python正则表达式re模块入门,贪婪匹配和非贪婪匹配,案例:猫眼电影TOP100信息提取
目录
正则表达式:re模块
元字符
正则表达式如何匹配任意字符:re.S
贪婪匹配和非贪婪匹配
1.贪婪匹配
2.非贪婪匹配
正则表达式的分组
猫眼电影TOP100信息提取
1.需求分析
2.代码分析
3.编写程序
正则表达式:re模块
re模块有两种方式实现正则匹配
方式一:
lists=re.findall("he","hello world")
方式二:
pattern=re.complie("he")
lists=pattern.findall("hello world")
这两种方法都可以正则匹配字符,只是第二种方式提前定义了正则表达式,可以复用,所以推荐使用第二种方式
元字符
正则表达式常用的元字符如下:
| . | 匹配任意一个字符,除了\n |
| * | 匹配0个或多个的字符串 |
| + | 匹配1个或多个的字符串 |
| ? | 匹配0个或1个,为非贪婪方式 |
| [a, b , c] | 匹配 ‘a’ 或 ‘b’ 或 ‘c’ |
| \s | 匹配 任何 空白字符, 相当于[\t\n\r\f] |
| \S | 匹配 任何 非空白字符, 相当于[^\t\n\r\f] |
正则表达式如何匹配任意字符:re.S
通常来说,如果我们要匹配任意字符,可以这样写(方式一):
pattern=re.complie("[\s\S]")
lists=pattern.findall("hello\nworld")
这样写可以匹配到\n,看下面这种写法,这个写法并不会匹配\n这个换行符。一个页面有非常多的换行符,所以这么写时不合理的。
pattern=re.complie(".*")
lists=pattern.findall("hello\nworld")
那么我们可以使用re.S,如下,re.S代表允许'. '匹配'\n'(方式二,推荐):
pattern=re.complie(".*",re.S)
lists=pattern.findall("hello\nworld")
贪婪匹配和非贪婪匹配
1.贪婪匹配
在整个表达式匹配成功的情况下,尽可能的多匹配*或 + 或 ?。
表达方式:.* 或 .+ 或 .?
2.非贪婪匹配
在整个表达式匹配成功的情况下,尽可能的少匹配* 或 + 或 ?。
表达方式:.*? 或 .?? 或 .+?
贪婪匹配和非贪婪匹配到底有什么含义能,看下面的例子:
编写这么一段代码,我们预期的结果是得到几个集合,集合里有两个对象,
今天天气不错
太阳很舒服
import re
str="""
今天天气不错
太阳很舒服
"""
pattern=re.compile(".*
",re.S)
lists=pattern.findall(str)
print(lists)但是结果却成了一个对象,这是因为在贪婪匹配模式下,由于‘.’会匹配任意字符(它会认为

再看下面的一段代码,稍一看似乎没什么区别,眼睛尖的是能发现区别的,在.*后面加了一个?号,刚才说了这是非贪婪表达式方式,而非贪婪匹配的匹配模式是匹配最近的以
import re
str="""
今天天气不错
太阳很舒服
"""
pattern=re.compile(".*?
",re.S)
lists=pattern.findall(str)
print(lists)结果:
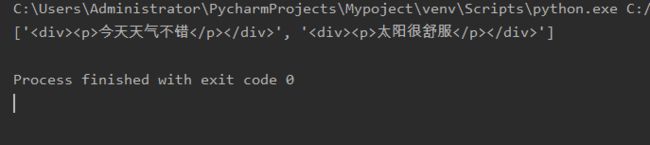
总结:在正则表达式中,绝大数情况会使用非贪婪匹配,非常好理解,我们需要的内容是一个装满了成功匹配的对象集合,而不是一个连在一起的对象集合(而且在多数情况下返回的结果总是会与你预想的结果有区别)。
正则表达式的分组
还是上面那个案例,我们刚才得到的结果如下图,我们仅需要
中间的内容该如何处理,这就需要用的正则表达式分组。正则表达式分组是指在完整的的模式中定义子模式,将每个用圆括号中的子模式作为结果提取出来
实际运用非常简单,还是上面的代码,我们只需要在.*?包在括号里即可,如下:
import re
str="""
今天天气不错
太阳很舒服
"""
pattern=re.compile('(.*?)
',re.S)
lists=pattern.findall(str)
做完上面的案例后,我们在具体来聊一下正则表达式的分组,请看下面3个案例:
import re
str='A B C D'
pattern2=re.compile("\w+\s+\w+")
lists2=pattern2.findall(str)
pattern3=re.compile("(\w+)\s+\w+")
lists3=pattern3.findall(str)
pattern4=re.compile("(\w+)\s+(\w+)")
lists4=pattern4.findall(str)
print(lists2)
print(lists3)
print(lists4)

