机器学习之模型创建(一)
创建模型的过程
import sklearn.linear_model as lm
创建模型
model = lm.LinearRegression()
训练模型
model.fit(输入, 输出) # 通过梯度下降法计算模型参数
预测输出
model.predict(输入)->输出
输入是一个二维数组,每一行是一个样本,每一列是一个特征。
y = wo + w1x1 + w2x2 + … + wnxn
| 特征1 | 特征2 | ... | 特征n | |
|---|---|---|---|---|
| 样本1 | x11 | x12 | ... | x1n |
| 样本2 | x21 | x22 | ... | x2n |
| 样本3 | x31 | x32 | ... | x3n |
代入模型后可以得到
y1
y2
…
ym
输出是一个一维数组,其中每个元素对应输入矩阵中的一行。
如何评价一个模型的好坏呢?
import sklearn.metrics as sm
这边我们使用一组数据
以下是从一个txt文件中读取的数据
4.94,4.37
-1.58,1.7
-4.45,1.88
-6.06,0.56
-1.22,2.23
-3.55,1.53
0.36,2.99
-3.24,0.48
1.31,2.76
2.17,3.99
2.94,3.25
-0.92,2.27
-0.91,2.0
1.24,4.75
1.56,3.52
-4.14,1.39
3.75,4.9
4.15,4.44
0.33,2.72
3.41,4.59
2.27,5.3
2.6,3.43
1.06,2.53
1.04,3.69
2.74,3.1
-0.71,2.72
-2.75,2.82
0.55,3.53
-3.45,1.77
1.09,4.61
2.47,4.24
-6.35,1.0
1.83,3.84
-0.68,2.42
-3.83,0.67
-2.03,1.07
3.13,3.19
0.92,4.21
4.02,5.24
3.89,3.94
-1.81,2.85
3.94,4.86
-2.0,1.31
0.54,3.99
0.78,2.92
2.15,4.72
2.55,3.83
-0.63,2.58
1.06,2.89
-0.36,1.99
接下来我们看代码
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
import numpy as np
import matplotlib.pyplot as mp
import sklearn.linear_model as lm
import sklearn.metrics as sm
import pickle
#采集数据
x,y = [],[]
with open('./single.txt','r') as f:
for line in f.readlines():
data = [float(substr) for substr in line.split(',')]
x.append(data[:-1])
y.append(data[-1])
x = np.array(x)
y = np.array(y)
#创建模型,也就意味着选择了算法
model = lm.LinearRegression() #线性回归
#训练模型
model.fit(x,y)
#根据输入预测输出
pred_y = model.predict(x)
#打印每个样本的实际输出和预测输出
for true, pred in zip(y,pred_y):
print(true,'----->',pred)
mp.figure('Linear Regression', facecolor='lightgray')
mp.title('Linear Regression', fontsize=20)
mp.xlabel('x', fontsize=14)
mp.ylabel('y', fontsize=14)
mp.tick_params(labelsize=10)
mp.grid(linestyle=':')
mp.scatter(x, y, c='dodgerblue', alpha=0.75, s=60, label='Sample')
#得到输入从小到大的索引值
sorted_indices = x.T[0].argsort()
mp.plot(x[sorted_indices],pred_y[sorted_indices],c='orangered',label='Regression')
mp.legend()
mp.show()
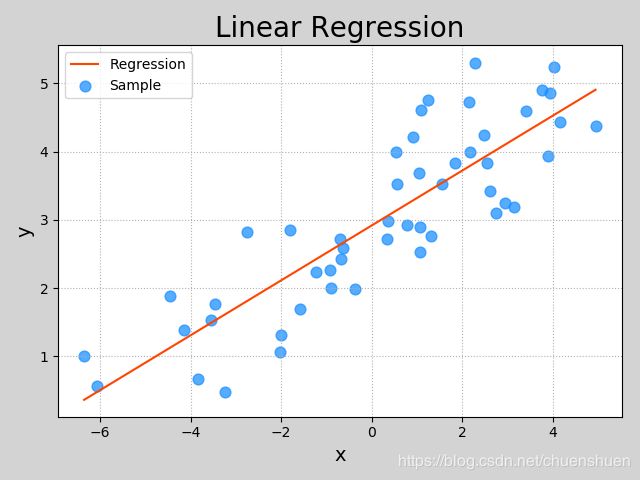
如上图,我们得到一个线性回归模型
如何评价一个模型的好坏呢?
import sklearn.metrics as sm
# 平均绝地值误差: 1/m * ∑|实际输出减去预测输出| 取绝地值
print(sm.mean_absolute_error(y,pred_y))
# 平均平方误差: SQRT(1/m * ∑(实际输出减去预测输出)^2)
print(sm.mean_squared_error(y,pred_y))
# 中位数绝对值误差:MEDIAN(|实际输出减去预测输出|)
print(sm.median_absolute_error(y,pred_y))
# R2得分 误差越接近于正无穷,r2值越接近于0,误差越接近0,r2值越接近1(相当于做了一次归一化)
print(sm.r2_score(y,pred_y))
可以得到如下数据
0.5482812185435971
0.43606903238180605
0.5356597030142565
0.736263899848181
模型的保存和加载
import pickle
pickle.dump(内存对象, 磁盘文件) # 保存模型,把内存对象放到磁盘文件中
pickle.load(磁盘文件)->内存对象 # 加载模型,读取磁盘文件中的内存对象
import pickle
#将训练好的学习模型保存到磁盘文件中
with open('./linear.pkl','wb') as f:
pickle.dump(model, f)
#从磁盘文件中加载模型对象
with open('./linear.pkl','rb') as f:
model = pickle.load(f)
重复上述代码,更改创建为读取,看看是否能得到相同的图形。