Python 正则表达式之爬取古诗文名句
Python 正则表达式之爬取古诗文名句
概述:
山有木兮木有枝,心悦君兮君不知。
概念介绍:
- 正则表达式:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。简单来说就是利用事先规定好的符号规则进行组合,然后过滤匹配,得到自己想要的数据!
- Python 正则表达式:import导入re模块使 Python 语言拥有全部的正则表达式功能。
基本知识:
- 正则表达式常用字符:
| 元字符 | 含义 |
|---|---|
| . | 匹配一个除了\n的任意字符 |
| * | 匹配前面的表达式0次或者任意次 |
| ? | 匹配前面的表达式0次或者1次 最多一次 |
| + | 匹配前面的表达式1次或者任意次 最少一次 |
| () | 只返回匹配的内容 |
| .* | 贪婪匹配,一直匹配到最后一个 |
| .*? | 非贪婪匹配,匹配到第一个及结束 |
| {n} | 匹配n次 |
| \d | 匹配任何一个数字 D为不匹配任何数字 |
| \w | 匹配任何一个字母 W为不匹配任何数字 |
- Python 正则表达式常用函数
| 函数 | 含义 |
|---|---|
| re.findall | 可以获取字符串中所有匹配的字符串,返回一个数组 |
| re.S | 忽略换行 |
| re.I | 忽略大小写 |
本地爬取:
- 首先本地保存文件1.txt,里面保存的时我比较喜欢的一首诗 When you are old.
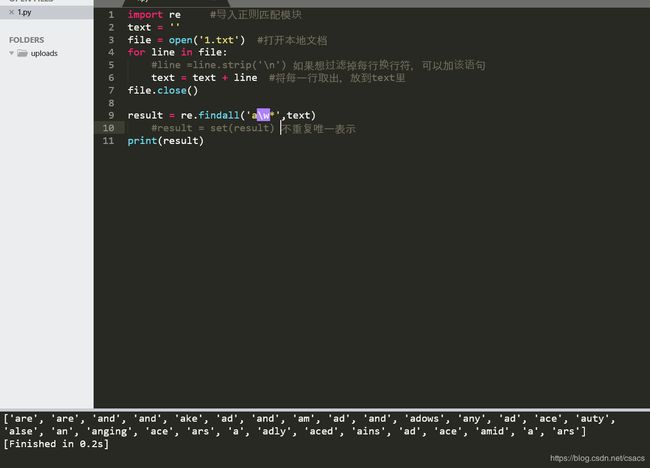
import re #导入正则匹配模块
text = ''
file = open('1.txt') #打开本地文档
for line in file:
#line =line.strip('\n') 如果想过滤掉每行换行符,可以加该语句
text = text + line #将每一行取出,放到text里
file.close()
result = re.findall(' a\w*',text) #匹配首字母是a的所有字符
#result = set(result) 不重复唯一表示
print(result)
网页爬取:
爬网页整体流程
爬取网页的流程一般如下:
1. 选着要爬的网址(url)
2. 使用 python 登录上这个网址(urlopen、requests 等)
3. 读取网页信息(read() 出来)
4. 将读取的信息放入 BeautifulSoup
5. 使用 BeautifulSoup 选取 tag 信息等
-夜已深了,先不搞了,未完待续…
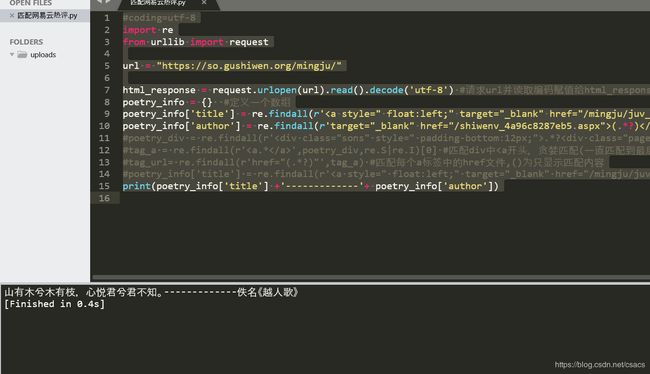
#coding=utf-8
import re
from urllib import request
url = "https://so.gushiwen.org/mingju/"
html_response = request.urlopen(url).read().decode('utf-8') #请求url并读取编码赋值给html_response
poetry_info = {} #定义一个数组
poetry_info['title'] = re.findall(r'(.*?)',html_response)[0] #匹配后的,非贪婪匹配(匹配一次,不往后进行)到之前的内容
poetry_info['author'] = re.findall(r'target="_blank" href="/shiwenv_4a96c8287eb5.aspx">(.*?)',html_response)[0]##匹配targer后的,非贪婪匹配到之前的内容
#poetry_div = re.findall(r'.*?',html_response,re.S|re.I)[0]#匹配div中间所有的html。【0】数组中取键位为0值
#tag_a = re.findall(r'',poetry_div,re.S|re.I)[0] #匹配div中 re.S 忽略回车 I 大小写
#tag_url= re.findall(r'href="(.*?)"',tag_a) #匹配每个a标签中的href文件,()为只显示匹配内容
#poetry_info['title'] = re.findall(r'(.*?)',html_response)#匹配每个诗句的具体url
print(poetry_info['title'] +'-------------'+ poetry_info['author'])
利用xpatch爬取
import requests
from parsel import Selector
import threading
headers = {
'authority': 'so.gushiwen.org',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
}
def get_page(num):
params = (
('p',f'{num}'),)
response = requests.get('https://so.gushiwen.org/mingju/default.aspx', headers=headers, params=params)
response.encoding = "utf8"
sel = Selector(response.text)
cont = sel.xpath('//div[@class="sons"]//div[@class="cont"]')
res = []
for s in cont:
l1 = s.xpath(".//a[1]/text()").extract_first()
l2 = s.xpath(".//a[2]/text()").extract_first()
#data = open("data.txt","a")
#data.write(l1+"---------"+l2+"\n")
print("num",num,l1+l2)
res.append((l1,l2))
return res
th = []
for p in range(1,30):
t = threading.Thread(target=get_page,args=(p,))
th.append(t)
for t in th:
t.start()

总结:持续更新,未完待续…
ps:萌新一枚,余生很长,请多指教。
