关键字
神经元模型:神经网络中简单单元就可以称为神经元。
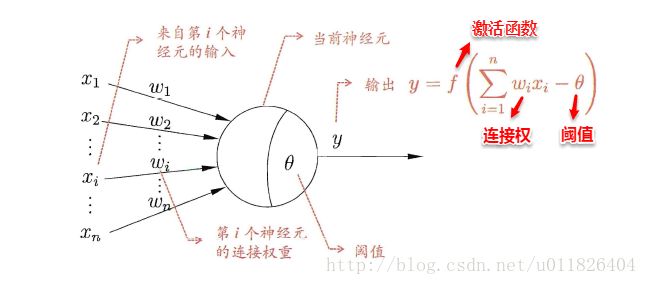
一直沿用至今的“M-P神经元模型”正是对这一结构进行了抽象,也称“阈值逻辑单元“,其中树突对应于输入部分,每个神经元收到n个其他神经元传递过来的输入信号,这些信号通过带权重的连接传递给细胞体,这些权重又称为连接权(connection weight)。细胞体分为两部分,前一部分计算总输入值(即输入信号的加权和,或者说累积电平),后一部分先计算总输入值与该神经元阈值的差值,然后通过激活函数(activation function)的处理,产生输出从轴突传送给其它神经元。
全局最小与局部极小:模型学习的过程实质上就是一个寻找最优参数的过程,例如BP算法试图通过最速下降来寻找使得累积经验误差最小的权值与阈值,在谈到最优时,一般会提到局部极小(local minimum)和全局最小(global minimum)。
- 局部极小解:参数空间中的某个点,其邻域点的误差函数值均不小于该点的误差函数值。
- 全局最小解:参数空间中的某个点,所有其他点的误差函数值均不小于该点的误差函数值。
1、神经网络和神经元模型
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络。神经网络中最基本的成分是神经元模型,即“简单单元”。
M-P神经元模型:神经元接收来自n个其他神经元传递过来的输入信号,输入信号通过带权重的连接进行传递,神经元收到的总输入值与阈值比较,然后通过“激活函数”产生神经元的输出。
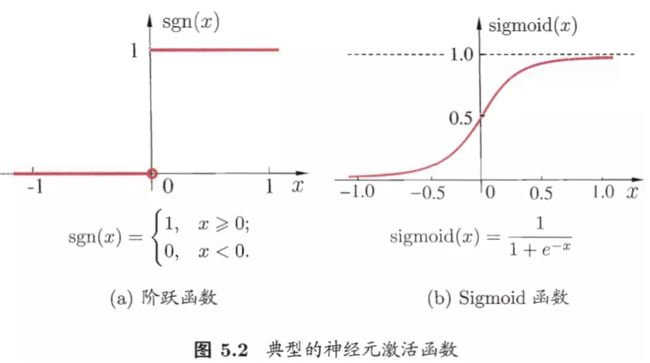
理想的激活函数是图5.2(a)所示的阶跃函数,输出值1对应神经元兴奋,0对应神经元抑制,缺点是不连续,不光滑。常用的激活函数是Sigmoid函数,输出值挤压在(0,1)内,又称挤压函数,如图5.2(b)所示
把许多个这样的神经元按一定的层次结构连接起来,就得到了神经网络。
2、多层前馈神经网络
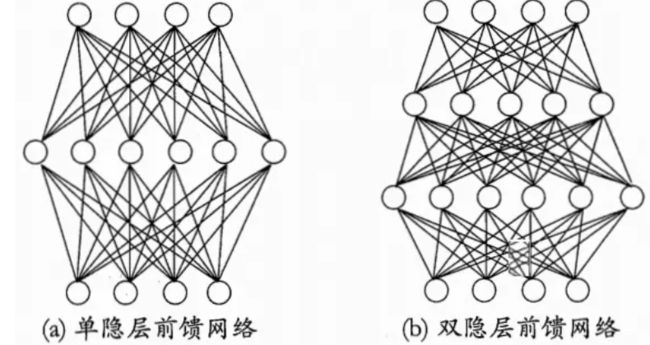
每层神经元与下一层神经元全互连,神经元之间不存在同层连接和跨层连接。其中输入层神经元接收外界输入,隐层与输出层神经元对信号加工,由输出神经元输出结果。
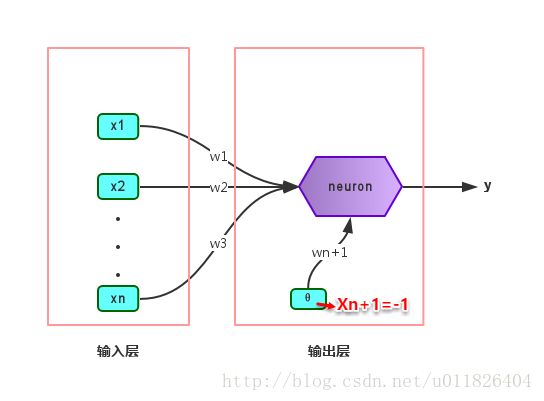
感知机和多层网络:感知机就是指由两层神经元组成,输入层接收外界输入信号后传递给输出层,输出层是M-P神经元,也称“阈值逻辑单元”。给定训练集,则感知机的n+1个参数(n个权重+1个阈值)都可以通过学习得到。阈值Θ可以看作一个输入值固定为-1的哑结点的权重ωn+1,即假设有一个固定输入xn+1=-1的输入层神经元,其对应的权重为ωn+1,这样就把权重和阈值统一为权重的学习了。简单感知机的结构如下图所示:
可以看出感知机是只有一层功能神经元,因此学习能力非常有限。在解决一些复杂问题时,我们就需要提供多层的功能神经元去处理,也就是说在输入层和输出层之间加入一层功能神经元,因此要解决非线性可分问题,需要考虑使用多层功能神经元,即神经网络。这一层常常称为隐层。这样隐层和输出层都有了激活函数的功能神经元。
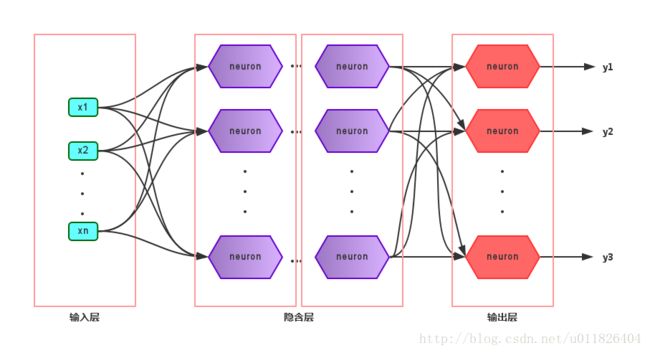
多层前馈神经网络:每层神经元与下层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接,称为“多层前馈神经网络”。这种网络中的输入层神经元只接受输入,不进行函数处理,隐层和输出层包含功能神经元。
3、误差逆传播算法
由上面可以得知:神经网络的学习主要蕴含在权重和阈值中,多层网络使用上面简单感知机的权重调整规则显然不够用了,BP神经网络算法即误差逆传播算法(error BackPropagation,BP)正是为学习多层前馈神经网络而设计,BP神经网络算法是迄今为止最成功的的神经网络学习算法。
先将输入层输入的数据提供给输入层神经元,然后逐层将信号前传,直到产生输出层的结构;然后计算输出层的误差,再将误差逆向传播至隐层神经元,最后根据隐层神经元的误差来对连接权和阈值进行调整,如此循环迭代,直到达到某些条件为止。
上图为一个单隐层前馈神经网络的拓扑结构,BP神经网络算法也使用梯度下降法(gradient descent),以单个样本的均方误差的负梯度方向对权重进行调节。可以看出:BP算法首先将误差反向传播给隐层神经元,调节隐层到输出层的连接权重与输出层神经元的阈值;接着根据隐含层神经元的均方误差,来调节输入层到隐含层的连接权值与隐含层神经元的阈值。注:BP算法的目标是要最小化训练集D上的误差积累,因此正因为强大的表示能力,BP神经网络经常出现过拟合,因此训练误差持续降低,而测试误差逐渐升高。那么常用“早停”和“正则化”两种测量来解决过拟合问题。
所以BP算法,是迄今最成功的神经网络学习算法。现实任务中使用神经网络时,大多是在使用BP算法进行训练。通常说“BP网络”时,一般是指用BP算法训练的多层前馈神经网络。
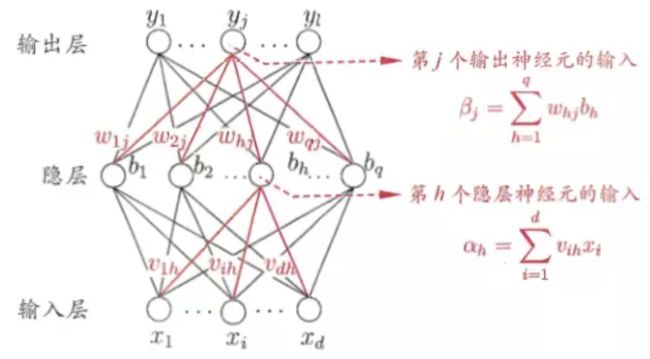
上图是一个由d个属性、l个输出神经元、q个隐层神经元的多层前馈网络结构。所示的网络有几个参数要确定:输入层到隐层的d*q个权值、隐层到输出层的q*l个权值,q个隐层神经元的阈值、l个输出层神经元的阈值。
4、BP算法的工作过程

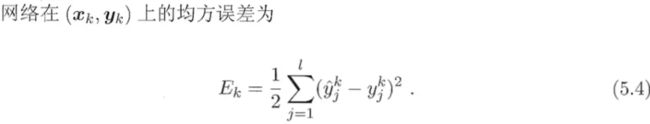

参数说明:

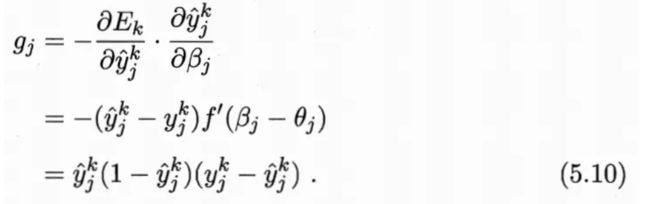


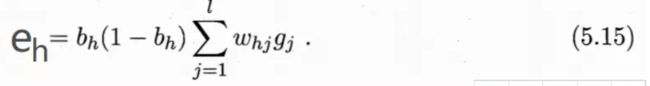
下图给出了BP算法的工作流程。对每个训练样例,BP算法执行以下操作:先将输入示例提供给输入层神经元,然后逐层将信号前传,直到产生输出层的结果;然后计算输出层的误差(第4-5行),再将误差逆传播至隐层神经元(第6行),最后根据隐层神经元的误差来对连接权和阈值进行调整(第7行)。该迭代过程循环进行,直到达到某些停止条件为止,例如训练误差已达到一个很小的值。

需注意的是,BP算法的目标是要最小化训练集D上的累积误差

但上图的更新规则是基于单个的Ek推导而得。如果是推导基于累积误差最小化的更新规则,就得到了累积误差逆传播算法。累积BP算法和标准BP算法都很常用。一般来说,标准BP算法每次更新只针对单个样例,参数更新的非常频繁,而且对不同样例更新的效果可能出现“抵消”现象。因此,为了达到同样的累积误差极小点,标准BP算法往往需进行更多次迭代。累积BP算法直接针对累积误差最小化,它在读取整个训练集D一遍后才对参数进行更新,其参数更新的频率低得多。但在很多任务中,累积误差下降到一定程度之后,进一步下降会非常缓慢,这时标准BP往往会更快获得较好的解,尤其是在训练集D非常大时更明显。
由于其强大的表示能力,BP神经网络经常遭遇过拟合,其训练误差持续降低,但测试误差却可能上升。有两种策略常用来缓解BP网络的过拟合。第一种策略是“早停”:将数据集分成训练集和测试集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。第二种策略是“正则化”,其基本思想是在误差目标函数中增加一个用于描述网络复杂度的部分,例如连接权与阈值的平方和。
5、代码
数据来自西瓜书P84

