Data是m行n列,那个U,Sigma,V.T就分别是m*m,m*n,n*n, 如下面的公式所示:
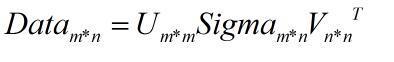
- 上面分解中会构建出一个矩阵Sigma,此矩阵只有对角元素,其他元素均为0.Sigma的对角元素一般是从大到小排列的。这些对角元素称为奇异值,它们对应了原始数据集矩阵Data的奇异值,设Data*Data.T矩阵的特征是是lambda,则奇异值就是sqrt(lambda)。
- 在实际工程中,存在一个现象。在某个奇异值的数目®个后,其他的奇异值都置为0。这意味着数据集中仅有r个重要的特征,而其余特征则都是噪声或冗余特征。如何知道仅保留前几个的奇异值?确定要保留的奇异值数量有很多启发式的策略。主要有两种:
- a.保留矩阵中90%的能量信息,为了计算总能量信息,将所有的奇异值求其平方和,于是可以将奇异值的平方累加到总值的90%为止。
- b.当矩阵中有很多的奇异值时,那么就保留前面的2000或3000个奇异值,在实际中更容易实现。
四、利用numpy求矩阵的奇异值SVD
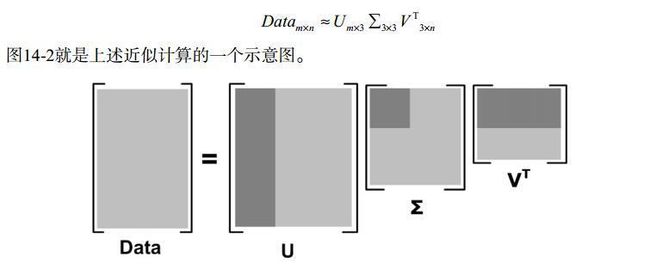
from numpy import *
from numpy import linalg as la
def loadDataSet():
return [[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[1, 1, 1, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1]]
dataMat = loadDataSet()
print("----------奇异值计算-----------")
U, Sigma, VT = la.svd(dataMat)
print("Sigma:\n", Sigma)
print("---------------重构原始矩阵dataMat------------")
Sigma3 = mat([[Sigma[0], 0, 0], [0, Sigma[1], 0], [0, 0, Sigma[2]]])
dataMatload = U[:, :3] * Sigma3 * VT[:3, :]
print("重构的原始矩阵:\n", dataMatload)
五、基于协同过滤的推荐引擎
- 协同过滤:通常是将用户和其他用户的数据进行对比来实现推荐的。下面的数据是采用餐馆的菜及评价的数据矩阵给出的。当数据采用这种方式给出时,就可以比较用户或物品之间的相似度。当知道两个用户或两个物品之间的相似度,就可以利用已有的数据来预测未知用户的喜好。唯一做的就是相似度的计算,计算方法通常有三种。
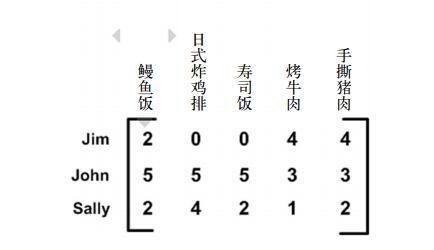
- 1.欧式距离
计算手撕猪肉与烤牛肉、鳗鱼饭之间的相似度,使用欧式距离来表示。计算公式如下:
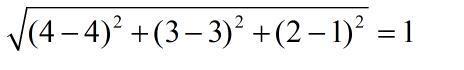
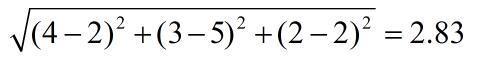
在上面的距离中,手撕猪肉与烤牛肉之间的距离小于手撕猪肉与鳗鱼饭之间的距离,因此手撕猪肉与烤牛肉更相似。我们希望相似度值在0到1之间变化,并且两个物品之间月相似,相似度值越大。可以使用**相似度=1/(1+欧式距离)**这样的计算方法来计算相似度,当距离为0是时,相似度是1. - 2.皮尔逊相关系数
相对于欧式距离的优势在于它对用户评级的量级并不敏感。例如,当某个极端主义者对所有物品的评分都是0或5,皮尔逊相关系数会认为这两个向量是相等的。在numpy中,皮尔逊相关系数由函数corrcoef()计算的。皮尔逊相关系数的取值范围从-1到+1,通过函数0.5+0.5*corrcoef()这个函数将取值范围归一化到0到1之间。 - 3.余弦相似度
计算两个向量之间夹角的余弦值,夹角是90度,相似度为0;两个向量同方向,则相似度为1。余弦相似度的范围也是-1到+1,因此也需要归一化至0到1之间。
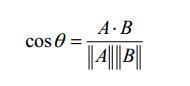
# 相似度计算函数 # 欧式距离---列向量参与运算 def ecludSim(inA, inB): return 1.0 / (1.0 + la.norm(inA - inB)) # la.norm是计算列向量的L2范数 # 皮尔逊系数 def pearSim(inA, inB): if (len(inA) < 3): return 1.0 else: return 0.5 + 0.5 * corrcoef(inA, inB, rowvar=0)[0][1] # 余弦相似度 def cosSim(inA, inB): num = float(inA.T * inB) denom = la.norm(inA) * la.norm(inB) return 0.5 + 0.5 * (num / denom)
- 1.欧式距离
###六、基于物品相似度的餐馆菜品推荐引擎实例
- 计算两个餐馆菜品之间的距离,称为基于物品的相似度。行与行之间的比较是基于用户的相似度,列与列之间的比较是基于物品的相似度。使用哪种相似度,主要取决于用户或物品的数量。如果用户的数目很多,倾向于使用基于物品的相似度的计算方法。对大部分产品导向的推荐引擎而言,用户的数量往往大于物品的数量,即购买商品的用户会对于出售商品的种类。另外,对推荐引擎的评价采用交叉测试的方法。将某些已经知道的评分值去掉,然后对它们进行预测,最后计算预测值与实际值之间的差异。通常用于推荐引擎的评价指标是最小均方根误差RMSE。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2019-05-20 10:34:35
# @Author : cdl ([email protected])
# @Link : https://github.com/cdlwhm1217096231/python3_spider
# @Version : $Id$
from numpy import *
from numpy import linalg as la
def loadDataSet():
return [[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[1, 1, 1, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1]]
def loadDataSet2():
return [[4, 4, 0, 2, 2],
[4, 0, 0, 3, 3],
[4, 0, 0, 1, 1],
[1, 1, 1, 2, 0],
[2, 2, 2, 0, 0],
[1, 1, 1, 0, 0],
[5, 5, 5, 0, 0]]
def loadExData():
return[[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
# 相似度计算函数
# 欧式距离---列向量参与运算
def ecludSim(inA, inB):
return 1.0 / (1.0 + la.norm(inA - inB)) # la.norm是计算列向量的L2范数
# 皮尔逊系数
def pearSim(inA, inB):
if (len(inA) < 3):
