遗传算法与进化算法
引言
1858年7月1日C.R.达尔文与A.R.华莱士在伦敦林奈学会上宣读了进化论的论文,至此进化理论深入人心,为广大吃瓜群众开辟了一个思想的新的天地。而我们的机器学习大师们向来喜欢从生物学家那里找灵感,神经网络的灵感据说来自于人体的神经元,而根据进化论的思想,我们的大师们提出了遗传算法和进化算法。(其实我觉得我们的大师们只是给自己发明的东西找个勉强站得住脚的理由吧,哈哈。)
遗传算法
遗传算法是仿真生物遗传学和自然选择机理,通过人工方式所构造的一类搜索算法,从某种程度上说遗传算法是对生物进化过程进行的数学方式仿真。霍兰德(Holland)在他的著作《Adaptation in Natural and Artificial Systems》首次提出遗传算法,并主要由他和他的学生发展起来的。其主要思想是生物种群的生存过程普遍遵循达尔文进化准则,群体中的个体根据对环境的适应能力而被大自然所选择或淘汰。进化过程的结果反映在个体的结构上,其染色体包含若干基因,相应的表现型和基因型的联系体现了个体的外部特性与内部机理间逻辑关系。通过个体之间的交叉、变异来适应大自然环境。生物染色体用数学方式或计算机方式来体现就是一串数码,仍叫染色体,有时也叫个体;适应能力是对应着一个染色体的一个数值来衡量;染色体的选择或淘汰则按所面对的问题是求最大还是最小来进行。
抄了那么多的废话,其实本质上,遗传算法就是在一个解空间上,随机的给定一组解,这组解称为父亲种群,通过这组解的交叉,变异(一会再解释这几个概念),构建出新的解,称为下一代种群,然后在目前已有的所有解(父亲种群和下一代种群)中抽取表现好的解组成新的父亲种群,然后继续上面的过程,直到达到了迭代条件或者获取到了最优解(一般都是局部最优解)。
就像生物进化一样,一群生物,不适应环境的被淘汰了,剩下来的生物适应环境,所以他们会产生后代继承他们的优秀基因(这里也包含了基因的变异),他们的后代也是这样一直被自然选择下去,直到最后必然会产生最适应环境的个体。
遗传算法的框架
下图表示了遗传算法的一个基本框架,
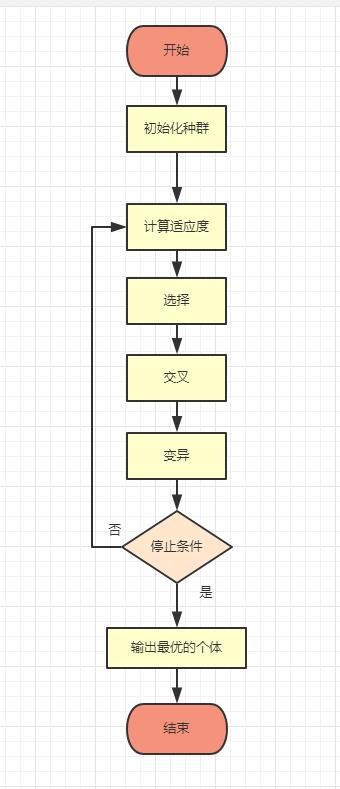
下面我们来解释下这个流程图里面的一些概念
适应度
所谓的适应度,本质上可以理解为一个代价函数,或者一个规则,通过对初始种群中的个体计算适应度,能够得到对初始种群中的个体是否优劣的一个度量
选择
选择操作是根据种群中的个体的适应度函数值所度量的优、劣程度决定它在下一代是被淘汰还是被遗传。
交叉
交叉操作是将选择的两个个体 p1 p 1 和 p2 p 2 作为父母节点,将两者的部分码值进行交换。假设有下面的两个节点的二进制编码表示:
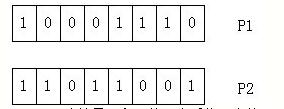
随机产生一个1到7之间的随机数,假设为3,则将 p1 p 1 和 p2 p 2 的低三位进行互换,如下图所示,就完成了交叉操作:
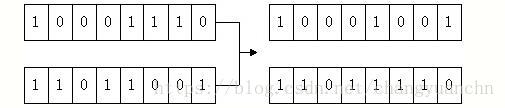
当然这个只是非常简单的交叉方法,业界常用的交叉方法为模拟二进制交叉,后面我们会继续介绍这种方法。
变异
变异操作就是改变节点 p2 p 2 的二进制编码的某些未知上的马尾的数值,如下所示:
| 1 | 1 | 0 | 1 | 1 | 1 | 1 |
随机产生一个1到8之间的随机数,假设为3,则将编码的第三位进行变异,将1变为0,如下图所示,就完成了交叉操作:
| 1 | 1 | 0 | 1 | 1 | 0 | 1 |
这个依旧是一种简单的变异操作,业界常用的变异操作方法有高斯变异,柯西变异等。
算法的收敛性
通过上面的操作,我们介绍了遗传算法的大概流程,那么现在还剩下一个问题,算法是否收敛,这个才是算法最关键的。
Radolph在文献[Radolph G. Convergence Analysis of Canonical Genetic Algorithms. IEEE Transactions on Neural Network, 1994,5(1): 96-101.]中证明了一般的遗传算法不一定收敛,只有每代保存了最优个体时才收敛。
进化算法
进化算法包括遗传算法、进化程序设计、进化规划和进化策略等等,进化算法的基本框架还是简单遗传算法所描述的框架,但在进化的方式上有较大的差异,选择、交叉、变异、种群控制等有很多变化,进化算法的大致框图可描述如下图所示:
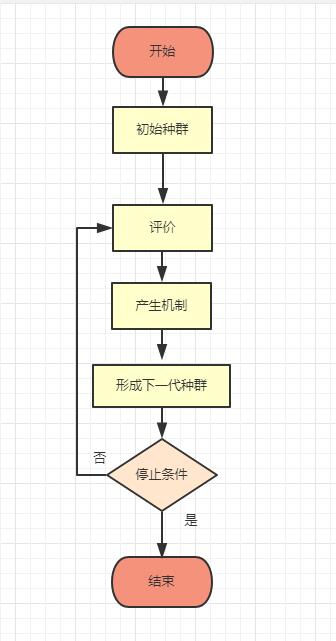
同遗传算法一样,进化算法的收敛性也是在保存最优个体时通用的进化计算是收敛的。但进化算法的很多结果是从遗传算法推过去的。
遗传算法对交叉操作要看重一些,认为变异操作是算法的辅助操作;而进化规划和进化策略认为在一般意义上说交叉并不优于变异,甚至可以不要交叉操作。
模拟二进制交叉算法

高斯变异
在进行变异时用一个均值为μ(μ实际上等于要变异的值)、方差为σ2的正态分布的一个随机数来替换原有基因值。也就是意味着以此数值为期望,以σ2(任取)为方差的正态分布中的一个值替换掉此数值。
高斯变异的局部搜索能力较好,但是引导个体跳出局部较优解的能力较弱,不利于全局收敛
多目标优化
多目标优化研究多于一个的目标函数在给定区域上的最优化,在很多实际问题中,例如经济、管理、军事、科学和工程设计等领域,衡量一个方案的好坏往往难以用一个指标来判断,而需要用多个目标来比较,而这些目标有时不甚协调,甚至是矛盾的。因此多目标优化大多数场景下无法得到在各个目标上都达到最优的结果。只能达到Pareto最优
Pareto最优
所谓的Pareto最优就是指下图所描述的场景
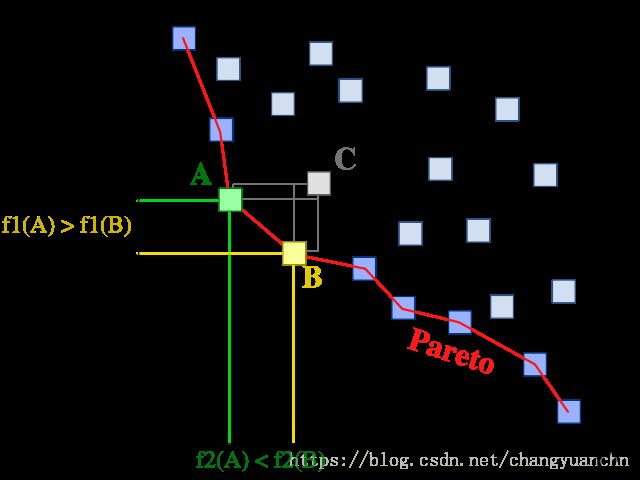
在多目标的优化过程中,如果对于一个点,不存在另外一个点在目标函数上比他更优,那么称这些最优的点组成的集合(点后者面或者其他空间结构)为pareto最优。如图所示,C点无论在f1还是f2上都比A点要打,那么这个C点就不是Pareto最优的。而对于A点和B点,无法找出任何一个点在两个维度上都比A或者B优,因此这两个点是Pareto最优的。
Pareto最优的是有实际意义的,Pareto最优也就意味着没有办法使任何一个人获得更多而不损失其他人的利益,如果可以,那么这个就不是Pareto最优的,pareto最优是一种模型上的最优。举个例子分10个苹果给3个小朋友,每个人3个,那么这个状态就不是Pareto最优的,因为还可以把一个苹果给一个孩子,而不减少其他孩子的苹果。如果给了一个孩子4个苹果,另外两个孩子三个苹果,那么如果想要给第一个孩子5个苹果。那么久必然从另两个孩子手中拿走一个,这个就是Pareto最优的。
多目标优化的目的就是得到Pareto最优
NSGA-2
MOEA/D
后记
目前看,遗传算法在工业界应用比较广泛,但是比较悲剧的是和神经网络一样,数学原理依旧不是很清晰,只不过算法效果比较好罢了,这也是一种遗憾。