import numpy as np
dataset = pd.read_csv('watermelon_3.csv', delimiter=",")
数据预处理
# 处理数据集
attributeMap = {}
attributeMap['浅白'] = 0
attributeMap['青绿'] = 0.5
attributeMap['乌黑'] = 1
attributeMap['蜷缩'] = 0
attributeMap['稍蜷'] = 0.5
attributeMap['硬挺'] = 1
attributeMap['沉闷'] = 0
attributeMap['浊响'] = 0.5
attributeMap['清脆'] = 1
attributeMap['模糊'] = 0
attributeMap['稍糊'] = 0.5
attributeMap['清晰'] = 1
attributeMap['凹陷'] = 0
attributeMap['稍凹'] = 0.5
attributeMap['平坦'] = 1
attributeMap['硬滑'] = 0
attributeMap['软粘'] = 1
attributeMap['否'] = 0
attributeMap['是'] = 1
del dataset['编号']
dataset = np.array(dataset)
m, n = np.shape(dataset)
for i in range(m):
for j in range(n):
if dataset[i, j] in attributeMap:
dataset[i, j] = attributeMap[dataset[i, j]]
dataset[i, j] = round(dataset[i, j], 3)
trueY = dataset[:, n-1]
X = dataset[:, :n-1]
m, n = np.shape(X)
初始化参数
# P101,初始化参数
import random
d = n # 输入向量的维数
l = 1 # 输出向量的维数
q = d+1 # 隐层节点的数量
theta = [random.random() for i in range(l)] # 输出神经元的阈值
gamma = [random.random() for i in range(q)] # 隐层神经元的阈值
# v size= d*q .输入和隐层神经元之间的连接权重
v = [[random.random() for i in range(q)] for j in range(d)]
# w size= q*l .隐藏和输出神经元之间的连接权重
w = [[random.random() for i in range(l)] for j in range(q)]
eta = 0.2 # 学习率,控制每一轮迭代的步长
maxIter = 5000 # 最大训练次数
sigmoid函数
import math
def sigmoid(iX,dimension): # iX is a matrix with a dimension
if dimension == 1:
for i in range(len(iX)):
iX[i] = 1 / (1 + math.exp(-iX[i]))
else:
for i in range(len(iX)):
iX[i] = sigmoid(iX[i], dimension-1)
return iX
标准的误差逆传播
# 标准BP
while(maxIter > 0):
maxIter -= 1
sumE = 0
for i in range(m):
alpha = np.dot(X[i], v) # p101 line 2 from bottom, shape=1*q
b = sigmoid(alpha-gamma, 1) # b=f(alpha-gamma), shape=1*q
beta = np.dot(b, w) # shape=(1*q)*(q*l)=1*l
predictY = sigmoid(beta-theta, 1) # shape=1*l ,p102--5.3
E = sum((predictY-trueY[i])*(predictY-trueY[i]))/2 # 5.4
sumE += E # 5.16
# p104
g = predictY*(1-predictY)*(trueY[i]-predictY) # shape=1*l p103--5.10
e = b*(1-b)*((np.dot(w, g.T)).T) # shape=1*q , p104--5.15
w += eta*np.dot(b.reshape((q, 1)), g.reshape((1, l))) # 5.11
theta -= eta*g # 5.12
v += eta*np.dot(X[i].reshape((d, 1)), e.reshape((1, q))) # 5.13
gamma -= eta*e # 5.14
# print(sumE)
累积的误差逆传播
# #累积 BP
# trueY=trueY.reshape((m,l))
# while(maxIter>0):
# maxIter-=1
# sumE=0
# alpha = np.dot(X, v)#p101 line 2 from bottom, shape=m*q
# b = sigmoid(alpha - gamma,2) # b=f(alpha-gamma), shape=m*q
# beta = np.dot(b, w) # shape=(m*q)*(q*l)=m*l
# predictY = sigmoid(beta - theta,2) # shape=m*l ,p102--5.3
#
# E = sum(sum((predictY - trueY) * (predictY - trueY))) / 2 # 5.4
# # print(round(E,5))
# g = predictY * (1 - predictY) * (trueY - predictY) # shape=m*l p103--5.10
# e = b * (1 - b) * ((np.dot(w, g.T)).T) # shape=m*q , p104--5.15
# w += eta * np.dot(b.T, g) # 5.11 shape (q*l)=(q*m) * (m*l)
# theta -= eta * g # 5.12
# v += eta * np.dot(X.T, e) # 5.13 (d,q)=(d,m)*(m,q)
# gamma -= eta * e # 5.14
预测
def predict(iX):
alpha = np.dot(iX, v) # p101 line 2 from bottom, shape=m*q
b = sigmoid(alpha-gamma, 2) # b=f(alpha-gamma), shape=m*q
beta = np.dot(b, w) # shape=(m*q)*(q*l)=m*l
predictY = sigmoid(beta - theta, 2) # shape=m*l ,p102--5.3
return predictY
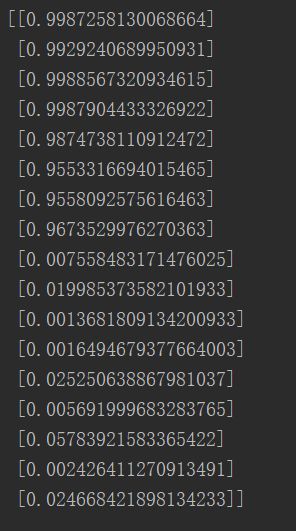
print(predict(X))
输出结果
整理的课后答案 http://blog.csdn.net/icefire_tyh/article/details/52106899
整个答案:http://blog.csdn.net/icefire_tyh/article/details/52064910
完整代码参考码云