return 1.0
else:
return 0.5 + 0.5 * corrcoef(inA, inB, rowvar=0)[0][1]
# 余弦相似度
def cosSim(inA, inB):
num = float(inA.T * inB)
denom = la.norm(inA) * la.norm(inB)
return 0.5 + 0.5 * (num / denom)
# 基于物品(列)进行相似度的推荐引擎
def standEst(dataMat, user, simMeas, item):
"""
dataMat:数据集
user:用户
simMeans:相似度衡量方式
item:物品
"""
n = shape(dataMat)[1]
simTotal = 0.0
ratSimTotal = 0.0
for j in range(n):
userRating = dataMat[user, j]
if userRating == 0:
continue
overlap = nonzero(logical_and(
dataMat[:, item].A > 0, dataMat[:, j].A > 0))[0]
if len(overlap) == 0:
similarity = 0.0
else:
similarity = simMeas(dataMat[overlap, item], dataMat[overlap, j])
print("the %d and %d similarity is: %f" % (item, j, similarity))
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0.0:
return 0
else:
return ratSimTotal / simTotal
# 基于SVD的评分估计
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0
ratSimTotal = 0.0
U, Sigma, VT = la.svd(dataMat)
Sig4 = mat(eye(4) * Sigma[:4]) # 包含奇异值能量的90%
xformedItems = dataMat.T * U[:, :4]
for j in range(n):
userRating = dataMat[user, j]
if userRating == 0 or j == item:
continue
else:
similarity = simMeas(xformedItems[item, :].T, xformedItems[j, :].T)
print("the %d and %d similarity is: %f" % (item, j, similarity))
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0.0:
return 0
else:
return ratSimTotal / simTotal
# 推荐函数
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
unratedItems = nonzero(dataMat[user, :].A == 0)[1] # 寻找未评分的物品
if len(unratedItems) == 0.0:
return "you rated everything"
itemScores = []
for item in unratedItems:
estimatedScore = estMethod(dataMat, user, simMeas, item)
itemScores.append((item, estimatedScore))
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N]
if __name__ == "__main__":
dataMat = loadDataSet()
print("----------奇异值计算-----------")
U, Sigma, VT = la.svd(dataMat)
print("Sigma:\n", Sigma)
print("---------------重构原始矩阵dataMat------------")
Sigma3 = mat([[Sigma[0], 0, 0], [0, Sigma[1], 0], [0, 0, Sigma[2]]])
dataMatload = U[:, :3] * Sigma3 * VT[:3, :]
print("重构的原始矩阵:\n", dataMatload)
print("----------------几种相似度计算方法-----------------")
myData = mat(dataMat)
print("欧式距离:\n", ecludSim(myData[:, 0], myData[:, 4]))
print("欧式距离:\n", ecludSim(myData[:, 4], myData[:, 4]))
print("皮尔逊系数:\n", pearSim(myData[:, 0], myData[:, 4]))
print("皮尔逊系数:\n", pearSim(myData[:, 4], myData[:, 4]))
print("余弦相似度:\n", cosSim(myData[:, 0], myData[:, 4]))
print("余弦相似度:\n", cosSim(myData[:, 4], myData[:, 4]))
print("------------基于物品相似度的推荐引擎-----------")
dataMat2 = loadDataSet2()
myData2 = mat(dataMat2)
print("默认推荐结果:\n", recommend(myData2, user=2))
print("使用欧式距离,推荐结果:\n", recommend(myData2, user=2, simMeas=ecludSim))
print("使用皮尔逊系数,推荐结果:\n", recommend(myData2, user=2, simMeas=pearSim))
print("------------基于SVD相似度的推荐引擎-----------")
myData3 = mat(loadExData())
U, Sigma, VT = la.svd(myData3)
print("奇异值矩阵Sigma:\n", Sigma)
Sigma2 = Sigma ** 2
sumSigma = sum(Sigma2)
print("总能量:", sumSigma)
print("总能量的90%:", sumSigma * 0.9)
print("前两个元素所包含的能量:", sum(Sigma2[:2]))
print("前三个元素所包含的能量:", sum(Sigma2[:3])) # 将11维矩阵降维到3维矩阵
print("使用默认相似度的SVD进行评分:", recommend(myData3, user=1, estMethod=svdEst))
print("使用皮尔逊系数的SVD进行评分:", recommend(myData3, user=1,
estMethod=svdEst, simMeas=pearSim))