先看第一组正则表达式:re.compile("\w+\s+\w+"),我们知道\w匹配任意字母和数字,+号匹配一个或多个,我们定义的str='A B C D',按照匹配规则,\w+将匹配一串连续的字符,而这里的字符用空格隔开了,所以只会匹配一个字符。\s+匹配任何空白字符,最后的\w+匹配一个字符。那么总结下来就是这样的匹配规则:字符 空格 字符。结果也是如此。
再看第二组正则表达式:re.compile("(\w+)\s+\w+"),与第一组的区别在与第一个\w+加了括号,从结果上区别就是只匹配到了一个字符。我们在上面的案例中讲了正则表达式的分组,这里的括号就是给\w+做分组,然它成为子模式。在子模式下只取出子模式的匹配内容作为结果,这里的\w+的匹配结果是A,所以输出A。
第三组:re.compile("(\w+)\s+(\w+)")。第三组有两个括号,代表有两个子模式。两个子模式会以元组的方式输出。
总结:
1.正则表达式的分组是通过加()来实现的
2.如果只想取匹配结果的某一段内容,为这一段内容的匹配模式加上()
3.有两个()将会以元组的方式进行输出
猫眼电影TOP100信息提取
1.需求分析
猫眼电影TOP100榜单URL:https://maoyan.com/board/4?offset=0
页面详情如下,我们要提取的信息有电影名称、主演、上移时间和评分。
因为是top100,每页显示10个,总计10页。分析URL得到第一页为https://maoyan.com/board/4?offset=0,第二页为https://maoyan.com/board/4?offset=10。
所以页码格式为offset=(page-1)*10

2.代码分析
提取信息的关键在与写对正则表达式,如图所示,我们要提取的信息有划红线的部分。

经过整理后得出的信息如下,我们要以这一串内容写一段正则表达式。首先我们将需要提取的字符打上分组符号()。要注意的是电影名有两处显示,我们选择title里的;评分是分为两段显示的,我们都要打上标记。切忌不要把他写成一行,目前这一段格式包含了\n换行符,并且每一个位置都是精确的,不易改动。
9.5
打完之后如下,现在这一段正则表达式仅可以匹配霸王别姬这一段内容,我们要想办法让他匹配所有。
(.*?)(.*?)
我们将多余的部分用.*?代替。得到如下格式。刚才说了,因为有换行符的存在,所以在换行出也要打上.*?
.*?title="(.*?)".*?
(.*?)
.*?
(.*?)
.*?
(.*?)(.*?)
最终经过整理后,得到下面内容。这里不要留空行,挤压成一段字符串。
.*?title="(.*?)".*?(.*?)
.*?(.*?)
.*?(.*?)(.*?)
3.编写程序
1.定义一个类
2.初始化类,定义url,headers,正则匹配表达式
3.定义方法:get_html()用于获取页面,注意转码
4.定义方法:run(),作为类的入口函数,提示输出页面。显示结果需要进一步处理,去除空格符
from urllib import request
import re
class Maoyan_spider(object):
def __init__(self):
self.url="https://maoyan.com/board/4?offset={}"
self.headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
self.pattern=re.compile('.*?title="(.*?)".*?(.*?)
.*?(.*?)'
'
.*?(.*?)(.*?)',re.S)
#获取页面
def get_html(self,url):
req = request.Request(url=url, headers=self.headers)
rep = request.urlopen(req)
html = rep.read().decode("utf-8")
return html
#入口函数
def run(self):
page=(int)(input("请输入页码数:"))
#计算页面
offset=(page-1)*10
#拼接url
url=self.url.format(offset)
html=self.get_html(url)
lists=self.pattern.findall(html)
for i in lists:
print("电影名:" + i[0].strip())
print(i[1].strip())
print(i[2].strip())
print("评分:" + i[3] + i[4])
if __name__ == "__main__":
maoyan=Maoyan_spider()
maoyan.run()
最终效果如下:
