MLflow机器学习工作流管理使用教程
MLflow简介
机器学习不是一个单向的pipeline,而是一个迭代的循环。其中包括四大部分:数据预处理、模型训练、模型部署、数据更新。
行业痛点:
- 数据预处理和模型训练都涉及到参数调整,不同参数对应的代码、不同参数对应的效果只能手动记录,这种方式比较费时费力而且不能保证每次记录都保存下来。
- 开发模型和模型部署是两个分开的环节,需要大量的沟通工作以及代码改写以及环境的配置,费时费力。
MLflow是一个管理机器学习生命周期的开源平台( Github项目地址),直面行业痛点。
接下来对MLflow的使用分为三个流程介绍:参数追踪、工程、模型
参数追踪(MLflow Tracking)
Tracking server
使用参数追踪功能前需要指定追踪服务器,默认情况下单机启动mlflow本机将作为参数服务器,默认uri为http://localhost:5000。如果参数服务器部署在远端,参数服务器可以收集多台client端运行得到的参数。
启动server命令行如下:
mlflow server [OPTIONS]
mlflow server \
--backend-store-uri \
--default-artifact-root \
--host \
--port \
--workers \
--gunicorn-opts
- –backend-store-uri是记录任务参数、指标、标签等字段信息的地址,默认会存本地路径,即这些字段信息以文件的形式存在server启动目录下的./mlruns路径中。除了本地路径,还可以用数据库记录这些字段的信息。
- –default-artifact-root是存储client端输出的大型文件,如文本、图片、模型文件等。artifacts文件默认会存在client端运行工程的./mlruns路径下,官方建议将artifacts存在Amazon S3, FTP server, HDFS等共享文件路径下。
- –workers可以指定gunicorn worker的数量,默认是4个。
- –gunicorn-opts可以添加额外操作。
在代码中使用Tracking
参数追踪能选择性记录入口程序的参数和性能指标(如模型的超参、模型性能指标、业务评价指标等),理论上入口程序中暴露的任何参数和指标都可以记录,使用者可以依据需求灵活记录需要的指标。
使用tracking记录参数是代码侵入式的,在最开始需要指定追踪服务器的uri、实验的名字、选择性添加实验标签(标签必须是key : value形式,string类型)
下面是示例实验的配置:
mlflow.set_tracking_uri("http://127.0.0.1:5000/")
mlflow.create_experiment("MLflowProject")
mlflow.set_tag("实验类型", "存模型和部署服务")
下面的代码是一个记录黑盒调参结果的demo:
# hyperopt黑盒调参
def mlflow_hyperopt(data_cleaner):
train_data, test_data, eva_data = data_cleaner.do_job()
lr = LogisticRegressionTrainer(train_data, test_data, Processing.SEPARATE.value)
def objective(args):
log_reg = LogisticRegression(C=args["C"], max_iter=int(args["max_iter"]),
solver="lbfgs",
class_weight={0: 0.9, 1: 0.1})
log_reg.fit(lr.get_x_train().values, lr.get_y_train().values.ravel())
y_pred = log_reg.predict(lr.get_x_test())
return -accuracy_score(lr.get_y_test().values.ravel(), y_pred)
space = {"max_iter": hp.choice("max_iter", range(50, 250)), # 确定参数搜索范围
"C": hp.uniform("C", 0.1, 1)}
max_evals = 20
algo = tpe.suggest # 选择寻参函数
best = fmin(objective, space, algo=algo, max_evals=max_evals, verbose=1)
# mlflow代码入侵部分
# 记录黑盒调参的最优参数和结果
with mlflow.start_run(run_name='V0.0.4', nested=True):
mlflow.log_params(best)
mlflow.log_param("max_evals", str(max_evals))
mlflow.log_metric('accuracy', abs(objective(best)))
代码第21行用’with’开头调用start_run()表示tracking开始,用这种方式不需要再使用end_run()去终止当前实验。
start_run(run_id=None, experiment_id=None, run_name=None, nested=False)
- run_id:可以手动指定也可以自动生成,如果没有指定则可以使用experiment_id和run_name标签
- experiment_id:实验所处目录名称
- run_name:多次实验可以处在同一个experiment_id对应目录下,本次实验的名称,可以作为区分每次实验的标签
- nested:本次实验是否某一次实验的子实验
log_param(key, value)
log_params(params)
log_metric(key, value, step=None)
log_metrics(metrics, step=None)
- log_param以key: value的形式记录参数,且参数均为string类型
- log_params以字典的形式记录多个参数,且参数均为string类型
- log_metric以key: value的形式记录指标,key是string类型value为float类型
- log_metrics以字典的形式记录多个参数,字典key、value字段类型同与log_metric一致
在MLflow UI中进行实验筛选和对比
MLflow支持类sql的方式,依据实验标签或者实验结果对多次实验进行筛选(可以参考下面两个图示的操作)。此外MLflow还支持简单的可视化实验结果对比,这部分功能可以在实践中慢慢尝试和摸索。
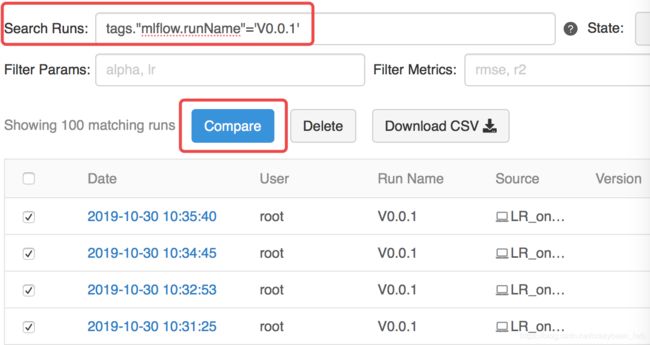
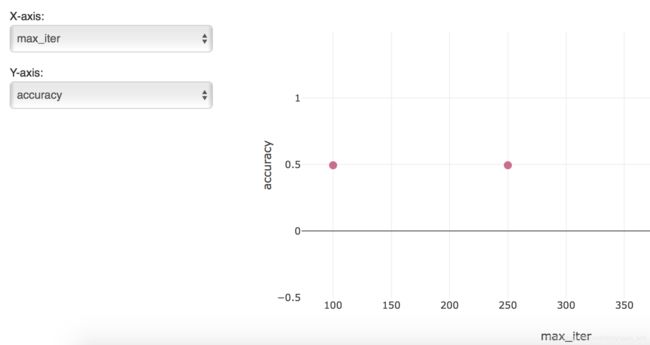
当然除了UI筛选,MLflow还支持java和python使用api的方式对实验结果筛选。
工程(MLflow Projects)
构建工程
注意:工程依赖环境有多种选择,以下案例工程均以conda作为依赖环境
构建MLflow工程只需要在原始工程根目录下添加MLproject和conda.yaml两个文件。MLproject负责记录这个项目的主要信息,conda.yaml记录项目依赖环境。
name: My Project
conda_env: conda.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}
如上MLproject示例文件所示,文件包含:
- 项目名称
- 依赖环境文件
- 入口程序(可以是多个)
- 如果在入口程序中设置了监听外界输入,可以指定入口程序的参数(也可以是默认参数)
name: sklearn-example
channels:
- defaults
dependencies:
- python==3.6.1
- pandas==0.20.3
- scipy==1.3.1
- numpy==1.17.2
- scikit-learn==0.21.3
- matplotlib==2.0.2
- pip:
- mlflow>=1.3
- hyperopt==0.2.2
如上conda.yaml示例文件所示,文件包含:
- 频道默认为conda
- 项目名称
- 依赖包
如果依赖的包比较多可以使用如下的命令将整个虚拟环境中的包都导出,建议每个项目在单独的虚拟环境中开发保证最小的依赖。
$ conda env export --name=environment_name > conda.yaml
运行工程
目前支持工程本地运行和git运行,本质上二者并无区别,使用git运行工程时会将整个工程从远程仓库拖拽到本地的临时路径中。建议使用git管理工程项目,方便版本管理与实验结果对比。
运行工程可以使用api也可以使用命令行的方式。
在cmd下使用 mlflow run 命令即可实现任务的提交,下面是一个提交运行的示例:
$ mlflow run file:///Users/lwb/.git/LogisticRegressionMLproject -v 8142edf2b2d1acb94e513d9ce1df12ebee511d3e -P C=1.0 -P class_weight=balanced --no-conda
提交任务的option含义如下:
- -v 版本:git管理的工程可以提交指定版本的任务,方便任务的复现
- -e 入口程序:默认调用MLproject文件中的main,调用其他入口需要指定
- -p 参数:入口程序中的参数列表,未提供调用默认参数
- -b 工程部署方式:默认使用local部署方式
- –no-conda 依赖环境:指定后任务将会在当前环境中运行,否则会下载conda.yaml中的依赖包
其他参数可以通过 $ mlflow run --help 命令查看
注意:由于工程依赖环境有多种,工程部署也可以多种方式,如databricks、kubernetes
模型(MLflow Models)
生成模型
MLflow Models相关文档对Models模块的定义为:这是一套标准格式来对模型结果进行打包,并可以被下游工具(如在线REST API服务和Apache Spark的批处理)所使用。
目前MLflow支持主流框架的模型格式,即下文提到的模型flavor参数,目前支持的flavor有如下几种:
 在tracking中使用api即可完成对模型文件的存储,下例是使用sk-learn风格对模型文件存储:
在tracking中使用api即可完成对模型文件的存储,下例是使用sk-learn风格对模型文件存储:
mlflow.sklearn.log_model(model, "my_model")
mlflow.sklearn.save_model(model, "my_model")
使用任一方式均可
模型存储地址默认为工程任务提交路径下 ./mlruns 文件夹下,也可以通过 --default-artifact-root 参数指定模型文件存储在hdfs等共享文件夹下。
将模型文件放在工程artifacts文件下可以看到模型文件包含:
- MLmodel:模型基本信息描述
- conda.yaml:依赖环境
- model.pkl:模型压缩文件
模型部署
UI部署
MLflow支持在artifacts路径下使用ui点击实现模型部署,生成模型服务如下例所示:
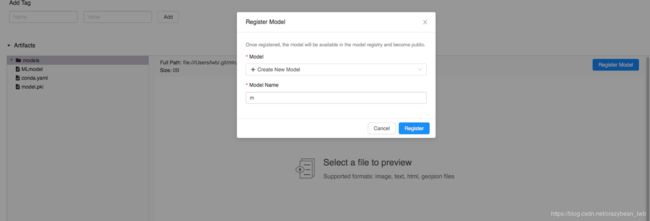 目前ui部署存在bug:不支持本地路径artifacts下的模型部署
目前ui部署存在bug:不支持本地路径artifacts下的模型部署
目前可以使用数据库存储的解决案例,但是该本部分依旧需要官方给出具体解决方案。
命令行下serve部署
启动模型serve命令行如下:
mlflow models serve [OPTIONS]
mlflow models serve \
--model-uri \
--host \
--port \
--workers \
--no-conda
- –model-uri 模型文件所在路径,如本地文件runs:/runid/model
- –workers 指定处理请求的worker数量,默认为4
- –no-conda 指定后使用本地conda环境,否则会下载模型文件依赖环境中的包
命令行下起模型服务后即可用api调用服务,下面是使用’post’方式调用的示例:
df = df[feature_headers].head(3)
msg = df.to_json(orient='split')
print(msg)
url = "http://0.0.0.0:8080/invocations"
headers = {'content-type': 'application/json; format=pandas-split'}
respond = requests.request("POST", url, data=msg, headers=headers)
print("predict: ", respond.json())
注意:发送数据的json格式与request中的字段格式一致
模型批处理
在命令行下使用模型文件能进行数据的批量预测,批量预测命令行如下:
mlflow models predict [OPTIONS]
mlflow models predict \
--model-uri \
--input-path \
--output-path \
--content-type \
--json-format \
--no-conda
- –model-uri 模型文件所在路径,如本地文件runs:/runid/model
- –input-path 输入文件
- –output-path 输出文件路径,默认与输入文件路径一致
- –content-type 输入文件格式,csv或json
- –json-format 如果输入文件是json格式,需要指定json的风格
- –no-conda 指定后使用本地conda环境,否则会下载模型文件依赖环境中的包
除了命令行批量处理,还可以调用api使用spark udf实现批量预测。
该种方法的核心思想是将模型文件加载成spark_udf,利用udf实现分布式批量预测。spark udf批量预测示例如下:
spark_df = spark.createDataFrame(df)
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, 'runs:/dcba50ddac7843bf9d371e270baf674d/models')
spark_df = spark_df.withColumn("prediction", pyfunc_udf('features'))
print(spark_df.show())
该种方法比较适用于需要大批量预测的场景。